 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatVideo: A Tracklet-centric Multimodal and Versatile Video Understanding System
Apr 29, 2023



Existing deep video models are limited by specific tasks, fixed input-output spaces, and poor generalization capabilities, making it difficult to deploy them in real-world scenarios. In this paper, we present our vision for multimodal and versatile video understanding and propose a prototype system, \system. Our system is built upon a tracklet-centric paradigm, which treats tracklets as the basic video unit and employs various Video Foundation Models (ViFMs) to annotate their properties e.g., appearance, motion, \etc. All the detected tracklets are stored in a database and interact with the user through a database manager. We have conducted extensive case studies on different types of in-the-wild videos, which demonstrates the effectiveness of our method in answering various video-related problems. Our project is available at https://www.wangjunke.info/ChatVideo/
Domain Generalization for Mammographic Image Analysis via Contrastive Learning
Apr 20, 2023Mammographic image analysis is a fundamental problem in the computer-aided diagnosis scheme, which has recently made remarkable progress with the advance of deep learning. However, the construction of a deep learning model requires training data that are large and sufficiently diverse in terms of image style and quality. In particular, the diversity of image style may be majorly attributed to the vendor factor. However, mammogram collection from vendors as many as possible is very expensive and sometimes impractical for laboratory-scale studies. Accordingly, to further augment the generalization capability of deep learning models to various vendors with limited resources, a new contrastive learning scheme is developed. Specifically, the backbone network is firstly trained with a multi-style and multi-view unsupervised self-learning scheme for the embedding of invariant features to various vendor styles. Afterward, the backbone network is then recalibrated to the downstream tasks of mass detection, multi-view mass matching, BI-RADS classification and breast density classification with specific supervised learning. The proposed method is evaluated with mammograms from four vendors and two unseen public datasets. The experimental results suggest that our approach can effectively improve analysis performance on both seen and unseen domains, and outperforms many state-of-the-art (SOTA) generalization methods.
AvatarCraft: Transforming Text into Neural Human Avatars with Parameterized Shape and Pose Control
Mar 30, 2023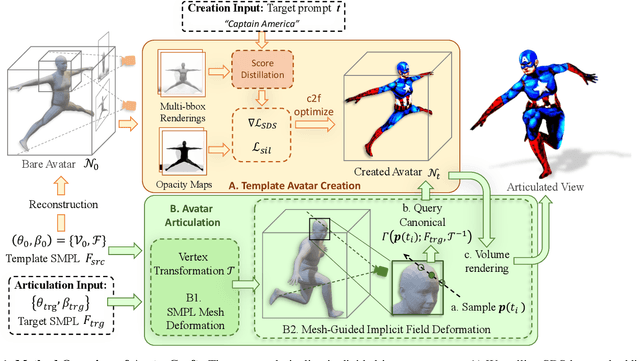
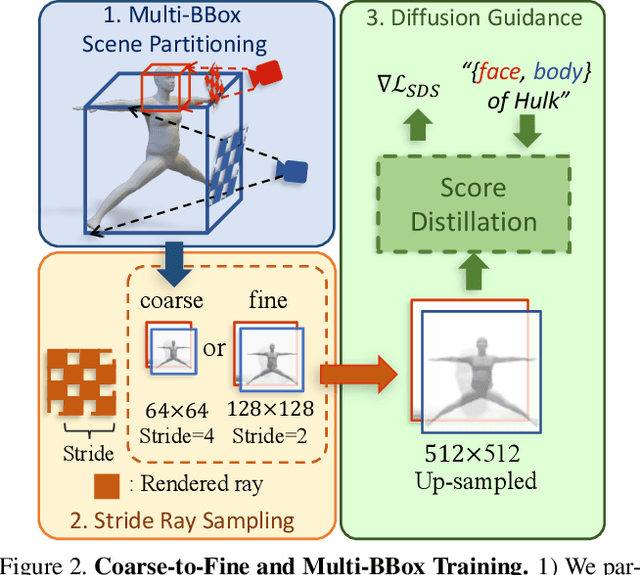
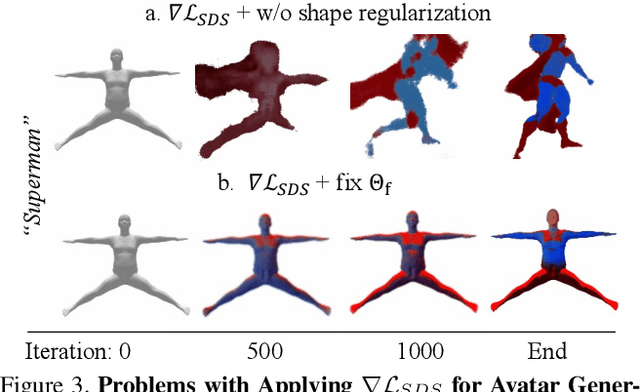
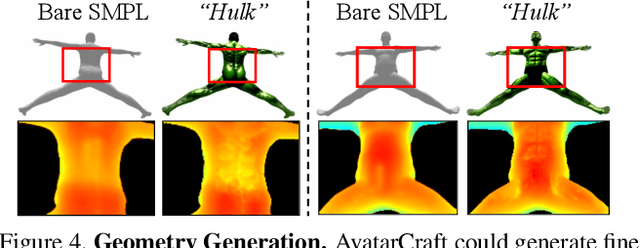
Neural implicit fields are powerful for representing 3D scenes and generating high-quality novel views, but it remains challenging to use such implicit representations for creating a 3D human avatar with a specific identity and artistic style that can be easily animated. Our proposed method, AvatarCraft, addresses this challenge by using diffusion models to guide the learning of geometry and texture for a neural avatar based on a single text prompt. We carefully design the optimization framework of neural implicit fields, including a coarse-to-fine multi-bounding box training strategy, shape regularization, and diffusion-based constraints, to produce high-quality geometry and texture. Additionally, we make the human avatar animatable by deforming the neural implicit field with an explicit warping field that maps the target human mesh to a template human mesh, both represented using parametric human models. This simplifies animation and reshaping of the generated avatar by controlling pose and shape parameters. Extensive experiments on various text descriptions show that AvatarCraft is effective and robust in creating human avatars and rendering novel views, poses, and shapes. Our project page is: \url{https://avatar-craft.github.io/}.
Streaming Video Model
Mar 30, 2023



Video understanding tasks have traditionally been modeled by two separate architectures, specially tailored for two distinct tasks. Sequence-based video tasks, such as action recognition, use a video backbone to directly extract spatiotemporal features, while frame-based video tasks, such as multiple object tracking (MOT), rely on single fixed-image backbone to extract spatial features. In contrast, we propose to unify video understanding tasks into one novel streaming video architecture, referred to as Streaming Vision Transformer (S-ViT). S-ViT first produces frame-level features with a memory-enabled temporally-aware spatial encoder to serve the frame-based video tasks. Then the frame features are input into a task-related temporal decoder to obtain spatiotemporal features for sequence-based tasks. The efficiency and efficacy of S-ViT is demonstrated by the state-of-the-art accuracy in the sequence-based action recognition task and the competitive advantage over conventional architecture in the frame-based MOT task. We believe that the concept of streaming video model and the implementation of S-ViT are solid steps towards a unified deep learning architecture for video understanding. Code will be available at https://github.com/yuzhms/Streaming-Video-Model.
OmniTracker: Unifying Object Tracking by Tracking-with-Detection
Mar 21, 2023Object tracking (OT) aims to estimate the positions of target objects in a video sequence. Depending on whether the initial states of target objects are specified by provided annotations in the first frame or the categories, OT could be classified as instance tracking (e.g., SOT and VOS) and category tracking (e.g., MOT, MOTS, and VIS) tasks. Combing the advantages of the best practices developed in both communities, we propose a novel tracking-with-detection paradigm, where tracking supplements appearance priors for detection and detection provides tracking with candidate bounding boxes for association. Equipped with such a design, a unified tracking model, OmniTracker, is further presented to resolve all the tracking tasks with a fully shared network architecture, model weights, and inference pipeline. Extensive experiments on 7 tracking datasets, including LaSOT, TrackingNet, DAVIS16-17, MOT17, MOTS20, and YTVIS19, demonstrate that OmniTracker achieves on-par or even better results than both task-specific and unified tracking models.
Diversity-Aware Meta Visual Prompting
Mar 14, 2023



We present Diversity-Aware Meta Visual Prompting~(DAM-VP), an efficient and effective prompting method for transferring pre-trained models to downstream tasks with frozen backbone. A challenging issue in visual prompting is that image datasets sometimes have a large data diversity whereas a per-dataset generic prompt can hardly handle the complex distribution shift toward the original pretraining data distribution properly. To address this issue, we propose a dataset Diversity-Aware prompting strategy whose initialization is realized by a Meta-prompt. Specifically, we cluster the downstream dataset into small homogeneity subsets in a diversity-adaptive way, with each subset has its own prompt optimized separately. Such a divide-and-conquer design reduces the optimization difficulty greatly and significantly boosts the prompting performance. Furthermore, all the prompts are initialized with a meta-prompt, which is learned across several datasets. It is a bootstrapped paradigm, with the key observation that the prompting knowledge learned from previous datasets could help the prompt to converge faster and perform better on a new dataset. During inference, we dynamically select a proper prompt for each input, based on the feature distance between the input and each subset. Through extensive experiments, our DAM-VP demonstrates superior efficiency and effectiveness, clearly surpassing previous prompting methods in a series of downstream datasets for different pretraining models. Our code is available at: \url{https://github.com/shikiw/DAM-VP}.
Layer Grafted Pre-training: Bridging Contrastive Learning And Masked Image Modeling For Label-Efficient Representations
Feb 27, 2023



Recently, both Contrastive Learning (CL) and Mask Image Modeling (MIM) demonstrate that self-supervision is powerful to learn good representations. However, naively combining them is far from success. In this paper, we start by making the empirical observation that a naive joint optimization of CL and MIM losses leads to conflicting gradient directions - more severe as the layers go deeper. This motivates us to shift the paradigm from combining loss at the end, to choosing the proper learning method per network layer. Inspired by experimental observations, we find that MIM and CL are suitable to lower and higher layers, respectively. We hence propose to combine them in a surprisingly simple, "sequential cascade" fashion: early layers are first trained under one MIM loss, on top of which latter layers continue to be trained under another CL loss. The proposed Layer Grafted Pre-training learns good visual representations that demonstrate superior label efficiency in downstream applications, in particular yielding strong few-shot performance besides linear evaluation. For instance, on ImageNet-1k, Layer Grafted Pre-training yields 65.5% Top-1 accuracy in terms of 1% few-shot learning with ViT-B/16, which improves MIM and CL baselines by 14.4% and 2.1% with no bells and whistles. The code is available at https://github.com/VITA-Group/layerGraftedPretraining_ICLR23.git.
MADAv2: Advanced Multi-Anchor Based Active Domain Adaptation Segmentation
Jan 18, 2023Unsupervised domain adaption has been widely adopted in tasks with scarce annotated data. Unfortunately, mapping the target-domain distribution to the source-domain unconditionally may distort the essential structural information of the target-domain data, leading to inferior performance. To address this issue, we firstly propose to introduce active sample selection to assist domain adaptation regarding the semantic segmentation task. By innovatively adopting multiple anchors instead of a single centroid, both source and target domains can be better characterized as multimodal distributions, in which way more complementary and informative samples are selected from the target domain. With only a little workload to manually annotate these active samples, the distortion of the target-domain distribution can be effectively alleviated, achieving a large performance gain. In addition, a powerful semi-supervised domain adaptation strategy is proposed to alleviate the long-tail distribution problem and further improve the segmentation performance. Extensive experiments are conducted on public datasets, and the results demonstrate that the proposed approach outperforms state-of-the-art methods by large margins and achieves similar performance to the fully-supervised upperbound, i.e., 71.4% mIoU on GTA5 and 71.8% mIoU on SYNTHIA. The effectiveness of each component is also verified by thorough ablation studies.
PA-GM: Position-Aware Learning of Embedding Networks for Deep Graph Matching
Jan 05, 2023



Graph matching can be formalized as a combinatorial optimization problem, where there are corresponding relationships between pairs of nodes that can be represented as edges. This problem becomes challenging when there are potential ambiguities present due to nodes and edges with high similarity, and there is a need to find accurate results for similar content matching. In this paper, we introduce a novel end-to-end neural network that can map the linear assignment problem into a high-dimensional space augmented with node-level relative position information, which is crucial for improving the method's performance for similar content matching. Our model constructs the anchor set for the relative position of nodes and then aggregates the feature information of the target node and each anchor node based on a measure of relative position. It then learns the node feature representation by integrating the topological structure and the relative position information, thus realizing the linear assignment between the two graphs. To verify the effectiveness and generalizability of our method, we conduct graph matching experiments, including cross-category matching, on different real-world datasets. Comparisons with different baselines demonstrate the superiority of our method. Our source code is available under https://github.com/anonymous.
NeRF-Art: Text-Driven Neural Radiance Fields Stylization
Dec 15, 2022
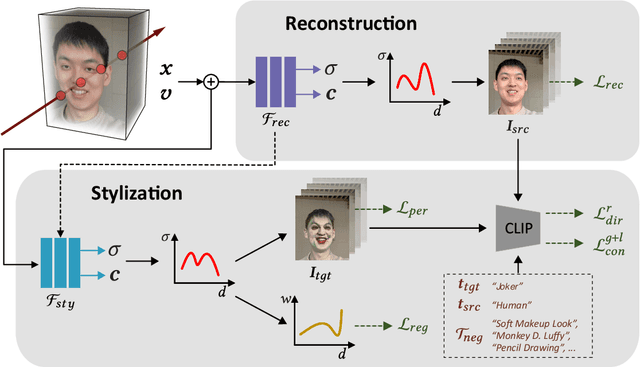
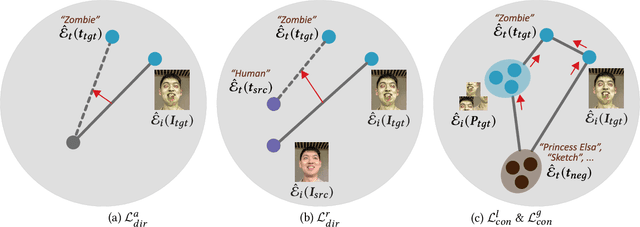

As a powerful representation of 3D scenes, the neural radiance field (NeRF) enables high-quality novel view synthesis from multi-view images. Stylizing NeRF, however, remains challenging, especially on simulating a text-guided style with both the appearance and the geometry altered simultaneously. In this paper, we present NeRF-Art, a text-guided NeRF stylization approach that manipulates the style of a pre-trained NeRF model with a simple text prompt. Unlike previous approaches that either lack sufficient geometry deformations and texture details or require meshes to guide the stylization, our method can shift a 3D scene to the target style characterized by desired geometry and appearance variations without any mesh guidance. This is achieved by introducing a novel global-local contrastive learning strategy, combined with the directional constraint to simultaneously control both the trajectory and the strength of the target style. Moreover, we adopt a weight regularization method to effectively suppress cloudy artifacts and geometry noises which arise easily when the density field is transformed during geometry stylization. Through extensive experiments on various styles, we demonstrate that our method is effective and robust regarding both single-view stylization quality and cross-view consistency. The code and more results can be found in our project page: https://cassiepython.github.io/nerfart/.