 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLANS: A Layout-Aware Neural Solver for Plane Geometry Problem
Nov 25, 2023Geometry problem solving (GPS) is a challenging mathematical reasoning task requiring multi-modal understanding, fusion and reasoning. Existing neural solvers take GPS as a vision-language task but be short in the representation of geometry diagrams which carry rich and complex layout information. In this paper, we propose a layout-aware neural solver named LANS, integrated with two new modules: multimodal layout-aware pre-trained language model (MLA-PLM) and layout-aware fusion attention (LA-FA). MLA-PLM adopts structural and semantic pre-training (SSP) to implement global relationship modeling, and point matching pre-training (PMP) to achieve alignment between visual points and textual points. LA-FA employs a layout-aware attention mask to realize point-guided cross-modal fusion for further boosting layout awareness of LANS. Extensive experiments on datasets Geometry3K and PGPS9K validate the effectiveness of the layout-aware modules and superior problem solving performance of our LANS solver, over existing symbolic solvers and neural solvers. The code will make public available soon.
ToonTalker: Cross-Domain Face Reenactment
Aug 24, 2023We target cross-domain face reenactment in this paper, i.e., driving a cartoon image with the video of a real person and vice versa. Recently, many works have focused on one-shot talking face generation to drive a portrait with a real video, i.e., within-domain reenactment. Straightforwardly applying those methods to cross-domain animation will cause inaccurate expression transfer, blur effects, and even apparent artifacts due to the domain shift between cartoon and real faces. Only a few works attempt to settle cross-domain face reenactment. The most related work AnimeCeleb requires constructing a dataset with pose vector and cartoon image pairs by animating 3D characters, which makes it inapplicable anymore if no paired data is available. In this paper, we propose a novel method for cross-domain reenactment without paired data. Specifically, we propose a transformer-based framework to align the motions from different domains into a common latent space where motion transfer is conducted via latent code addition. Two domain-specific motion encoders and two learnable motion base memories are used to capture domain properties. A source query transformer and a driving one are exploited to project domain-specific motion to the canonical space. The edited motion is projected back to the domain of the source with a transformer. Moreover, since no paired data is provided, we propose a novel cross-domain training scheme using data from two domains with the designed analogy constraint. Besides, we contribute a cartoon dataset in Disney style. Extensive evaluations demonstrate the superiority of our method over competing methods.
NOFA: NeRF-based One-shot Facial Avatar Reconstruction
Jul 07, 20233D facial avatar reconstruction has been a significant research topic in computer graphics and computer vision, where photo-realistic rendering and flexible controls over poses and expressions are necessary for many related applications. Recently, its performance has been greatly improved with the development of neural radiance fields (NeRF). However, most existing NeRF-based facial avatars focus on subject-specific reconstruction and reenactment, requiring multi-shot images containing different views of the specific subject for training, and the learned model cannot generalize to new identities, limiting its further applications. In this work, we propose a one-shot 3D facial avatar reconstruction framework that only requires a single source image to reconstruct a high-fidelity 3D facial avatar. For the challenges of lacking generalization ability and missing multi-view information, we leverage the generative prior of 3D GAN and develop an efficient encoder-decoder network to reconstruct the canonical neural volume of the source image, and further propose a compensation network to complement facial details. To enable fine-grained control over facial dynamics, we propose a deformation field to warp the canonical volume into driven expressions. Through extensive experimental comparisons, we achieve superior synthesis results compared to several state-of-the-art methods.
Efficient Text-Guided 3D-Aware Portrait Generation with Score Distillation Sampling on Distribution
Jun 03, 2023



Text-to-3D is an emerging task that allows users to create 3D content with infinite possibilities. Existing works tackle the problem by optimizing a 3D representation with guidance from pre-trained diffusion models. An apparent drawback is that they need to optimize from scratch for each prompt, which is computationally expensive and often yields poor visual fidelity. In this paper, we propose DreamPortrait, which aims to generate text-guided 3D-aware portraits in a single-forward pass for efficiency. To achieve this, we extend Score Distillation Sampling from datapoint to distribution formulation, which injects semantic prior into a 3D distribution. However, the direct extension will lead to the mode collapse problem since the objective only pursues semantic alignment. Hence, we propose to optimize a distribution with hierarchical condition adapters and GAN loss regularization. For better 3D modeling, we further design a 3D-aware gated cross-attention mechanism to explicitly let the model perceive the correspondence between the text and the 3D-aware space. These elaborated designs enable our model to generate portraits with robust multi-view semantic consistency, eliminating the need for optimization-based methods. Extensive experiments demonstrate our model's highly competitive performance and significant speed boost against existing methods.
Accelerating Diffusion Models for Inverse Problems through Shortcut Sampling
May 26, 2023



Recently, diffusion models have demonstrated a remarkable ability to solve inverse problems in an unsupervised manner. Existing methods mainly focus on modifying the posterior sampling process while neglecting the potential of the forward process. In this work, we propose Shortcut Sampling for Diffusion (SSD), a novel pipeline for solving inverse problems. Instead of initiating from random noise, the key concept of SSD is to find the "Embryo", a transitional state that bridges the measurement image y and the restored image x. By utilizing the "shortcut" path of "input-Embryo-output", SSD can achieve precise and fast restoration. To obtain the Embryo in the forward process, We propose Distortion Adaptive Inversion (DA Inversion). Moreover, we apply back projection and attention injection as additional consistency constraints during the generation process. Experimentally, we demonstrate the effectiveness of SSD on several representative tasks, including super-resolution, deblurring, and colorization. Compared to state-of-the-art zero-shot methods, our method achieves competitive results with only 30 NFEs. Moreover, SSD with 100 NFEs can outperform state-of-the-art zero-shot methods in certain tasks.
A Multi-Modal Neural Geometric Solver with Textual Clauses Parsed from Diagram
Feb 22, 2023



Geometry problem solving (GPS) is a high-level mathematical reasoning requiring the capacities of multi-modal fusion and geometric knowledge application. Recently, neural solvers have shown great potential in GPS but still be short in diagram presentation and modal fusion. In this work, we convert diagrams into basic textual clauses to describe diagram features effectively, and propose a new neural solver called PGPSNet to fuse multi-modal information efficiently. Combining structural and semantic pre-training, data augmentation and self-limited decoding, PGPSNet is endowed with rich knowledge of geometry theorems and geometric representation, and therefore promotes geometric understanding and reasoning. In addition, to facilitate the research of GPS, we build a new large-scale and fine-annotated GPS dataset named PGPS9K, labeled with both fine-grained diagram annotation and interpretable solution program. Experiments on PGPS9K and an existing dataset Geometry3K validate the superiority of our method over the state-of-the-art neural solvers. The code and dataset will be public available soon.
Generalizable Black-Box Adversarial Attack with Meta Learning
Jan 01, 2023In the scenario of black-box adversarial attack, the target model's parameters are unknown, and the attacker aims to find a successful adversarial perturbation based on query feedback under a query budget. Due to the limited feedback information, existing query-based black-box attack methods often require many queries for attacking each benign example. To reduce query cost, we propose to utilize the feedback information across historical attacks, dubbed example-level adversarial transferability. Specifically, by treating the attack on each benign example as one task, we develop a meta-learning framework by training a meta-generator to produce perturbations conditioned on benign examples. When attacking a new benign example, the meta generator can be quickly fine-tuned based on the feedback information of the new task as well as a few historical attacks to produce effective perturbations. Moreover, since the meta-train procedure consumes many queries to learn a generalizable generator, we utilize model-level adversarial transferability to train the meta-generator on a white-box surrogate model, then transfer it to help the attack against the target model. The proposed framework with the two types of adversarial transferability can be naturally combined with any off-the-shelf query-based attack methods to boost their performance, which is verified by extensive experiments.
3D GAN Inversion with Facial Symmetry Prior
Nov 30, 2022Recently, a surge of high-quality 3D-aware GANs have been proposed, which leverage the generative power of neural rendering. It is natural to associate 3D GANs with GAN inversion methods to project a real image into the generator's latent space, allowing free-view consistent synthesis and editing, referred as 3D GAN inversion. Although with the facial prior preserved in pre-trained 3D GANs, reconstructing a 3D portrait with only one monocular image is still an ill-pose problem. The straightforward application of 2D GAN inversion methods focuses on texture similarity only while ignoring the correctness of 3D geometry shapes. It may raise geometry collapse effects, especially when reconstructing a side face under an extreme pose. Besides, the synthetic results in novel views are prone to be blurry. In this work, we propose a novel method to promote 3D GAN inversion by introducing facial symmetry prior. We design a pipeline and constraints to make full use of the pseudo auxiliary view obtained via image flipping, which helps obtain a robust and reasonable geometry shape during the inversion process. To enhance texture fidelity in unobserved viewpoints, pseudo labels from depth-guided 3D warping can provide extra supervision. We design constraints aimed at filtering out conflict areas for optimization in asymmetric situations. Comprehensive quantitative and qualitative evaluations on image reconstruction and editing demonstrate the superiority of our method.
VideoReTalking: Audio-based Lip Synchronization for Talking Head Video Editing In the Wild
Nov 27, 2022We present VideoReTalking, a new system to edit the faces of a real-world talking head video according to input audio, producing a high-quality and lip-syncing output video even with a different emotion. Our system disentangles this objective into three sequential tasks: (1) face video generation with a canonical expression; (2) audio-driven lip-sync; and (3) face enhancement for improving photo-realism. Given a talking-head video, we first modify the expression of each frame according to the same expression template using the expression editing network, resulting in a video with the canonical expression. This video, together with the given audio, is then fed into the lip-sync network to generate a lip-syncing video. Finally, we improve the photo-realism of the synthesized faces through an identity-aware face enhancement network and post-processing. We use learning-based approaches for all three steps and all our modules can be tackled in a sequential pipeline without any user intervention. Furthermore, our system is a generic approach that does not need to be retrained to a specific person. Evaluations on two widely-used datasets and in-the-wild examples demonstrate the superiority of our framework over other state-of-the-art methods in terms of lip-sync accuracy and visual quality.
MobileCodec: Neural Inter-frame Video Compression on Mobile Devices
Jul 18, 2022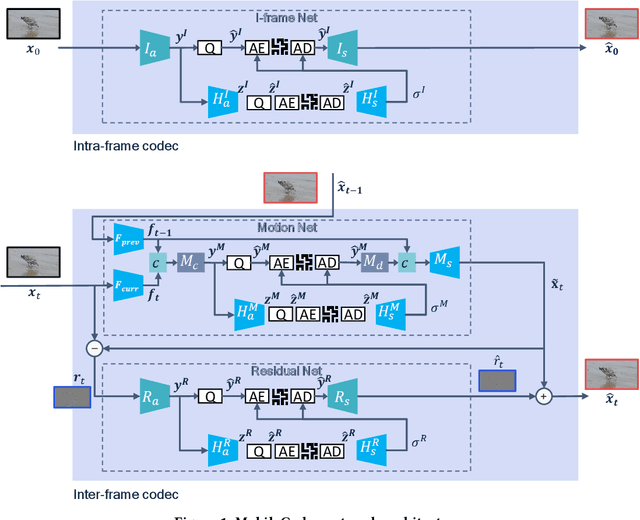
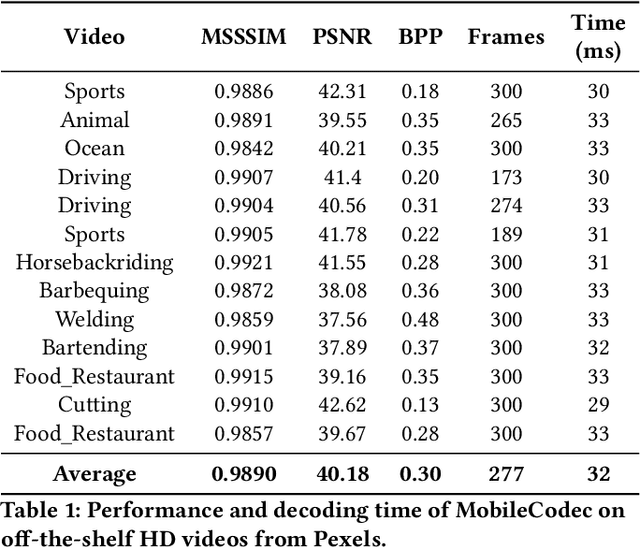
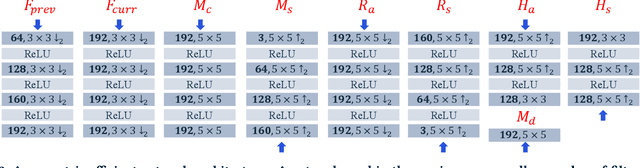
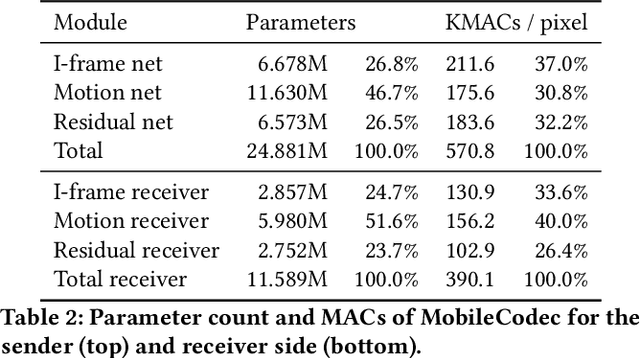
Realizing the potential of neural video codecs on mobile devices is a big technological challenge due to the computational complexity of deep networks and the power-constrained mobile hardware. We demonstrate practical feasibility by leveraging Qualcomm's technology and innovation, bridging the gap from neural network-based codec simulations running on wall-powered workstations, to real-time operation on a mobile device powered by Snapdragon technology. We show the first-ever inter-frame neural video decoder running on a commercial mobile phone, decoding high-definition videos in real-time while maintaining a low bitrate and high visual quality.