 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhisper-MLA: Reducing GPU Memory Consumption of ASR Models based on MHA2MLA Conversion
Feb 28, 2026The Transformer-based Whisper model has achieved state-of-the-art performance in Automatic Speech Recognition (ASR). However, its Multi-Head Attention (MHA) mechanism results in significant GPU memory consumption due to the linearly growing Key-Value (KV) cache usage, which is problematic for many applications especially with long-form audio. To address this, we introduce Whisper-MLA, a novel architecture that incorporates Multi-Head Latent Attention (MLA) into the Whisper model. Specifically, we adapt MLA for Whisper's absolute positional embeddings and systematically investigate its application across encoder self-attention, decoder self-attention, and cross-attention modules. Empirical results indicate that applying MLA exclusively to decoder self-attention yields the desired balance between performance and memory efficiency. Our proposed approach allows conversion of a pretrained Whisper model to Whisper-MLA with minimal fine-tuning. Extensive experiments on the LibriSpeech benchmark validate the effectiveness of this conversion, demonstrating that Whisper-MLA reduces the KV cache size by up to 87.5% while maintaining competitive accuracy.
Talk Less, Verify More: Improving LLM Assistants with Semantic Checks and Execution Feedback
Jan 07, 2026As large language model (LLM) assistants become increasingly integrated into enterprise workflows, their ability to generate accurate, semantically aligned, and executable outputs is critical. However, current conversational business analytics (CBA) systems often lack built-in verification mechanisms, leaving users to manually validate potentially flawed results. This paper introduces two complementary verification techniques: Q*, which performs reverse translation and semantic matching between code and user intent, and Feedback+, which incorporates execution feedback to guide code refinement. Embedded within a generator-discriminator framework, these mechanisms shift validation responsibilities from users to the system. Evaluations on three benchmark datasets, Spider, Bird, and GSM8K, demonstrate that both Q* and Feedback+ reduce error rates and task completion time. The study also identifies reverse translation as a key bottleneck, highlighting opportunities for future improvement. Overall, this work contributes a design-oriented framework for building more reliable, enterprise-grade GenAI systems capable of trustworthy decision support.
LOOPRAG: Enhancing Loop Transformation Optimization with Retrieval-Augmented Large Language Models
Dec 12, 2025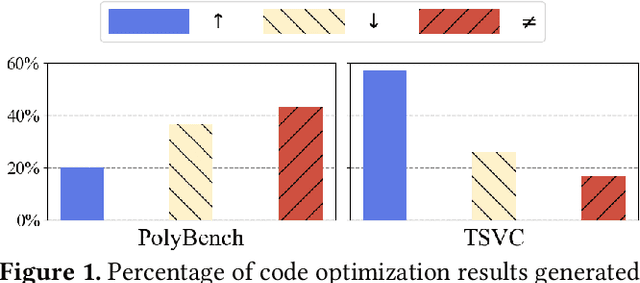
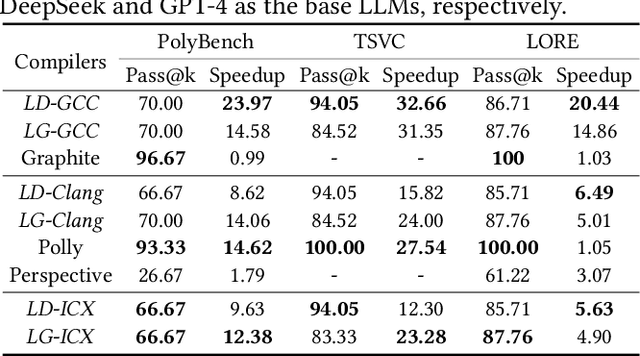

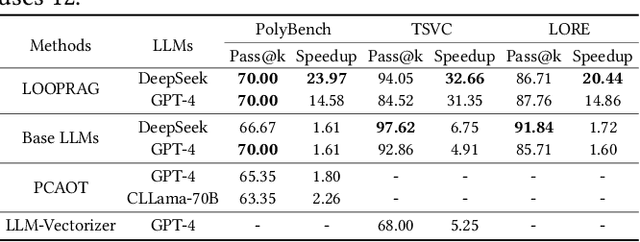
Loop transformations are semantics-preserving optimization techniques, widely used to maximize objectives such as parallelism. Despite decades of research, applying the optimal composition of loop transformations remains challenging due to inherent complexities, including cost modeling for optimization objectives. Recent studies have explored the potential of Large Language Models (LLMs) for code optimization. However, our key observation is that LLMs often struggle with effective loop transformation optimization, frequently leading to errors or suboptimal optimization, thereby missing opportunities for performance improvements. To bridge this gap, we propose LOOPRAG, a novel retrieval-augmented generation framework designed to guide LLMs in performing effective loop optimization on Static Control Part. We introduce a parameter-driven method to harness loop properties, which trigger various loop transformations, and generate diverse yet legal example codes serving as a demonstration source. To effectively obtain the most informative demonstrations, we propose a loop-aware algorithm based on loop features, which balances similarity and diversity for code retrieval. To enhance correct and efficient code generation, we introduce a feedback-based iterative mechanism that incorporates compilation, testing and performance results as feedback to guide LLMs. Each optimized code undergoes mutation, coverage and differential testing for equivalence checking. We evaluate LOOPRAG on PolyBench, TSVC and LORE benchmark suites, and compare it against compilers (GCC-Graphite, Clang-Polly, Perspective and ICX) and representative LLMs (DeepSeek and GPT-4). The results demonstrate average speedups over base compilers of up to 11.20$\times$, 14.34$\times$, and 9.29$\times$ for PolyBench, TSVC, and LORE, respectively, and speedups over base LLMs of up to 11.97$\times$, 5.61$\times$, and 11.59$\times$.
Learning linear acyclic causal model including Gaussian noise using ancestral relationships
Aug 31, 2024



This paper discusses algorithms for learning causal DAGs. The PC algorithm makes no assumptions other than the faithfulness to the causal model and can identify only up to the Markov equivalence class. LiNGAM assumes linearity and continuous non-Gaussian disturbances for the causal model, and the causal DAG defining LiNGAM is shown to be fully identifiable. The PC-LiNGAM, a hybrid of the PC algorithm and LiNGAM, can identify up to the distribution-equivalence pattern of a linear causal model, even in the presence of Gaussian disturbances. However, in the worst case, the PC-LiNGAM has factorial time complexity for the number of variables. In this paper, we propose an algorithm for learning the distribution-equivalence patterns of a linear causal model with a lower time complexity than PC-LiNGAM, using the causal ancestor finding algorithm in Maeda and Shimizu, which is generalized to account for Gaussian disturbances.
Learning causal graphs using variable grouping according to ancestral relationship
Mar 21, 2024Several causal discovery algorithms have been proposed. However, when the sample size is small relative to the number of variables, the accuracy of estimating causal graphs using existing methods decreases. And some methods are not feasible when the sample size is smaller than the number of variables. To circumvent these problems, some researchers proposed causal structure learning algorithms using divide-and-conquer approaches. For learning the entire causal graph, the approaches first split variables into several subsets according to the conditional independence relationships among the variables, then apply a conventional causal discovery algorithm to each subset and merge the estimated results. Since the divide-and-conquer approach reduces the number of variables to which a causal structure learning algorithm is applied, it is expected to improve the estimation accuracy of causal graphs, especially when the sample size is small relative to the number of variables and the model is sparse. However, existing methods are either computationally expensive or do not provide sufficient accuracy when the sample size is small. This paper proposes a new algorithm for grouping variables based the ancestral relationships among the variables, under the LiNGAM assumption, where the causal relationships are linear, and the mutually independent noise are distributed as continuous non-Gaussian distributions. We call the proposed algorithm CAG. The time complexity of the ancestor finding in CAG is shown to be cubic to the number of variables. Extensive computer experiments confirm that the proposed method outperforms the original DirectLiNGAM without grouping variables and other divide-and-conquer approaches not only in estimation accuracy but also in computation time when the sample size is small relative to the number of variables and the model is sparse.
From Graph to Word Bag: Introducing Domain Knowledge to Confusing Charge Prediction
Mar 14, 2024



Confusing charge prediction is a challenging task in legal AI, which involves predicting confusing charges based on fact descriptions. While existing charge prediction methods have shown impressive performance, they face significant challenges when dealing with confusing charges, such as Snatch and Robbery. In the legal domain, constituent elements play a pivotal role in distinguishing confusing charges. Constituent elements are fundamental behaviors underlying criminal punishment and have subtle distinctions among charges. In this paper, we introduce a novel From Graph to Word Bag (FWGB) approach, which introduces domain knowledge regarding constituent elements to guide the model in making judgments on confusing charges, much like a judge's reasoning process. Specifically, we first construct a legal knowledge graph containing constituent elements to help select keywords for each charge, forming a word bag. Subsequently, to guide the model's attention towards the differentiating information for each charge within the context, we expand the attention mechanism and introduce a new loss function with attention supervision through words in the word bag. We construct the confusing charges dataset from real-world judicial documents. Experiments demonstrate the effectiveness of our method, especially in maintaining exceptional performance in imbalanced label distributions.
Enhancing Court View Generation with Knowledge Injection and Guidance
Mar 07, 2024



Court View Generation (CVG) is a challenging task in the field of Legal Artificial Intelligence (LegalAI), which aims to generate court views based on the plaintiff claims and the fact descriptions. While Pretrained Language Models (PLMs) have showcased their prowess in natural language generation, their application to the complex, knowledge-intensive domain of CVG often reveals inherent limitations. In this paper, we present a novel approach, named Knowledge Injection and Guidance (KIG), designed to bolster CVG using PLMs. To efficiently incorporate domain knowledge during the training stage, we introduce a knowledge-injected prompt encoder for prompt tuning, thereby reducing computational overhead. Moreover, to further enhance the model's ability to utilize domain knowledge, we employ a generating navigator, which dynamically guides the text generation process in the inference stage without altering the model's architecture, making it readily transferable. Comprehensive experiments on real-world data demonstrate the effectiveness of our approach compared to several established baselines, especially in the responsivity of claims, where it outperforms the best baseline by 11.87%.
Enhancing Language Representation with Constructional Information for Natural Language Understanding
Jun 05, 2023



Natural language understanding (NLU) is an essential branch of natural language processing, which relies on representations generated by pre-trained language models (PLMs). However, PLMs primarily focus on acquiring lexico-semantic information, while they may be unable to adequately handle the meaning of constructions. To address this issue, we introduce construction grammar (CxG), which highlights the pairings of form and meaning, to enrich language representation. We adopt usage-based construction grammar as the basis of our work, which is highly compatible with statistical models such as PLMs. Then a HyCxG framework is proposed to enhance language representation through a three-stage solution. First, all constructions are extracted from sentences via a slot-constraints approach. As constructions can overlap with each other, bringing redundancy and imbalance, we formulate the conditional max coverage problem for selecting the discriminative constructions. Finally, we propose a relational hypergraph attention network to acquire representation from constructional information by capturing high-order word interactions among constructions. Extensive experiments demonstrate the superiority of the proposed model on a variety of NLU tasks.
Learn from Structural Scope: Improving Aspect-Level Sentiment Analysis with Hybrid Graph Convolutional Networks
Apr 27, 2022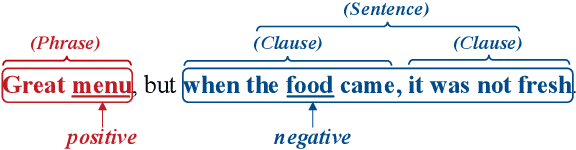
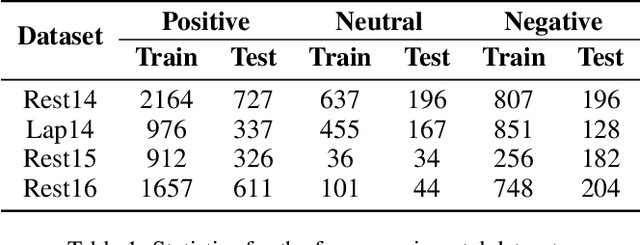
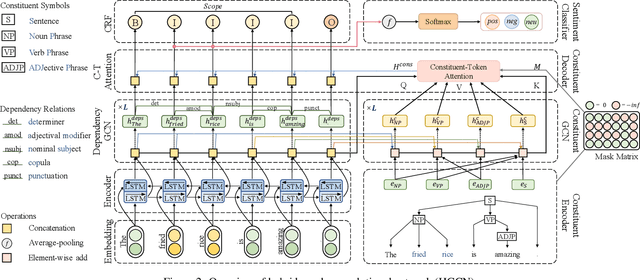
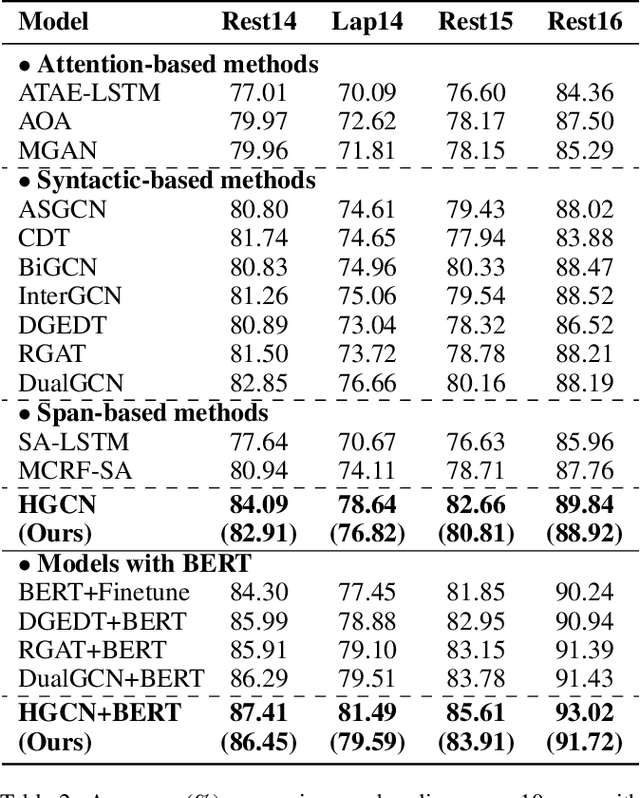
Aspect-level sentiment analysis aims to determine the sentiment polarity towards a specific target in a sentence. The main challenge of this task is to effectively model the relation between targets and sentiments so as to filter out noisy opinion words from irrelevant targets. Most recent efforts capture relations through target-sentiment pairs or opinion spans from a word-level or phrase-level perspective. Based on the observation that targets and sentiments essentially establish relations following the grammatical hierarchy of phrase-clause-sentence structure, it is hopeful to exploit comprehensive syntactic information for better guiding the learning process. Therefore, we introduce the concept of Scope, which outlines a structural text region related to a specific target. To jointly learn structural Scope and predict the sentiment polarity, we propose a hybrid graph convolutional network (HGCN) to synthesize information from constituency tree and dependency tree, exploring the potential of linking two syntax parsing methods to enrich the representation. Experimental results on four public datasets illustrate that our HGCN model outperforms current state-of-the-art baselines.
Graph-based Pyramid Global Context Reasoning with a Saliency-aware Projection for COVID-19 Lung Infections Segmentation
Mar 07, 2021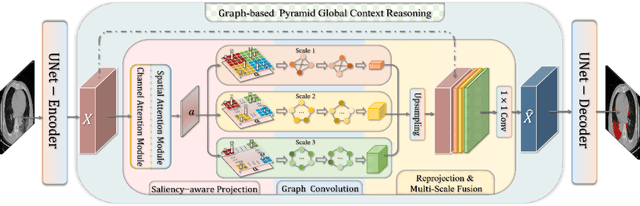
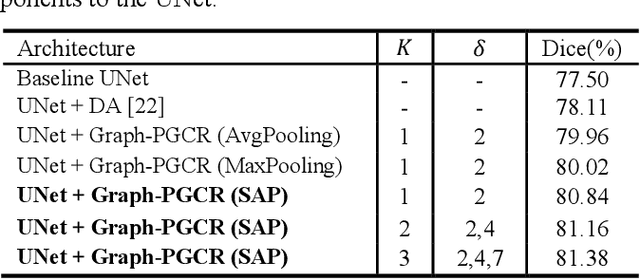
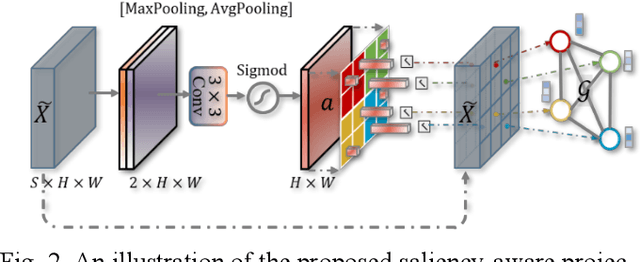
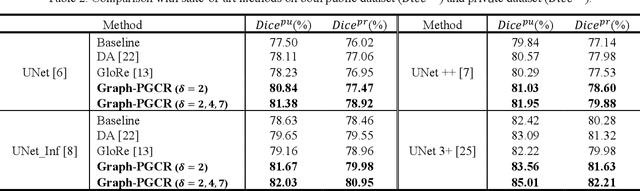
Coronavirus Disease 2019 (COVID-19) has rapidly spread in 2020, emerging a mass of studies for lung infection segmentation from CT images. Though many methods have been proposed for this issue, it is a challenging task because of infections of various size appearing in different lobe zones. To tackle these issues, we propose a Graph-based Pyramid Global Context Reasoning (Graph-PGCR) module, which is capable of modeling long-range dependencies among disjoint infections as well as adapt size variation. We first incorporate graph convolution to exploit long-term contextual information from multiple lobe zones. Different from previous average pooling or maximum object probability, we propose a saliency-aware projection mechanism to pick up infection-related pixels as a set of graph nodes. After graph reasoning, the relation-aware features are reversed back to the original coordinate space for the down-stream tasks. We further construct multiple graphs with different sampling rates to handle the size variation problem. To this end, distinct multi-scale long-range contextual patterns can be captured. Our Graph-PGCR module is plug-and-play, which can be integrated into any architecture to improve its performance. Experiments demonstrated that the proposed method consistently boost the performance of state-of-the-art backbone architectures on both of public and our private COVID-19 datasets.