 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttentive Sequence to Sequence Translation for Localizing Clips of Interest by Natural Language Descriptions
Paper and Code

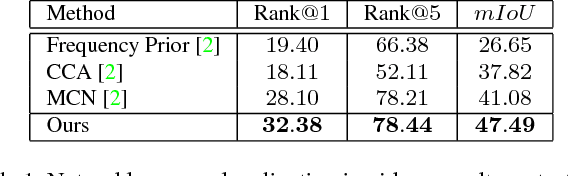
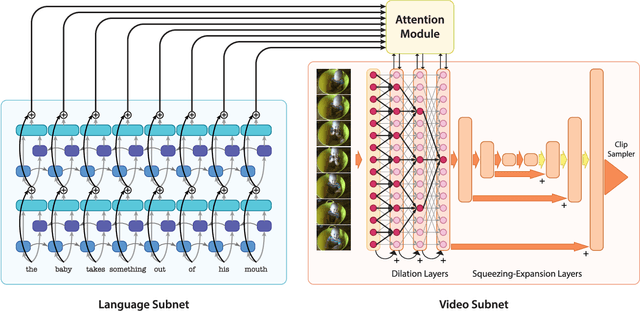
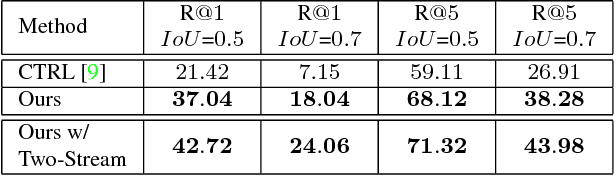
We propose a novel attentive sequence to sequence translator (ASST) for clip localization in videos by natural language descriptions. We make two contributions. First, we propose a bi-directional Recurrent Neural Network (RNN) with a finely calibrated vision-language attentive mechanism to comprehensively understand the free-formed natural language descriptions. The RNN parses natural language descriptions in two directions, and the attentive model attends every meaningful word or phrase to each frame, thereby resulting in a more detailed understanding of video content and description semantics. Second, we design a hierarchical architecture for the network to jointly model language descriptions and video content. Given a video-description pair, the network generates a matrix representation, i.e., a sequence of vectors. Each vector in the matrix represents a video frame conditioned by the description. The 2D representation not only preserves the temporal dependencies of frames but also provides an effective way to perform frame-level video-language matching. The hierarchical architecture exploits video content with multiple granularities, ranging from subtle details to global context. Integration of the multiple granularities yields a robust representation for multi-level video-language abstraction. We validate the effectiveness of our ASST on two large-scale datasets. Our ASST outperforms the state-of-the-art by $4.28\%$ in Rank$@1$ on the DiDeMo dataset. On the Charades-STA dataset, we significantly improve the state-of-the-art by $13.41\%$ in Rank$@1,IoU=0.5$.