 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMER 2023: Multi-label Learning, Modality Robustness, and Semi-Supervised Learning
Apr 18, 2023



Over the past few decades, multimodal emotion recognition has made remarkable progress with the development of deep learning. However, existing technologies are difficult to meet the demand for practical applications. To improve the robustness, we launch a Multimodal Emotion Recognition Challenge (MER 2023) to motivate global researchers to build innovative technologies that can further accelerate and foster research. For this year's challenge, we present three distinct sub-challenges: (1) MER-MULTI, in which participants recognize both discrete and dimensional emotions; (2) MER-NOISE, in which noise is added to test videos for modality robustness evaluation; (3) MER-SEMI, which provides large amounts of unlabeled samples for semi-supervised learning. In this paper, we test a variety of multimodal features and provide a competitive baseline for each sub-challenge. Our system achieves 77.57% on the F1 score and 0.82 on the mean squared error (MSE) for MER-MULTI, 69.82% on the F1 score and 1.12 on MSE for MER-NOISE, and 86.75% on the F1 score for MER-SEMI, respectively. Baseline code is available at https://github.com/zeroQiaoba/MER2023-Baseline.
Logical Reasoning over Natural Language as Knowledge Representation: A Survey
Mar 21, 2023



Logical reasoning is central to human cognition and intelligence. Past research of logical reasoning within AI uses formal language as knowledge representation~(and symbolic reasoners). However, reasoning with formal language has proved challenging~(e.g., brittleness and knowledge-acquisition bottleneck). This paper provides a comprehensive overview on a new paradigm of logical reasoning, which uses natural language as knowledge representation~(and pretrained language models as reasoners), including philosophical definition and categorization of logical reasoning, advantages of the new paradigm, benchmarks and methods, challenges of the new paradigm, desirable tasks & methods in the future, and relation to related NLP fields. This new paradigm is promising since it not only alleviates many challenges of formal representation but also has advantages over end-to-end neural methods.
FinXABSA: Explainable Finance through Aspect-Based Sentiment Analysis
Mar 16, 2023



This paper presents a novel approach for explainability in financial analysis by utilizing the Pearson correlation coefficient to establish a relationship between aspect-based sentiment analysis and stock prices. The proposed methodology involves constructing an aspect list from financial news articles and analyzing sentiment intensity scores for each aspect. These scores are then compared to the stock prices for the relevant companies using the Pearson coefficient to determine any significant correlations. The results indicate that the proposed approach provides a more detailed and accurate understanding of the relationship between sentiment analysis and stock prices, which can be useful for investors and financial analysts in making informed decisions. Additionally, this methodology offers a transparent and interpretable way to explain the sentiment analysis results and their impact on stock prices. Overall, the findings of this paper demonstrate the importance of explainability in financial analysis and highlight the potential benefits of utilizing the Pearson coefficient for analyzing aspect-based sentiment analysis and stock prices. The proposed approach offers a valuable tool for understanding the complex relationships between financial news sentiment and stock prices, providing a new perspective on the financial market and aiding in making informed investment decisions.
Adaptive Knowledge Distillation between Text and Speech Pre-trained Models
Mar 07, 2023Learning on a massive amount of speech corpus leads to the recent success of many self-supervised speech models. With knowledge distillation, these models may also benefit from the knowledge encoded by language models that are pre-trained on rich sources of texts. The distillation process, however, is challenging due to the modal disparity between textual and speech embedding spaces. This paper studies metric-based distillation to align the embedding space of text and speech with only a small amount of data without modifying the model structure. Since the semantic and granularity gap between text and speech has been omitted in literature, which impairs the distillation, we propose the Prior-informed Adaptive knowledge Distillation (PAD) that adaptively leverages text/speech units of variable granularity and prior distributions to achieve better global and local alignments between text and speech pre-trained models. We evaluate on three spoken language understanding benchmarks to show that PAD is more effective in transferring linguistic knowledge than other metric-based distillation approaches.
Will Affective Computing Emerge from Foundation Models and General AI? A First Evaluation on ChatGPT
Mar 03, 2023ChatGPT has shown the potential of emerging general artificial intelligence capabilities, as it has demonstrated competent performance across many natural language processing tasks. In this work, we evaluate the capabilities of ChatGPT to perform text classification on three affective computing problems, namely, big-five personality prediction, sentiment analysis, and suicide tendency detection. We utilise three baselines, a robust language model (RoBERTa-base), a legacy word model with pretrained embeddings (Word2Vec), and a simple bag-of-words baseline (BoW). Results show that the RoBERTa trained for a specific downstream task generally has a superior performance. On the other hand, ChatGPT provides decent results, and is relatively comparable to the Word2Vec and BoW baselines. ChatGPT further shows robustness against noisy data, where Word2Vec models achieve worse results due to noise. Results indicate that ChatGPT is a good generalist model that is capable of achieving good results across various problems without any specialised training, however, it is not as good as a specialised model for a downstream task.
Language Models as Inductive Reasoners
Dec 21, 2022Inductive reasoning is a core component of human intelligence. In the past research of inductive reasoning within computer science, logic language is used as representations of knowledge (facts and rules, more specifically). However, logic language can cause systematic problems for inductive reasoning such as disability of handling raw input such as natural language, sensitiveness to mislabeled data, and incapacity to handle ambiguous input. To this end, we propose a new task, which is to induce natural language rules from natural language facts, and create a dataset termed DEER containing 1.2k rule-fact pairs for the task, where rules and facts are written in natural language. New automatic metrics are also proposed and analysed for the evaluation of this task. With DEER, we investigate a modern approach for inductive reasoning where we use natural language as representation for knowledge instead of logic language and use pretrained language models as ''reasoners''. Moreover, we provide the first and comprehensive analysis of how well pretrained language models can induce natural language rules from natural language facts. We also propose a new framework drawing insights from philosophy literature for this task, which we show in the experiment section that surpasses baselines in both automatic and human evaluations.
ConNER: Consistency Training for Cross-lingual Named Entity Recognition
Nov 17, 2022Cross-lingual named entity recognition (NER) suffers from data scarcity in the target languages, especially under zero-shot settings. Existing translate-train or knowledge distillation methods attempt to bridge the language gap, but often introduce a high level of noise. To solve this problem, consistency training methods regularize the model to be robust towards perturbations on data or hidden states. However, such methods are likely to violate the consistency hypothesis, or mainly focus on coarse-grain consistency. We propose ConNER as a novel consistency training framework for cross-lingual NER, which comprises of: (1) translation-based consistency training on unlabeled target-language data, and (2) dropoutbased consistency training on labeled source-language data. ConNER effectively leverages unlabeled target-language data and alleviates overfitting on the source language to enhance the cross-lingual adaptability. Experimental results show our ConNER achieves consistent improvement over various baseline methods.
Hierarchical Attention Network for Explainable Depression Detection on Twitter Aided by Metaphor Concept Mappings
Sep 15, 2022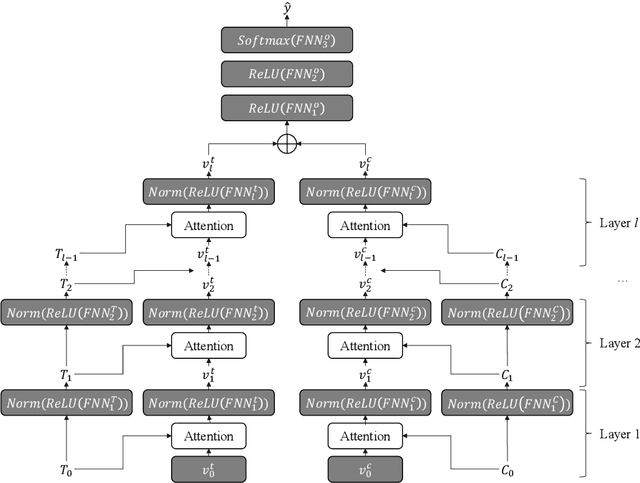
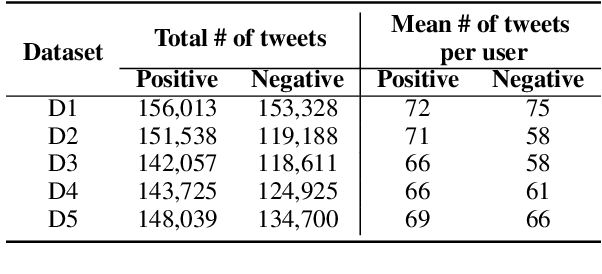
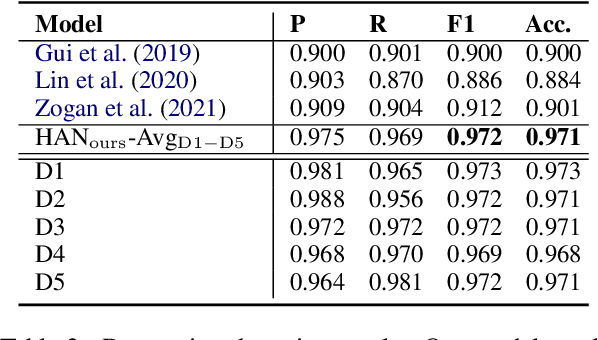
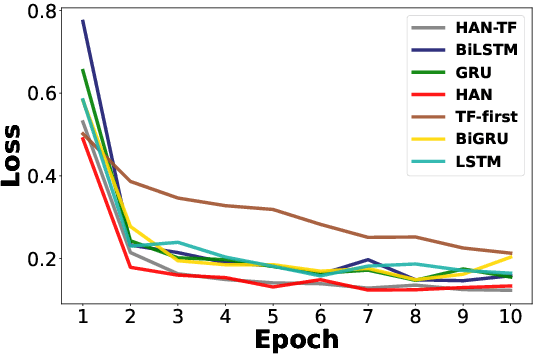
Automatic depression detection on Twitter can help individuals privately and conveniently understand their mental health status in the early stages before seeing mental health professionals. Most existing black-box-like deep learning methods for depression detection largely focused on improving classification performance. However, explaining model decisions is imperative in health research because decision-making can often be high-stakes and life-and-death. Reliable automatic diagnosis of mental health problems including depression should be supported by credible explanations justifying models' predictions. In this work, we propose a novel explainable model for depression detection on Twitter. It comprises a novel encoder combining hierarchical attention mechanisms and feed-forward neural networks. To support psycholinguistic studies, our model leverages metaphorical concept mappings as input. Thus, it not only detects depressed individuals, but also identifies features of such users' tweets and associated metaphor concept mappings.
Proceedings of the ICML 2022 Expressive Vocalizations Workshop and Competition: Recognizing, Generating, and Personalizing Vocal Bursts
Jul 14, 2022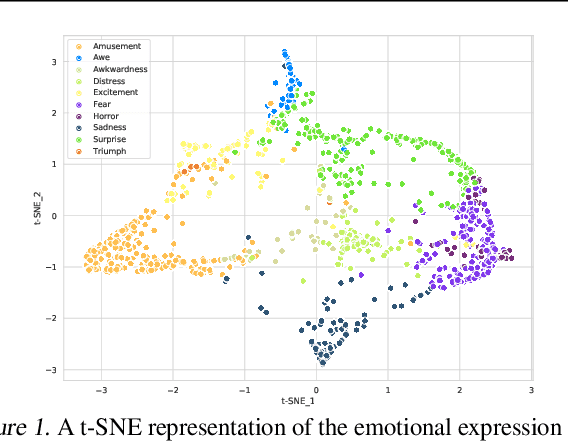
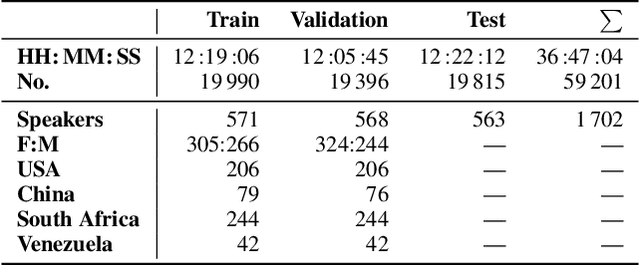
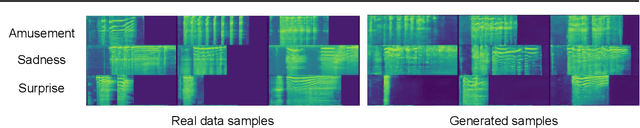
This is the Proceedings of the ICML Expressive Vocalization (ExVo) Competition. The ExVo competition focuses on understanding and generating vocal bursts: laughs, gasps, cries, and other non-verbal vocalizations that are central to emotional expression and communication. ExVo 2022, included three competition tracks using a large-scale dataset of 59,201 vocalizations from 1,702 speakers. The first, ExVo-MultiTask, requires participants to train a multi-task model to recognize expressed emotions and demographic traits from vocal bursts. The second, ExVo-Generate, requires participants to train a generative model that produces vocal bursts conveying ten different emotions. The third, ExVo-FewShot, requires participants to leverage few-shot learning incorporating speaker identity to train a model for the recognition of 10 emotions conveyed by vocal bursts.
The ICML 2022 Expressive Vocalizations Workshop and Competition: Recognizing, Generating, and Personalizing Vocal Bursts
May 03, 2022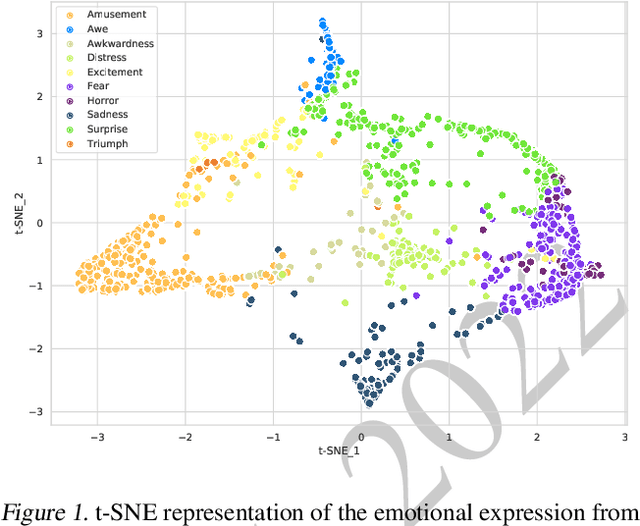
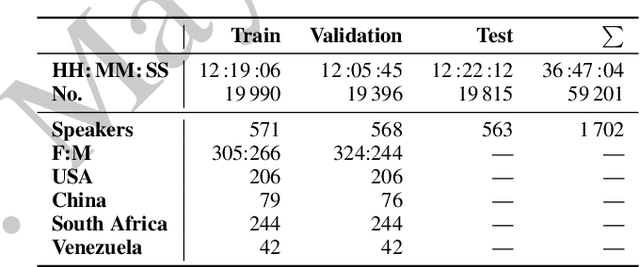
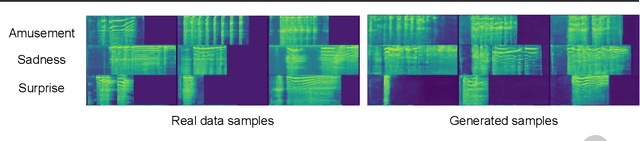
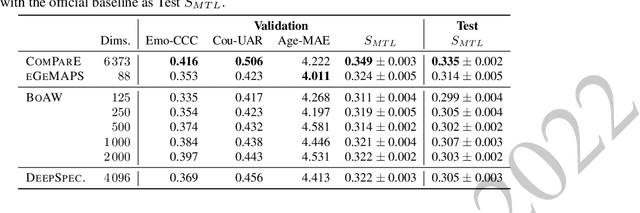
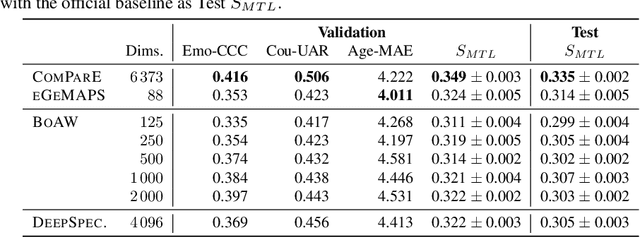
The ICML Expressive Vocalization (ExVo) Competition is focused on understanding and generating vocal bursts: laughs, gasps, cries, and other non-verbal vocalizations that are central to emotional expression and communication. ExVo 2022, includes three competition tracks using a large-scale dataset of 59,201 vocalizations from 1,702 speakers. The first, ExVo-MultiTask, requires participants to train a multi-task model to recognize expressed emotions and demographic traits from vocal bursts. The second, ExVo-Generate, requires participants to train a generative model that produces vocal bursts conveying ten different emotions. The third, ExVo-FewShot, requires participants to leverage few-shot learning incorporating speaker identity to train a model for the recognition of 10 emotions conveyed by vocal bursts. This paper describes the three tracks and provides performance measures for baseline models using state-of-the-art machine learning strategies. The baseline for each track is as follows, for ExVo-MultiTask, a combined score, computing the harmonic mean of Concordance Correlation Coefficient (CCC), Unweighted Average Recall (UAR), and inverted Mean Absolute Error (MAE) ($S_{MTL}$) is at best, 0.335 $S_{MTL}$; for ExVo-Generate, we report Fr\'echet inception distance (FID) scores ranging from 4.81 to 8.27 (depending on the emotion) between the training set and generated samples. We then combine the inverted FID with perceptual ratings of the generated samples ($S_{Gen}$) and obtain 0.174 $S_{Gen}$; and for ExVo-FewShot, a mean CCC of 0.444 is obtained.