 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgedaVinci-Env: Open SWE Environment Synthesis at Scale
Mar 16, 2026Training capable software engineering (SWE) agents demands large-scale, executable, and verifiable environments that provide dynamic feedback loops for iterative code editing, test execution, and solution refinement. However, existing open-source datasets remain limited in scale and repository diversity, while industrial solutions are opaque with unreleased infrastructure, creating a prohibitive barrier for most academic research groups. We present OpenSWE, the largest fully transparent framework for SWE agent training in Python, comprising 45,320 executable Docker environments spanning over 12.8k repositories, with all Dockerfiles, evaluation scripts, and infrastructure fully open-sourced for reproducibility. OpenSWE is built through a multi-agent synthesis pipeline deployed across a 64-node distributed cluster, automating repository exploration, Dockerfile construction, evaluation script generation, and iterative test analysis. Beyond scale, we propose a quality-centric filtering pipeline that characterizes the inherent difficulty of each environment, filtering out instances that are either unsolvable or insufficiently challenging and retaining only those that maximize learning efficiency. With $891K spent on environment construction and an additional $576K on trajectory sampling and difficulty-aware curation, the entire project represents a total investment of approximately $1.47 million, yielding about 13,000 curated trajectories from roughly 9,000 quality guaranteed environments. Extensive experiments validate OpenSWE's effectiveness: OpenSWE-32B and OpenSWE-72B achieve 62.4% and 66.0% on SWE-bench Verified, establishing SOTA among Qwen2.5 series. Moreover, SWE-focused training yields substantial out-of-domain improvements, including up to 12 points on mathematical reasoning and 5 points on science benchmarks, without degrading factual recall.
daVinci-Dev: Agent-native Mid-training for Software Engineering
Jan 27, 2026Recently, the frontier of Large Language Model (LLM) capabilities has shifted from single-turn code generation to agentic software engineering-a paradigm where models autonomously navigate, edit, and test complex repositories. While post-training methods have become the de facto approach for code agents, **agentic mid-training**-mid-training (MT) on large-scale data that mirrors authentic agentic workflows-remains critically underexplored due to substantial resource requirements, despite offering a more scalable path to instilling foundational agentic behaviors than relying solely on expensive reinforcement learning. A central challenge in realizing effective agentic mid-training is the distribution mismatch between static training data and the dynamic, feedback-rich environment of real development. To address this, we present a systematic study of agentic mid-training, establishing both the data synthesis principles and training methodology for effective agent development at scale. Central to our approach is **agent-native data**-supervision comprising two complementary types of trajectories: **contextually-native trajectories** that preserve the complete information flow an agent experiences, offering broad coverage and diversity; and **environmentally-native trajectories** collected from executable repositories where observations stem from actual tool invocations and test executions, providing depth and interaction authenticity. We verify the model's agentic capabilities on `SWE-Bench Verified`. We demonstrate our superiority over the previous open software engineering mid-training recipe `Kimi-Dev` under two post-training settings with an aligned base model and agentic scaffold, while using less than half mid-training tokens (73.1B). Besides relative advantage, our best performing 32B and 72B models achieve **56.1%** and **58.5%** resolution rates, respectively, which are ...
AgencyBench: Benchmarking the Frontiers of Autonomous Agents in 1M-Token Real-World Contexts
Jan 16, 2026Large Language Models (LLMs) based autonomous agents demonstrate multifaceted capabilities to contribute substantially to economic production. However, existing benchmarks remain focused on single agentic capability, failing to capture long-horizon real-world scenarios. Moreover, the reliance on human-in-the-loop feedback for realistic tasks creates a scalability bottleneck, hindering automated rollout collection and evaluation. To bridge this gap, we introduce AgencyBench, a comprehensive benchmark derived from daily AI usage, evaluating 6 core agentic capabilities across 32 real-world scenarios, comprising 138 tasks with specific queries, deliverables, and rubrics. These scenarios require an average of 90 tool calls, 1 million tokens, and hours of execution time to resolve. To enable automated evaluation, we employ a user simulation agent to provide iterative feedback, and a Docker sandbox to conduct visual and functional rubric-based assessment. Experiments reveal that closed-source models significantly outperform open-source models (48.4% vs 32.1%). Further analysis reveals significant disparities across models in resource efficiency, feedback-driven self-correction, and specific tool-use preferences. Finally, we investigate the impact of agentic scaffolds, observing that proprietary models demonstrate superior performance within their native ecosystems (e.g., Claude-4.5-Opus via Claude-Agent-SDK), while open-source models exhibit distinct performance peaks, suggesting potential optimization for specific execution frameworks. AgencyBench serves as a critical testbed for next-generation agents, highlighting the necessity of co-optimizing model architecture with agentic frameworks. We believe this work sheds light on the future direction of autonomous agents, and we release the full benchmark and evaluation toolkit at https://github.com/GAIR-NLP/AgencyBench.
InnovatorBench: Evaluating Agents' Ability to Conduct Innovative LLM Research
Nov 03, 2025
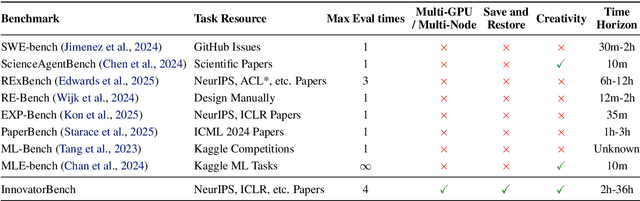


AI agents could accelerate scientific discovery by automating hypothesis formation, experiment design, coding, execution, and analysis, yet existing benchmarks probe narrow skills in simplified settings. To address this gap, we introduce InnovatorBench, a benchmark-platform pair for realistic, end-to-end assessment of agents performing Large Language Model (LLM) research. It comprises 20 tasks spanning Data Construction, Filtering, Augmentation, Loss Design, Reward Design, and Scaffold Construction, which require runnable artifacts and assessment of correctness, performance, output quality, and uncertainty. To support agent operation, we develop ResearchGym, a research environment offering rich action spaces, distributed and long-horizon execution, asynchronous monitoring, and snapshot saving. We also implement a lightweight ReAct agent that couples explicit reasoning with executable planning using frontier models such as Claude-4, GPT-5, GLM-4.5, and Kimi-K2. Our experiments demonstrate that while frontier models show promise in code-driven research tasks, they struggle with fragile algorithm-related tasks and long-horizon decision making, such as impatience, poor resource management, and overreliance on template-based reasoning. Furthermore, agents require over 11 hours to achieve their best performance on InnovatorBench, underscoring the benchmark's difficulty and showing the potential of InnovatorBench to be the next generation of code-based research benchmark.
Interaction as Intelligence Part II: Asynchronous Human-Agent Rollout for Long-Horizon Task Training
Nov 03, 2025Large Language Model (LLM) agents have recently shown strong potential in domains such as automated coding, deep research, and graphical user interface manipulation. However, training them to succeed on long-horizon, domain-specialized tasks remains challenging. Current methods primarily fall into two categories. The first relies on dense human annotations through behavior cloning, which is prohibitively expensive for long-horizon tasks that can take days or months. The second depends on outcome-driven sampling, which often collapses due to the rarity of valid positive trajectories on domain-specialized tasks. We introduce Apollo, a sampling framework that integrates asynchronous human guidance with action-level data filtering. Instead of requiring annotators to shadow every step, Apollo allows them to intervene only when the agent drifts from a promising trajectory, by providing prior knowledge, strategic advice, etc. This lightweight design makes it possible to sustain interactions for over 30 hours and produces valuable trajectories at a lower cost. Apollo then applies supervision control to filter out sub-optimal actions and prevent error propagation. Together, these components enable reliable and effective data collection in long-horizon environments. To demonstrate the effectiveness of Apollo, we evaluate it using InnovatorBench. Our experiments show that when applied to train the GLM-4.5 model on InnovatorBench, Apollo achieves more than a 50% improvement over the untrained baseline and a 28% improvement over a variant trained without human interaction. These results highlight the critical role of human-in-the-loop sampling and the robustness of Apollo's design in handling long-horizon, domain-specialized tasks.
Context Engineering 2.0: The Context of Context Engineering
Oct 30, 2025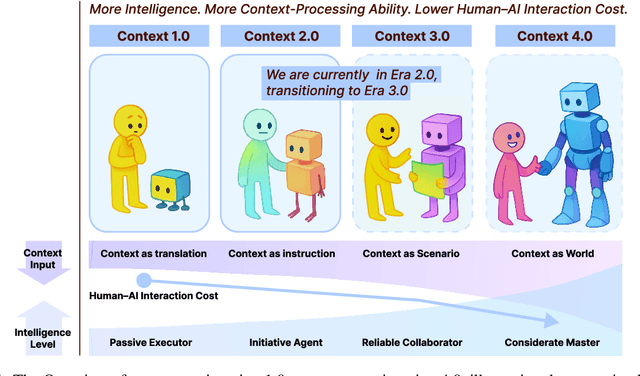
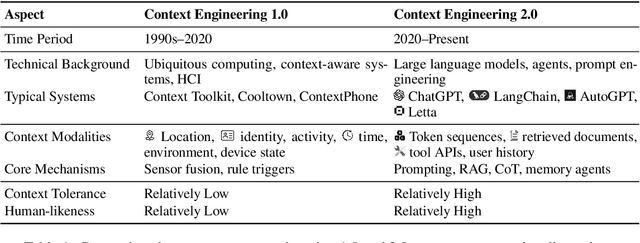
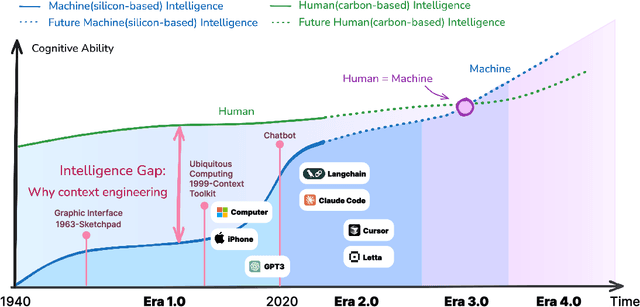
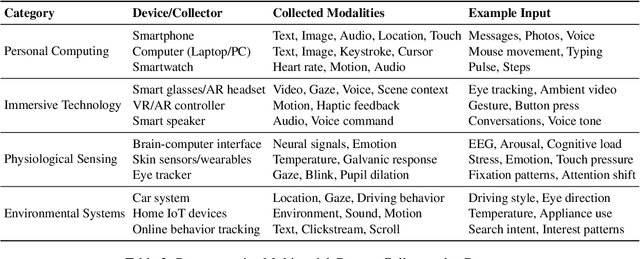
Karl Marx once wrote that ``the human essence is the ensemble of social relations'', suggesting that individuals are not isolated entities but are fundamentally shaped by their interactions with other entities, within which contexts play a constitutive and essential role. With the advent of computers and artificial intelligence, these contexts are no longer limited to purely human--human interactions: human--machine interactions are included as well. Then a central question emerges: How can machines better understand our situations and purposes? To address this challenge, researchers have recently introduced the concept of context engineering. Although it is often regarded as a recent innovation of the agent era, we argue that related practices can be traced back more than twenty years. Since the early 1990s, the field has evolved through distinct historical phases, each shaped by the intelligence level of machines: from early human--computer interaction frameworks built around primitive computers, to today's human--agent interaction paradigms driven by intelligent agents, and potentially to human--level or superhuman intelligence in the future. In this paper, we situate context engineering, provide a systematic definition, outline its historical and conceptual landscape, and examine key design considerations for practice. By addressing these questions, we aim to offer a conceptual foundation for context engineering and sketch its promising future. This paper is a stepping stone for a broader community effort toward systematic context engineering in AI systems.
DatasetResearch: Benchmarking Agent Systems for Demand-Driven Dataset Discovery
Aug 09, 2025The rapid advancement of large language models has fundamentally shifted the bottleneck in AI development from computational power to data availability-with countless valuable datasets remaining hidden across specialized repositories, research appendices, and domain platforms. As reasoning capabilities and deep research methodologies continue to evolve, a critical question emerges: can AI agents transcend conventional search to systematically discover any dataset that meets specific user requirements, enabling truly autonomous demand-driven data curation? We introduce DatasetResearch, the first comprehensive benchmark evaluating AI agents' ability to discover and synthesize datasets from 208 real-world demands across knowledge-intensive and reasoning-intensive tasks. Our tri-dimensional evaluation framework reveals a stark reality: even advanced deep research systems achieve only 22% score on our challenging DatasetResearch-pro subset, exposing the vast gap between current capabilities and perfect dataset discovery. Our analysis uncovers a fundamental dichotomy-search agents excel at knowledge tasks through retrieval breadth, while synthesis agents dominate reasoning challenges via structured generation-yet both catastrophically fail on "corner cases" outside existing distributions. These findings establish the first rigorous baseline for dataset discovery agents and illuminate the path toward AI systems capable of finding any dataset in the digital universe. Our benchmark and comprehensive analysis provide the foundation for the next generation of self-improving AI systems and are publicly available at https://github.com/GAIR-NLP/DatasetResearch.
NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 19, 2025



This paper reviews the NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images. This challenge received a wide range of impressive solutions, which are developed and evaluated using our collected real-world Raindrop Clarity dataset. Unlike existing deraining datasets, our Raindrop Clarity dataset is more diverse and challenging in degradation types and contents, which includes day raindrop-focused, day background-focused, night raindrop-focused, and night background-focused degradations. This dataset is divided into three subsets for competition: 14,139 images for training, 240 images for validation, and 731 images for testing. The primary objective of this challenge is to establish a new and powerful benchmark for the task of removing raindrops under varying lighting and focus conditions. There are a total of 361 participants in the competition, and 32 teams submitting valid solutions and fact sheets for the final testing phase. These submissions achieved state-of-the-art (SOTA) performance on the Raindrop Clarity dataset. The project can be found at https://lixinustc.github.io/CVPR-NTIRE2025-RainDrop-Competition.github.io/.