 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMESH2IR: Neural Acoustic Impulse Response Generator for Complex 3D Scenes
May 18, 2022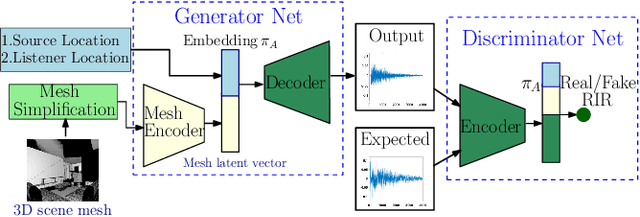
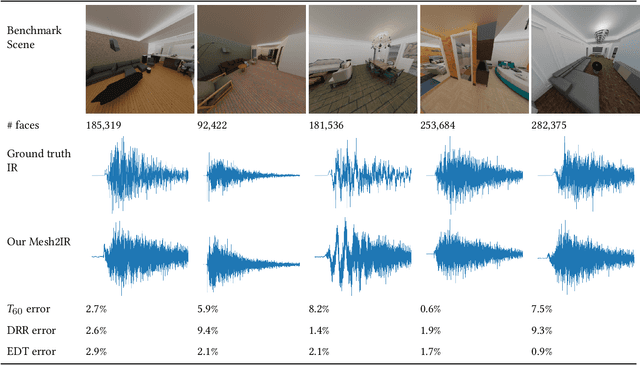
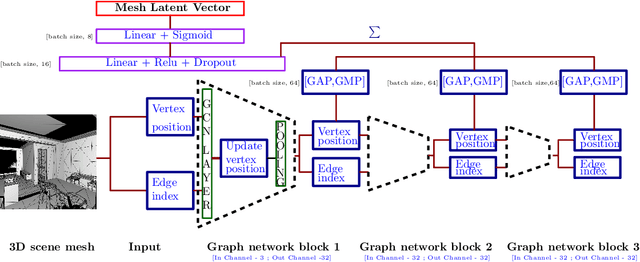
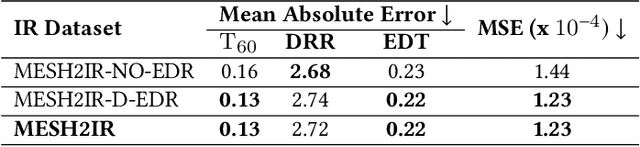
We propose a mesh-based neural network (MESH2IR) to generate acoustic impulse responses (IRs) for indoor 3D scenes represented using a mesh. The IRs are used to create a high-quality sound experience in interactive applications and audio processing. Our method can handle input triangular meshes with arbitrary topologies (2K - 3M triangles). We present a novel training technique to train MESH2IR using energy decay relief and highlight its benefits. We also show that training MESH2IR on IRs preprocessed using our proposed technique significantly improves the accuracy of IR generation. We reduce the non-linearity in the mesh space by transforming 3D scene meshes to latent space using a graph convolution network. Our MESH2IR is more than 200 times faster than a geometric acoustic algorithm on a CPU and can generate more than 10,000 IRs per second on an NVIDIA GeForce RTX 2080 Ti GPU for a given furnished indoor 3D scene. The acoustic metrics are used to characterize the acoustic environment. We show that the acoustic metrics of the IRs predicted from our MESH2IR match the ground truth with less than 10% error. We also highlight the benefits of MESH2IR on audio and speech processing applications such as speech dereverberation and speech separation. To the best of our knowledge, ours is the first neural-network-based approach to predict IRs from a given 3D scene mesh in real-time.
Sim-to-Real Strategy for Spatially Aware Robot Navigation in Uneven Outdoor Environments
May 18, 2022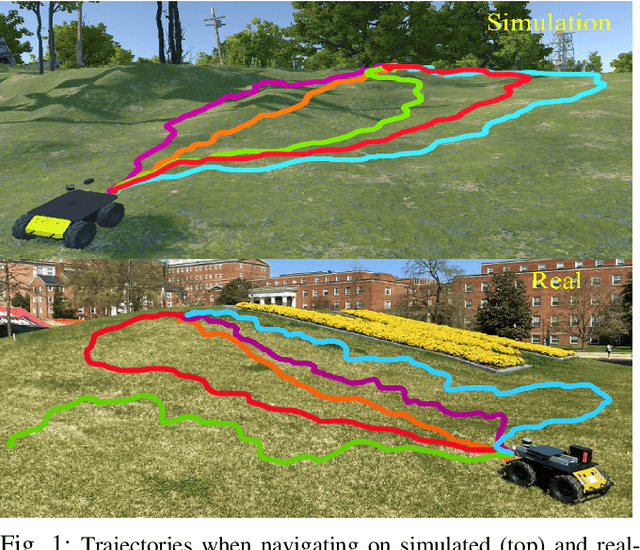
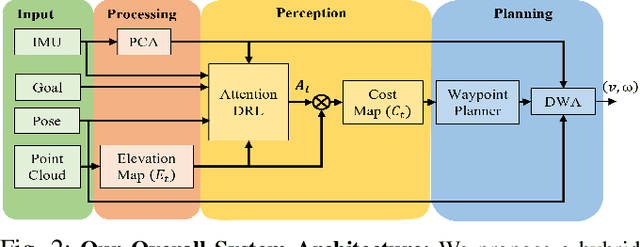
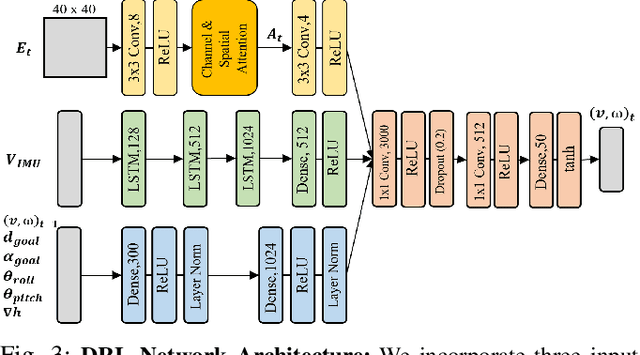
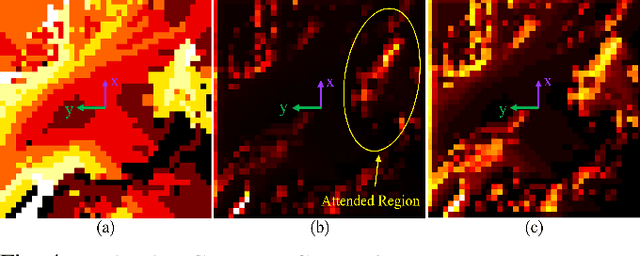
Deep Reinforcement Learning (DRL) is hugely successful due to the availability of realistic simulated environments. However, performance degradation during simulation to real-world transfer still remains a challenging problem for the policies trained in simulated environments. To close this sim-to-real gap, we present a novel hybrid architecture that utilizes an intermediate output from a fully trained attention DRL policy as a navigation cost map for outdoor navigation. Our attention DRL network incorporates a robot-centric elevation map, IMU data, the robot's pose, previous actions, and goal information as inputs to compute a navigation cost-map that highlights non-traversable regions. We compute least-cost waypoints on the cost map and utilize the Dynamic Window Approach (DWA) with velocity constraints on high cost regions to follow the waypoints in highly uneven outdoor environments. Our formulation generates dynamically feasible velocities along stable, traversable regions to reach the robot's goals. We observe an increase of 5% in terms of success rate, 13.09% of the decrease in average robot vibration, and a 19.33% reduction in average velocity compared to end-to-end DRL method and state-of-the-art methods in complex outdoor environments. We evaluate the benefits of our method using a Clearpath Husky robot in both simulated and real-world uneven environments.
AdaptiveON: Adaptive Outdoor Navigation Method For Stable and Reliable Actions
May 15, 2022
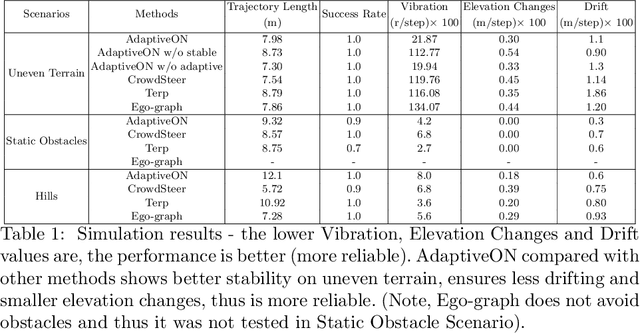
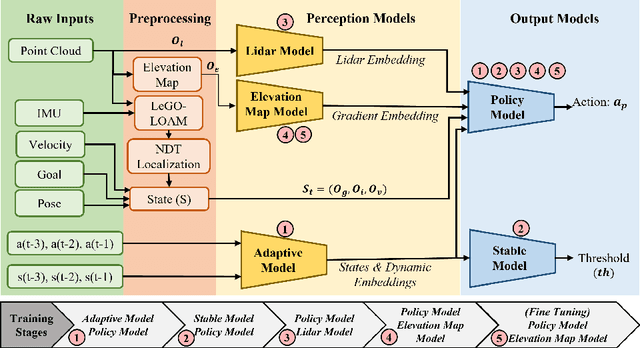
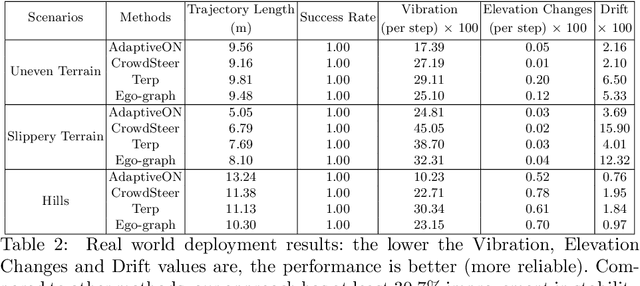
We present a novel outdoor navigation algorithm to generate stable and efficient actions to navigate a robot to the goal. We use a multi-stage training pipeline and show that our model produces policies that result in stable and reliable robot navigation on complex terrains. Based on the Proximal Policy Optimization (PPO) algorithm, we developed a novel method to achieve multiple capabilities for outdoor navigation tasks, namely: alleviating the robot's drifting, keeping the robot stable on bumpy terrains, avoiding climbing on hills with steep elevation changes, and collision avoidance. Our training process mitigates the reality(sim-to-real) gap by introducing more generalized environmental and robotic parameters and training with rich features of Lidar perception in the Unity simulator. We evaluate our method in both simulation and the real world with Clearpath Husky and Jackal. Additionally, we compare our method against the state-of-the-art approaches and show that in the real world it improves stability by at least 30.7% on uneven terrains, reduces drifting by 8.08%, and for high hills our trained policy keeps small changes of the elevation of the robot at each motion step by preventing the robot from moving on areas with high gradients.
Predicting Loose-Fitting Garment Deformations Using Bone-Driven Motion Networks
May 06, 2022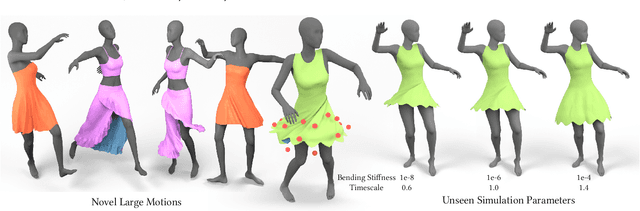
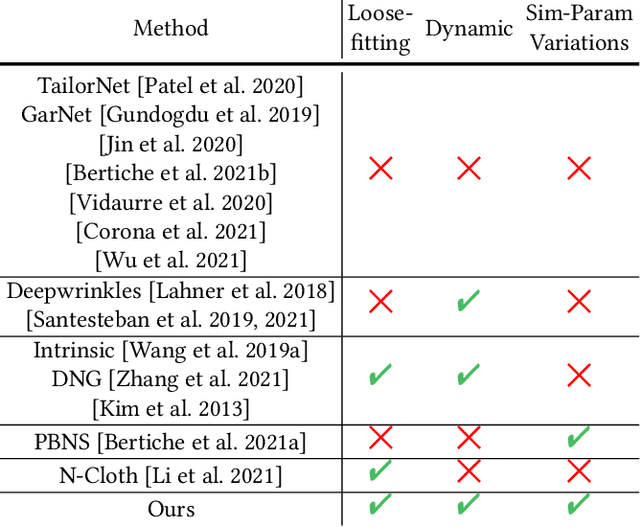
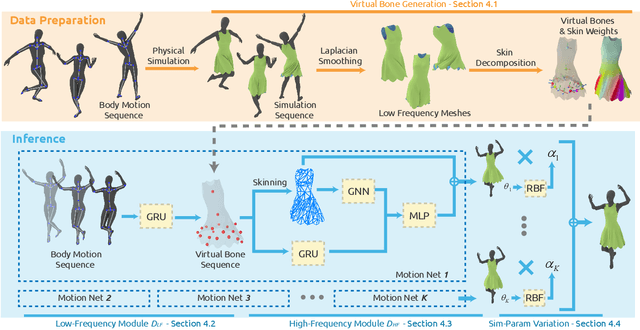
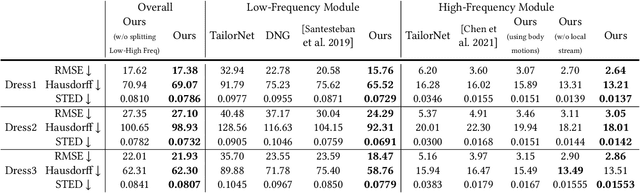
We present a learning algorithm that uses bone-driven motion networks to predict the deformation of loose-fitting garment meshes at interactive rates. Given a garment, we generate a simulation database and extract virtual bones from simulated mesh sequences using skin decomposition. At runtime, we separately compute low- and high-frequency deformations in a sequential manner. The low-frequency deformations are predicted by transferring body motions to virtual bones' motions, and the high-frequency deformations are estimated leveraging the global information of virtual bones' motions and local information extracted from low-frequency meshes. In addition, our method can estimate garment deformations caused by variations of the simulation parameters (e.g., fabric's bending stiffness) using an RBF kernel ensembling trained networks for different sets of simulation parameters. Through extensive comparisons, we show that our method outperforms state-of-the-art methods in terms of prediction accuracy of mesh deformations by about 20% in RMSE and 10% in Hausdorff distance and STED. The code and data are available at https://github.com/non-void/VirtualBones.
Game-Theoretic Planning for Autonomous Driving among Risk-Aware Human Drivers
May 01, 2022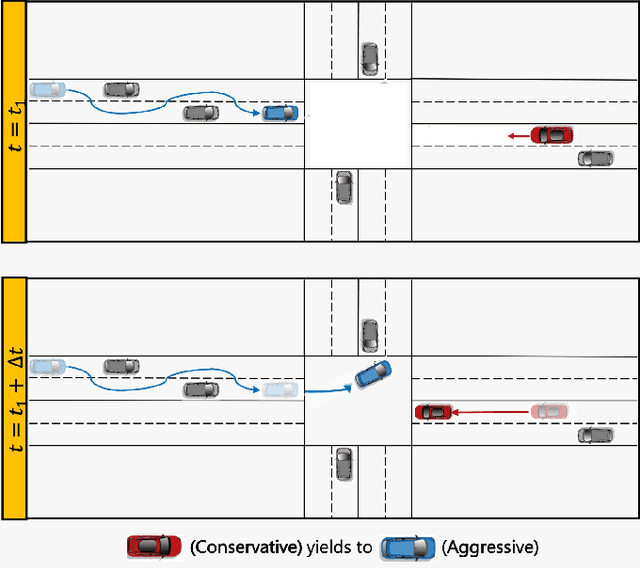
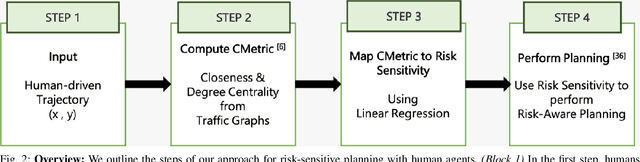
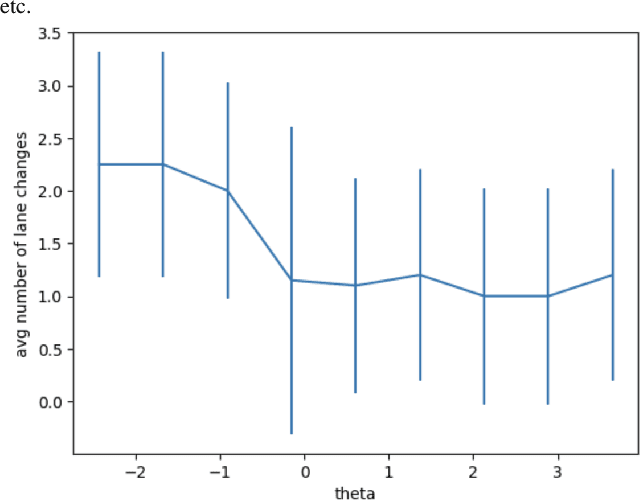
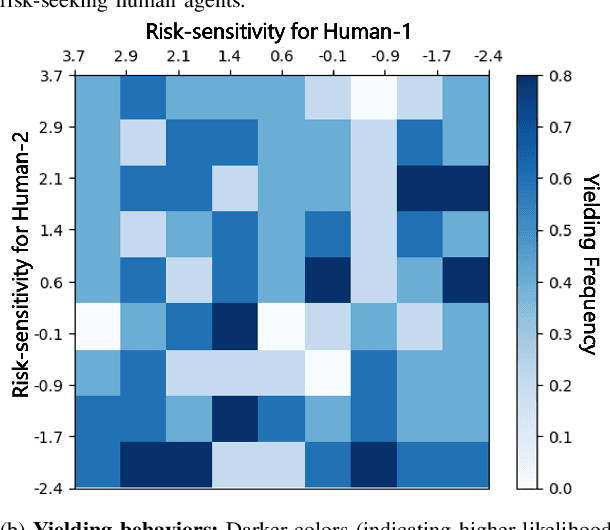
We present a novel approach for risk-aware planning with human agents in multi-agent traffic scenarios. Our approach takes into account the wide range of human driver behaviors on the road, from aggressive maneuvers like speeding and overtaking, to conservative traits like driving slowly and conforming to the right-most lane. In our approach, we learn a mapping from a data-driven human driver behavior model called the CMetric to a driver's entropic risk preference. We then use the derived risk preference within a game-theoretic risk-sensitive planner to model risk-aware interactions among human drivers and an autonomous vehicle in various traffic scenarios. We demonstrate our method in a merging scenario, where our results show that the final trajectories obtained from the risk-aware planner generate desirable emergent behaviors. Particularly, our planner recognizes aggressive human drivers and yields to them while maintaining a greater distance from them. In a user study, participants were able to distinguish between aggressive and conservative simulated drivers based on trajectories generated from our risk-sensitive planner. We also observe that aggressive human driving results in more frequent lane-changing in the planner. Finally, we compare the performance of our modified risk-aware planner with existing methods and show that modeling human driver behavior leads to safer navigation.
GWA: A Large High-Quality Acoustic Dataset for Audio Processing
Apr 04, 2022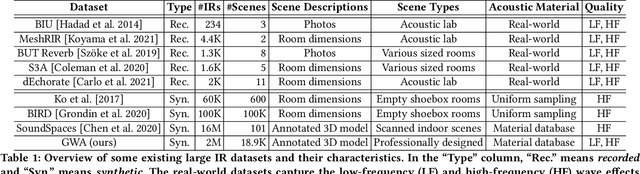
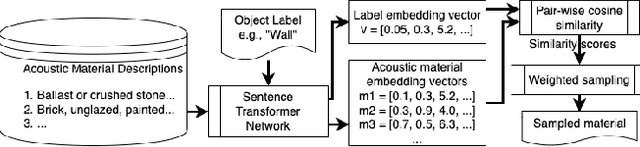

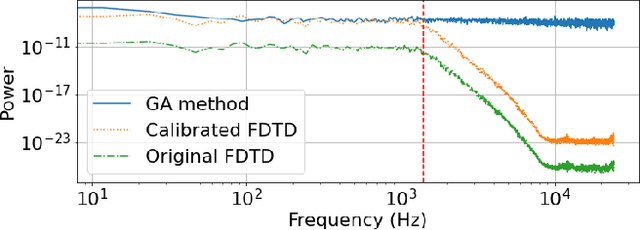
We present the Geometric-Wave Acoustic (GWA) dataset, a large-scale audio dataset of over 2 million synthetic room impulse responses (IRs) and their corresponding detailed geometric and simulation configurations. Our dataset samples acoustic environments from over 6.8K high-quality diverse and professionally designed houses represented as semantically labeled 3D meshes. We also present a novel real-world acoustic materials assignment scheme based on semantic matching that uses a sentence transformer model. We compute high-quality impulse responses corresponding to accurate low-frequency and high-frequency wave effects by automatically calibrating geometric acoustic ray-tracing with a finite-difference time-domain wave solver. We demonstrate the higher accuracy of our IRs by comparing with recorded IRs from complex real-world environments. The code and the full dataset will be released at the time of publication. Moreover, we highlight the benefits of GWA on audio deep learning tasks such as automated speech recognition, speech enhancement, and speech separation. We observe significant improvement over prior synthetic IR datasets in all tasks due to using our dataset.
STCrowd: A Multimodal Dataset for Pedestrian Perception in Crowded Scenes
Apr 03, 2022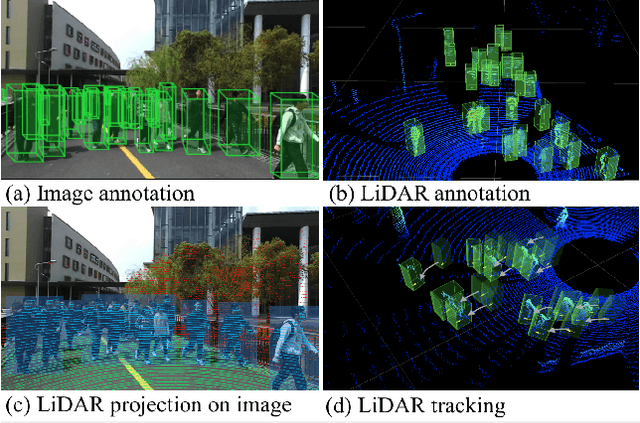
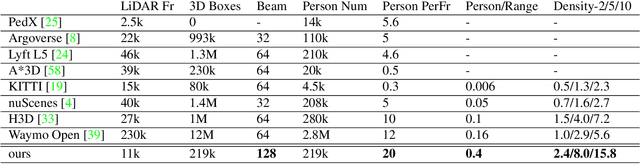

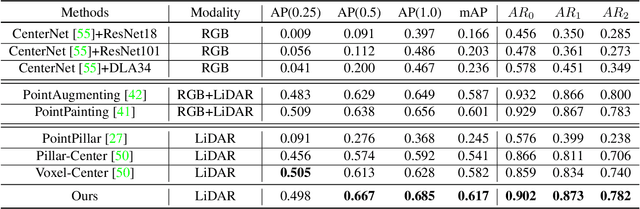
Accurately detecting and tracking pedestrians in 3D space is challenging due to large variations in rotations, poses and scales. The situation becomes even worse for dense crowds with severe occlusions. However, existing benchmarks either only provide 2D annotations, or have limited 3D annotations with low-density pedestrian distribution, making it difficult to build a reliable pedestrian perception system especially in crowded scenes. To better evaluate pedestrian perception algorithms in crowded scenarios, we introduce a large-scale multimodal dataset,STCrowd. Specifically, in STCrowd, there are a total of 219 K pedestrian instances and 20 persons per frame on average, with various levels of occlusion. We provide synchronized LiDAR point clouds and camera images as well as their corresponding 3D labels and joint IDs. STCrowd can be used for various tasks, including LiDAR-only, image-only, and sensor-fusion based pedestrian detection and tracking. We provide baselines for most of the tasks. In addition, considering the property of sparse global distribution and density-varying local distribution of pedestrians, we further propose a novel method, Density-aware Hierarchical heatmap Aggregation (DHA), to enhance pedestrian perception in crowded scenes. Extensive experiments show that our new method achieves state-of-the-art performance for pedestrian detection on various datasets.
3MASSIV: Multilingual, Multimodal and Multi-Aspect dataset of Social Media Short Videos
Mar 28, 2022
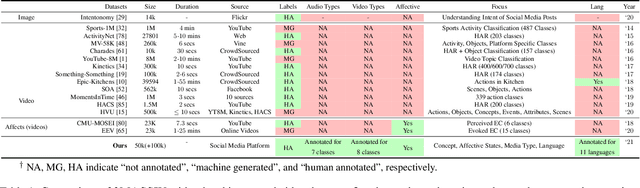

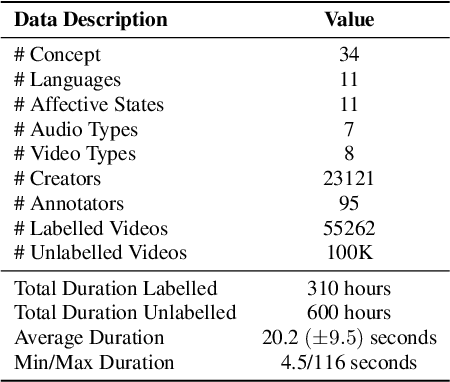
We present 3MASSIV, a multilingual, multimodal and multi-aspect, expertly-annotated dataset of diverse short videos extracted from short-video social media platform - Moj. 3MASSIV comprises of 50k short videos (20 seconds average duration) and 100K unlabeled videos in 11 different languages and captures popular short video trends like pranks, fails, romance, comedy expressed via unique audio-visual formats like self-shot videos, reaction videos, lip-synching, self-sung songs, etc. 3MASSIV presents an opportunity for multimodal and multilingual semantic understanding on these unique videos by annotating them for concepts, affective states, media types, and audio language. We present a thorough analysis of 3MASSIV and highlight the variety and unique aspects of our dataset compared to other contemporary popular datasets with strong baselines. We also show how the social media content in 3MASSIV is dynamic and temporal in nature, which can be used for semantic understanding tasks and cross-lingual analysis.
Fourier Disentangled Space-Time Attention for Aerial Video Recognition
Mar 21, 2022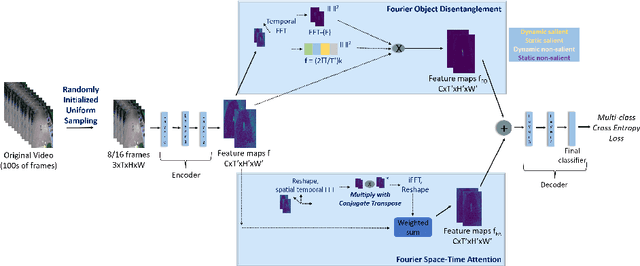


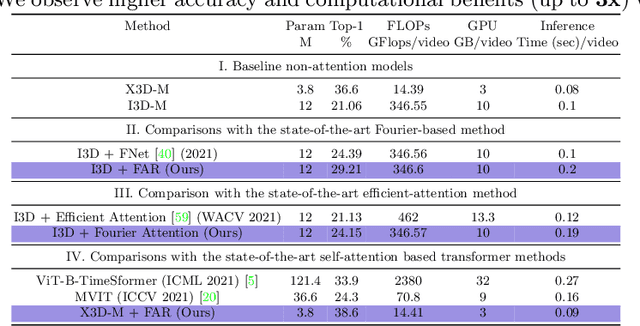
We present an algorithm, Fourier Activity Recognition (FAR), for UAV video activity recognition. Our formulation uses a novel Fourier object disentanglement method to innately separate out the human agent (which is typically small) from the background. Our disentanglement technique operates in the frequency domain to characterize the extent of temporal change of spatial pixels, and exploits convolution-multiplication properties of Fourier transform to map this representation to the corresponding object-background entangled features obtained from the network. To encapsulate contextual information and long-range space-time dependencies, we present a novel Fourier Attention algorithm, which emulates the benefits of self-attention by modeling the weighted outer product in the frequency domain. Our Fourier attention formulation uses much fewer computations than self-attention. We have evaluated our approach on multiple UAV datasets including UAV Human RGB, UAV Human Night, Drone Action, and NEC Drone. We demonstrate a relative improvement of 8.02% - 38.69% in top-1 accuracy and up to 3 times faster over prior works.
GAMEOPT: Optimal Real-time Multi-Agent Planning and Control for Dynamic Intersections
Mar 18, 2022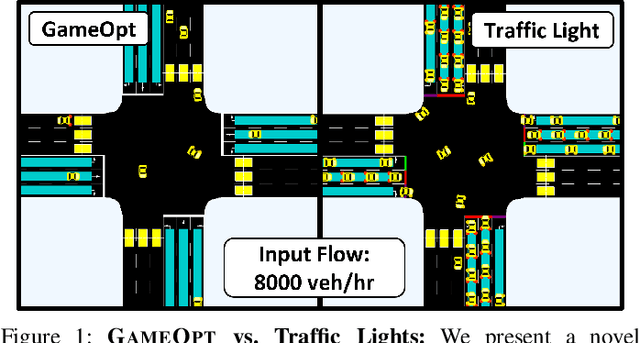
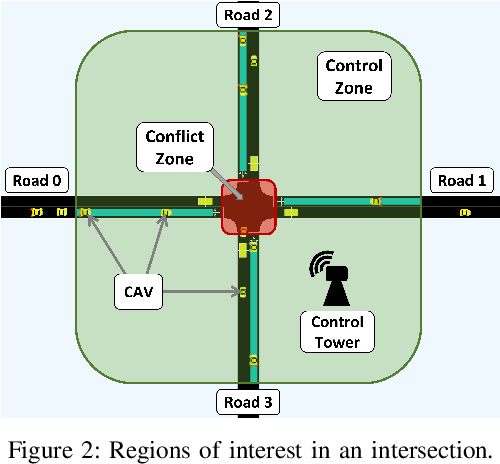
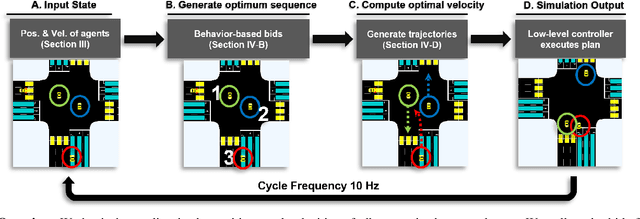
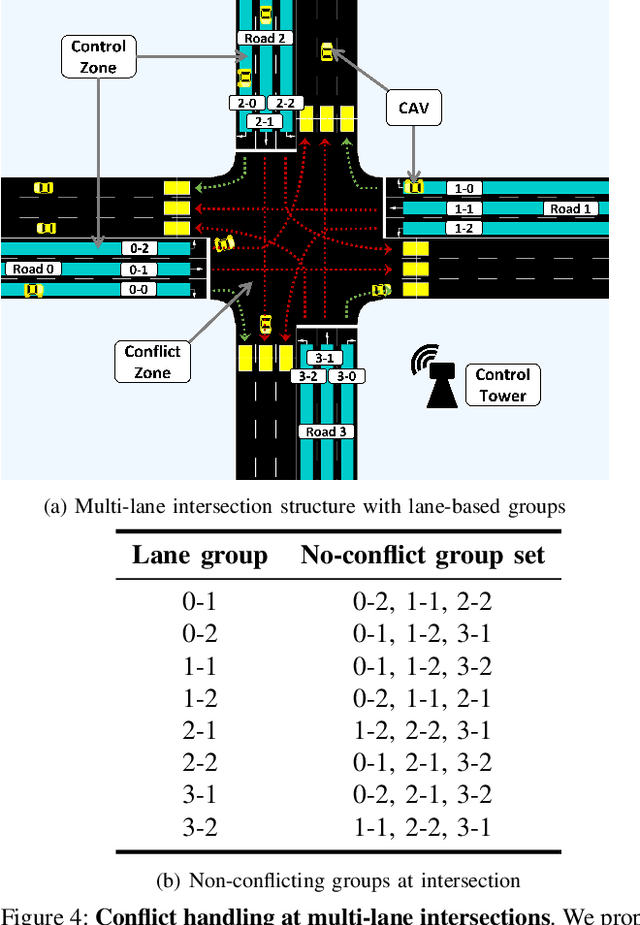
We propose GameOpt: a novel hybrid approach to cooperative intersection control for dynamic, multi-lane, unsignalized intersections. Safely navigating these complex and accident prone intersections requires simultaneous trajectory planning and negotiation among drivers. GameOpt is a hybrid formulation that first uses an auction mechanism to generate a priority entrance sequence for every agent, followed by an optimization-based trajectory planner that computes velocity controls that satisfy the priority sequence. This coupling operates at real-time speeds of less than 10 milliseconds in high density traffic of more than 10,000 vehicles/hr, 100 times faster than other fully optimization-based methods, while providing guarantees in terms of fairness, safety, and efficiency. Tested on the SUMO simulator, our algorithm improves throughput by at least 25%, time taken to reach the goal by 75%, and fuel consumption by 33% compared to auction-based approaches and signaled approaches using traffic-lights and stop signs.