 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNCLE-Grasp: Uncertainty-Aware Grasping of Leaf-Occluded Strawberries
Jan 20, 2026Robotic strawberry harvesting is challenging under partial occlusion, where leaves induce significant geometric uncertainty and make grasp decisions based on a single deterministic shape estimate unreliable. From a single partial observation, multiple incompatible 3D completions may be plausible, causing grasps that appear feasible on one completion to fail on another. We propose an uncertainty-aware grasping pipeline for partially occluded strawberries that explicitly models completion uncertainty arising from both occlusion and learned shape reconstruction. Our approach uses point cloud completion with Monte Carlo dropout to sample multiple shape hypotheses, generates candidate grasps for each completion, and evaluates grasp feasibility using physically grounded force-closure-based metrics. Rather than selecting a grasp based on a single estimate, we aggregate feasibility across completions and apply a conservative lower confidence bound (LCB) criterion to decide whether a grasp should be attempted or safely abstained. We evaluate the proposed method in simulation and on a physical robot across increasing levels of synthetic and real leaf occlusion. Results show that uncertainty-aware decision making enables reliable abstention from high-risk grasp attempts under severe occlusion while maintaining robust grasp execution when geometric confidence is sufficient, outperforming deterministic baselines in both simulated and physical robot experiments.
GeoAware-VLA: Implicit Geometry Aware Vision-Language-Action Model
Sep 17, 2025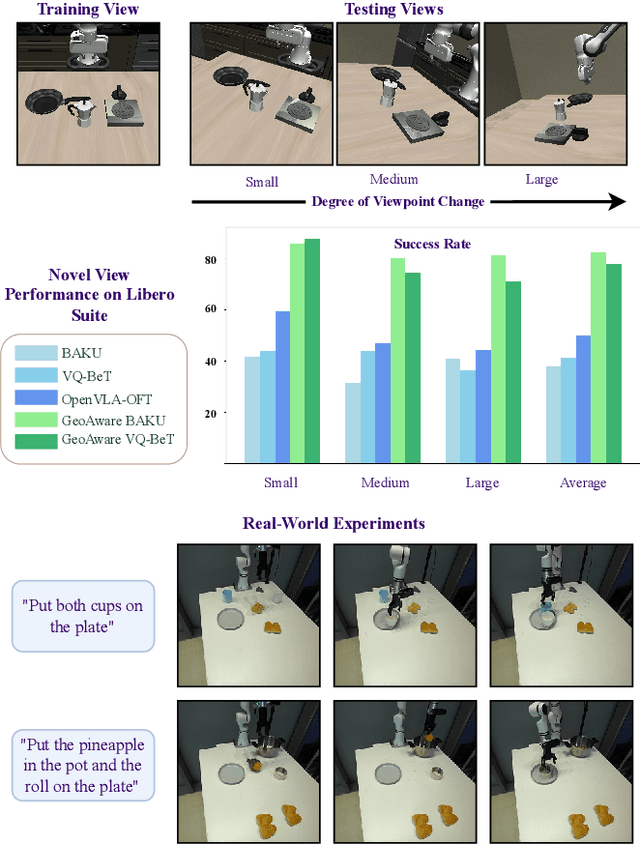
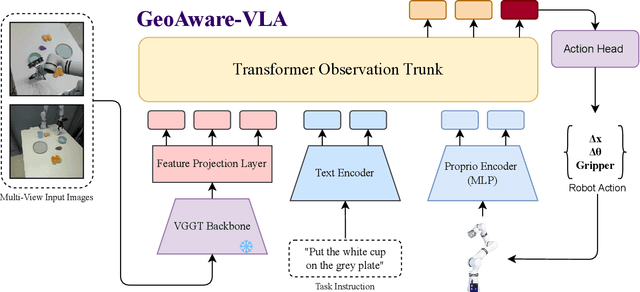
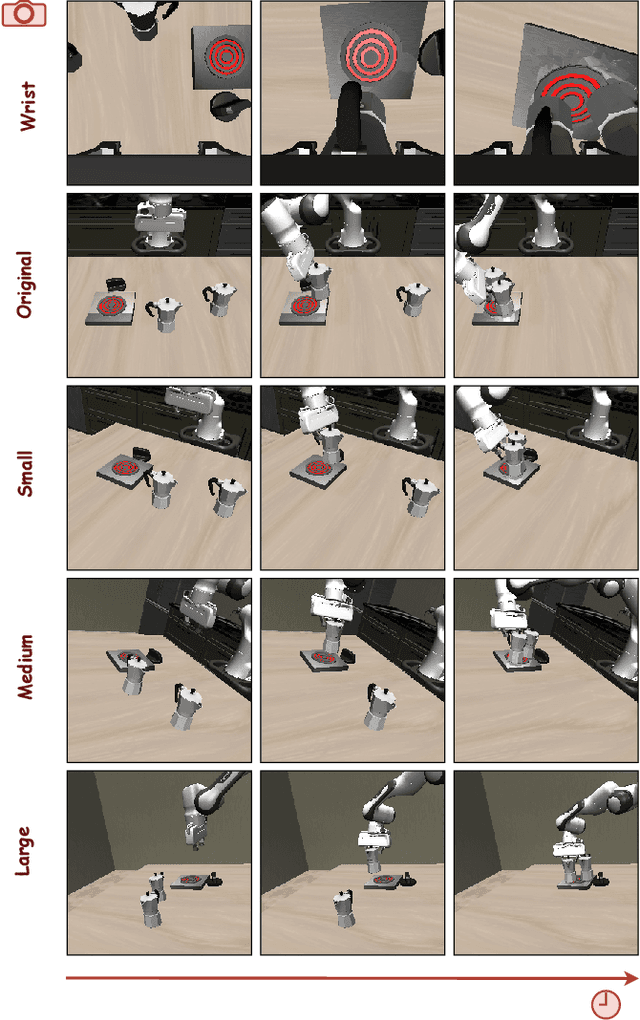

Vision-Language-Action (VLA) models often fail to generalize to novel camera viewpoints, a limitation stemming from their difficulty in inferring robust 3D geometry from 2D images. We introduce GeoAware-VLA, a simple yet effective approach that enhances viewpoint invariance by integrating strong geometric priors into the vision backbone. Instead of training a visual encoder or relying on explicit 3D data, we leverage a frozen, pretrained geometric vision model as a feature extractor. A trainable projection layer then adapts these geometrically-rich features for the policy decoder, relieving it of the burden of learning 3D consistency from scratch. Through extensive evaluations on LIBERO benchmark subsets, we show GeoAware-VLA achieves substantial improvements in zero-shot generalization to novel camera poses, boosting success rates by over 2x in simulation. Crucially, these benefits translate to the physical world; our model shows a significant performance gain on a real robot, especially when evaluated from unseen camera angles. Our approach proves effective across both continuous and discrete action spaces, highlighting that robust geometric grounding is a key component for creating more generalizable robotic agents.