 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Affect to Complex Behavior: Advancing Multimodal Human-Centered AI at the 10th ABAW Workshop & Competition
May 24, 2026The 10th Affective & Behavior Analysis in-the-Wild (ABAW) Workshop and Competition, held at CVPR 2026, continues to advance research on modelling, analysis, understanding of human affect and behavior in real-world, unconstrained environments. The workshop maintains its dual structure, comprising both a competition and a paper track. The ABAW Competition introduces a diverse set of challenges targeting key aspects of affective and behavioral understanding, including continuous affect (valence-arousal) estimation, discrete affect (expression and action unit) recognition, as well as more complex behavior analysis tasks, such as emotional mimicry intensity estimation, ambivalence/hesitancy recognition and fine-grained violence detection. These challenges are built upon large-scale in-the-wild datasets, providing comprehensive benchmarks for state-of-the-art approaches. In parallel, the paper track presents a wide range of contributions spanning pose, motion & behavior estimation, affect modelling & multimodal learning, benchmarks, datasets & evaluation protocols, fairness, robustness & deployment. Overall, the 10th ABAW Workshop and Competition continues to serve as a key platform for benchmarking, collaboration and innovation, shaping the development of next-generation multimodal, human-centered AI systems.
The 2026 ACII Dyadic Conversations (DaiKon) Workshop & Challenge
May 04, 2026The 2026 ACII Dyadic Conversations (ACII-DaiKon) Workshop & Challenge introduces a benchmark for modeling interpersonal affect and social dynamics in dyadic conversations. Although conversational affect modeling has advanced rapidly, most benchmarks remain speaker-centric and underrepresent coupled, time-evolving processes between partners, including directional influence, conversational timing coordination, and rapport development. To address this gap, ACII-DaiKon presents three coordinated sub-challenges built on a shared dataset: (1) directional interpersonal influence prediction, (2) turn-taking prediction (next-speaker and time-to-next-speech), and (3) rapport trajectory prediction across full interactions. The challenge is built on the Hume-DaiKon dataset, comprising 945 dyadic conversations (743.4 hours of audiovisual data) collected under naturalistic conditions across five languages. The benchmark supports multimodal modeling, temporal reasoning, and cross-context generalization through fixed train/validation/test splits, standardized metrics, and released baseline systems. Evaluation uses Concordance Correlation Coefficient (CCC), Pearson correlation, Macro-F1, and Mean Absolute Error (MAE) depending on the sub-challenge. Baseline experiments establish initial reference performance, with best test results of 0.40 CCC and 0.50 Pearson for influence prediction, 0.66 Macro-F1 and 1.50~s MAE for turn-taking, and 0.68 CCC and 0.70 Pearson for rapport trajectory modeling. These results indicate that while current methods capture coarse dyadic patterns, robust modeling of directional dependence and long-horizon interpersonal dynamics remains challenging. The workshop provides a shared platform for rigorous comparison and cross-disciplinary discussion on data validity, evaluation protocols, and culturally aware modeling for dyadic interaction.
The NeurIPS 2023 Machine Learning for Audio Workshop: Affective Audio Benchmarks and Novel Data
Mar 21, 2024



The NeurIPS 2023 Machine Learning for Audio Workshop brings together machine learning (ML) experts from various audio domains. There are several valuable audio-driven ML tasks, from speech emotion recognition to audio event detection, but the community is sparse compared to other ML areas, e.g., computer vision or natural language processing. A major limitation with audio is the available data; with audio being a time-dependent modality, high-quality data collection is time-consuming and costly, making it challenging for academic groups to apply their often state-of-the-art strategies to a larger, more generalizable dataset. In this short white paper, to encourage researchers with limited access to large-datasets, the organizers first outline several open-source datasets that are available to the community, and for the duration of the workshop are making several propriety datasets available. Namely, three vocal datasets, Hume-Prosody, Hume-VocalBurst, an acted emotional speech dataset Modulate-Sonata, and an in-game streamer dataset Modulate-Stream. We outline the current baselines on these datasets but encourage researchers from across audio to utilize them outside of the initial baseline tasks.
The 6th Affective Behavior Analysis in-the-wild Competition
Mar 12, 2024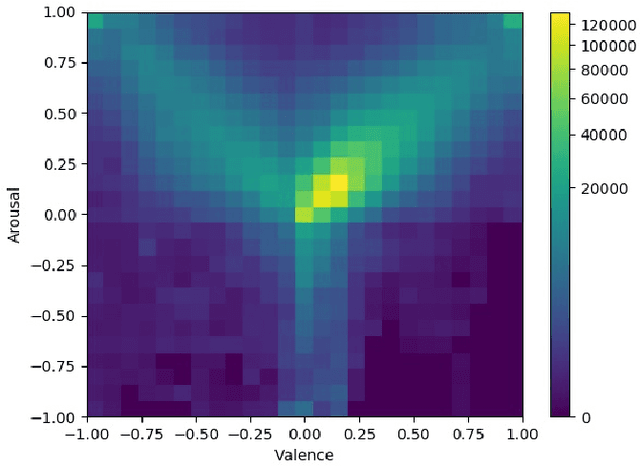
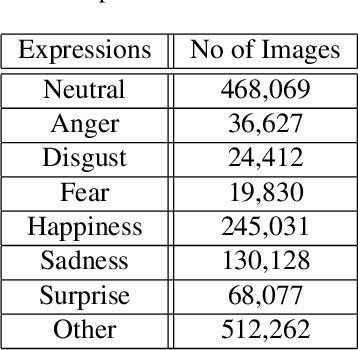
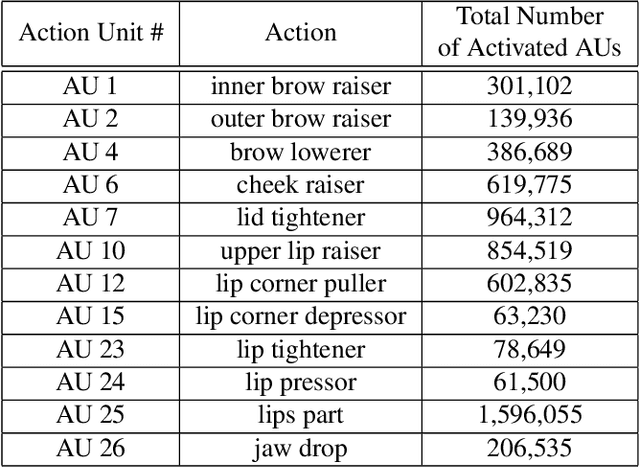
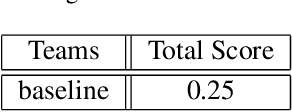
This paper describes the 6th Affective Behavior Analysis in-the-wild (ABAW) Competition, which is part of the respective Workshop held in conjunction with IEEE CVPR 2024. The 6th ABAW Competition addresses contemporary challenges in understanding human emotions and behaviors, crucial for the development of human-centered technologies. In more detail, the Competition focuses on affect related benchmarking tasks and comprises of five sub-challenges: i) Valence-Arousal Estimation (the target is to estimate two continuous affect dimensions, valence and arousal), ii) Expression Recognition (the target is to recognise between the mutually exclusive classes of the 7 basic expressions and 'other'), iii) Action Unit Detection (the target is to detect 12 action units), iv) Compound Expression Recognition (the target is to recognise between the 7 mutually exclusive compound expression classes), and v) Emotional Mimicry Intensity Estimation (the target is to estimate six continuous emotion dimensions). In the paper, we present these Challenges, describe their respective datasets and challenge protocols (we outline the evaluation metrics) and present the baseline systems as well as their obtained performance. More information for the Competition can be found in: https://affective-behavior-analysis-in-the-wild.github.io/6th.
The MuSe 2023 Multimodal Sentiment Analysis Challenge: Mimicked Emotions, Cross-Cultural Humour, and Personalisation
May 05, 2023



The MuSe 2023 is a set of shared tasks addressing three different contemporary multimodal affect and sentiment analysis problems: In the Mimicked Emotions Sub-Challenge (MuSe-Mimic), participants predict three continuous emotion targets. This sub-challenge utilises the Hume-Vidmimic dataset comprising of user-generated videos. For the Cross-Cultural Humour Detection Sub-Challenge (MuSe-Humour), an extension of the Passau Spontaneous Football Coach Humour (Passau-SFCH) dataset is provided. Participants predict the presence of spontaneous humour in a cross-cultural setting. The Personalisation Sub-Challenge (MuSe-Personalisation) is based on the Ulm-Trier Social Stress Test (Ulm-TSST) dataset, featuring recordings of subjects in a stressed situation. Here, arousal and valence signals are to be predicted, whereas parts of the test labels are made available in order to facilitate personalisation. MuSe 2023 seeks to bring together a broad audience from different research communities such as audio-visual emotion recognition, natural language processing, signal processing, and health informatics. In this baseline paper, we introduce the datasets, sub-challenges, and provided feature sets. As a competitive baseline system, a Gated Recurrent Unit (GRU)-Recurrent Neural Network (RNN) is employed. On the respective sub-challenges' test datasets, it achieves a mean (across three continuous intensity targets) Pearson's Correlation Coefficient of .4727 for MuSe-Mimic, an Area Under the Curve (AUC) value of .8310 for MuSe-Humor and Concordance Correlation Coefficient (CCC) values of .7482 for arousal and .7827 for valence in the MuSe-Personalisation sub-challenge.
The ACM Multimedia 2023 Computational Paralinguistics Challenge: Emotion Share & Requests
May 01, 2023



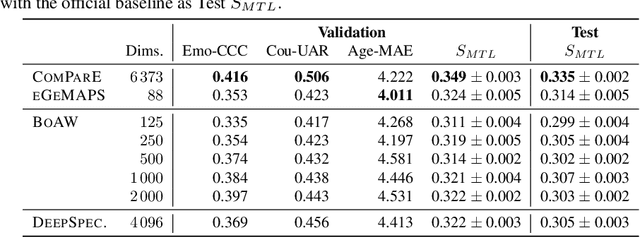
The ACM Multimedia 2023 Computational Paralinguistics Challenge addresses two different problems for the first time in a research competition under well-defined conditions: In the Emotion Share Sub-Challenge, a regression on speech has to be made; and in the Requests Sub-Challenges, requests and complaints need to be detected. We describe the Sub-Challenges, baseline feature extraction, and classifiers based on the usual ComPaRE features, the auDeep toolkit, and deep feature extraction from pre-trained CNNs using the DeepSpectRum toolkit; in addition, wav2vec2 models are used.
ABAW: Valence-Arousal Estimation, Expression Recognition, Action Unit Detection & Emotional Reaction Intensity Estimation Challenges
Mar 20, 2023



The fifth Affective Behavior Analysis in-the-wild (ABAW) Competition is part of the respective ABAW Workshop which will be held in conjunction with IEEE Computer Vision and Pattern Recognition Conference (CVPR), 2023. The 5th ABAW Competition is a continuation of the Competitions held at ECCV 2022, IEEE CVPR 2022, ICCV 2021, IEEE FG 2020 and CVPR 2017 Conferences, and is dedicated at automatically analyzing affect. For this year's Competition, we feature two corpora: i) an extended version of the Aff-Wild2 database and ii) the Hume-Reaction dataset. The former database is an audiovisual one of around 600 videos of around 3M frames and is annotated with respect to:a) two continuous affect dimensions -valence (how positive/negative a person is) and arousal (how active/passive a person is)-; b) basic expressions (e.g. happiness, sadness, neutral state); and c) atomic facial muscle actions (i.e., action units). The latter dataset is an audiovisual one in which reactions of individuals to emotional stimuli have been annotated with respect to seven emotional expression intensities. Thus the 5th ABAW Competition encompasses four Challenges: i) uni-task Valence-Arousal Estimation, ii) uni-task Expression Classification, iii) uni-task Action Unit Detection, and iv) Emotional Reaction Intensity Estimation. In this paper, we present these Challenges, along with their corpora, we outline the evaluation metrics, we present the baseline systems and illustrate their obtained performance.
Proceedings of the ACII Affective Vocal Bursts Workshop and Competition 2022 (A-VB): Understanding a critically understudied modality of emotional expression
Oct 27, 2022This is the Proceedings of the ACII Affective Vocal Bursts Workshop and Competition (A-VB). A-VB was a workshop-based challenge that introduces the problem of understanding emotional expression in vocal bursts -- a wide range of non-verbal vocalizations that includes laughs, grunts, gasps, and much more. With affective states informing both mental and physical wellbeing, the core focus of the A-VB workshop was the broader discussion of current strategies in affective computing for modeling vocal emotional expression. Within this first iteration of the A-VB challenge, the participants were presented with four emotion-focused sub-challenges that utilize the large-scale and `in-the-wild' Hume-VB dataset. The dataset and the four sub-challenges draw attention to new innovations in emotion science as it pertains to vocal expression, addressing low- and high-dimensional theories of emotional expression, cultural variation, and `call types' (laugh, cry, sigh, etc.).
An Overview of Affective Speech Synthesis and Conversion in the Deep Learning Era
Oct 06, 2022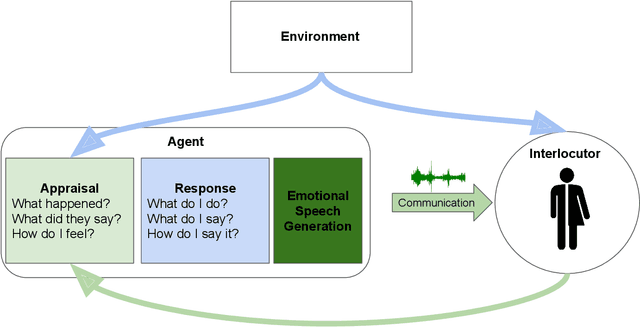
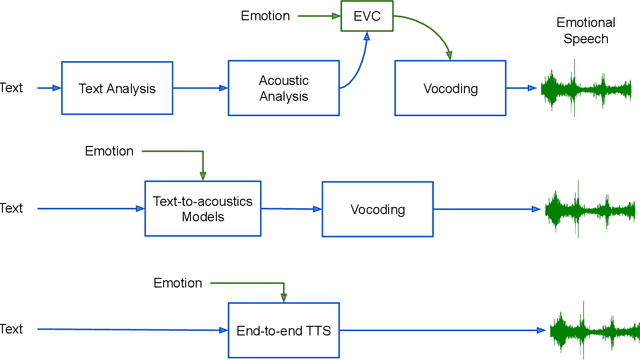
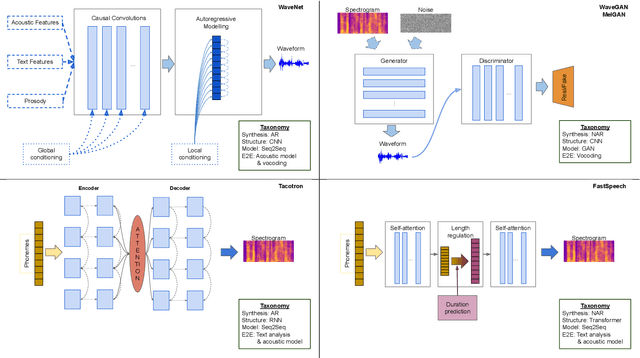
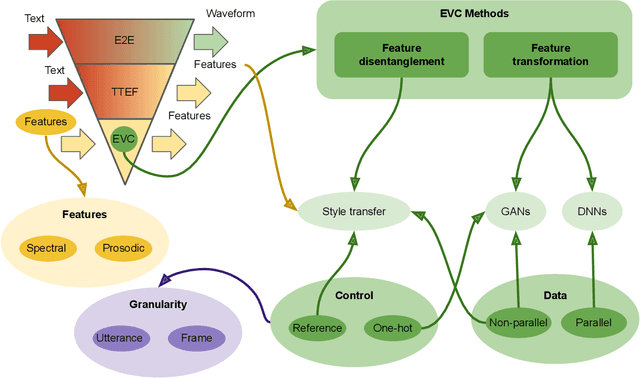
Speech is the fundamental mode of human communication, and its synthesis has long been a core priority in human-computer interaction research. In recent years, machines have managed to master the art of generating speech that is understandable by humans. But the linguistic content of an utterance encompasses only a part of its meaning. Affect, or expressivity, has the capacity to turn speech into a medium capable of conveying intimate thoughts, feelings, and emotions -- aspects that are essential for engaging and naturalistic interpersonal communication. While the goal of imparting expressivity to synthesised utterances has so far remained elusive, following recent advances in text-to-speech synthesis, a paradigm shift is well under way in the fields of affective speech synthesis and conversion as well. Deep learning, as the technology which underlies most of the recent advances in artificial intelligence, is spearheading these efforts. In the present overview, we outline ongoing trends and summarise state-of-the-art approaches in an attempt to provide a comprehensive overview of this exciting field.
Proceedings of the ICML 2022 Expressive Vocalizations Workshop and Competition: Recognizing, Generating, and Personalizing Vocal Bursts
Jul 14, 2022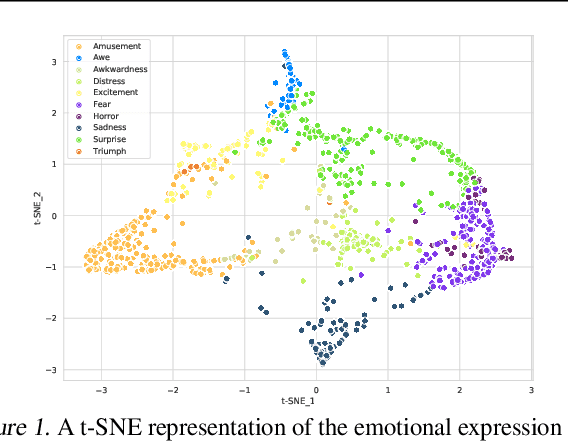
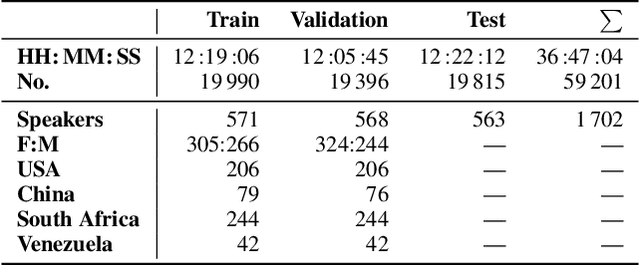
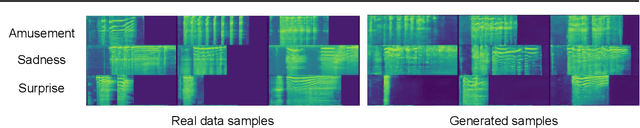
This is the Proceedings of the ICML Expressive Vocalization (ExVo) Competition. The ExVo competition focuses on understanding and generating vocal bursts: laughs, gasps, cries, and other non-verbal vocalizations that are central to emotional expression and communication. ExVo 2022, included three competition tracks using a large-scale dataset of 59,201 vocalizations from 1,702 speakers. The first, ExVo-MultiTask, requires participants to train a multi-task model to recognize expressed emotions and demographic traits from vocal bursts. The second, ExVo-Generate, requires participants to train a generative model that produces vocal bursts conveying ten different emotions. The third, ExVo-FewShot, requires participants to leverage few-shot learning incorporating speaker identity to train a model for the recognition of 10 emotions conveyed by vocal bursts.