 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Attention Network for Explainable Depression Detection on Twitter Aided by Metaphor Concept Mappings
Sep 15, 2022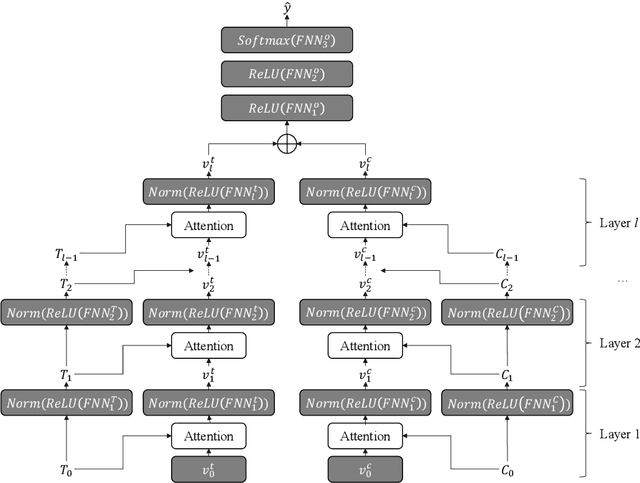
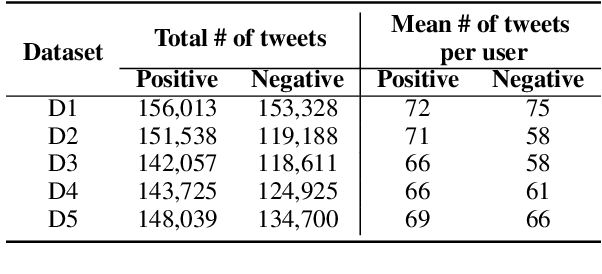
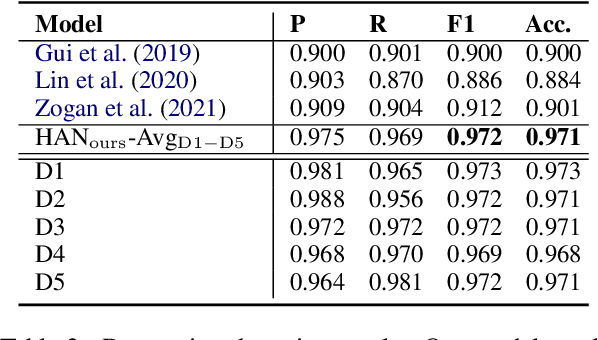
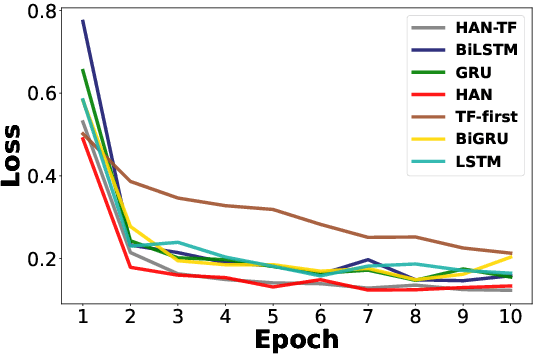
Automatic depression detection on Twitter can help individuals privately and conveniently understand their mental health status in the early stages before seeing mental health professionals. Most existing black-box-like deep learning methods for depression detection largely focused on improving classification performance. However, explaining model decisions is imperative in health research because decision-making can often be high-stakes and life-and-death. Reliable automatic diagnosis of mental health problems including depression should be supported by credible explanations justifying models' predictions. In this work, we propose a novel explainable model for depression detection on Twitter. It comprises a novel encoder combining hierarchical attention mechanisms and feed-forward neural networks. To support psycholinguistic studies, our model leverages metaphorical concept mappings as input. Thus, it not only detects depressed individuals, but also identifies features of such users' tweets and associated metaphor concept mappings.
RP-DNN: A Tweet level propagation context based deep neural networks for early rumor detection in Social Media
Mar 02, 2020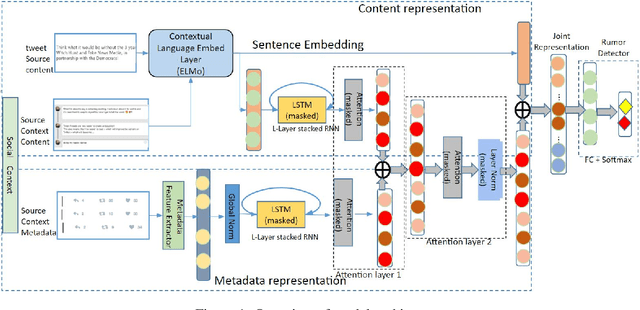

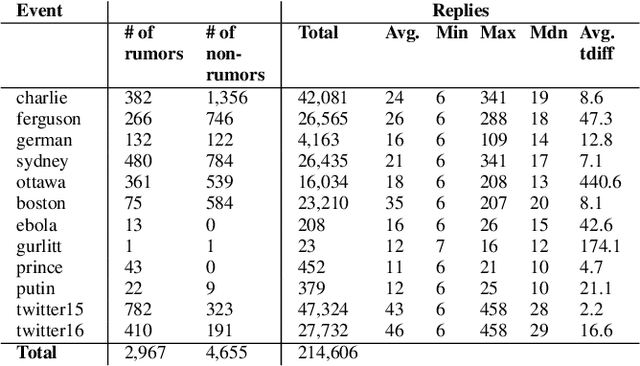
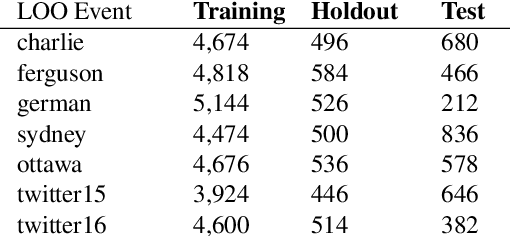
Early rumor detection (ERD) on social media platform is very challenging when limited, incomplete and noisy information is available. Most of the existing methods have largely worked on event-level detection that requires the collection of posts relevant to a specific event and relied only on user-generated content. They are not appropriate to detect rumor sources in the very early stages, before an event unfolds and becomes widespread. In this paper, we address the task of ERD at the message level. We present a novel hybrid neural network architecture, which combines a task-specific character-based bidirectional language model and stacked Long Short-Term Memory (LSTM) networks to represent textual contents and social-temporal contexts of input source tweets, for modelling propagation patterns of rumors in the early stages of their development. We apply multi-layered attention models to jointly learn attentive context embeddings over multiple context inputs. Our experiments employ a stringent leave-one-out cross-validation (LOO-CV) evaluation setup on seven publicly available real-life rumor event data sets. Our models achieve state-of-the-art(SoA) performance for detecting unseen rumors on large augmented data which covers more than 12 events and 2,967 rumors. An ablation study is conducted to understand the relative contribution of each component of our proposed model.
Neural Language Model Based Training Data Augmentation for Weakly Supervised Early Rumor Detection
Jul 16, 2019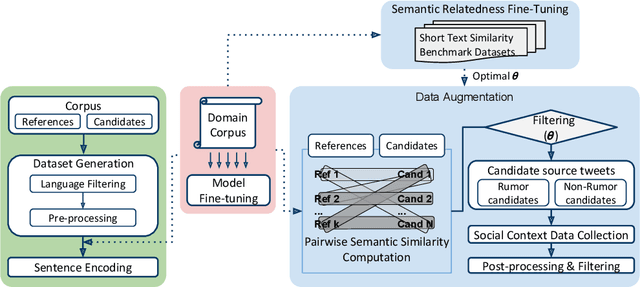
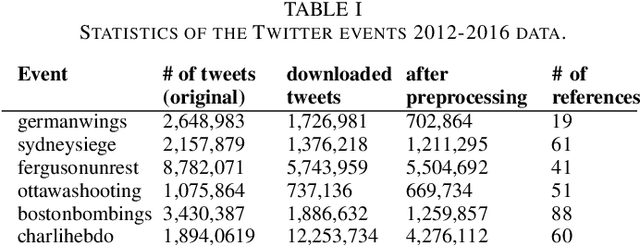
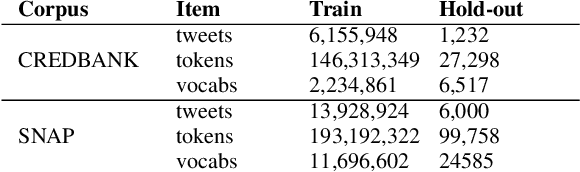

The scarcity and class imbalance of training data are known issues in current rumor detection tasks. We propose a straight-forward and general-purpose data augmentation technique which is beneficial to early rumor detection relying on event propagation patterns. The key idea is to exploit massive unlabeled event data sets on social media to augment limited labeled rumor source tweets. This work is based on rumor spreading patterns revealed by recent rumor studies and semantic relatedness between labeled and unlabeled data. A state-of-the-art neural language model (NLM) and large credibility-focused Twitter corpora are employed to learn context-sensitive representations of rumor tweets. Six different real-world events based on three publicly available rumor datasets are employed in our experiments to provide a comparative evaluation of the effectiveness of the method. The results show that our method can expand the size of an existing rumor data set nearly by 200% and corresponding social context (i.e., conversational threads) by 100% with reasonable quality. Preliminary experiments with a state-of-the-art deep learning-based rumor detection model show that augmented data can alleviate over-fitting and class imbalance caused by limited train data and can help to train complex neural networks (NNs). With augmented data, the performance of rumor detection can be improved by 12.1% in terms of F-score. Our experiments also indicate that augmented training data can help to generalize rumor detection models on unseen rumors.
* 8 pages