 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanoptic-FlashOcc: An Efficient Baseline to Marry Semantic Occupancy with Panoptic via Instance Center
Jun 15, 2024Panoptic occupancy poses a novel challenge by aiming to integrate instance occupancy and semantic occupancy within a unified framework. However, there is still a lack of efficient solutions for panoptic occupancy. In this paper, we propose Panoptic-FlashOcc, a straightforward yet robust 2D feature framework that enables realtime panoptic occupancy. Building upon the lightweight design of FlashOcc, our approach simultaneously learns semantic occupancy and class-aware instance clustering in a single network, these outputs are jointly incorporated through panoptic occupancy procession for panoptic occupancy. This approach effectively addresses the drawbacks of high memory and computation requirements associated with three-dimensional voxel-level representations. With its straightforward and efficient design that facilitates easy deployment, Panoptic-FlashOcc demonstrates remarkable achievements in panoptic occupancy prediction. On the Occ3D-nuScenes benchmark, it achieves exceptional performance, with 38.5 RayIoU and 29.1 mIoU for semantic occupancy, operating at a rapid speed of 43.9 FPS. Furthermore, it attains a notable score of 16.0 RayPQ for panoptic occupancy, accompanied by a fast inference speed of 30.2 FPS. These results surpass the performance of existing methodologies in terms of both speed and accuracy. The source code and trained models can be found at the following github repository: https://github.com/Yzichen/FlashOCC.
FlashOcc: Fast and Memory-Efficient Occupancy Prediction via Channel-to-Height Plugin
Nov 18, 2023



Given the capability of mitigating the long-tail deficiencies and intricate-shaped absence prevalent in 3D object detection, occupancy prediction has become a pivotal component in autonomous driving systems. However, the procession of three-dimensional voxel-level representations inevitably introduces large overhead in both memory and computation, obstructing the deployment of to-date occupancy prediction approaches. In contrast to the trend of making the model larger and more complicated, we argue that a desirable framework should be deployment-friendly to diverse chips while maintaining high precision. To this end, we propose a plug-and-play paradigm, namely FlashOCC, to consolidate rapid and memory-efficient occupancy prediction while maintaining high precision. Particularly, our FlashOCC makes two improvements based on the contemporary voxel-level occupancy prediction approaches. Firstly, the features are kept in the BEV, enabling the employment of efficient 2D convolutional layers for feature extraction. Secondly, a channel-to-height transformation is introduced to lift the output logits from the BEV into the 3D space. We apply the FlashOCC to diverse occupancy prediction baselines on the challenging Occ3D-nuScenes benchmarks and conduct extensive experiments to validate the effectiveness. The results substantiate the superiority of our plug-and-play paradigm over previous state-of-the-art methods in terms of precision, runtime efficiency, and memory costs, demonstrating its potential for deployment. The code will be made available.
AutoShape: Real-Time Shape-Aware Monocular 3D Object Detection
Aug 25, 2021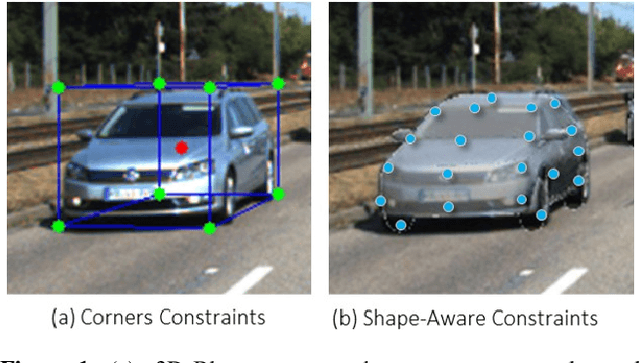
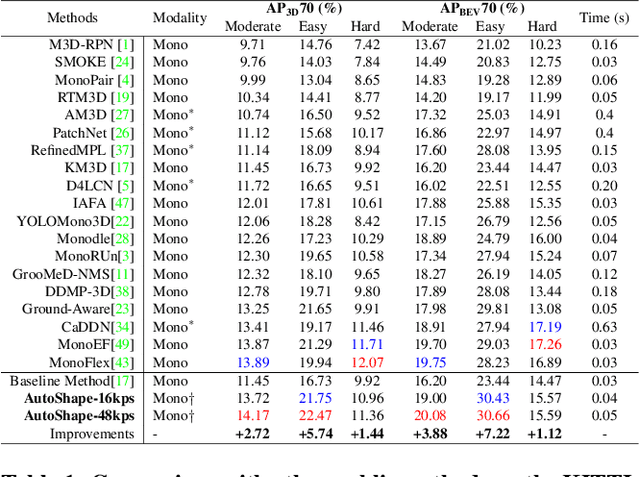
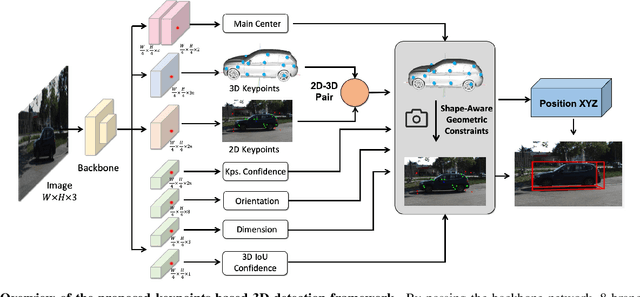
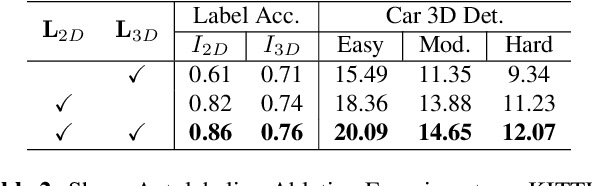
Existing deep learning-based approaches for monocular 3D object detection in autonomous driving often model the object as a rotated 3D cuboid while the object's geometric shape has been ignored. In this work, we propose an approach for incorporating the shape-aware 2D/3D constraints into the 3D detection framework. Specifically, we employ the deep neural network to learn distinguished 2D keypoints in the 2D image domain and regress their corresponding 3D coordinates in the local 3D object coordinate first. Then the 2D/3D geometric constraints are built by these correspondences for each object to boost the detection performance. For generating the ground truth of 2D/3D keypoints, an automatic model-fitting approach has been proposed by fitting the deformed 3D object model and the object mask in the 2D image. The proposed framework has been verified on the public KITTI dataset and the experimental results demonstrate that by using additional geometrical constraints the detection performance has been significantly improved as compared to the baseline method. More importantly, the proposed framework achieves state-of-the-art performance with real time. Data and code will be available at https://github.com/zongdai/AutoShape
Robust 2D/3D Vehicle Parsing in CVIS
Mar 11, 2021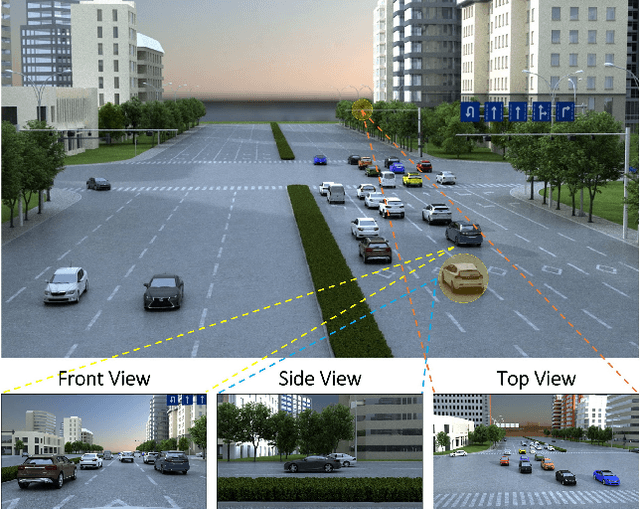
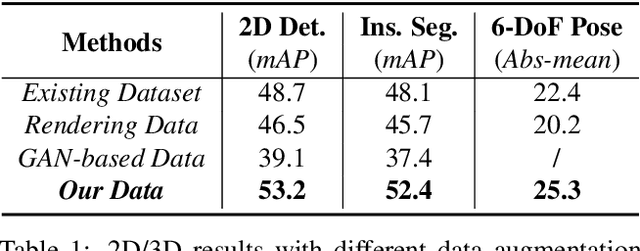
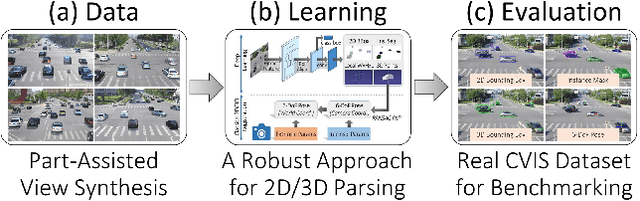
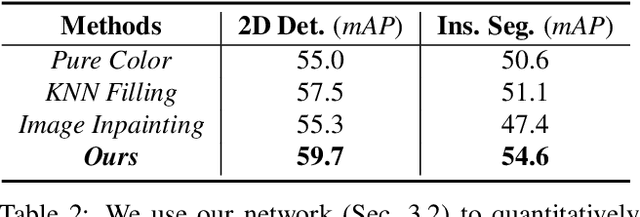
We present a novel approach to robustly detect and perceive vehicles in different camera views as part of a cooperative vehicle-infrastructure system (CVIS). Our formulation is designed for arbitrary camera views and makes no assumptions about intrinsic or extrinsic parameters. First, to deal with multi-view data scarcity, we propose a part-assisted novel view synthesis algorithm for data augmentation. We train a part-based texture inpainting network in a self-supervised manner. Then we render the textured model into the background image with the target 6-DoF pose. Second, to handle various camera parameters, we present a new method that produces dense mappings between image pixels and 3D points to perform robust 2D/3D vehicle parsing. Third, we build the first CVIS dataset for benchmarking, which annotates more than 1540 images (14017 instances) from real-world traffic scenarios. We combine these novel algorithms and datasets to develop a robust approach for 2D/3D vehicle parsing for CVIS. In practice, our approach outperforms SOTA methods on 2D detection, instance segmentation, and 6-DoF pose estimation, by 4.5%, 4.3%, and 2.9%, respectively. More details and results are included in the supplement. To facilitate future research, we will release the source code and the dataset on GitHub.
Fine-Grained Vehicle Perception via 3D Part-Guided Visual Data Augmentation
Jan 06, 2021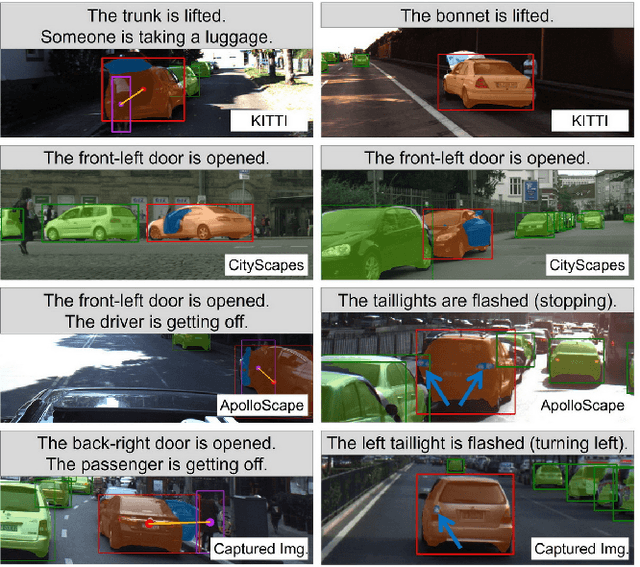
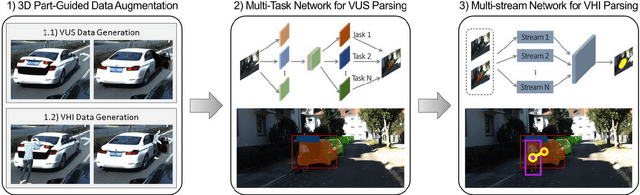
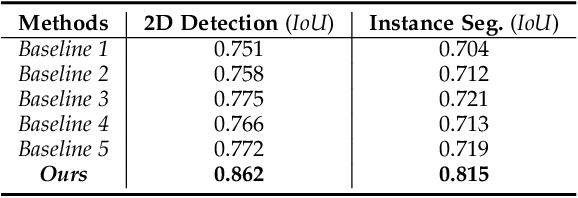
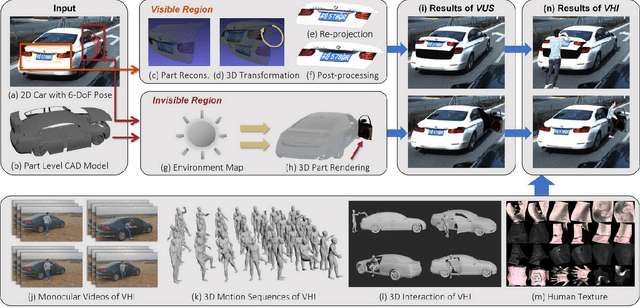
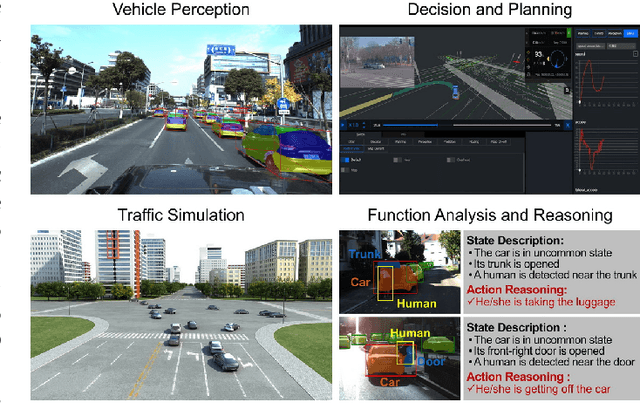
Holistically understanding an object and its 3D movable parts through visual perception models is essential for enabling an autonomous agent to interact with the world. For autonomous driving, the dynamics and states of vehicle parts such as doors, the trunk, and the bonnet can provide meaningful semantic information and interaction states, which are essential to ensuring the safety of the self-driving vehicle. Existing visual perception models mainly focus on coarse parsing such as object bounding box detection or pose estimation and rarely tackle these situations. In this paper, we address this important autonomous driving problem by solving three critical issues. First, to deal with data scarcity, we propose an effective training data generation process by fitting a 3D car model with dynamic parts to vehicles in real images before reconstructing human-vehicle interaction (VHI) scenarios. Our approach is fully automatic without any human interaction, which can generate a large number of vehicles in uncommon states (VUS) for training deep neural networks (DNNs). Second, to perform fine-grained vehicle perception, we present a multi-task network for VUS parsing and a multi-stream network for VHI parsing. Third, to quantitatively evaluate the effectiveness of our data augmentation approach, we build the first VUS dataset in real traffic scenarios (e.g., getting on/out or placing/removing luggage). Experimental results show that our approach advances other baseline methods in 2D detection and instance segmentation by a big margin (over 8%). In addition, our network yields large improvements in discovering and understanding these uncommon cases. Moreover, we have released the source code, the dataset, and the trained model on Github (https://github.com/zongdai/EditingForDNN).
PerMO: Perceiving More at Once from a Single Image for Autonomous Driving
Jul 16, 2020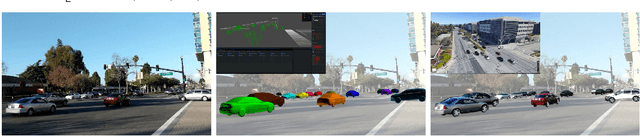

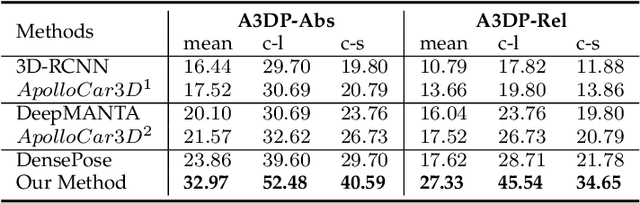
We present a novel approach to detect, segment, and reconstruct complete textured 3D models of vehicles from a single image for autonomous driving. Our approach combines the strengths of deep learning and the elegance of traditional techniques from part-based deformable model representation to produce high-quality 3D models in the presence of severe occlusions. We present a new part-based deformable vehicle model that is used for instance segmentation and automatically generate a dataset that contains dense correspondences between 2D images and 3D models. We also present a novel end-to-end deep neural network to predict dense 2D/3D mapping and highlight its benefits. Based on the dense mapping, we are able to compute precise 6-DoF poses and 3D reconstruction results at almost interactive rates on a commodity GPU. We have integrated these algorithms with an autonomous driving system. In practice, our method outperforms the state-of-the-art methods for all major vehicle parsing tasks: 2D instance segmentation by 4.4 points (mAP), 6-DoF pose estimation by 9.11 points, and 3D detection by 1.37. Moreover, we have released all of the source code, dataset, and the trained model on Github.