 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Adapted Fine-Tuning of ECG Foundation Models for Multi-Label Structural Heart Disease Screening
Apr 25, 2026Transthoracic echocardiography is the reference standard for confirming structural heart disease (SHD), but first-line screening is limited by cost, workflow burden, and specialist availability. We evaluated whether open pretrained electrocardiogram (ECG) foundation models can support echo-confirmed multi-label SHD detection using the public EchoNext Mini-Model benchmark. Six echocardiography-derived abnormalities were targeted: reduced left ventricular ejection fraction, increased left ventricular wall thickness, aortic stenosis, mitral regurgitation, tricuspid regurgitation, and right ventricular systolic dysfunction. Under a common pipeline, we compared engineered ECG features with gradient boosting, end-to-end waveform learning from scratch, and transfer from open ECG foundation models. We then applied in-domain self-supervised adaptation of an ECG foundation model (ECG-FM) on EchoNext waveforms followed by selective supervised fine-tuning, and evaluated trade-offs between discrimination and adaptation cost. Adapted ECG-FM models achieved the best overall performance: peak macro-AUROC 0.8509 and macro-AUPRC 0.4297, while a parameter-efficient operating point preserved AUROC (0.8501) and attained the highest fixed-threshold macro-F1 0.3691. Late fusion with covariates did not improve threshold-independent discrimination, and evaluated LoRA, alternative backbones, and mixture-of-foundations strategies did not surpass the best adapted single-backbone models. These results indicate that for ECG-based case finding and echocardiography triage, combining target-domain self-supervised adaptation with selective supervised updating of a pretrained ECG backbone is the most effective transfer strategy.
HiFloat4 Format for Language Model Pre-training on Ascend NPUs
Apr 09, 2026Large foundation models have become central to modern machine learning, with performance scaling predictably with model size and data. However, training and deploying such models incur substantial computational and memory costs, motivating the development of low-precision training techniques. Recent work has demonstrated that 4-bit floating-point (FP4) formats--such as MXFP4 and NVFP4--can be successfully applied to linear GEMM operations in large language models (LLMs), achieving up to 4x improvements in compute throughput and memory efficiency compared to higher-precision baselines. In this work, we investigate the recently proposed HiFloat4 FP4 format for Huawei Ascend NPUs and systematically compare it with MXFP4 in large-scale training settings. All experiments are conducted on Ascend NPU clusters, with linear and expert GEMM operations performed entirely in FP4 precision. We evaluate both dense architectures (e.g., Pangu and LLaMA-style models) and mixture-of-experts (MoE) models, where both standard linear layers and expert-specific GEMMs operate in FP4. Furthermore, we explore stabilization techniques tailored to FP4 training that significantly reduce numerical degradation, maintaining relative error within 1% of full-precision baselines while preserving the efficiency benefits of 4-bit computation. Our results provide a comprehensive empirical study of FP4 training on NPUs and highlight the practical trade-offs between FP4 formats in large-scale dense and MoE models.
Do-Undo: Generating and Reversing Physical Actions in Vision-Language Models
Dec 15, 2025We introduce the Do-Undo task and benchmark to address a critical gap in vision-language models: understanding and generating physically plausible scene transformations driven by real-world actions. Unlike prior work focused on object-level edits, Do-Undo requires models to simulate the outcome of a physical action and then accurately reverse it, reflecting true cause-and-effect in the visual world. We curate a large-scale dataset of reversible actions from real-world videos and design a training strategy enforcing consistency for robust action grounding. Our experiments reveal that current models struggle with physical reversibility, underscoring the importance of this task for embodied AI, robotics, and physics-aware generative modeling. Do-Undo establishes an intuitive testbed for evaluating and advancing physical reasoning in multimodal systems.
Improved Mapping Between Illuminations and Sensors for RAW Images
Aug 20, 2025RAW images are unprocessed camera sensor output with sensor-specific RGB values based on the sensor's color filter spectral sensitivities. RAW images also incur strong color casts due to the sensor's response to the spectral properties of scene illumination. The sensor- and illumination-specific nature of RAW images makes it challenging to capture RAW datasets for deep learning methods, as scenes need to be captured for each sensor and under a wide range of illumination. Methods for illumination augmentation for a given sensor and the ability to map RAW images between sensors are important for reducing the burden of data capture. To explore this problem, we introduce the first-of-its-kind dataset comprising carefully captured scenes under a wide range of illumination. Specifically, we use a customized lightbox with tunable illumination spectra to capture several scenes with different cameras. Our illumination and sensor mapping dataset has 390 illuminations, four cameras, and 18 scenes. Using this dataset, we introduce a lightweight neural network approach for illumination and sensor mapping that outperforms competing methods. We demonstrate the utility of our approach on the downstream task of training a neural ISP. Link to project page: https://github.com/SamsungLabs/illum-sensor-mapping.
Sort-free Gaussian Splatting via Weighted Sum Rendering
Oct 24, 2024



Recently, 3D Gaussian Splatting (3DGS) has emerged as a significant advancement in 3D scene reconstruction, attracting considerable attention due to its ability to recover high-fidelity details while maintaining low complexity. Despite the promising results achieved by 3DGS, its rendering performance is constrained by its dependence on costly non-commutative alpha-blending operations. These operations mandate complex view dependent sorting operations that introduce computational overhead, especially on the resource-constrained platforms such as mobile phones. In this paper, we propose Weighted Sum Rendering, which approximates alpha blending with weighted sums, thereby removing the need for sorting. This simplifies implementation, delivers superior performance, and eliminates the "popping" artifacts caused by sorting. Experimental results show that optimizing a generalized Gaussian splatting formulation to the new differentiable rendering yields competitive image quality. The method was implemented and tested in a mobile device GPU, achieving on average $1.23\times$ faster rendering.
Low-Latency Neural Stereo Streaming
Mar 26, 2024



The rise of new video modalities like virtual reality or autonomous driving has increased the demand for efficient multi-view video compression methods, both in terms of rate-distortion (R-D) performance and in terms of delay and runtime. While most recent stereo video compression approaches have shown promising performance, they compress left and right views sequentially, leading to poor parallelization and runtime performance. This work presents Low-Latency neural codec for Stereo video Streaming (LLSS), a novel parallel stereo video coding method designed for fast and efficient low-latency stereo video streaming. Instead of using a sequential cross-view motion compensation like existing methods, LLSS introduces a bidirectional feature shifting module to directly exploit mutual information among views and encode them effectively with a joint cross-view prior model for entropy coding. Thanks to this design, LLSS processes left and right views in parallel, minimizing latency; all while substantially improving R-D performance compared to both existing neural and conventional codecs.
Bitstream Organization for Parallel Entropy Coding on Neural Network-based Video Codecs
Dec 01, 2023



Video compression systems must support increasing bandwidth and data throughput at low cost and power, and can be limited by entropy coding bottlenecks. Efficiency can be greatly improved by parallelizing coding, which can be done at much larger scales with new neural-based codecs, but with some compression loss related to data organization. We analyze the bit rate overhead needed to support multiple bitstreams for concurrent decoding, and for its minimization propose a method for compressing parallel-decoding entry points, using bidirectional bitstream packing, and a new form of jointly optimizing arithmetic coding termination. It is shown that those techniques significantly lower the overhead, making it easier to reduce it to a small fraction of the average bitstream size, like, for example, less than 1% and 0.1% when the average number of bitstream bytes is respectively larger than 95 and 1,200 bytes.
MobileNVC: Real-time 1080p Neural Video Compression on a Mobile Device
Oct 02, 2023



Neural video codecs have recently become competitive with standard codecs such as HEVC in the low-delay setting. However, most neural codecs are large floating-point networks that use pixel-dense warping operations for temporal modeling, making them too computationally expensive for deployment on mobile devices. Recent work has demonstrated that running a neural decoder in real time on mobile is feasible, but shows this only for 720p RGB video, while the YUV420 format is more commonly used in production. This work presents the first neural video codec that decodes 1080p YUV420 video in real time on a mobile device. Our codec relies on two major contributions. First, we design an efficient codec that uses a block-based motion compensation algorithm available on the warping core of the mobile accelerator, and we show how to quantize this model to integer precision. Second, we implement a fast decoder pipeline that concurrently runs neural network components on the neural signal processor, parallel entropy coding on the mobile GPU, and warping on the warping core. Our codec outperforms the previous on-device codec by a large margin with up to 48 % BD-rate savings, while reducing the MAC count on the receiver side by 10x. We perform a careful ablation to demonstrate the effect of the introduced motion compensation scheme, and ablate the effect of model quantization.
Optimized learned entropy coding parameters for practical neural-based image and video compression
Jan 20, 2023



Neural-based image and video codecs are significantly more power-efficient when weights and activations are quantized to low-precision integers. While there are general-purpose techniques for reducing quantization effects, large losses can occur when specific entropy coding properties are not considered. This work analyzes how entropy coding is affected by parameter quantizations, and provides a method to minimize losses. It is shown that, by using a certain type of coding parameters to be learned, uniform quantization becomes practically optimal, also simplifying the minimization of code memory requirements. The mathematical properties of the new representation are presented, and its effectiveness is demonstrated by coding experiments, showing that good results can be obtained with precision as low as 4~bits per network output, and practically no loss with 8~bits.
* 2022 IEEE International Conference on Image Processing (ICIP)
Boosting neural video codecs by exploiting hierarchical redundancy
Aug 08, 2022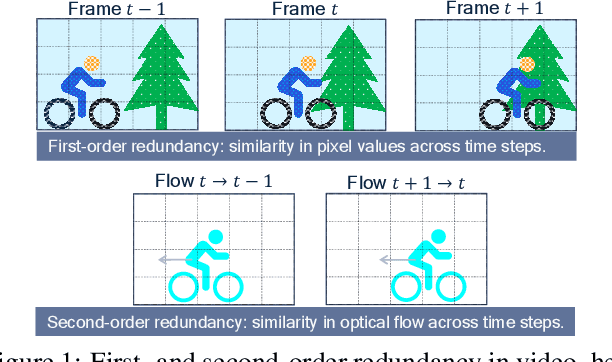
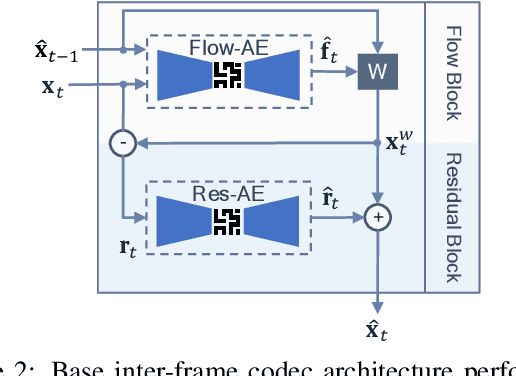
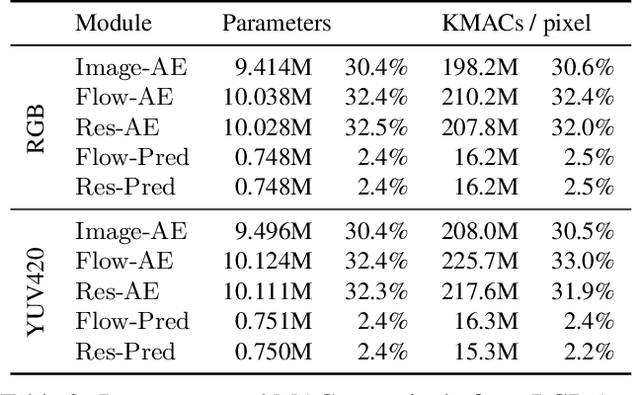
In video compression, coding efficiency is improved by reusing pixels from previously decoded frames via motion and residual compensation. We define two levels of hierarchical redundancy in video frames: 1) first-order: redundancy in pixel space, i.e., similarities in pixel values across neighboring frames, which is effectively captured using motion and residual compensation, 2) second-order: redundancy in motion and residual maps due to smooth motion in natural videos. While most of the existing neural video coding literature addresses first-order redundancy, we tackle the problem of capturing second-order redundancy in neural video codecs via predictors. We introduce generic motion and residual predictors that learn to extrapolate from previously decoded data. These predictors are lightweight, and can be employed with most neural video codecs in order to improve their rate-distortion performance. Moreover, while RGB is the dominant colorspace in neural video coding literature, we introduce general modifications for neural video codecs to embrace the YUV420 colorspace and report YUV420 results. Our experiments show that using our predictors with a well-known neural video codec leads to 38% and 34% bitrate savings in RGB and YUV420 colorspaces measured on the UVG dataset.