 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Advantage Optimization for Model-Based Reinforcement Learning
Jun 26, 2021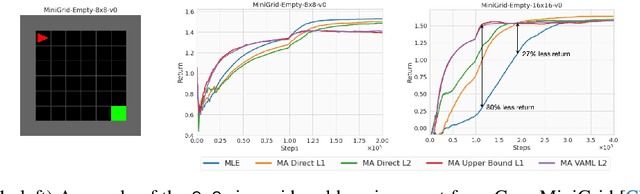
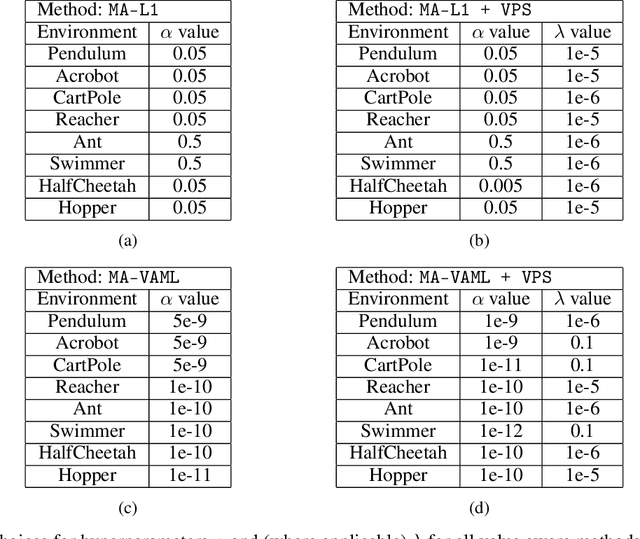
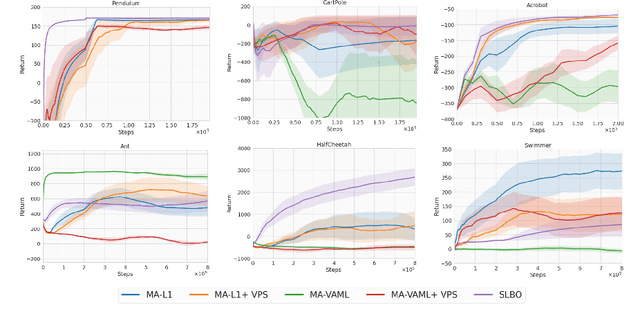
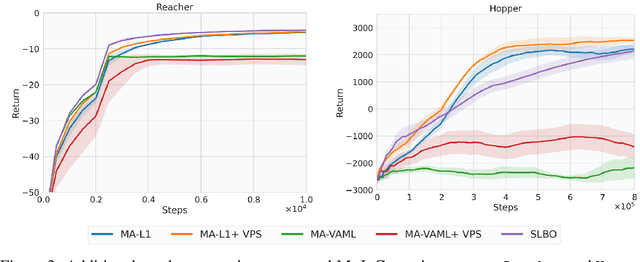
Model-based Reinforcement Learning (MBRL) algorithms have been traditionally designed with the goal of learning accurate dynamics of the environment. This introduces a mismatch between the objectives of model-learning and the overall learning problem of finding an optimal policy. Value-aware model learning, an alternative model-learning paradigm to maximum likelihood, proposes to inform model-learning through the value function of the learnt policy. While this paradigm is theoretically sound, it does not scale beyond toy settings. In this work, we propose a novel value-aware objective that is an upper bound on the absolute performance difference of a policy across two models. Further, we propose a general purpose algorithm that modifies the standard MBRL pipeline -- enabling learning with value aware objectives. Our proposed objective, in conjunction with this algorithm, is the first successful instantiation of value-aware MBRL on challenging continuous control environments, outperforming previous value-aware objectives and with competitive performance w.r.t. MLE-based MBRL approaches.
Auxiliary Tasks and Exploration Enable ObjectNav
Apr 08, 2021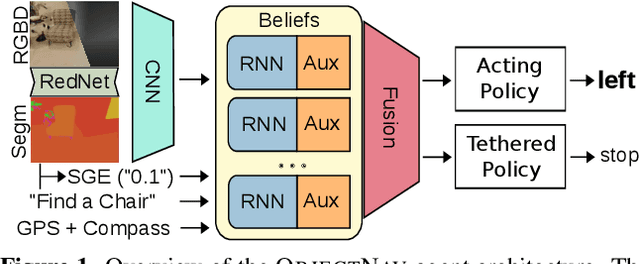
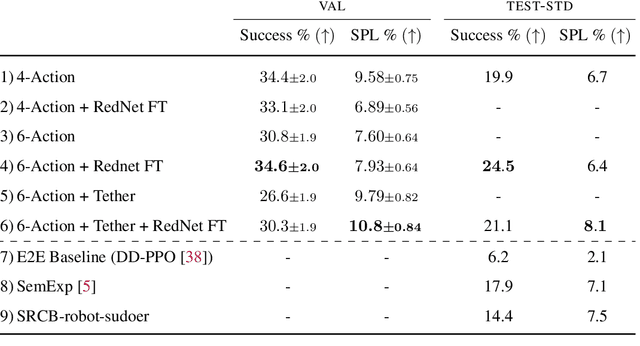
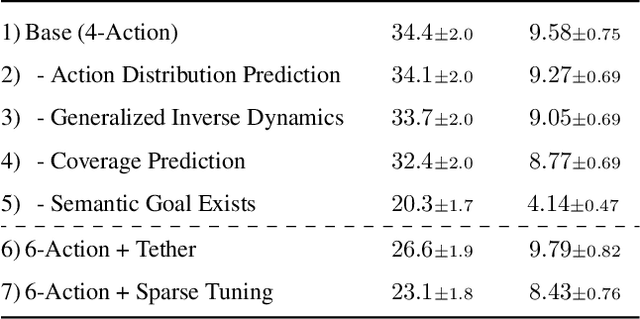
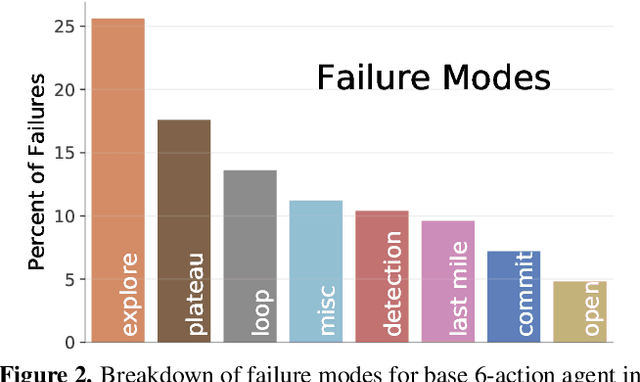
ObjectGoal Navigation (ObjectNav) is an embodied task wherein agents are to navigate to an object instance in an unseen environment. Prior works have shown that end-to-end ObjectNav agents that use vanilla visual and recurrent modules, e.g. a CNN+RNN, perform poorly due to overfitting and sample inefficiency. This has motivated current state-of-the-art methods to mix analytic and learned components and operate on explicit spatial maps of the environment. We instead re-enable a generic learned agent by adding auxiliary learning tasks and an exploration reward. Our agents achieve 24.5% success and 8.1% SPL, a 37% and 8% relative improvement over prior state-of-the-art, respectively, on the Habitat ObjectNav Challenge. From our analysis, we propose that agents will act to simplify their visual inputs so as to smooth their RNN dynamics, and that auxiliary tasks reduce overfitting by minimizing effective RNN dimensionality; i.e. a performant ObjectNav agent that must maintain coherent plans over long horizons does so by learning smooth, low-dimensional recurrent dynamics. Site: https://joel99.github.io/objectnav/
Success Weighted by Completion Time: A Dynamics-Aware Evaluation Criteria for Embodied Navigation
Mar 14, 2021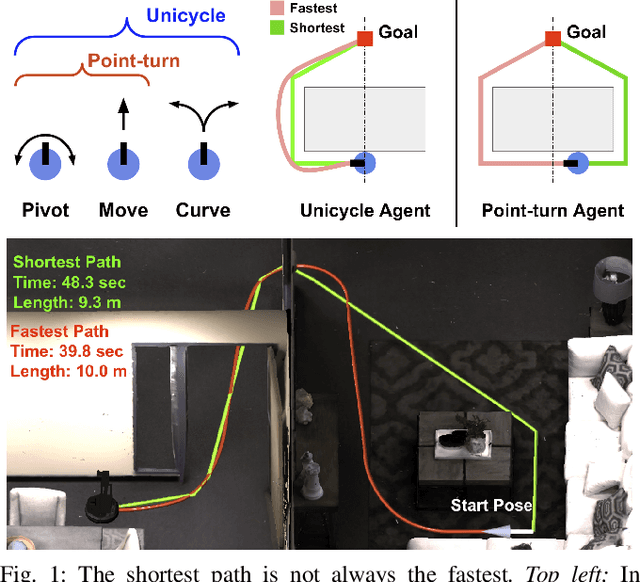
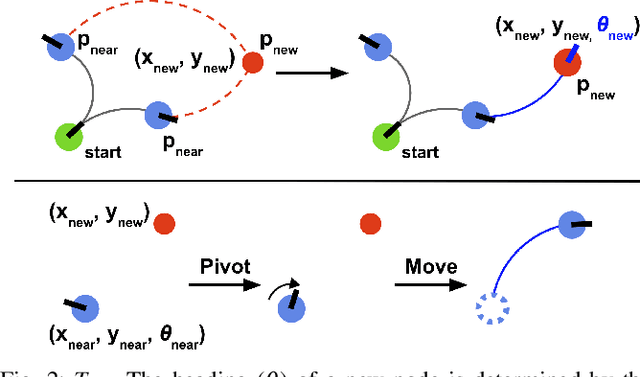

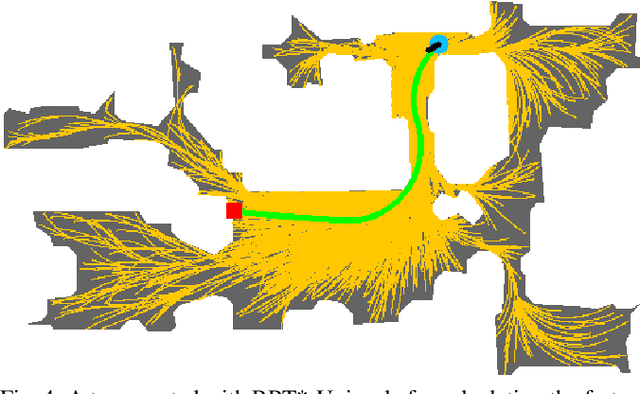
We present Success weighted by Completion Time (SCT), a new metric for evaluating navigation performance for mobile robots. Several related works on navigation have used Success weighted by Path Length (SPL) as the primary method of evaluating the path an agent makes to a goal location, but SPL is limited in its ability to properly evaluate agents with complex dynamics. In contrast, SCT explicitly takes the agent's dynamics model into consideration, and aims to accurately capture how well the agent has approximated the fastest navigation behavior afforded by its dynamics. While several embodied navigation works use point-turn dynamics, we focus on unicycle-cart dynamics for our agent, which better exemplifies the dynamics model of popular mobile robotics platforms (e.g., LoCoBot, TurtleBot, Fetch, etc.). We also present RRT*-Unicycle, an algorithm for unicycle dynamics that estimates the fastest collision-free path and completion time from a starting pose to a goal location in an environment containing obstacles. We experiment with deep reinforcement learning and reward shaping to train and compare the navigation performance of agents with different dynamics models. In evaluating these agents, we show that in contrast to SPL, SCT is able to capture the advantages in navigation speed a unicycle model has over a simpler point-turn model of dynamics. Lastly, we show that we can successfully deploy our trained models and algorithms outside of simulation in the real world. We embody our agents in an real robot to navigate an apartment, and show that they can generalize in a zero-shot manner.
Large Batch Simulation for Deep Reinforcement Learning
Mar 12, 2021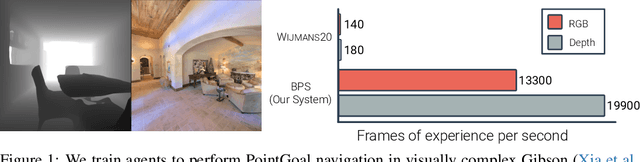
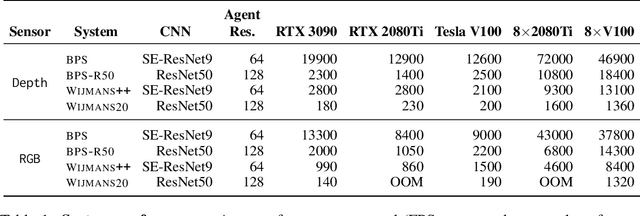
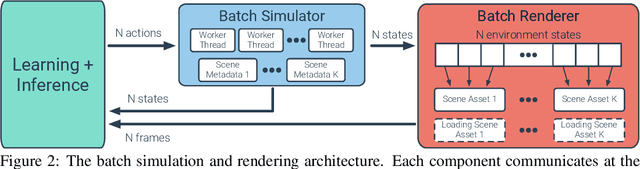
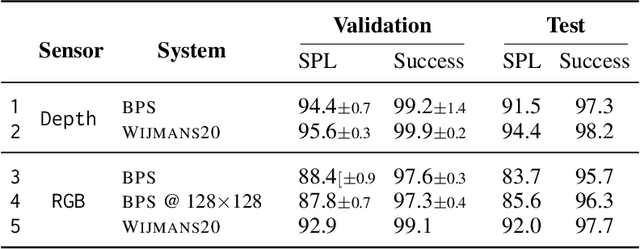
We accelerate deep reinforcement learning-based training in visually complex 3D environments by two orders of magnitude over prior work, realizing end-to-end training speeds of over 19,000 frames of experience per second on a single GPU and up to 72,000 frames per second on a single eight-GPU machine. The key idea of our approach is to design a 3D renderer and embodied navigation simulator around the principle of "batch simulation": accepting and executing large batches of requests simultaneously. Beyond exposing large amounts of work at once, batch simulation allows implementations to amortize in-memory storage of scene assets, rendering work, data loading, and synchronization costs across many simulation requests, dramatically improving the number of simulated agents per GPU and overall simulation throughput. To balance DNN inference and training costs with faster simulation, we also build a computationally efficient policy DNN that maintains high task performance, and modify training algorithms to maintain sample efficiency when training with large mini-batches. By combining batch simulation and DNN performance optimizations, we demonstrate that PointGoal navigation agents can be trained in complex 3D environments on a single GPU in 1.5 days to 97% of the accuracy of agents trained on a prior state-of-the-art system using a 64-GPU cluster over three days. We provide open-source reference implementations of our batch 3D renderer and simulator to facilitate incorporation of these ideas into RL systems.
Memory-Augmented Reinforcement Learning for Image-Goal Navigation
Jan 13, 2021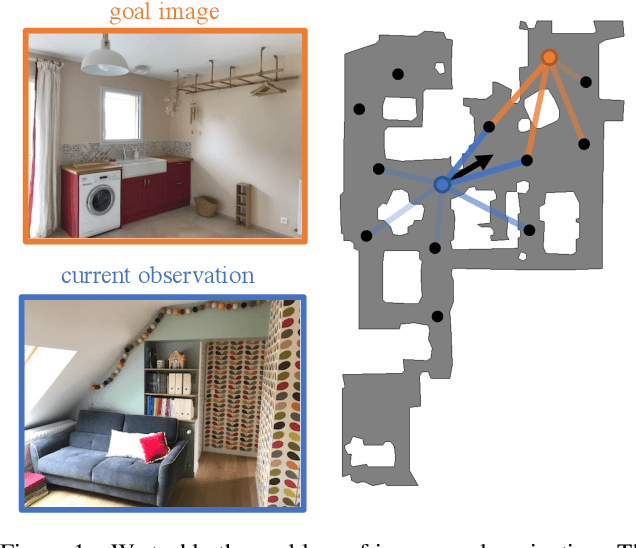
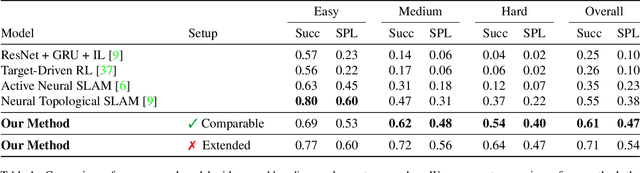
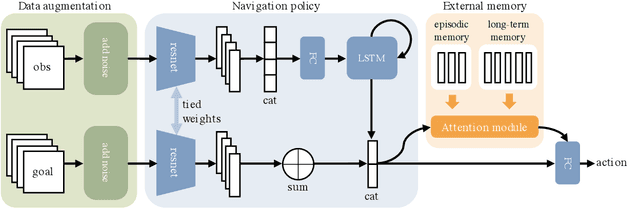
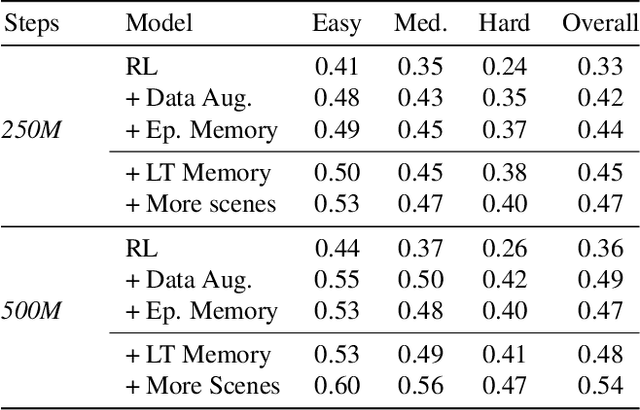
In this work, we address the problem of image-goal navigation in the context of visually-realistic 3D environments. This task involves navigating to a location indicated by a target image in a previously unseen environment. Earlier attempts, including RL-based and SLAM-based approaches, have either shown poor generalization performance, or are heavily-reliant on pose/depth sensors. We present a novel method that leverages a cross-episode memory to learn to navigate. We first train a state-embedding network in a self-supervised fashion, and then use it to embed previously-visited states into a memory. In order to avoid overfitting, we propose to use data augmentation on the RGB input during training. We validate our approach through extensive evaluations, showing that our data-augmented memory-based model establishes a new state of the art on the image-goal navigation task in the challenging Gibson dataset. We obtain this competitive performance from RGB input only, without access to additional sensors such as position or depth.
How to Train PointGoal Navigation Agents on a Budget
Dec 11, 2020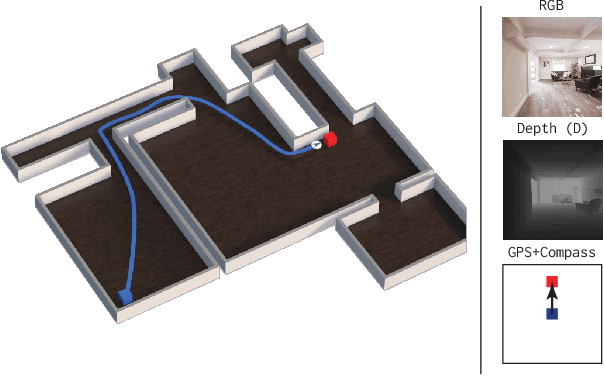
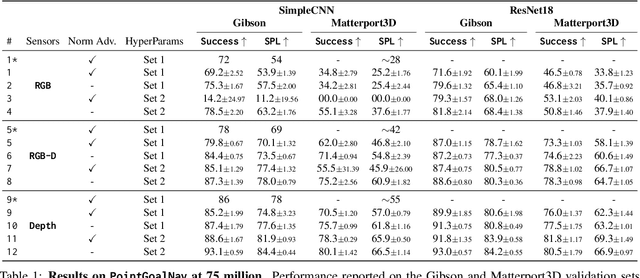
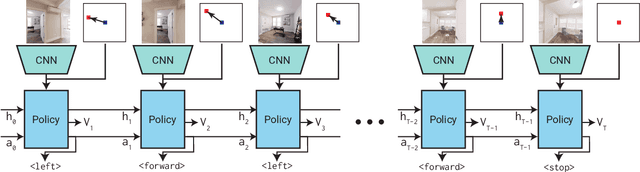
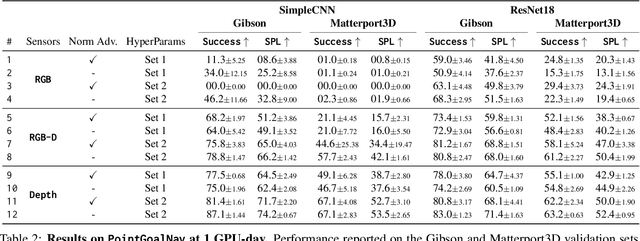
PointGoal navigation has seen significant recent interest and progress, spurred on by the Habitat platform and associated challenge. In this paper, we study PointGoal navigation under both a sample budget (75 million frames) and a compute budget (1 GPU for 1 day). We conduct an extensive set of experiments, cumulatively totaling over 50,000 GPU-hours, that let us identify and discuss a number of ostensibly minor but significant design choices -- the advantage estimation procedure (a key component in training), visual encoder architecture, and a seemingly minor hyper-parameter change. Overall, these design choices to lead considerable and consistent improvements over the baselines present in Savva et al. Under a sample budget, performance for RGB-D agents improves 8 SPL on Gibson (14% relative improvement) and 20 SPL on Matterport3D (38% relative improvement). Under a compute budget, performance for RGB-D agents improves by 19 SPL on Gibson (32% relative improvement) and 35 SPL on Matterport3D (220% relative improvement). We hope our findings and recommendations will make serve to make the community's experiments more efficient.
Bi-directional Domain Adaptation for Sim2Real Transfer of Embodied Navigation Agents
Nov 24, 2020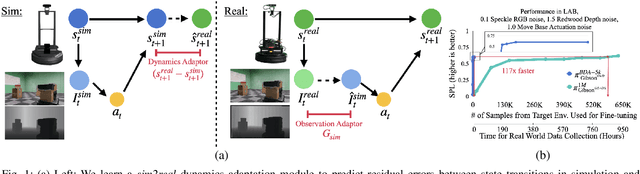


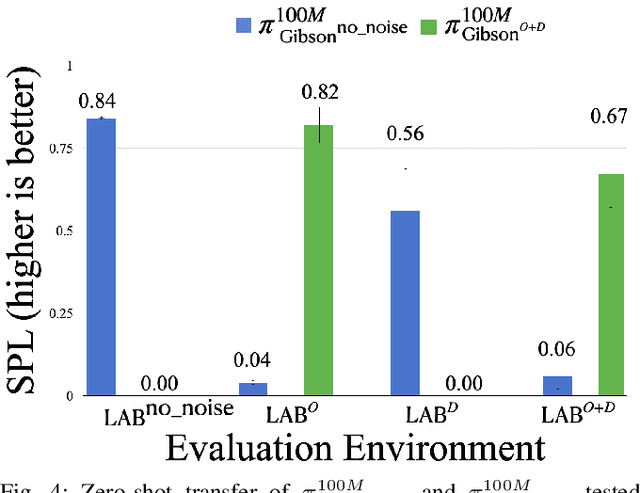
Deep reinforcement learning models are notoriously data hungry, yet real-world data is expensive and time consuming to obtain. The solution that many have turned to is to use simulation for training before deploying the robot in a real environment. Simulation offers the ability to train large numbers of robots in parallel, and offers an abundance of data. However, no simulation is perfect, and robots trained solely in simulation fail to generalize to the real-world, resulting in a "sim-vs-real gap". How can we overcome the trade-off between the abundance of less accurate, artificial data from simulators and the scarcity of reliable, real-world data? In this paper, we propose Bi-directional Domain Adaptation (BDA), a novel approach to bridge the sim-vs-real gap in both directions -- real2sim to bridge the visual domain gap, and sim2real to bridge the dynamics domain gap. We demonstrate the benefits of BDA on the task of PointGoal Navigation. BDA with only 5k real-world (state, action, next-state) samples matches the performance of a policy fine-tuned with ~600k samples, resulting in a speed-up of ~120x.
Learning Navigation Skills for Legged Robots with Learned Robot Embeddings
Nov 24, 2020

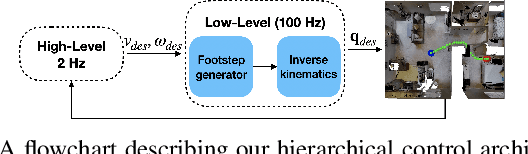
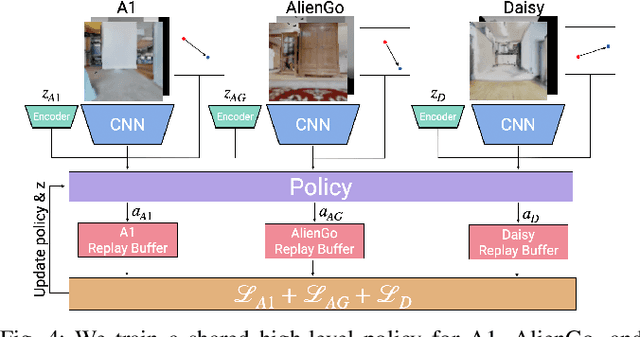
Navigation policies are commonly learned on idealized cylinder agents in simulation, without modelling complex dynamics, like contact dynamics, arising from the interaction between the robot and the environment. Such policies perform poorly when deployed on complex and dynamic robots, such as legged robots. In this work, we learn hierarchical navigation policies that account for the low-level dynamics of legged robots, such as maximum speed, slipping, and achieve good performance at navigating cluttered indoor environments. Once such a policy is learned on one legged robot, it does not directly generalize to a different robot due to dynamical differences, which increases the cost of learning such a policy on new robots. To overcome this challenge, we learn dynamics-aware navigation policies across multiple robots with robot-specific embeddings, which enable generalization to new unseen robots. We train our policies across three legged robots - 2 quadrupeds (A1, AlienGo) and a hexapod (Daisy). At test time, we study the performance of our learned policy on two new legged robots (Laikago, 4-legged Daisy) and show that our learned policy can sample-efficiently generalize to previously unseen robots.
Where Are You? Localization from Embodied Dialog
Nov 16, 2020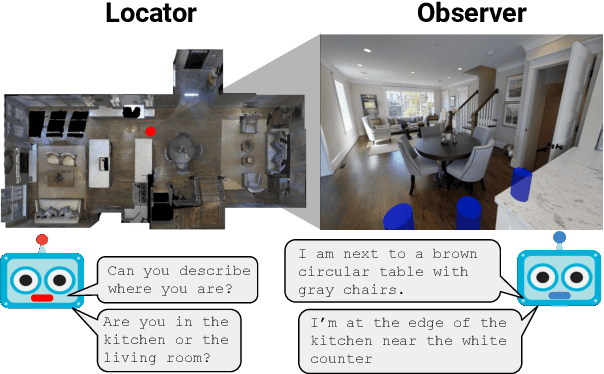
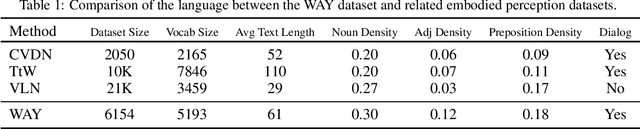
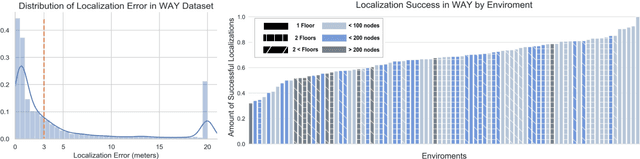
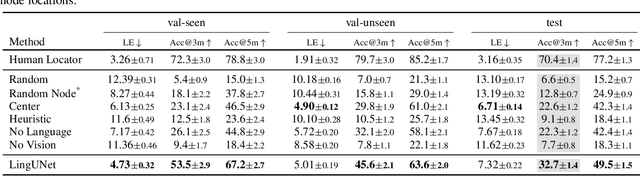
We present Where Are You? (WAY), a dataset of ~6k dialogs in which two humans -- an Observer and a Locator -- complete a cooperative localization task. The Observer is spawned at random in a 3D environment and can navigate from first-person views while answering questions from the Locator. The Locator must localize the Observer in a detailed top-down map by asking questions and giving instructions. Based on this dataset, we define three challenging tasks: Localization from Embodied Dialog or LED (localizing the Observer from dialog history), Embodied Visual Dialog (modeling the Observer), and Cooperative Localization (modeling both agents). In this paper, we focus on the LED task -- providing a strong baseline model with detailed ablations characterizing both dataset biases and the importance of various modeling choices. Our best model achieves 32.7% success at identifying the Observer's location within 3m in unseen buildings, vs. 70.4% for human Locators.
Sim-to-Real Transfer for Vision-and-Language Navigation
Nov 07, 2020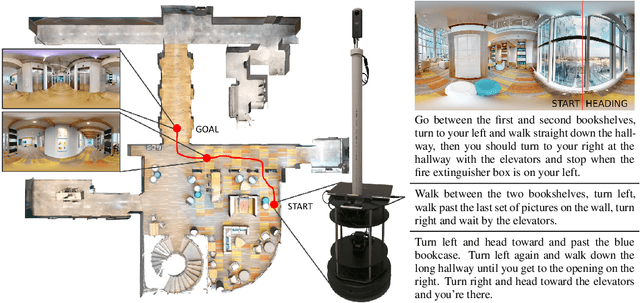

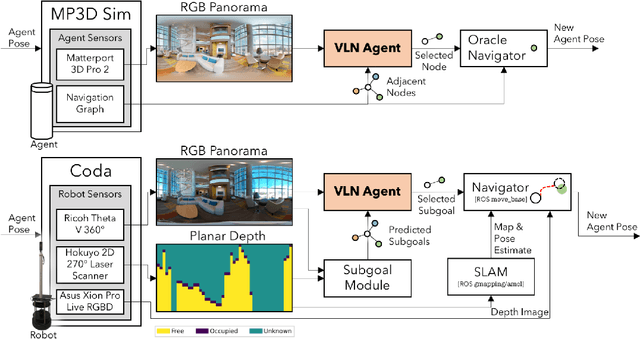

We study the challenging problem of releasing a robot in a previously unseen environment, and having it follow unconstrained natural language navigation instructions. Recent work on the task of Vision-and-Language Navigation (VLN) has achieved significant progress in simulation. To assess the implications of this work for robotics, we transfer a VLN agent trained in simulation to a physical robot. To bridge the gap between the high-level discrete action space learned by the VLN agent, and the robot's low-level continuous action space, we propose a subgoal model to identify nearby waypoints, and use domain randomization to mitigate visual domain differences. For accurate sim and real comparisons in parallel environments, we annotate a 325m2 office space with 1.3km of navigation instructions, and create a digitized replica in simulation. We find that sim-to-real transfer to an environment not seen in training is successful if an occupancy map and navigation graph can be collected and annotated in advance (success rate of 46.8% vs. 55.9% in sim), but much more challenging in the hardest setting with no prior mapping at all (success rate of 22.5%).