 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdge-Cloud Polarization and Collaboration: A Comprehensive Survey
Nov 12, 2021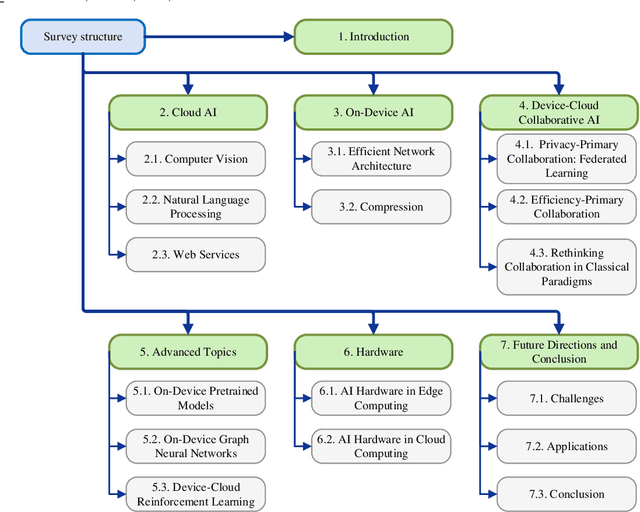
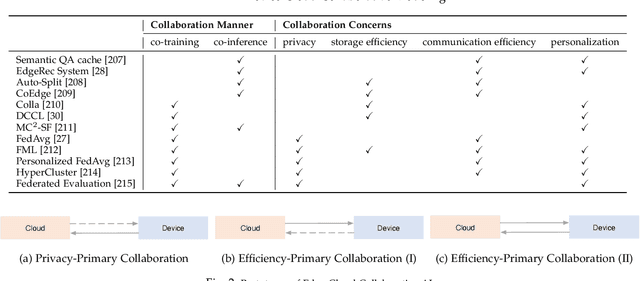
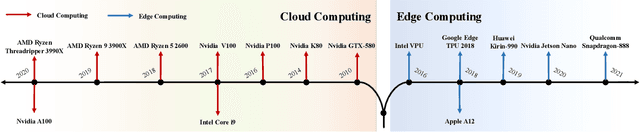
Influenced by the great success of deep learning via cloud computing and the rapid development of edge chips, research in artificial intelligence (AI) has shifted to both of the computing paradigms, i.e., cloud computing and edge computing. In recent years, we have witnessed significant progress in developing more advanced AI models on cloud servers that surpass traditional deep learning models owing to model innovations (e.g., Transformers, Pretrained families), explosion of training data and soaring computing capabilities. However, edge computing, especially edge and cloud collaborative computing, are still in its infancy to announce their success due to the resource-constrained IoT scenarios with very limited algorithms deployed. In this survey, we conduct a systematic review for both cloud and edge AI. Specifically, we are the first to set up the collaborative learning mechanism for cloud and edge modeling with a thorough review of the architectures that enable such mechanism. We also discuss potentials and practical experiences of some on-going advanced edge AI topics including pretraining models, graph neural networks and reinforcement learning. Finally, we discuss the promising directions and challenges in this field.
Amazon SageMaker Model Parallelism: A General and Flexible Framework for Large Model Training
Nov 10, 2021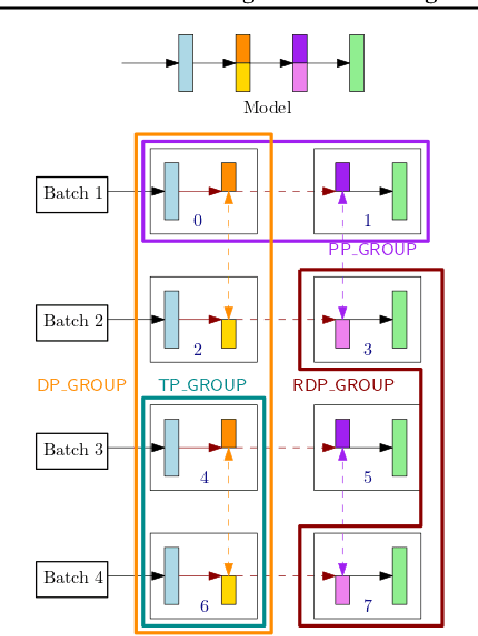
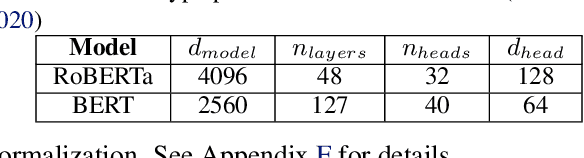
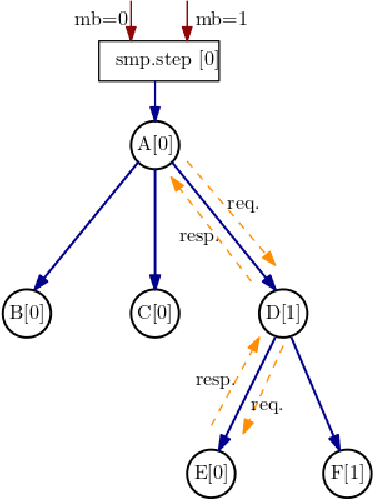

With deep learning models rapidly growing in size, systems-level solutions for large-model training are required. We present Amazon SageMaker model parallelism, a software library that integrates with PyTorch, and enables easy training of large models using model parallelism and other memory-saving features. In contrast to existing solutions, the implementation of the SageMaker library is much more generic and flexible, in that it can automatically partition and run pipeline parallelism over arbitrary model architectures with minimal code change, and also offers a general and extensible framework for tensor parallelism, which supports a wider range of use cases, and is modular enough to be easily applied to new training scripts. The library also preserves the native PyTorch user experience to a much larger degree, supporting module re-use and dynamic graphs, while giving the user full control over the details of the training step. We evaluate performance over GPT-3, RoBERTa, BERT, and neural collaborative filtering, and demonstrate competitive performance over existing solutions.
Unified Group Fairness on Federated Learning
Nov 09, 2021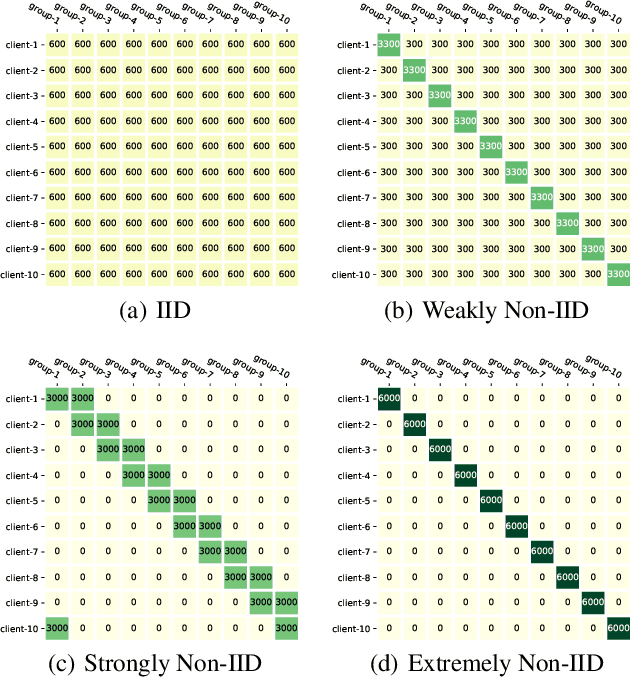
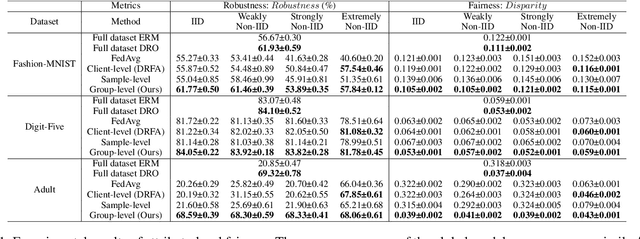
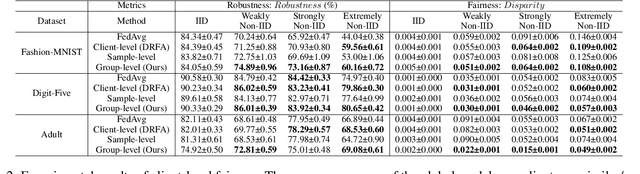
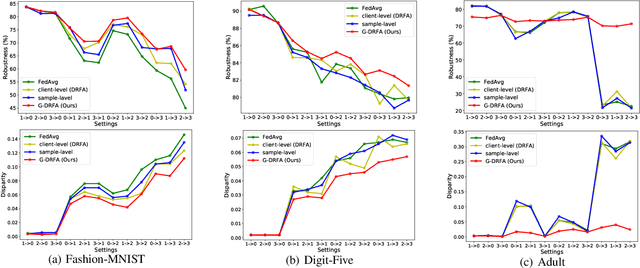
Federated learning (FL) has emerged as an important machine learning paradigm where a global model is trained based on the private data from distributed clients. However, most of existing FL algorithms cannot guarantee the performance fairness towards different clients or different groups of samples because of the distribution shift. Recent researches focus on achieving fairness among clients, but they ignore the fairness towards different groups formed by sensitive attribute(s) (e.g., gender and/or race), which is important and practical in real applications. To bridge this gap, we formulate the goal of unified group fairness on FL which is to learn a fair global model with similar performance on different groups. To achieve the unified group fairness for arbitrary sensitive attribute(s), we propose a novel FL algorithm, named Group Distributionally Robust Federated Averaging (G-DRFA), which mitigates the distribution shift across groups with theoretical analysis of convergence rate. Specifically, we treat the performance of the federated global model at each group as an objective and employ the distributionally robust techniques to maximize the performance of the worst-performing group over an uncertainty set by group reweighting. We validate the advantages of the G-DRFA algorithm with various kinds of distribution shift settings in experiments, and the results show that G-DRFA algorithm outperforms the existing fair federated learning algorithms on unified group fairness.
Dialogue Inspectional Summarization with Factual Inconsistency Awareness
Nov 05, 2021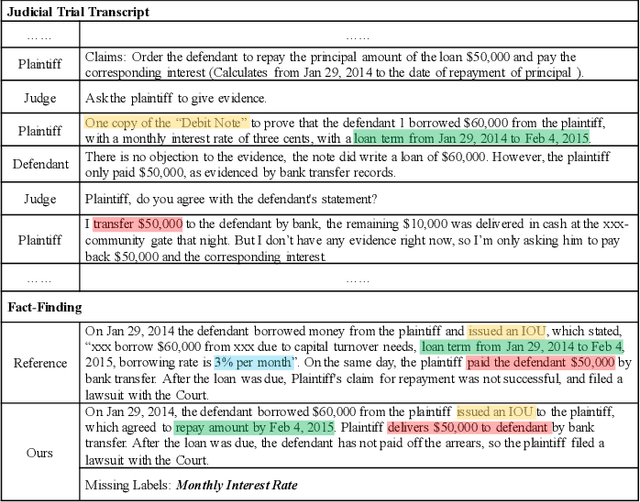
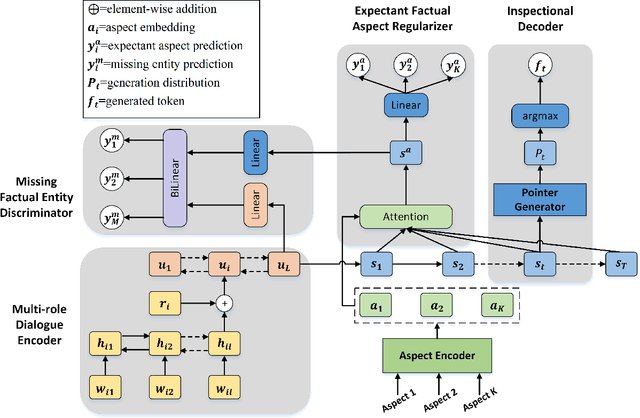
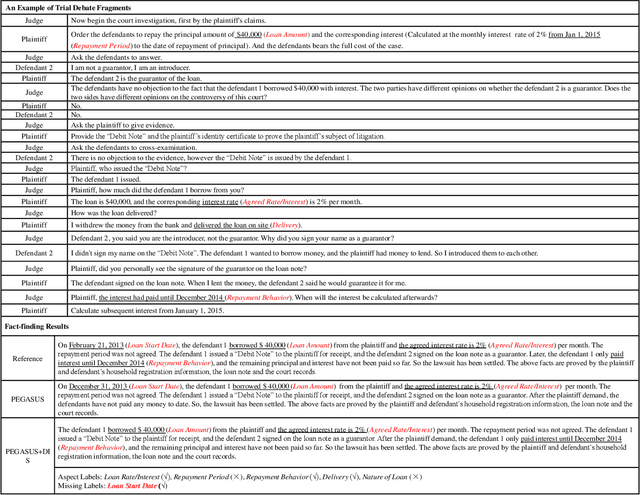
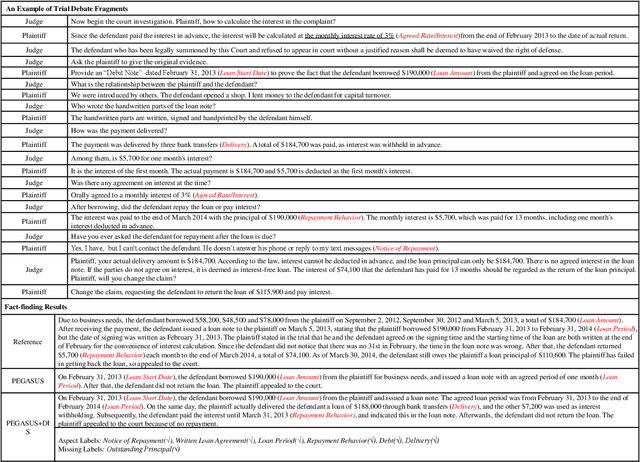
Dialogue summarization has been extensively studied and applied, where the prior works mainly focused on exploring superior model structures to align the input dialogue and the output summary. However, for professional dialogues (e.g., legal debate and medical diagnosis), semantic/statistical alignment can hardly fill the logical/factual gap between input dialogue discourse and summary output with external knowledge. In this paper, we mainly investigate the factual inconsistency problem for Dialogue Inspectional Summarization (DIS) under non-pretraining and pretraining settings. An innovative end-to-end dialogue summary generation framework is proposed with two auxiliary tasks: Expectant Factual Aspect Regularization (EFAR) and Missing Factual Entity Discrimination (MFED). Comprehensive experiments demonstrate that the proposed model can generate a more readable summary with accurate coverage of factual aspects as well as informing the user with potential missing facts detected from the input dialogue for further human intervention.
GNN-LM: Language Modeling based on Global Contexts via GNN
Oct 17, 2021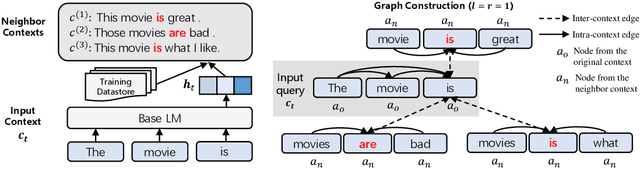
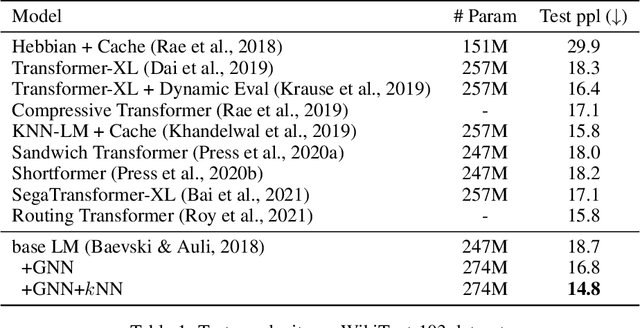
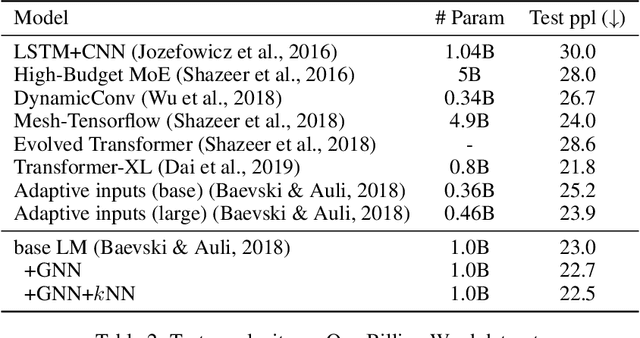
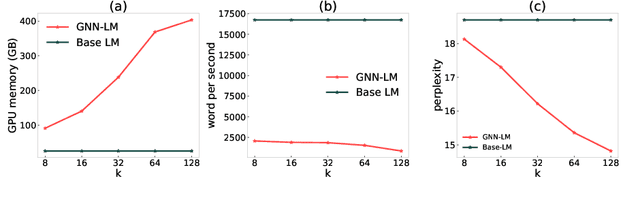
Inspired by the notion that ``{\it to copy is easier than to memorize}``, in this work, we introduce GNN-LM, which extends the vanilla neural language model (LM) by allowing to reference similar contexts in the entire training corpus. We build a directed heterogeneous graph between an input context and its semantically related neighbors selected from the training corpus, where nodes are tokens in the input context and retrieved neighbor contexts, and edges represent connections between nodes. Graph neural networks (GNNs) are constructed upon the graph to aggregate information from similar contexts to decode the token. This learning paradigm provides direct access to the reference contexts and helps improve a model's generalization ability. We conduct comprehensive experiments to validate the effectiveness of the GNN-LM: GNN-LM achieves a new state-of-the-art perplexity of 14.8 on WikiText-103 (a 4.5 point improvement over its counterpart of the vanilla LM model) and shows substantial improvement on One Billion Word and Enwiki8 datasets against strong baselines. In-depth ablation studies are performed to understand the mechanics of GNN-LM.
Do We Need to Directly Access the Source Datasets for Domain Generalization?
Oct 15, 2021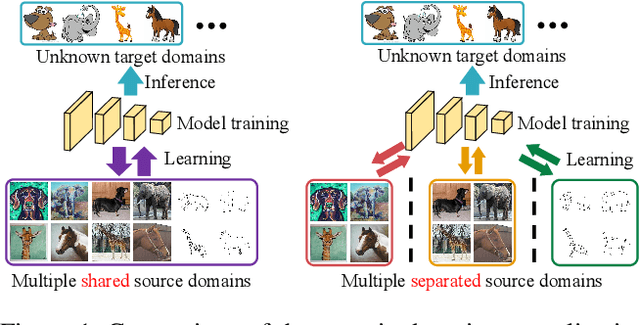
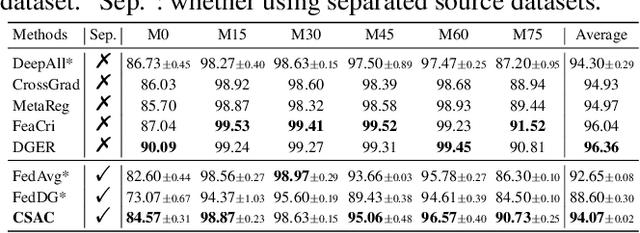
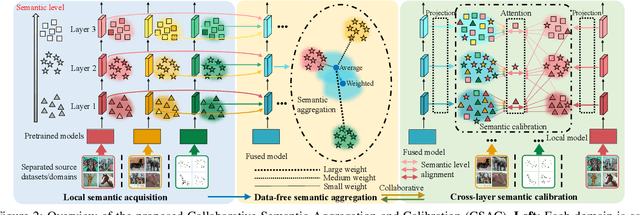
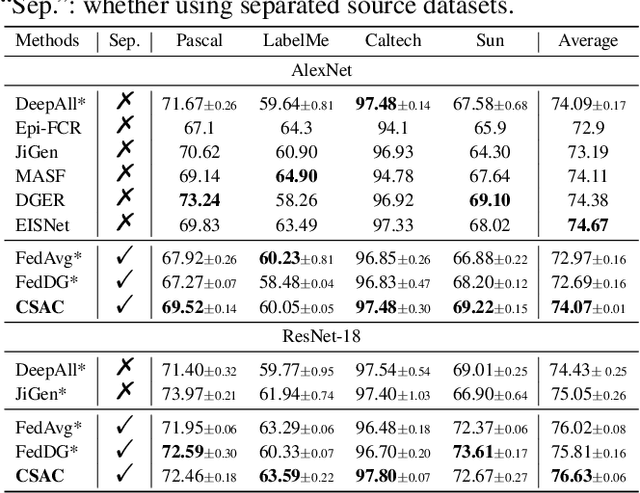
Domain generalization (DG) aims to learn a generalizable model from multiple known source domains for unknown target domains. Tremendous data distributed across lots of places/devices nowadays that can not be directly accessed due to privacy protection, especially in some crucial areas like finance and medical care. However, most of the existing DG algorithms assume that all the source datasets are accessible and can be mixed for domain-invariant semantics extraction, which may fail in real-world applications. In this paper, we introduce a challenging setting of training a generalizable model by using distributed source datasets without directly accessing them. We propose a novel method for this setting, which first trains a model on each source dataset and then conduct data-free model fusion that fuses the trained models layer-by-layer based on their semantic similarities, which aggregates different levels of semantics from the distributed sources indirectly. The fused model is then transmitted and trained on each dataset, we further introduce cross-layer semantic calibration for domain-invariant semantics enhancement, which aligns feature maps between the fused model and a fixed local model with an attention mechanism. Extensive experiments on multiple DG datasets show the significant performance of our method in tackling this challenging setting, which is even on par or superior to the performance of the state-of-the-art DG approaches in the standard DG setting.
Multi-trends Enhanced Dynamic Micro-video Recommendation
Oct 08, 2021
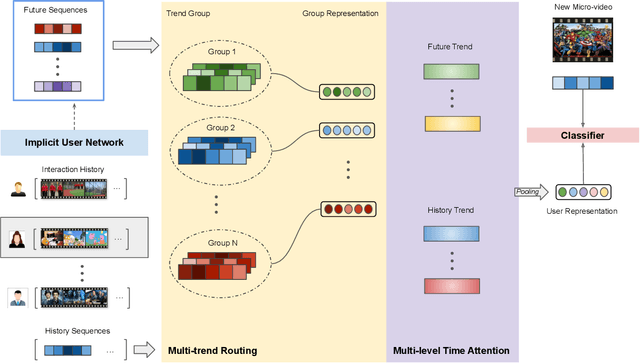

The explosively generated micro-videos on content sharing platforms call for recommender systems to permit personalized micro-video discovery with ease. Recent advances in micro-video recommendation have achieved remarkable performance in mining users' current preference based on historical behaviors. However, most of them neglect the dynamic and time-evolving nature of users' preference, and the prediction on future micro-videos with historically mined preference may deteriorate the effectiveness of recommender systems. In this paper, we propose the DMR framework to explicitly model dynamic multi-trends of users' current preference and make predictions based on both the history and future potential trends. We devise the DMR framework, which comprises: 1) the implicit user network module which identifies sequence fragments from other users with similar interests and extracts the sequence fragments that are chronologically behind the identified fragments; 2) the multi-trend routing module which assigns each extracted sequence fragment into a trend group and update the corresponding trend vector; 3) the history-future trend prediction module jointly uses the history preference vectors and future trend vectors to yield the final click-through-rate. We validate the effectiveness of DMR over multiple state-of-the-art micro-video recommenders on two publicly available real-world datasets. Relatively extensive analysis further demonstrate the superiority of modeling dynamic multi-trend for micro-video recommendation.
Stable Prediction on Graphs with Agnostic Distribution Shift
Oct 08, 2021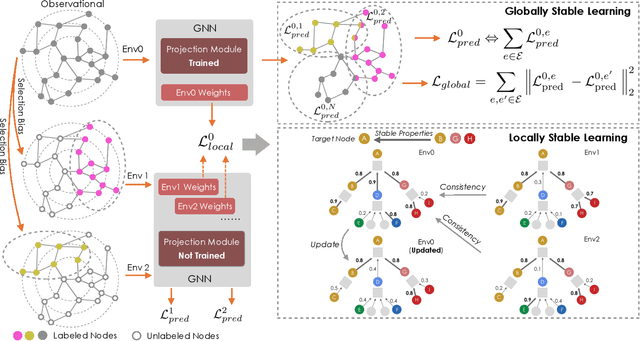
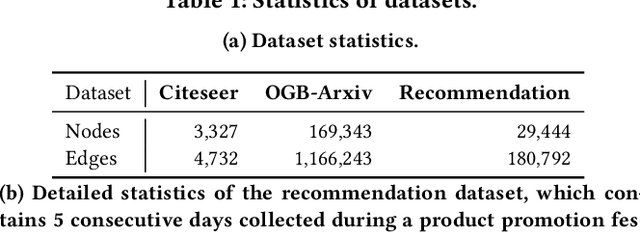
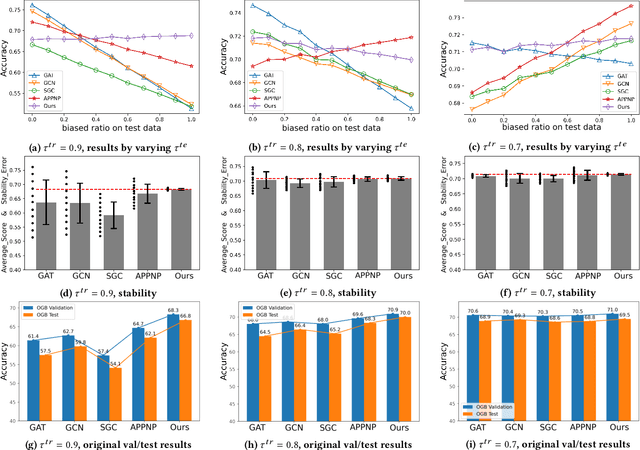
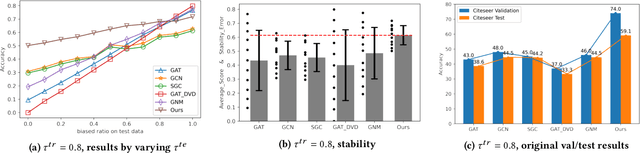
Graph is a flexible and effective tool to represent complex structures in practice and graph neural networks (GNNs) have been shown to be effective on various graph tasks with randomly separated training and testing data. In real applications, however, the distribution of training graph might be different from that of the test one (e.g., users' interactions on the user-item training graph and their actual preference on items, i.e., testing environment, are known to have inconsistencies in recommender systems). Moreover, the distribution of test data is always agnostic when GNNs are trained. Hence, we are facing the agnostic distribution shift between training and testing on graph learning, which would lead to unstable inference of traditional GNNs across different test environments. To address this problem, we propose a novel stable prediction framework for GNNs, which permits both locally and globally stable learning and prediction on graphs. In particular, since each node is partially represented by its neighbors in GNNs, we propose to capture the stable properties for each node (locally stable) by re-weighting the information propagation/aggregation processes. For global stability, we propose a stable regularizer that reduces the training losses on heterogeneous environments and thus warping the GNNs to generalize well. We conduct extensive experiments on several graph benchmarks and a noisy industrial recommendation dataset that is collected from 5 consecutive days during a product promotion festival. The results demonstrate that our method outperforms various SOTA GNNs for stable prediction on graphs with agnostic distribution shift, including shift caused by node labels and attributes.
Domain-Specific Bias Filtering for Single Labeled Domain Generalization
Oct 02, 2021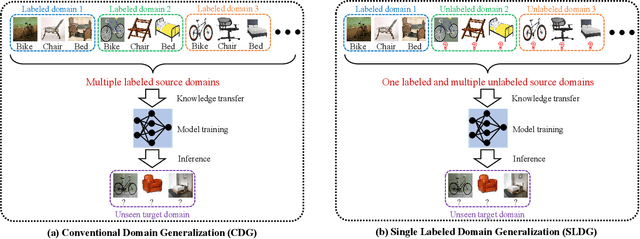
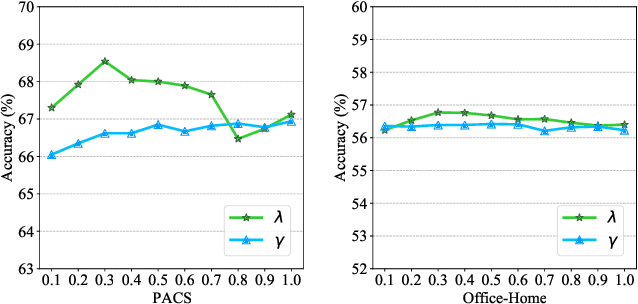
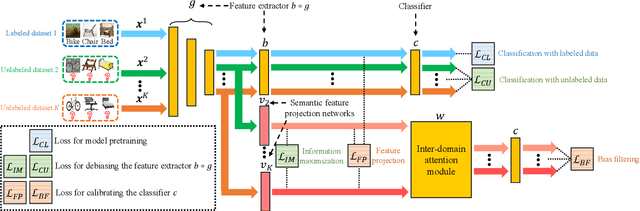
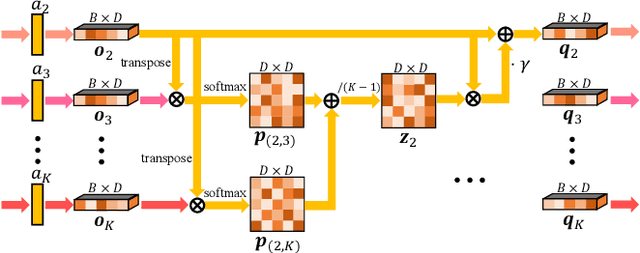
Domain generalization (DG) utilizes multiple labeled source datasets to train a generalizable model for unseen target domains. However, due to expensive annotation costs, the requirements of labeling all the source data are hard to be met in real-world applications. In this paper, we investigate a Single Labeled Domain Generalization (SLDG) task with only one source domain being labeled, which is more practical and challenging than the Conventional Domain Generalization (CDG). A major obstacle in the SLDG task is the discriminability-generalization bias: discriminative information in the labeled source dataset may contain domain-specific bias, constraining the generalization of the trained model. To tackle this challenging task, we propose a novel method called Domain-Specific Bias Filtering (DSBF), which initializes a discriminative model with the labeled source data and filters out its domain-specific bias with the unlabeled source data for generalization improvement. We divide the filtering process into: (1) Feature extractor debiasing using k-means clustering-based semantic feature re-extraction; and (2) Classifier calibrating using attention-guided semantic feature projection. DSBF unifies the exploration of the labeled and the unlabeled source data to enhance the discriminability and generalization of the trained model, resulting in a highly generalizable model. We further provide theoretical analysis to verify the proposed domain-specific bias filtering process. Extensive experiments on multiple datasets show the superior performance of DSBF in tackling both the challenging SLDG task and the CDG task.
Why Do We Click: Visual Impression-aware News Recommendation
Sep 26, 2021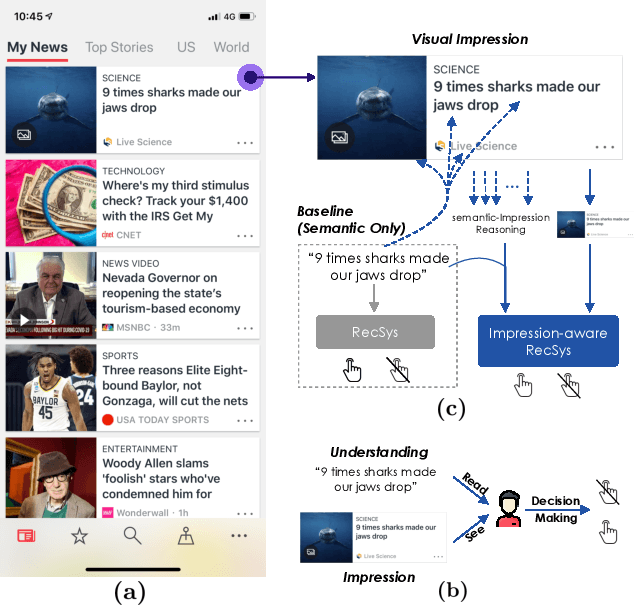
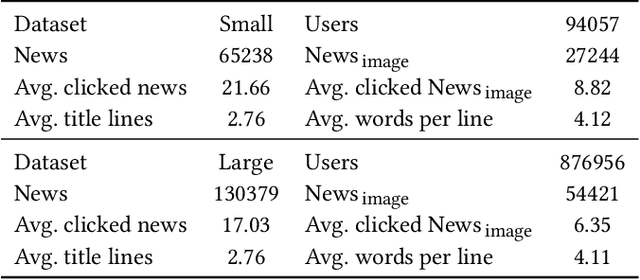
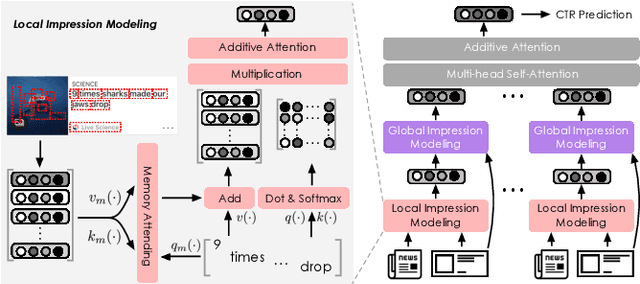
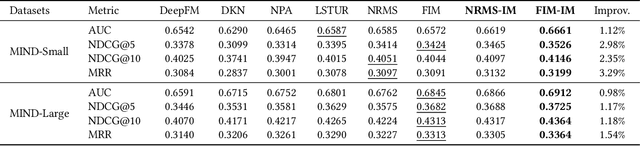
There is a soaring interest in the news recommendation research scenario due to the information overload. To accurately capture users' interests, we propose to model multi-modal features, in addition to the news titles that are widely used in existing works, for news recommendation. Besides, existing research pays little attention to the click decision-making process in designing multi-modal modeling modules. In this work, inspired by the fact that users make their click decisions mostly based on the visual impression they perceive when browsing news, we propose to capture such visual impression information with visual-semantic modeling for news recommendation. Specifically, we devise the local impression modeling module to simultaneously attend to decomposed details in the impression when understanding the semantic meaning of news title, which could explicitly get close to the process of users reading news. In addition, we inspect the impression from a global view and take structural information, such as the arrangement of different fields and spatial position of different words on the impression, into the modeling of multiple modalities. To accommodate the research of visual impression-aware news recommendation, we extend the text-dominated news recommendation dataset MIND by adding snapshot impression images and will release it to nourish the research field. Extensive comparisons with the state-of-the-art news recommenders along with the in-depth analyses demonstrate the effectiveness of the proposed method and the promising capability of modeling visual impressions for the content-based recommenders.