 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASR-GLUE: A New Multi-task Benchmark for ASR-Robust Natural Language Understanding
Aug 30, 2021
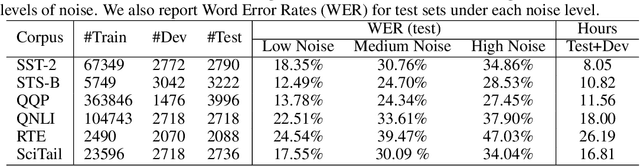
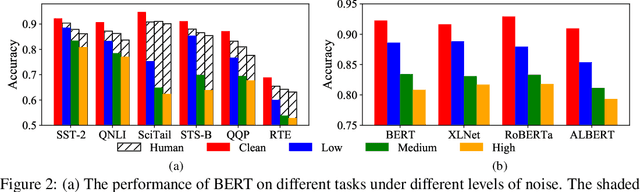

Language understanding in speech-based systems have attracted much attention in recent years with the growing demand for voice interface applications. However, the robustness of natural language understanding (NLU) systems to errors introduced by automatic speech recognition (ASR) is under-examined. %To facilitate the research on ASR-robust general language understanding, In this paper, we propose ASR-GLUE benchmark, a new collection of 6 different NLU tasks for evaluating the performance of models under ASR error across 3 different levels of background noise and 6 speakers with various voice characteristics. Based on the proposed benchmark, we systematically investigate the effect of ASR error on NLU tasks in terms of noise intensity, error type and speaker variants. We further purpose two ways, correction-based method and data augmentation-based method to improve robustness of the NLU systems. Extensive experimental results and analysises show that the proposed methods are effective to some extent, but still far from human performance, demonstrating that NLU under ASR error is still very challenging and requires further research.
CrossFormer: A Versatile Vision Transformer Based on Cross-scale Attention
Jul 31, 2021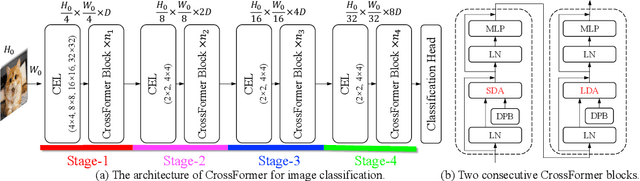
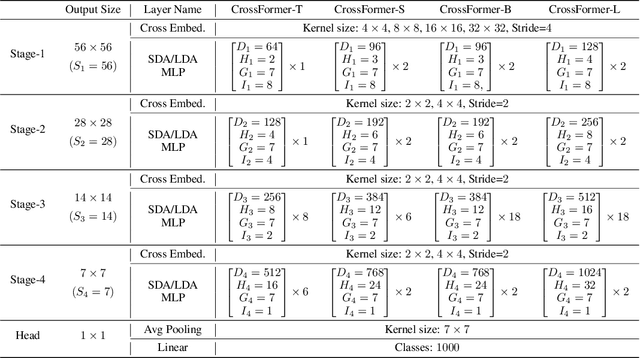
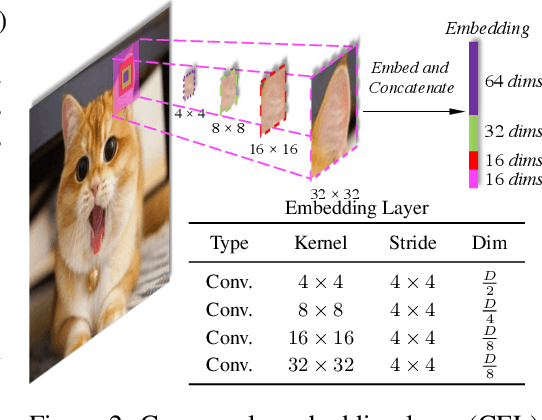
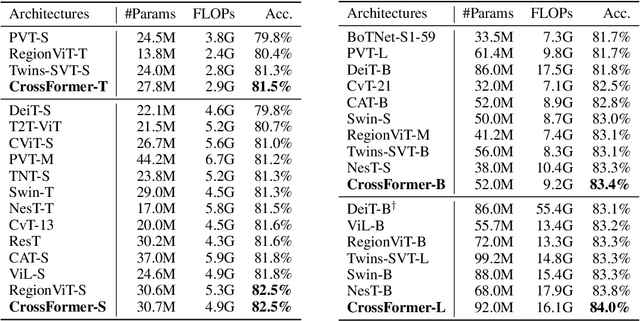
Transformers have made much progress in dealing with visual tasks. However, existing vision transformers still do not possess an ability that is important to visual input: building the attention among features of different scales. The reasons for this problem are two-fold: (1) Input embeddings of each layer are equal-scale without cross-scale features; (2) Some vision transformers sacrifice the small-scale features of embeddings to lower the cost of the self-attention module. To make up this defect, we propose Cross-scale Embedding Layer (CEL) and Long Short Distance Attention (LSDA). In particular, CEL blends each embedding with multiple patches of different scales, providing the model with cross-scale embeddings. LSDA splits the self-attention module into a short-distance and long-distance one, also lowering the cost but keeping both small-scale and large-scale features in embeddings. Through these two designs, we achieve cross-scale attention. Besides, we propose dynamic position bias for vision transformers to make the popular relative position bias apply to variable-sized images. Based on these proposed modules, we construct our vision architecture called CrossFormer. Experiments show that CrossFormer outperforms other transformers on several representative visual tasks, especially object detection and segmentation. The code has been released: https://github.com/cheerss/CrossFormer.
Learning to Affiliate: Mutual Centralized Learning for Few-shot Classification
Jun 10, 2021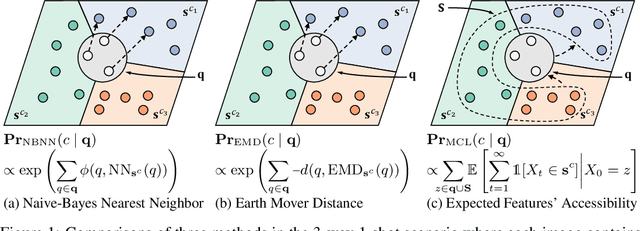
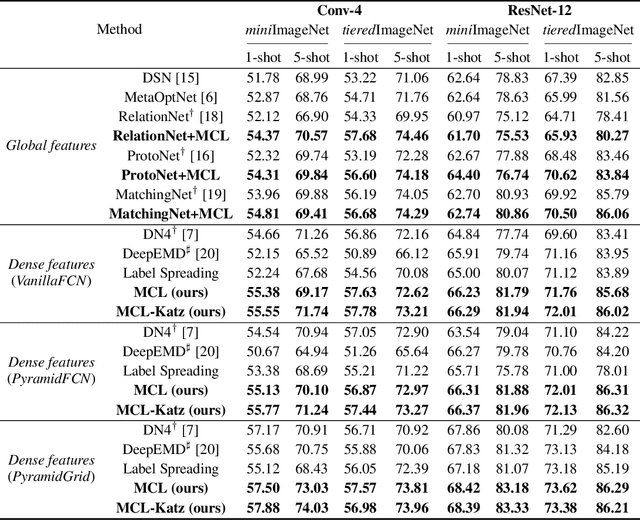
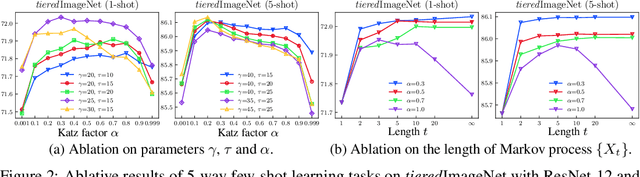
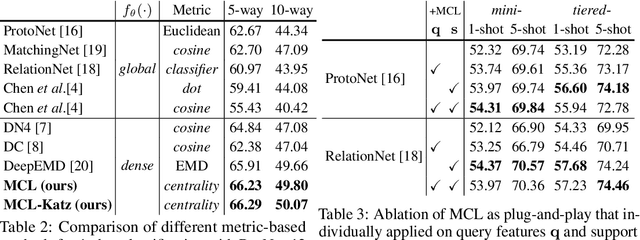
Few-shot learning (FSL) aims to learn a classifier that can be easily adapted to accommodate new tasks not seen during training, given only a few examples. To handle the limited-data problem in few-shot regimes, recent methods tend to collectively use a set of local features to densely represent an image instead of using a mixed global feature. They generally explore a unidirectional query-to-support paradigm in FSL, e.g., find the nearest/optimal support feature for each query feature and aggregate these local matches for a joint classification. In this paper, we propose a new method Mutual Centralized Learning (MCL) to fully affiliate the two disjoint sets of dense features in a bidirectional paradigm. We associate each local feature with a particle that can bidirectionally random walk in a discrete feature space by the affiliations. To estimate the class probability, we propose the features' accessibility that measures the expected number of visits to the support features of that class in a Markov process. We relate our method to learning a centrality on an affiliation network and demonstrate its capability to be plugged in existing methods by highlighting centralized local features. Experiments show that our method achieves the state-of-the-art on both miniImageNet and tieredImageNet.
Salient Object Ranking with Position-Preserved Attention
Jun 10, 2021
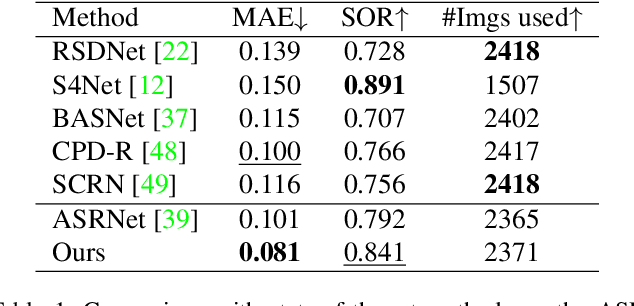
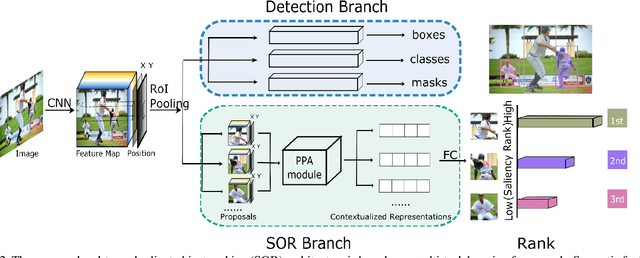
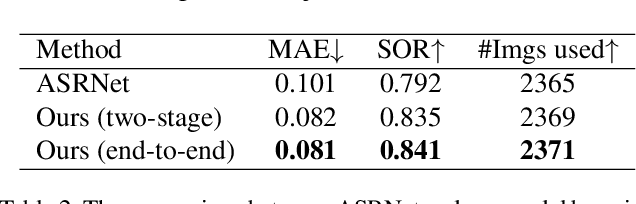
Instance segmentation can detect where the objects are in an image, but hard to understand the relationship between them. We pay attention to a typical relationship, relative saliency. A closely related task, salient object detection, predicts a binary map highlighting a visually salient region while hard to distinguish multiple objects. Directly combining two tasks by post-processing also leads to poor performance. There is a lack of research on relative saliency at present, limiting the practical applications such as content-aware image cropping, video summary, and image labeling. In this paper, we study the Salient Object Ranking (SOR) task, which manages to assign a ranking order of each detected object according to its visual saliency. We propose the first end-to-end framework of the SOR task and solve it in a multi-task learning fashion. The framework handles instance segmentation and salient object ranking simultaneously. In this framework, the SOR branch is independent and flexible to cooperate with different detection methods, so that easy to use as a plugin. We also introduce a Position-Preserved Attention (PPA) module tailored for the SOR branch. It consists of the position embedding stage and feature interaction stage. Considering the importance of position in saliency comparison, we preserve absolute coordinates of objects in ROI pooling operation and then fuse positional information with semantic features in the first stage. In the feature interaction stage, we apply the attention mechanism to obtain proposals' contextualized representations to predict their relative ranking orders. Extensive experiments have been conducted on the ASR dataset. Without bells and whistles, our proposed method outperforms the former state-of-the-art method significantly. The code will be released publicly available.
Attacking Adversarial Attacks as A Defense
Jun 09, 2021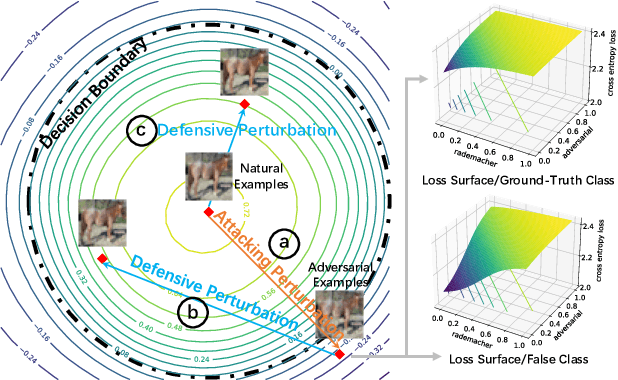
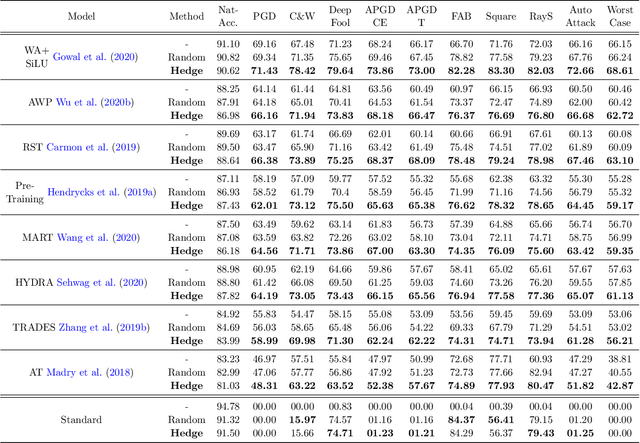
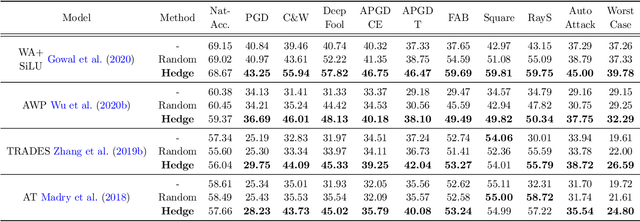
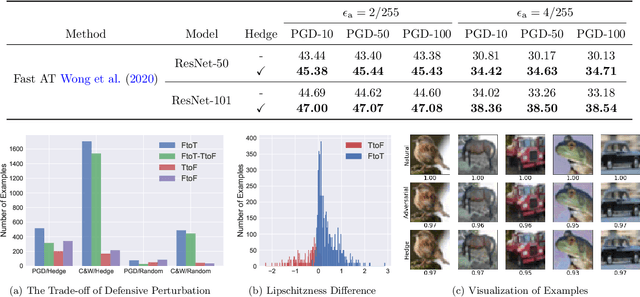
It is well known that adversarial attacks can fool deep neural networks with imperceptible perturbations. Although adversarial training significantly improves model robustness, failure cases of defense still broadly exist. In this work, we find that the adversarial attacks can also be vulnerable to small perturbations. Namely, on adversarially-trained models, perturbing adversarial examples with a small random noise may invalidate their misled predictions. After carefully examining state-of-the-art attacks of various kinds, we find that all these attacks have this deficiency to different extents. Enlightened by this finding, we propose to counter attacks by crafting more effective defensive perturbations. Our defensive perturbations leverage the advantage that adversarial training endows the ground-truth class with smaller local Lipschitzness. By simultaneously attacking all the classes, the misled predictions with larger Lipschitzness can be flipped into correct ones. We verify our defensive perturbation with both empirical experiments and theoretical analyses on a linear model. On CIFAR10, it boosts the state-of-the-art model from 66.16% to 72.66% against the four attacks of AutoAttack, including 71.76% to 83.30% against the Square attack. On ImageNet, the top-1 robust accuracy of FastAT is improved from 33.18% to 38.54% under the 100-step PGD attack.
Neural Machine Translation with Monolingual Translation Memory
Jun 02, 2021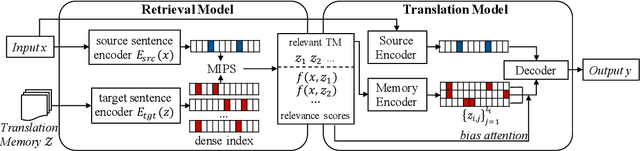
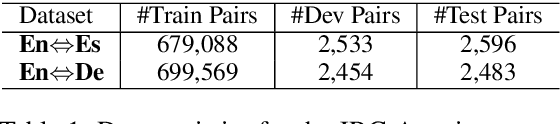
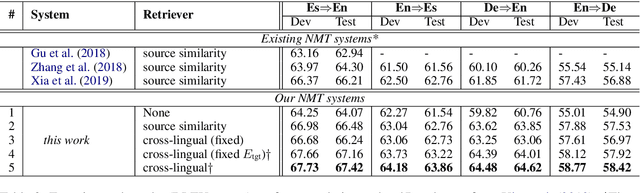
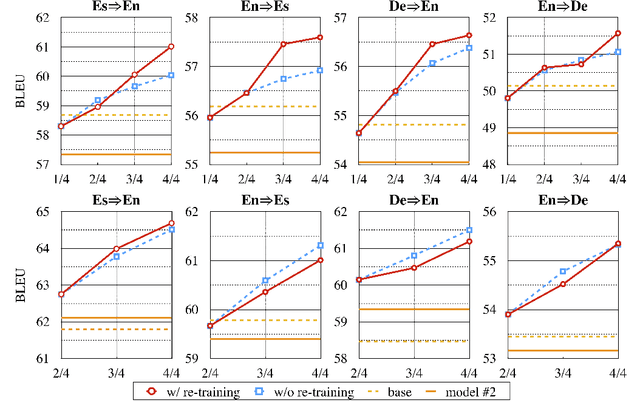
Prior work has proved that Translation memory (TM) can boost the performance of Neural Machine Translation (NMT). In contrast to existing work that uses bilingual corpus as TM and employs source-side similarity search for memory retrieval, we propose a new framework that uses monolingual memory and performs learnable memory retrieval in a cross-lingual manner. Our framework has unique advantages. First, the cross-lingual memory retriever allows abundant monolingual data to be TM. Second, the memory retriever and NMT model can be jointly optimized for the ultimate translation goal. Experiments show that the proposed method obtains substantial improvements. Remarkably, it even outperforms strong TM-augmented NMT baselines using bilingual TM. Owning to the ability to leverage monolingual data, our model also demonstrates effectiveness in low-resource and domain adaptation scenarios.
Assessing Dialogue Systems with Distribution Distances
May 27, 2021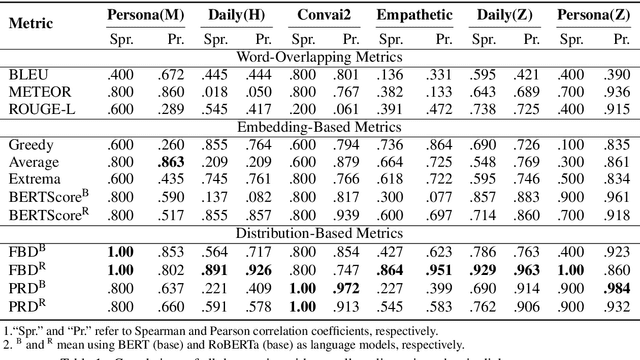
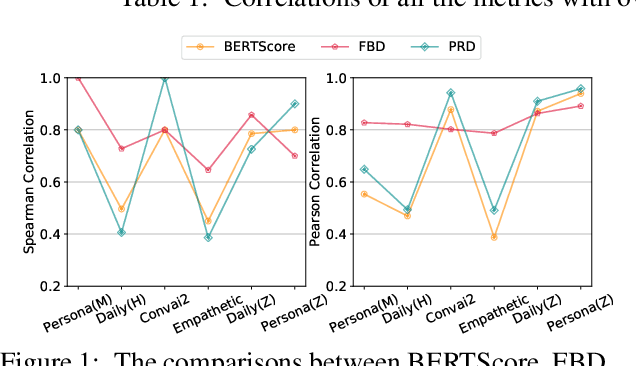
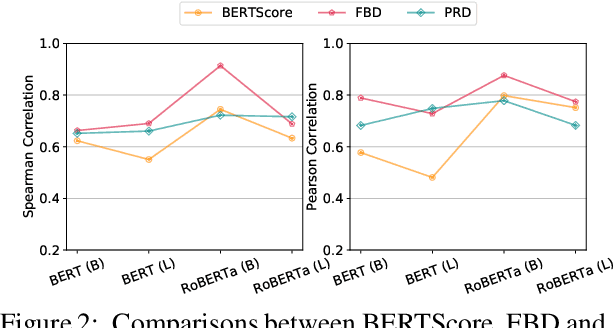
An important aspect of developing dialogue systems is how to evaluate and compare the performance of different systems. Existing automatic evaluation metrics are based on turn-level quality evaluation and use average scores for system-level comparison. In this paper, we propose to measure the performance of a dialogue system by computing the distribution-wise distance between its generated conversations and real-world conversations. Specifically, two distribution-wise metrics, FBD and PRD, are developed and evaluated. Experiments on several dialogue corpora show that our proposed metrics correlate better with human judgments than existing metrics.
* 7 pages, 2 figures
Dynamic Semantic Graph Construction and Reasoning for Explainable Multi-hop Science Question Answering
May 25, 2021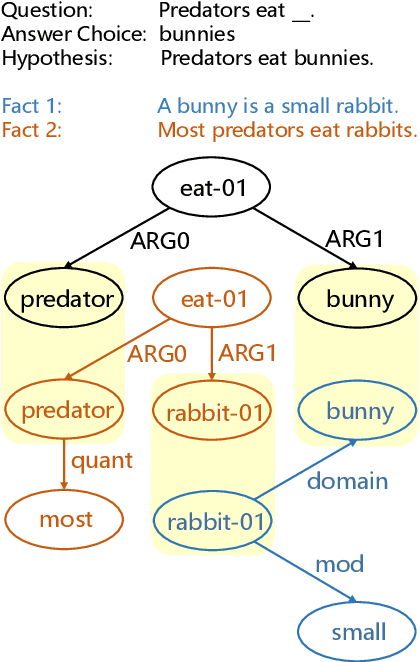
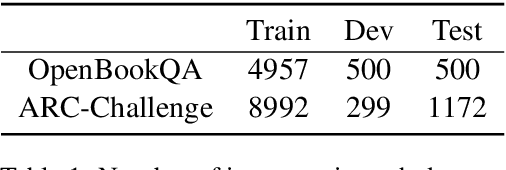
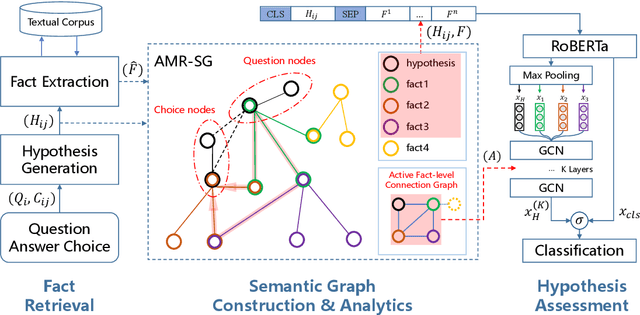
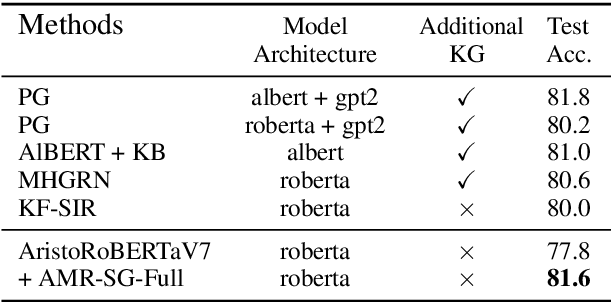
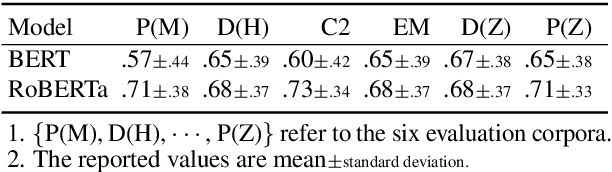
Knowledge retrieval and reasoning are two key stages in multi-hop question answering (QA) at web scale. Existing approaches suffer from low confidence when retrieving evidence facts to fill the knowledge gap and lack transparent reasoning process. In this paper, we propose a new framework to exploit more valid facts while obtaining explainability for multi-hop QA by dynamically constructing a semantic graph and reasoning over it. We employ Abstract Meaning Representation (AMR) as semantic graph representation. Our framework contains three new ideas: (a) {\tt AMR-SG}, an AMR-based Semantic Graph, constructed by candidate fact AMRs to uncover any hop relations among question, answer and multiple facts. (b) A novel path-based fact analytics approach exploiting {\tt AMR-SG} to extract active facts from a large fact pool to answer questions. (c) A fact-level relation modeling leveraging graph convolution network (GCN) to guide the reasoning process. Results on two scientific multi-hop QA datasets show that we can surpass recent approaches including those using additional knowledge graphs while maintaining high explainability on OpenBookQA and achieve a new state-of-the-art result on ARC-Challenge in a computationally practicable setting.
Discriminative-Generative Dual Memory Video Anomaly Detection
Apr 29, 2021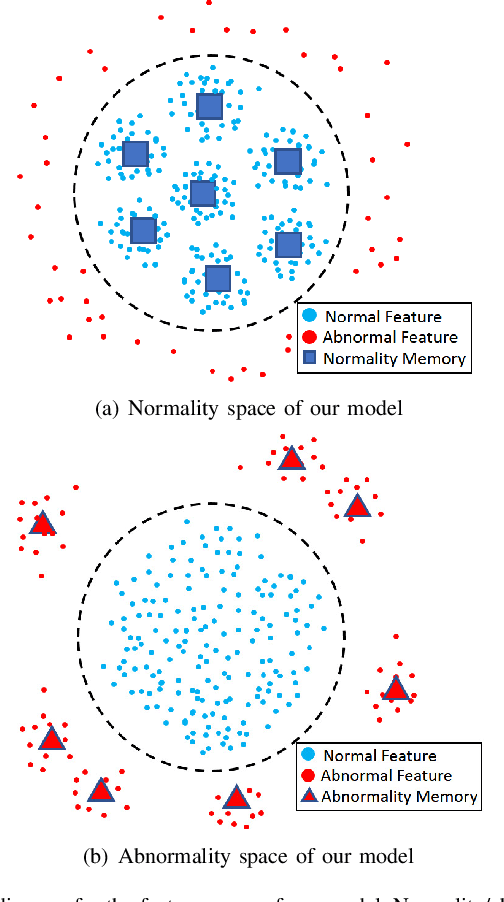
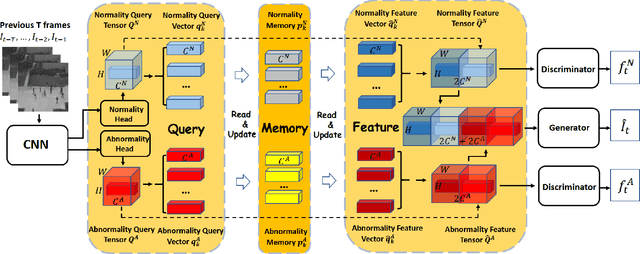
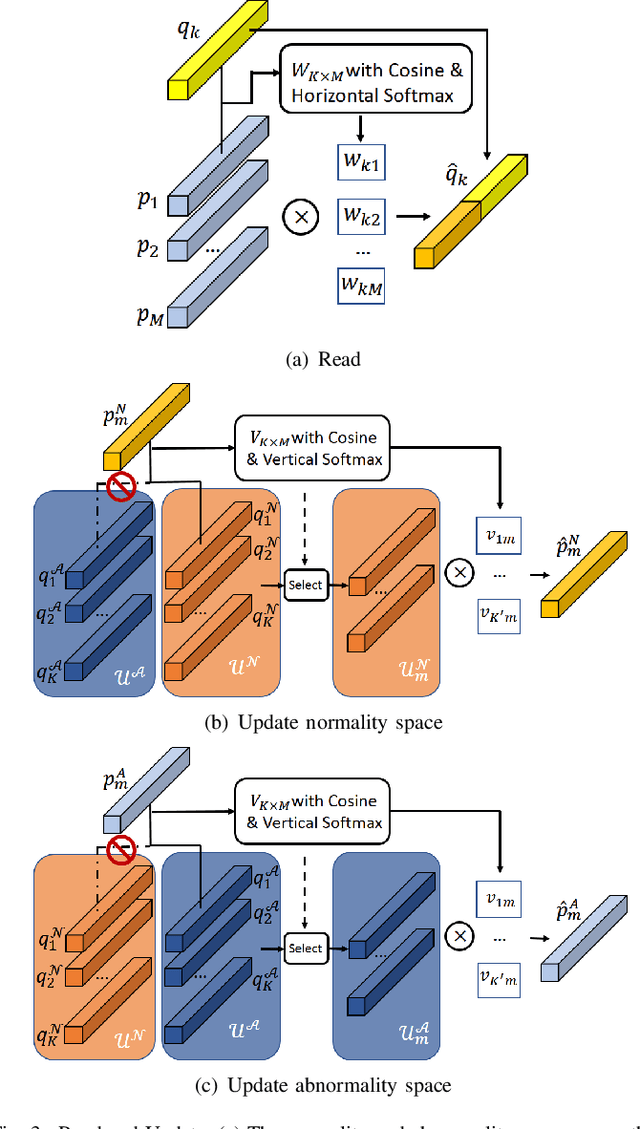
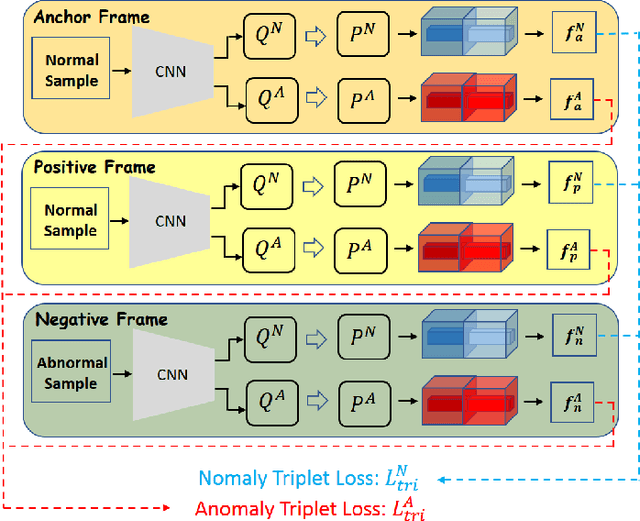
Recently, people tried to use a few anomalies for video anomaly detection (VAD) instead of only normal data during the training process. A side effect of data imbalance occurs when a few abnormal data face a vast number of normal data. The latest VAD works use triplet loss or data re-sampling strategy to lessen this problem. However, there is still no elaborately designed structure for discriminative VAD with a few anomalies. In this paper, we propose a DiscRiminative-gEnerative duAl Memory (DREAM) anomaly detection model to take advantage of a few anomalies and solve data imbalance. We use two shallow discriminators to tighten the normal feature distribution boundary along with a generator for the next frame prediction. Further, we propose a dual memory module to obtain a sparse feature representation in both normality and abnormality space. As a result, DREAM not only solves the data imbalance problem but also learn a reasonable feature space. Further theoretical analysis shows that our DREAM also works for the unknown anomalies. Comparing with the previous methods on UCSD Ped1, UCSD Ped2, CUHK Avenue, and ShanghaiTech, our model outperforms all the baselines with no extra parameters. The ablation study demonstrates the effectiveness of our dual memory module and discriminative-generative network.
Lidar Point Cloud Guided Monocular 3D Object Detection
Apr 19, 2021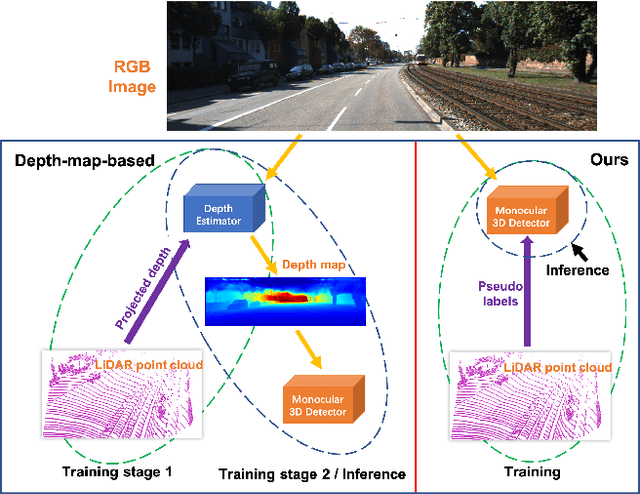
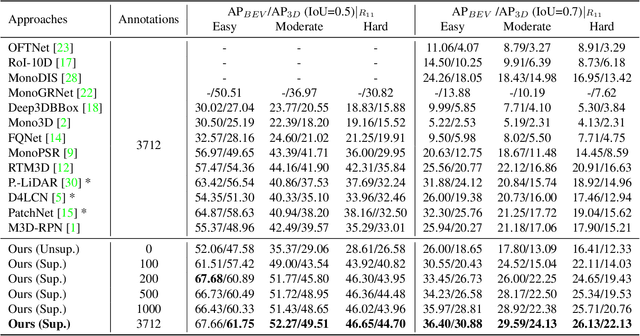
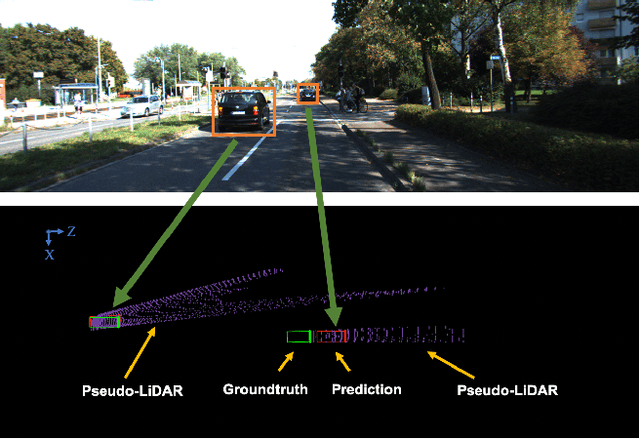
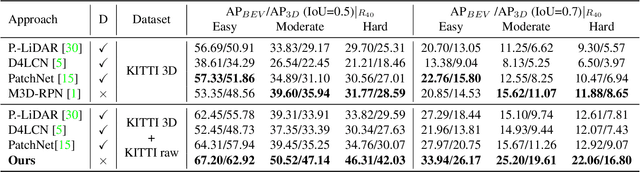
Monocular 3D object detection is drawing increasing attention from the community as it enables cars to perceive the world in 3D with a single camera. However, monocular 3D detection currently struggles with extremely lower detection rates compared to LiDAR-based methods, limiting its applications. The poor accuracy is mainly caused by the absence of accurate depth cues due to the ill-posed nature of monocular imagery. LiDAR point clouds, which provide accurate depth measurement, can offer beneficial information for the training of monocular methods. Prior works only use LiDAR point clouds to train a depth estimator. This implicit way does not fully utilize LiDAR point clouds, consequently leading to suboptimal performances. To effectively take advantage of LiDAR point clouds, in this paper we propose a general, simple yet effective framework for monocular methods. Specifically, we use LiDAR point clouds to directly guide the training of monocular 3D detectors, allowing them to learn desired objectives meanwhile eliminating the extra annotation cost. Thanks to the general design, our method can be plugged into any monocular 3D detection method, significantly boosting the performance. In conclusion, we take the first place on KITTI monocular 3D detection benchmark and increase the BEV/3D AP from 11.88/8.65 to 22.06/16.80 on the hard setting for the prior state-of-the-art method. The code will be made publicly available soon.