 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGI-Bench: A Panoramic Benchmark Revealing the Knowledge-Experience Dissociation of Multimodal Large Language Models in Gastrointestinal Endoscopy Against Clinical Standards
Jan 13, 2026Multimodal Large Language Models (MLLMs) show promise in gastroenterology, yet their performance against comprehensive clinical workflows and human benchmarks remains unverified. To systematically evaluate state-of-the-art MLLMs across a panoramic gastrointestinal endoscopy workflow and determine their clinical utility compared with human endoscopists. We constructed GI-Bench, a benchmark encompassing 20 fine-grained lesion categories. Twelve MLLMs were evaluated across a five-stage clinical workflow: anatomical localization, lesion identification, diagnosis, findings description, and management. Model performance was benchmarked against three junior endoscopists and three residency trainees using Macro-F1, mean Intersection-over-Union (mIoU), and multi-dimensional Likert scale. Gemini-3-Pro achieved state-of-the-art performance. In diagnostic reasoning, top-tier models (Macro-F1 0.641) outperformed trainees (0.492) and rivaled junior endoscopists (0.727; p>0.05). However, a critical "spatial grounding bottleneck" persisted; human lesion localization (mIoU >0.506) significantly outperformed the best model (0.345; p<0.05). Furthermore, qualitative analysis revealed a "fluency-accuracy paradox": models generated reports with superior linguistic readability compared with humans (p<0.05) but exhibited significantly lower factual correctness (p<0.05) due to "over-interpretation" and hallucination of visual features.GI-Bench maintains a dynamic leaderboard that tracks the evolving performance of MLLMs in clinical endoscopy. The current rankings and benchmark results are available at https://roterdl.github.io/GIBench/.
CrossFormer: A Versatile Vision Transformer Based on Cross-scale Attention
Jul 31, 2021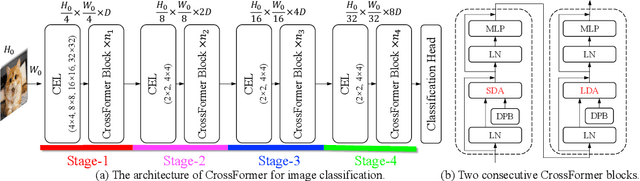
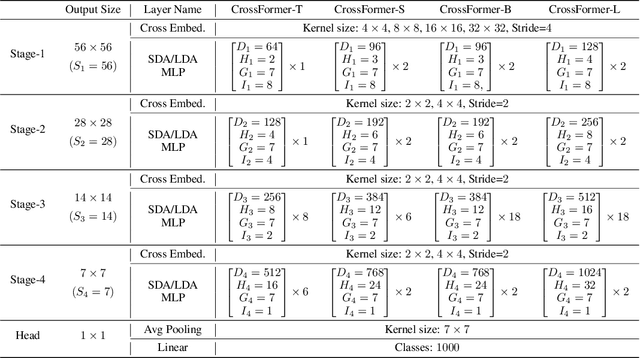
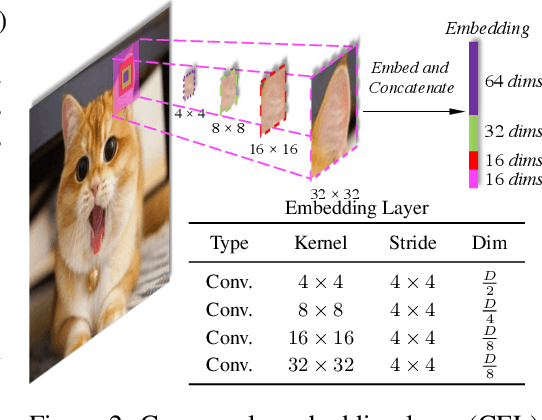
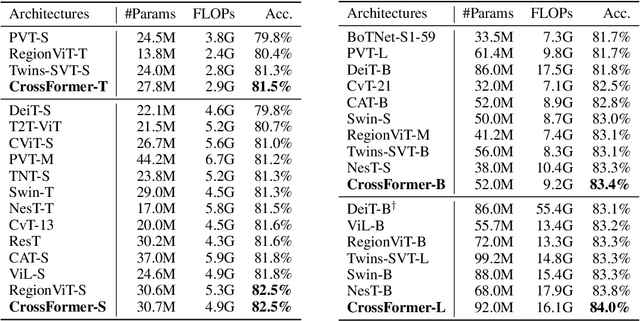
Transformers have made much progress in dealing with visual tasks. However, existing vision transformers still do not possess an ability that is important to visual input: building the attention among features of different scales. The reasons for this problem are two-fold: (1) Input embeddings of each layer are equal-scale without cross-scale features; (2) Some vision transformers sacrifice the small-scale features of embeddings to lower the cost of the self-attention module. To make up this defect, we propose Cross-scale Embedding Layer (CEL) and Long Short Distance Attention (LSDA). In particular, CEL blends each embedding with multiple patches of different scales, providing the model with cross-scale embeddings. LSDA splits the self-attention module into a short-distance and long-distance one, also lowering the cost but keeping both small-scale and large-scale features in embeddings. Through these two designs, we achieve cross-scale attention. Besides, we propose dynamic position bias for vision transformers to make the popular relative position bias apply to variable-sized images. Based on these proposed modules, we construct our vision architecture called CrossFormer. Experiments show that CrossFormer outperforms other transformers on several representative visual tasks, especially object detection and segmentation. The code has been released: https://github.com/cheerss/CrossFormer.
Context-aware Ensemble of Multifaceted Factorization Models for Recommendation Prediction in Social Networks
May 03, 2021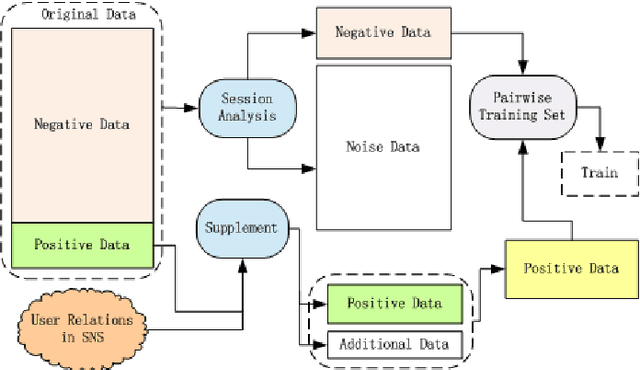
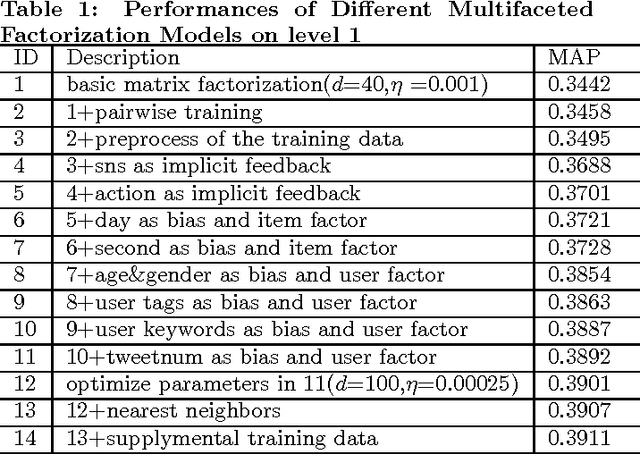
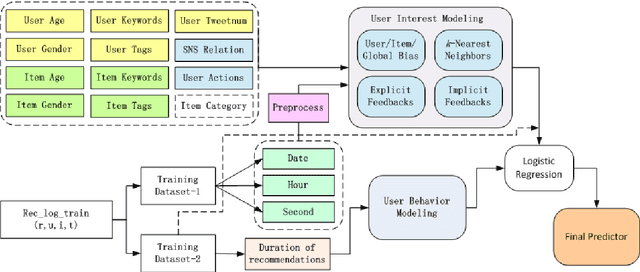

This paper describes the solution of Shanda Innovations team to Task 1 of KDD-Cup 2012. A novel approach called Multifaceted Factorization Models is proposed to incorporate a great variety of features in social networks. Social relationships and actions between users are integrated as implicit feedbacks to improve the recommendation accuracy. Keywords, tags, profiles, time and some other features are also utilized for modeling user interests. In addition, user behaviors are modeled from the durations of recommendation records. A context-aware ensemble framework is then applied to combine multiple predictors and produce final recommendation results. The proposed approach obtained 0.43959 (public score) / 0.41874 (private score) on the testing dataset, which achieved the 2nd place in the KDD-Cup competition.