Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Video Scene Text Spotting: Unifying Detection, Tracking, and Recognition
Paper and Code



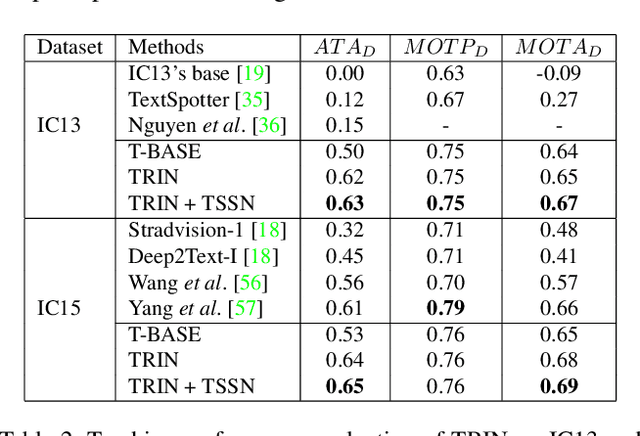
This paper proposes an unified framework for efficiently spotting scene text in videos. The method localizes and tracks text in each frame, and recognizes each tracked text stream one-time. Specifically, we first train a spatial-temporal text detector for localizing text regions in the sequential frames. Secondly, a well-designed text tracker is trained for grouping the localized text regions into corresponding cropped text streams. To efficiently spot video text, we recognize each tracked text stream one-time with a text region quality scoring mechanism instead of identifying the cropped text regions one-by-one. Experiments on two public benchmarks demonstrate that our method achieves impressive performance.
View paper on