 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVQNet: Sparse Voxel-Adjacent Query Network for 4D Spatio-Temporal LiDAR Semantic Segmentation
Aug 25, 2023



LiDAR-based semantic perception tasks are critical yet challenging for autonomous driving. Due to the motion of objects and static/dynamic occlusion, temporal information plays an essential role in reinforcing perception by enhancing and completing single-frame knowledge. Previous approaches either directly stack historical frames to the current frame or build a 4D spatio-temporal neighborhood using KNN, which duplicates computation and hinders realtime performance. Based on our observation that stacking all the historical points would damage performance due to a large amount of redundant and misleading information, we propose the Sparse Voxel-Adjacent Query Network (SVQNet) for 4D LiDAR semantic segmentation. To take full advantage of the historical frames high-efficiently, we shunt the historical points into two groups with reference to the current points. One is the Voxel-Adjacent Neighborhood carrying local enhancing knowledge. The other is the Historical Context completing the global knowledge. Then we propose new modules to select and extract the instructive features from the two groups. Our SVQNet achieves state-of-the-art performance in LiDAR semantic segmentation of the SemanticKITTI benchmark and the nuScenes dataset.
SCAT: Robust Self-supervised Contrastive Learning via Adversarial Training for Text Classification
Jul 04, 2023Despite their promising performance across various natural language processing (NLP) tasks, current NLP systems are vulnerable to textual adversarial attacks. To defend against these attacks, most existing methods apply adversarial training by incorporating adversarial examples. However, these methods have to rely on ground-truth labels to generate adversarial examples, rendering it impractical for large-scale model pre-training which is commonly used nowadays for NLP and many other tasks. In this paper, we propose a novel learning framework called SCAT (Self-supervised Contrastive Learning via Adversarial Training), which can learn robust representations without requiring labeled data. Specifically, SCAT modifies random augmentations of the data in a fully labelfree manner to generate adversarial examples. Adversarial training is achieved by minimizing the contrastive loss between the augmentations and their adversarial counterparts. We evaluate SCAT on two text classification datasets using two state-of-the-art attack schemes proposed recently. Our results show that SCAT can not only train robust language models from scratch, but it can also significantly improve the robustness of existing pre-trained language models. Moreover, to demonstrate its flexibility, we show that SCAT can also be combined with supervised adversarial training to further enhance model robustness.
Integrating Geometric Control into Text-to-Image Diffusion Models for High-Quality Detection Data Generation via Text Prompt
Jun 28, 2023Diffusion models have attracted significant attention due to their remarkable ability to create content and generate data for tasks such as image classification. However, the usage of diffusion models to generate high-quality object detection data remains an underexplored area, where not only the image-level perceptual quality but also geometric conditions such as bounding boxes and camera views are essential. Previous studies have utilized either copy-paste synthesis or layout-to-image (L2I) generation with specifically designed modules to encode semantic layouts. In this paper, we propose GeoDiffusion, a simple framework that can flexibly translate various geometric conditions into text prompts and empower the pre-trained text-to-image (T2I) diffusion models for high-quality detection data generation. Unlike previous L2I methods, our GeoDiffusion is able to encode not only bounding boxes but also extra geometric conditions such as camera views in self-driving scenes. Extensive experiments demonstrate GeoDiffusion outperforms previous L2I methods while maintaining 4x training time faster. To the best of our knowledge, this is the first work to adopt diffusion models for layout-to-image generation with geometric conditions and demonstrate that L2I-generated images can be beneficial for improving the performance of object detectors.
Mixed Autoencoder for Self-supervised Visual Representation Learning
Mar 30, 2023Masked Autoencoder (MAE) has demonstrated superior performance on various vision tasks via randomly masking image patches and reconstruction. However, effective data augmentation strategies for MAE still remain open questions, different from those in contrastive learning that serve as the most important part. This paper studies the prevailing mixing augmentation for MAE. We first demonstrate that naive mixing will in contrast degenerate model performance due to the increase of mutual information (MI). To address, we propose homologous recognition, an auxiliary pretext task, not only to alleviate the MI increasement by explicitly requiring each patch to recognize homologous patches, but also to perform object-aware self-supervised pre-training for better downstream dense perception performance. With extensive experiments, we demonstrate that our proposed Mixed Autoencoder (MixedAE) achieves the state-of-the-art transfer results among masked image modeling (MIM) augmentations on different downstream tasks with significant efficiency. Specifically, our MixedAE outperforms MAE by +0.3% accuracy, +1.7 mIoU and +0.9 AP on ImageNet-1K, ADE20K and COCO respectively with a standard ViT-Base. Moreover, MixedAE surpasses iBOT, a strong MIM method combined with instance discrimination, while accelerating training by 2x. To our best knowledge, this is the very first work to consider mixing for MIM from the perspective of pretext task design. Code will be made available.
CLIP$^2$: Contrastive Language-Image-Point Pretraining from Real-World Point Cloud Data
Mar 26, 2023



Contrastive Language-Image Pre-training, benefiting from large-scale unlabeled text-image pairs, has demonstrated great performance in open-world vision understanding tasks. However, due to the limited Text-3D data pairs, adapting the success of 2D Vision-Language Models (VLM) to the 3D space remains an open problem. Existing works that leverage VLM for 3D understanding generally resort to constructing intermediate 2D representations for the 3D data, but at the cost of losing 3D geometry information. To take a step toward open-world 3D vision understanding, we propose Contrastive Language-Image-Point Cloud Pretraining (CLIP$^2$) to directly learn the transferable 3D point cloud representation in realistic scenarios with a novel proxy alignment mechanism. Specifically, we exploit naturally-existed correspondences in 2D and 3D scenarios, and build well-aligned and instance-based text-image-point proxies from those complex scenarios. On top of that, we propose a cross-modal contrastive objective to learn semantic and instance-level aligned point cloud representation. Experimental results on both indoor and outdoor scenarios show that our learned 3D representation has great transfer ability in downstream tasks, including zero-shot and few-shot 3D recognition, which boosts the state-of-the-art methods by large margins. Furthermore, we provide analyses of the capability of different representations in real scenarios and present the optional ensemble scheme.
Deep COVID-19 Forecasting for Multiple States with Data Augmentation
Feb 02, 2023



In this work, we propose a deep learning approach to forecasting state-level COVID-19 trends of weekly cumulative death in the United States (US) and incident cases in Germany. This approach includes a transformer model, an ensemble method, and a data augmentation technique for time series. We arrange the inputs of the transformer in such a way that predictions for different states can attend to the trends of the others. To overcome the issue of scarcity of training data for this COVID-19 pandemic, we have developed a novel data augmentation technique to generate useful data for training. More importantly, the generated data can also be used for model validation. As such, it has a two-fold advantage: 1) more actual observations can be used for training, and 2) the model can be validated on data which has distribution closer to the expected situation. Our model has achieved some of the best state-level results on the COVID-19 Forecast Hub for the US and for Germany.
Learning 3D-aware Image Synthesis with Unknown Pose Distribution
Jan 18, 2023



Existing methods for 3D-aware image synthesis largely depend on the 3D pose distribution pre-estimated on the training set. An inaccurate estimation may mislead the model into learning faulty geometry. This work proposes PoF3D that frees generative radiance fields from the requirements of 3D pose priors. We first equip the generator with an efficient pose learner, which is able to infer a pose from a latent code, to approximate the underlying true pose distribution automatically. We then assign the discriminator a task to learn pose distribution under the supervision of the generator and to differentiate real and synthesized images with the predicted pose as the condition. The pose-free generator and the pose-aware discriminator are jointly trained in an adversarial manner. Extensive results on a couple of datasets confirm that the performance of our approach, regarding both image quality and geometry quality, is on par with state of the art. To our best knowledge, PoF3D demonstrates the feasibility of learning high-quality 3D-aware image synthesis without using 3D pose priors for the first time.
SongRewriter: A Chinese Song Rewriting System with Controllable Content and Rhyme Scheme
Nov 28, 2022



Although lyrics generation has achieved significant progress in recent years, it has limited practical applications because the generated lyrics cannot be performed without composing compatible melodies. In this work, we bridge this practical gap by proposing a song rewriting system which rewrites the lyrics of an existing song such that the generated lyrics are compatible with the rhythm of the existing melody and thus singable. In particular, we propose SongRewriter, a controllable Chinese lyric generation and editing system which assists users without prior knowledge of melody composition. The system is trained by a randomized multi-level masking strategy which produces a unified model for generating entirely new lyrics or editing a few fragments. To improve the controllabiliy of the generation process, we further incorporate a keyword prompt to control the lexical choices of the content and propose novel decoding constraints and a vowel modeling task to enable flexible end and internal rhyme schemes. While prior rhyming metrics are mainly for rap lyrics, we propose three novel rhyming evaluation metrics for song lyrics. Both automatic and human evaluations show that the proposed model performs better than the state-of-the-art models in both contents and rhyming quality. Our code and models implemented in MindSpore Lite tool will be available.
Improving 3D-aware Image Synthesis with A Geometry-aware Discriminator
Sep 30, 2022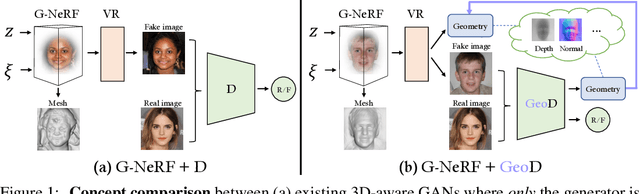
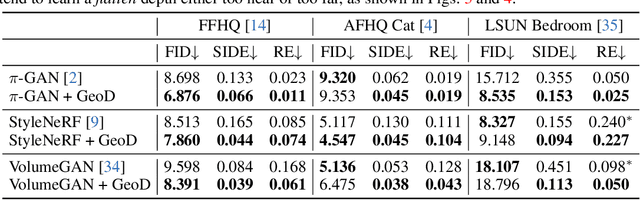

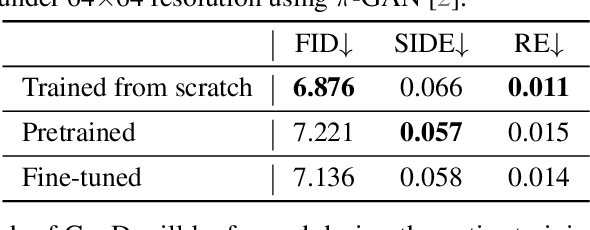
3D-aware image synthesis aims at learning a generative model that can render photo-realistic 2D images while capturing decent underlying 3D shapes. A popular solution is to adopt the generative adversarial network (GAN) and replace the generator with a 3D renderer, where volume rendering with neural radiance field (NeRF) is commonly used. Despite the advancement of synthesis quality, existing methods fail to obtain moderate 3D shapes. We argue that, considering the two-player game in the formulation of GANs, only making the generator 3D-aware is not enough. In other words, displacing the generative mechanism only offers the capability, but not the guarantee, of producing 3D-aware images, because the supervision of the generator primarily comes from the discriminator. To address this issue, we propose GeoD through learning a geometry-aware discriminator to improve 3D-aware GANs. Concretely, besides differentiating real and fake samples from the 2D image space, the discriminator is additionally asked to derive the geometry information from the inputs, which is then applied as the guidance of the generator. Such a simple yet effective design facilitates learning substantially more accurate 3D shapes. Extensive experiments on various generator architectures and training datasets verify the superiority of GeoD over state-of-the-art alternatives. Moreover, our approach is registered as a general framework such that a more capable discriminator (i.e., with a third task of novel view synthesis beyond domain classification and geometry extraction) can further assist the generator with a better multi-view consistency.
Trading off Quality for Efficiency of Community Detection: An Inductive Method across Graphs
Sep 29, 2022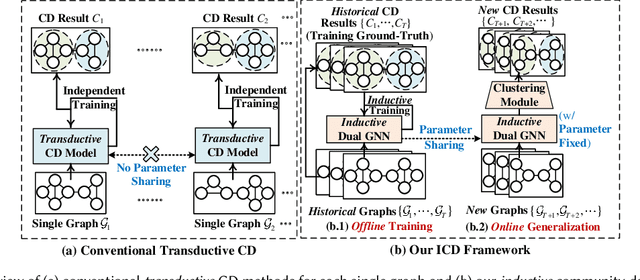

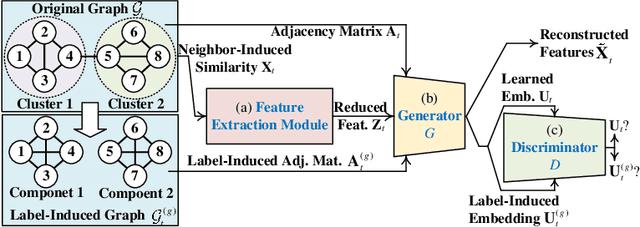
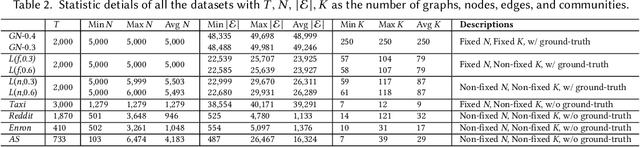
Many network applications can be formulated as NP-hard combinatorial optimization problems of community detection (CD). Due to the NP-hardness, to balance the CD quality and efficiency remains a challenge. Most existing CD methods are transductive, which are independently optimized only for the CD on a single graph. Some of these methods use advanced machine learning techniques to obtain high-quality CD results but usually have high complexity. Other approaches use fast heuristic approximation to ensure low runtime but may suffer from quality degradation. In contrast to these transductive methods, we propose an alternative inductive community detection (ICD) method across graphs of a system or scenario to alleviate the NP-hard challenge. ICD first conducts the offline training of an adversarial dual GNN on historical graphs to capture key properties of the system. The trained model is then directly generalized to new unseen graphs for online CD without additional optimization, where a better trade-off between quality and efficiency can be achieved. ICD can also capture the permutation invariant community labels in the offline training and tackle the online CD on new graphs with non-fixed number of nodes and communities. Experiments on a set of benchmarks demonstrate that ICD can achieve a significant trade-off between quality and efficiency over various baselines.