 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Vision Transformer with Adaptive Focal Loss for Medical Image Classification
Feb 02, 2026While deep learning models like Vision Transformer (ViT) have achieved significant advances, they typically require large datasets. With data privacy regulations, access to many original datasets is restricted, especially medical images. Federated learning (FL) addresses this challenge by enabling global model aggregation without data exchange. However, the heterogeneity of the data and the class imbalance that exist in local clients pose challenges for the generalization of the model. This study proposes a FL framework leveraging a dynamic adaptive focal loss (DAFL) and a client-aware aggregation strategy for local training. Specifically, we design a dynamic class imbalance coefficient that adjusts based on each client's sample distribution and class data distribution, ensuring minority classes receive sufficient attention and preventing sparse data from being ignored. To address client heterogeneity, a weighted aggregation strategy is adopted, which adapts to data size and characteristics to better capture inter-client variations. The classification results on three public datasets (ISIC, Ocular Disease and RSNA-ICH) show that the proposed framework outperforms DenseNet121, ResNet50, ViT-S/16, ViT-L/32, FedCLIP, Swin Transformer, CoAtNet, and MixNet in most cases, with accuracy improvements ranging from 0.98\% to 41.69\%. Ablation studies on the imbalanced ISIC dataset validate the effectiveness of the proposed loss function and aggregation strategy compared to traditional loss functions and other FL approaches. The codes can be found at: https://github.com/AIPMLab/ViT-FLDAF.
GazeFormer-MoE: Context-Aware Gaze Estimation via CLIP and MoE Transformer
Jan 18, 2026We present a semantics modulated, multi scale Transformer for 3D gaze estimation. Our model conditions CLIP global features with learnable prototype banks (illumination, head pose, background, direction), fuses these prototype-enriched global vectors with CLIP patch tokens and high-resolution CNN tokens in a unified attention space, and replaces several FFN blocks with routed/shared Mixture of Experts to increase conditional capacity. Evaluated on MPIIFaceGaze, EYEDIAP, Gaze360 and ETH-XGaze, our model achieves new state of the art angular errors of 2.49°, 3.22°, 10.16°, and 1.44°, demonstrating up to a 64% relative improvement over previously reported results. ablations attribute gains to prototype conditioning, cross scale fusion, MoE and hyperparameter. Our code is publicly available at https://github. com/AIPMLab/Gazeformer.
A Knowledge Distillation-Based Approach to Enhance Transparency of Classifier Models
Feb 21, 2025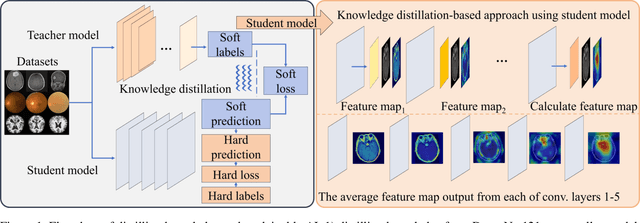
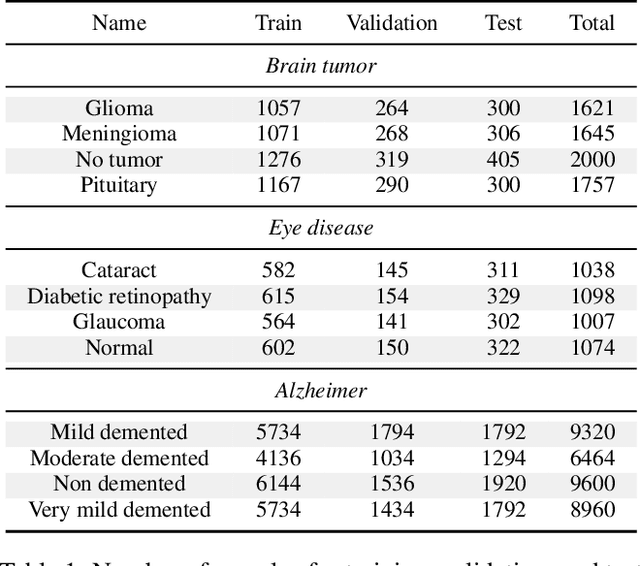
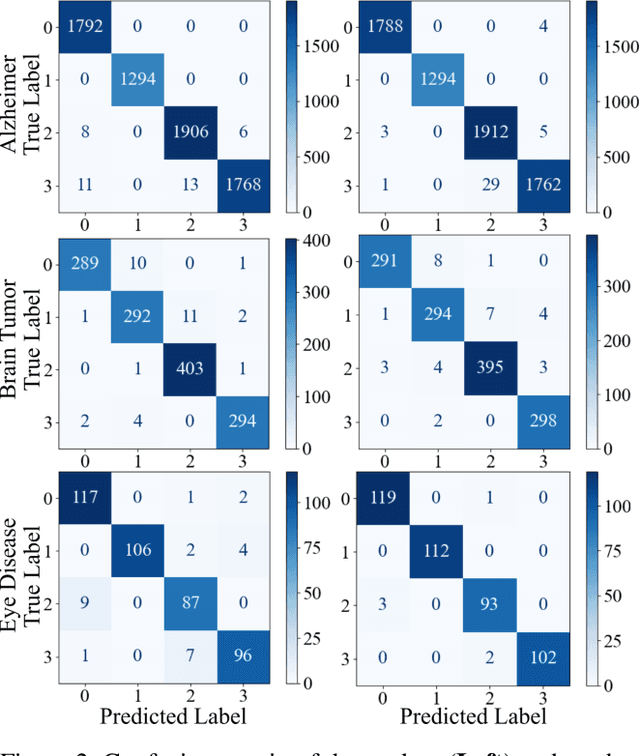
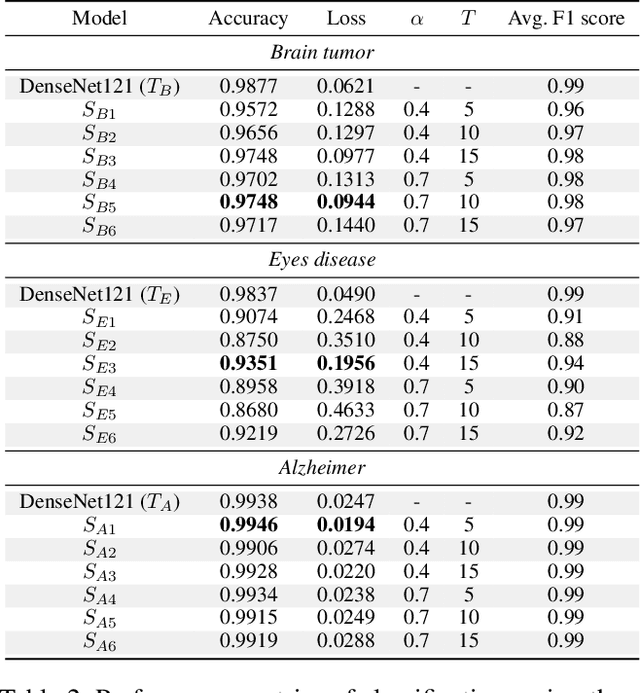
With the rapid development of artificial intelligence (AI), especially in the medical field, the need for its explainability has grown. In medical image analysis, a high degree of transparency and model interpretability can help clinicians better understand and trust the decision-making process of AI models. In this study, we propose a Knowledge Distillation (KD)-based approach that aims to enhance the transparency of the AI model in medical image analysis. The initial step is to use traditional CNN to obtain a teacher model and then use KD to simplify the CNN architecture, retain most of the features of the data set, and reduce the number of network layers. It also uses the feature map of the student model to perform hierarchical analysis to identify key features and decision-making processes. This leads to intuitive visual explanations. We selected three public medical data sets (brain tumor, eye disease, and Alzheimer's disease) to test our method. It shows that even when the number of layers is reduced, our model provides a remarkable result in the test set and reduces the time required for the interpretability analysis.
Disentangling data distribution for Federated Learning
Oct 16, 2024Federated Learning (FL) facilitates collaborative training of a global model whose performance is boosted by private data owned by distributed clients, without compromising data privacy. Yet the wide applicability of FL is hindered by entanglement of data distributions across different clients. This paper demonstrates for the first time that by disentangling data distributions FL can in principle achieve efficiencies comparable to those of distributed systems, requiring only one round of communication. To this end, we propose a novel FedDistr algorithm, which employs stable diffusion models to decouple and recover data distributions. Empirical results on the CIFAR100 and DomainNet datasets show that FedDistr significantly enhances model utility and efficiency in both disentangled and near-disentangled scenarios while ensuring privacy, outperforming traditional federated learning methods.
Unlearning during Learning: An Efficient Federated Machine Unlearning Method
May 24, 2024



In recent years, Federated Learning (FL) has garnered significant attention as a distributed machine learning paradigm. To facilitate the implementation of the right to be forgotten, the concept of federated machine unlearning (FMU) has also emerged. However, current FMU approaches often involve additional time-consuming steps and may not offer comprehensive unlearning capabilities, which renders them less practical in real FL scenarios. In this paper, we introduce FedAU, an innovative and efficient FMU framework aimed at overcoming these limitations. Specifically, FedAU incorporates a lightweight auxiliary unlearning module into the learning process and employs a straightforward linear operation to facilitate unlearning. This approach eliminates the requirement for extra time-consuming steps, rendering it well-suited for FL. Furthermore, FedAU exhibits remarkable versatility. It not only enables multiple clients to carry out unlearning tasks concurrently but also supports unlearning at various levels of granularity, including individual data samples, specific classes, and even at the client level. We conducted extensive experiments on MNIST, CIFAR10, and CIFAR100 datasets to evaluate the performance of FedAU. The results demonstrate that FedAU effectively achieves the desired unlearning effect while maintaining model accuracy.
Federated Domain-Specific Knowledge Transfer on Large Language Models Using Synthetic Data
May 23, 2024As large language models (LLMs) demonstrate unparalleled performance and generalization ability, LLMs are widely used and integrated into various applications. When it comes to sensitive domains, as commonly described in federated learning scenarios, directly using external LLMs on private data is strictly prohibited by stringent data security and privacy regulations. For local clients, the utilization of LLMs to improve the domain-specific small language models (SLMs), characterized by limited computational resources and domain-specific data, has attracted considerable research attention. By observing that LLMs can empower domain-specific SLMs, existing methods predominantly concentrate on leveraging the public data or LLMs to generate more data to transfer knowledge from LLMs to SLMs. However, due to the discrepancies between LLMs' generated data and clients' domain-specific data, these methods cannot yield substantial improvements in the domain-specific tasks. In this paper, we introduce a Federated Domain-specific Knowledge Transfer (FDKT) framework, which enables domain-specific knowledge transfer from LLMs to SLMs while preserving clients' data privacy. The core insight is to leverage LLMs to augment data based on domain-specific few-shot demonstrations, which are synthesized from private domain data using differential privacy. Such synthetic samples share similar data distribution with clients' private data and allow the server LLM to generate particular knowledge to improve clients' SLMs. The extensive experimental results demonstrate that the proposed FDKT framework consistently and greatly improves SLMs' task performance by around 5\% with a privacy budget of less than 10, compared to local training on private data.
A Theoretical Analysis of Efficiency Constrained Utility-Privacy Bi-Objective Optimization in Federated Learning
Dec 27, 2023



Federated learning (FL) enables multiple clients to collaboratively learn a shared model without sharing their individual data. Concerns about utility, privacy, and training efficiency in FL have garnered significant research attention. Differential privacy has emerged as a prevalent technique in FL, safeguarding the privacy of individual user data while impacting utility and training efficiency. Within Differential Privacy Federated Learning (DPFL), previous studies have primarily focused on the utility-privacy trade-off, neglecting training efficiency, which is crucial for timely completion. Moreover, differential privacy achieves privacy by introducing controlled randomness (noise) on selected clients in each communication round. Previous work has mainly examined the impact of noise level ($\sigma$) and communication rounds ($T$) on the privacy-utility dynamic, overlooking other influential factors like the sample ratio ($q$, the proportion of selected clients). This paper systematically formulates an efficiency-constrained utility-privacy bi-objective optimization problem in DPFL, focusing on $\sigma$, $T$, and $q$. We provide a comprehensive theoretical analysis, yielding analytical solutions for the Pareto front. Extensive empirical experiments verify the validity and efficacy of our analysis, offering valuable guidance for low-cost parameter design in DPFL.
3DFill:Reference-guided Image Inpainting by Self-supervised 3D Image Alignment
Nov 09, 2022Most existing image inpainting algorithms are based on a single view, struggling with large holes or the holes containing complicated scenes. Some reference-guided algorithms fill the hole by referring to another viewpoint image and use 2D image alignment. Due to the camera imaging process, simple 2D transformation is difficult to achieve a satisfactory result. In this paper, we propose 3DFill, a simple and efficient method for reference-guided image inpainting. Given a target image with arbitrary hole regions and a reference image from another viewpoint, the 3DFill first aligns the two images by a two-stage method: 3D projection + 2D transformation, which has better results than 2D image alignment. The 3D projection is an overall alignment between images and the 2D transformation is a local alignment focused on the hole region. The entire process of image alignment is self-supervised. We then fill the hole in the target image with the contents of the aligned image. Finally, we use a conditional generation network to refine the filled image to obtain the inpainting result. 3DFill achieves state-of-the-art performance on image inpainting across a variety of wide view shifts and has a faster inference speed than other inpainting models.
Global Spectral Filter Memory Network for Video Object Segmentation
Oct 12, 2022
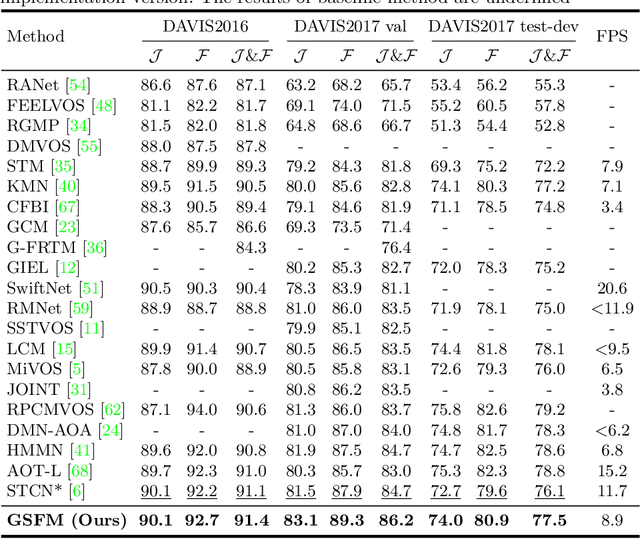

This paper studies semi-supervised video object segmentation through boosting intra-frame interaction. Recent memory network-based methods focus on exploiting inter-frame temporal reference while paying little attention to intra-frame spatial dependency. Specifically, these segmentation model tends to be susceptible to interference from unrelated nontarget objects in a certain frame. To this end, we propose Global Spectral Filter Memory network (GSFM), which improves intra-frame interaction through learning long-term spatial dependencies in the spectral domain. The key components of GSFM is 2D (inverse) discrete Fourier transform for spatial information mixing. Besides, we empirically find low frequency feature should be enhanced in encoder (backbone) while high frequency for decoder (segmentation head). We attribute this to semantic information extracting role for encoder and fine-grained details highlighting role for decoder. Thus, Low (High) Frequency Module is proposed to fit this circumstance. Extensive experiments on the popular DAVIS and YouTube-VOS benchmarks demonstrate that GSFM noticeably outperforms the baseline method and achieves state-of-the-art performance. Besides, extensive analysis shows that the proposed modules are reasonable and of great generalization ability. Our source code is available at https://github.com/workforai/GSFM.
Learning Quality-aware Dynamic Memory for Video Object Segmentation
Jul 16, 2022
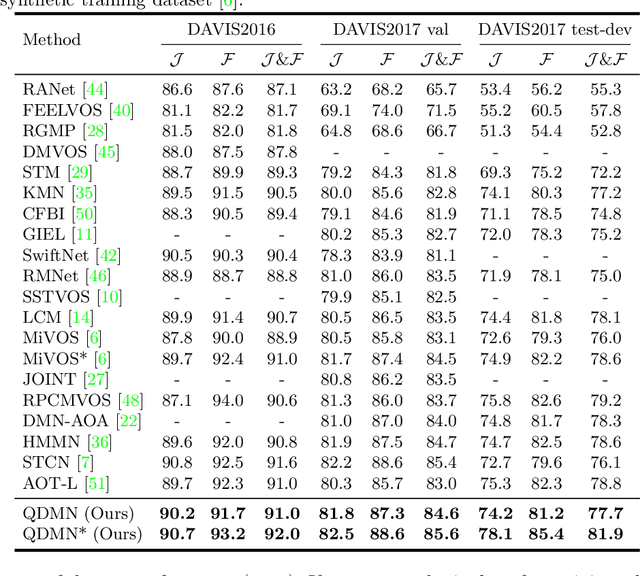
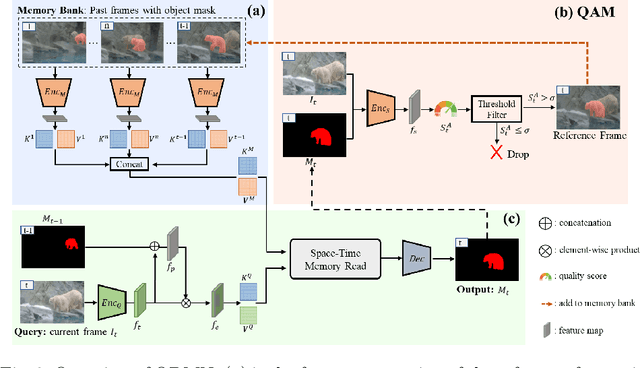
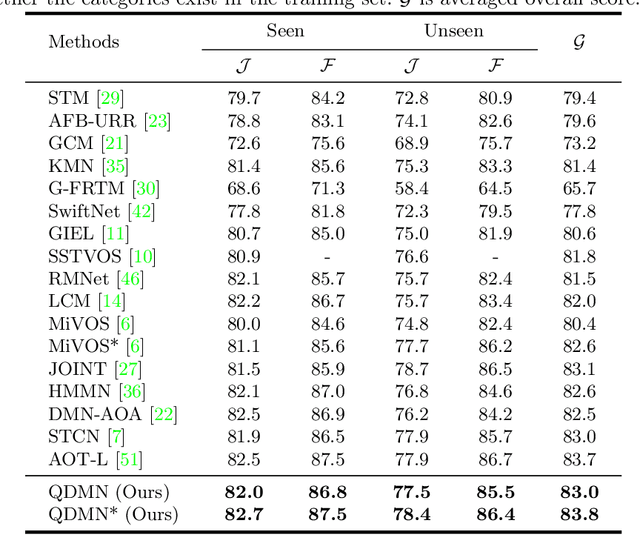
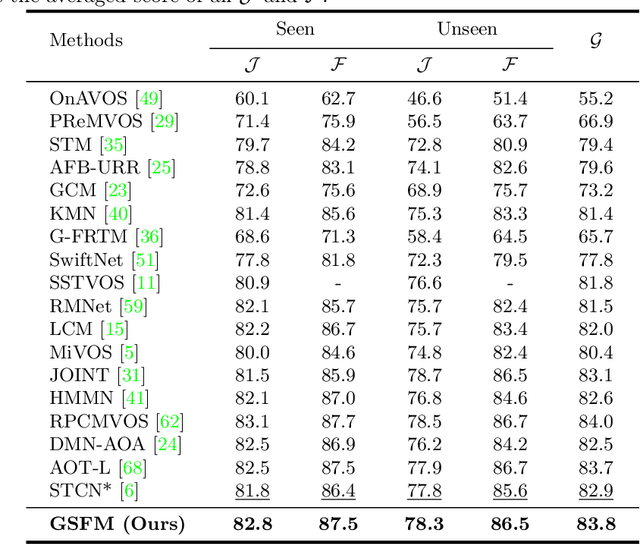
Recently, several spatial-temporal memory-based methods have verified that storing intermediate frames and their masks as memory are helpful to segment target objects in videos. However, they mainly focus on better matching between the current frame and the memory frames without explicitly paying attention to the quality of the memory. Therefore, frames with poor segmentation masks are prone to be memorized, which leads to a segmentation mask error accumulation problem and further affect the segmentation performance. In addition, the linear increase of memory frames with the growth of frame number also limits the ability of the models to handle long videos. To this end, we propose a Quality-aware Dynamic Memory Network (QDMN) to evaluate the segmentation quality of each frame, allowing the memory bank to selectively store accurately segmented frames to prevent the error accumulation problem. Then, we combine the segmentation quality with temporal consistency to dynamically update the memory bank to improve the practicability of the models. Without any bells and whistles, our QDMN achieves new state-of-the-art performance on both DAVIS and YouTube-VOS benchmarks. Moreover, extensive experiments demonstrate that the proposed Quality Assessment Module (QAM) can be applied to memory-based methods as generic plugins and significantly improves performance. Our source code is available at https://github.com/workforai/QDMN.