 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdgeNet : Encoder-decoder generative Network for Auction Design in E-commerce Online Advertising
May 09, 2023


We present a new encoder-decoder generative network dubbed EdgeNet, which introduces a novel encoder-decoder framework for data-driven auction design in online e-commerce advertising. We break the neural auction paradigm of Generalized-Second-Price(GSP), and improve the utilization efficiency of data while ensuring the economic characteristics of the auction mechanism. Specifically, EdgeNet introduces a transformer-based encoder to better capture the mutual influence among different candidate advertisements. In contrast to GSP based neural auction model, we design an autoregressive decoder to better utilize the rich context information in online advertising auctions. EdgeNet is conceptually simple and easy to extend to the existing end-to-end neural auction framework. We validate the efficiency of EdgeNet on a wide range of e-commercial advertising auction, demonstrating its potential in improving user experience and platform revenue.
Unified Vision-Language Representation Modeling for E-Commerce Same-Style Products Retrieval
Feb 20, 2023Same-style products retrieval plays an important role in e-commerce platforms, aiming to identify the same products which may have different text descriptions or images. It can be used for similar products retrieval from different suppliers or duplicate products detection of one supplier. Common methods use the image as the detected object, but they only consider the visual features and overlook the attribute information contained in the textual descriptions, and perform weakly for products in image less important industries like machinery, hardware tools and electronic component, even if an additional text matching module is added. In this paper, we propose a unified vision-language modeling method for e-commerce same-style products retrieval, which is designed to represent one product with its textual descriptions and visual contents. It contains one sampling skill to collect positive pairs from user click log with category and relevance constrained, and a novel contrastive loss unit to model the image, text, and image+text representations into one joint embedding space. It is capable of cross-modal product-to-product retrieval, as well as style transfer and user-interactive search. Offline evaluations on annotated data demonstrate its superior retrieval performance, and online testings show it can attract more clicks and conversions. Moreover, this model has already been deployed online for similar products retrieval in alibaba.com, the largest B2B e-commerce platform in the world.
QR-CLIP: Introducing Explicit Open-World Knowledge for Location and Time Reasoning
Feb 02, 2023Daily images may convey abstract meanings that require us to memorize and infer profound information from them. To encourage such human-like reasoning, in this work, we teach machines to predict where and when it was taken rather than performing basic tasks like traditional segmentation or classification. Inspired by Horn's QR theory, we designed a novel QR-CLIP model consisting of two components: 1) the Quantity module first retrospects more open-world knowledge as the candidate language inputs; 2) the Relevance module carefully estimates vision and language cues and infers the location and time. Experiments show our QR-CLIP's effectiveness, and it outperforms the previous SOTA on each task by an average of about 10% and 130% relative lift in terms of location and time reasoning. This study lays a technical foundation for location and time reasoning and suggests that effectively introducing open-world knowledge is one of the panaceas for the tasks.
Masked Vision-Language Transformer in Fashion
Oct 27, 2022We present a masked vision-language transformer (MVLT) for fashion-specific multi-modal representation. Technically, we simply utilize vision transformer architecture for replacing the BERT in the pre-training model, making MVLT the first end-to-end framework for the fashion domain. Besides, we designed masked image reconstruction (MIR) for a fine-grained understanding of fashion. MVLT is an extensible and convenient architecture that admits raw multi-modal inputs without extra pre-processing models (e.g., ResNet), implicitly modeling the vision-language alignments. More importantly, MVLT can easily generalize to various matching and generative tasks. Experimental results show obvious improvements in retrieval (rank@5: 17%) and recognition (accuracy: 3%) tasks over the Fashion-Gen 2018 winner Kaleido-BERT. Code is made available at https://github.com/GewelsJI/MVLT.
Fast Heterogeneous Federated Learning with Hybrid Client Selection
Aug 16, 2022
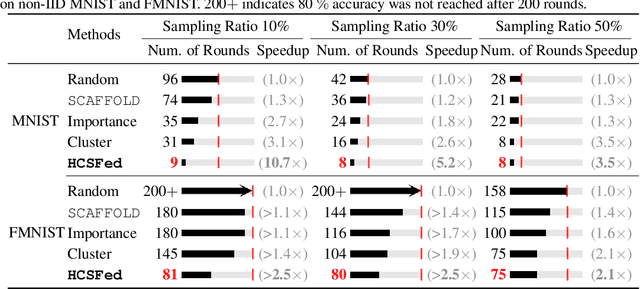
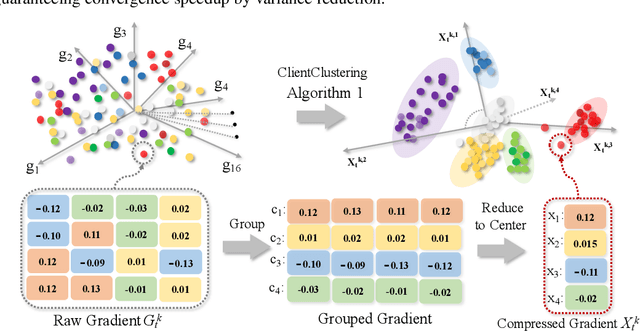
Client selection schemes are widely adopted to handle the communication-efficient problems in recent studies of Federated Learning (FL). However, the large variance of the model updates aggregated from the randomly-selected unrepresentative subsets directly slows the FL convergence. We present a novel clustering-based client selection scheme to accelerate the FL convergence by variance reduction. Simple yet effective schemes are designed to improve the clustering effect and control the effect fluctuation, therefore, generating the client subset with certain representativeness of sampling. Theoretically, we demonstrate the improvement of the proposed scheme in variance reduction. We also present the tighter convergence guarantee of the proposed method thanks to the variance reduction. Experimental results confirm the exceed efficiency of our scheme compared to alternatives.
Variance-Reduced Heterogeneous Federated Learning via Stratified Client Selection
Jan 15, 2022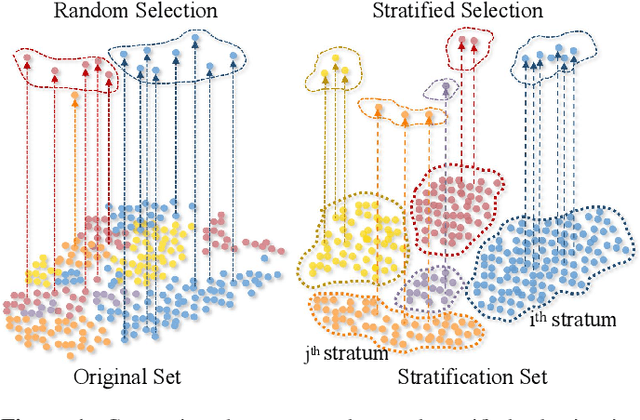
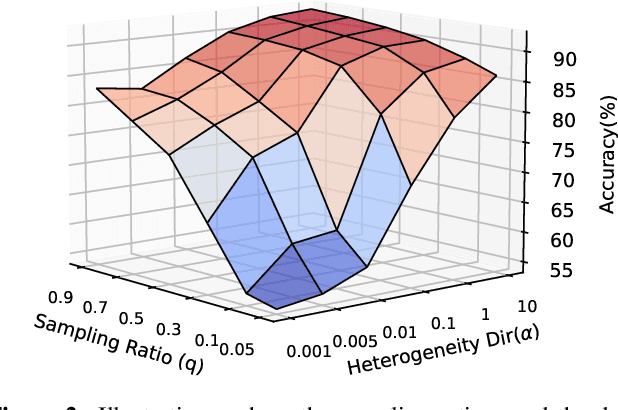
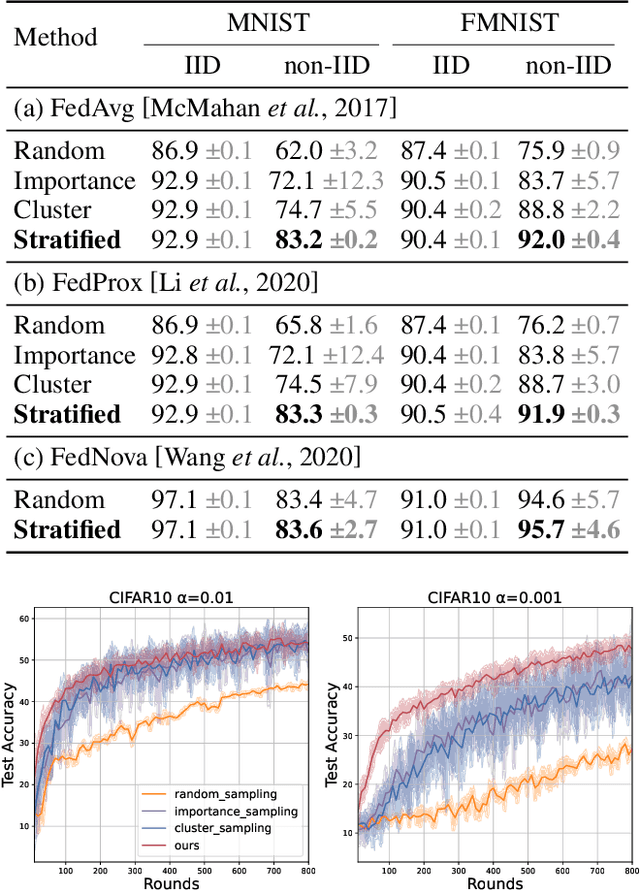
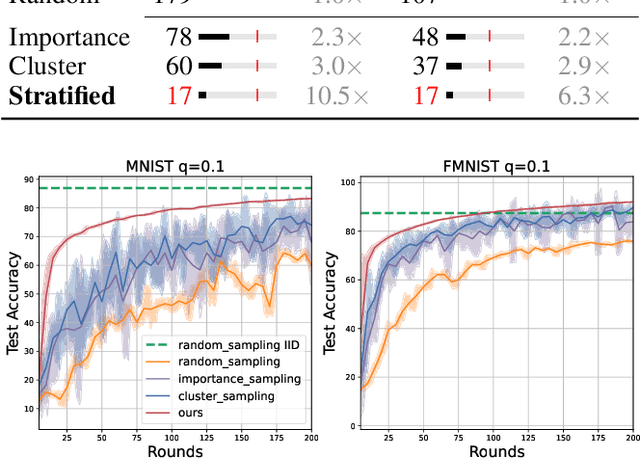
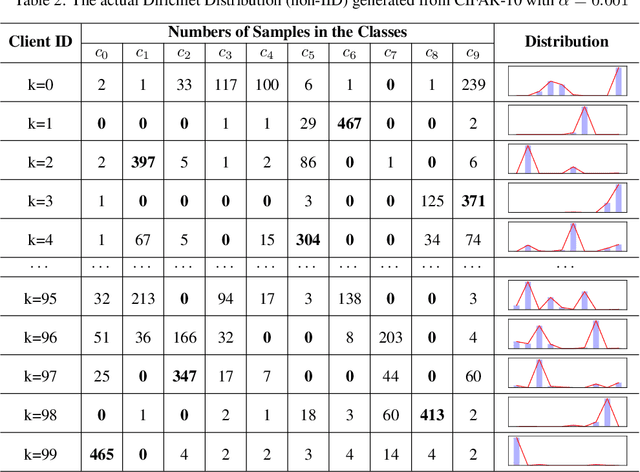
Client selection strategies are widely adopted to handle the communication-efficient problem in recent studies of Federated Learning (FL). However, due to the large variance of the selected subset's update, prior selection approaches with a limited sampling ratio cannot perform well on convergence and accuracy in heterogeneous FL. To address this problem, in this paper, we propose a novel stratified client selection scheme to reduce the variance for the pursuit of better convergence and higher accuracy. Specifically, to mitigate the impact of heterogeneity, we develop stratification based on clients' local data distribution to derive approximate homogeneous strata for better selection in each stratum. Concentrating on a limited sampling ratio scenario, we next present an optimized sample size allocation scheme by considering the diversity of stratum's variability, with the promise of further variance reduction. Theoretically, we elaborate the explicit relation among different selection schemes with regard to variance, under heterogeneous settings, we demonstrate the effectiveness of our selection scheme. Experimental results confirm that our approach not only allows for better performance relative to state-of-the-art methods but also is compatible with prevalent FL algorithms.
Mind the Gap: Cross-Lingual Information Retrieval with Hierarchical Knowledge Enhancement
Dec 27, 2021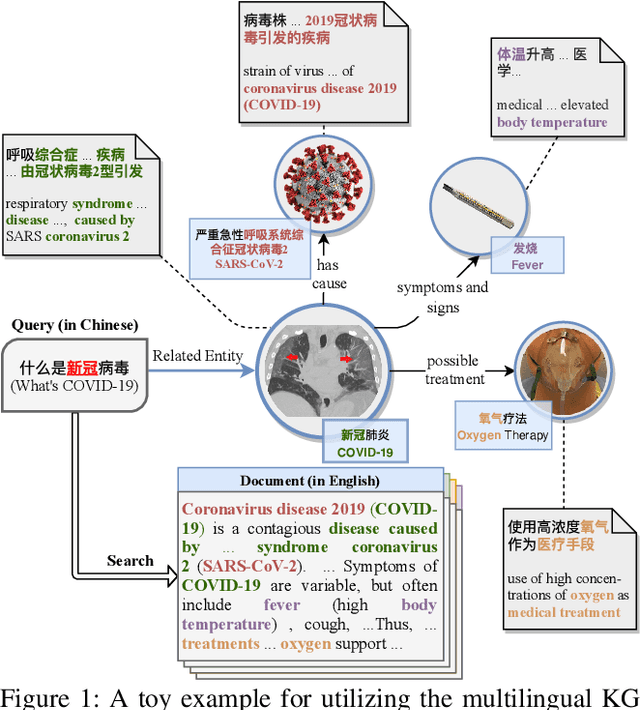
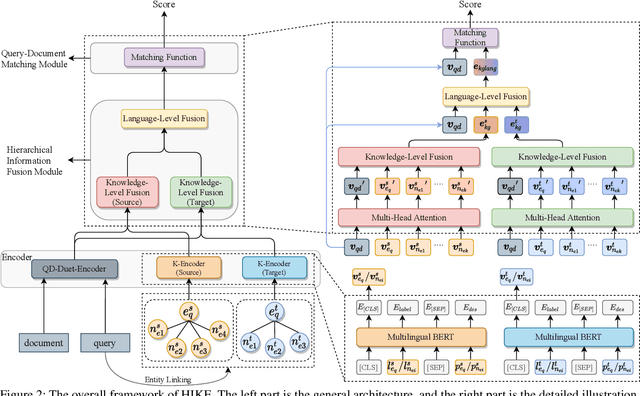
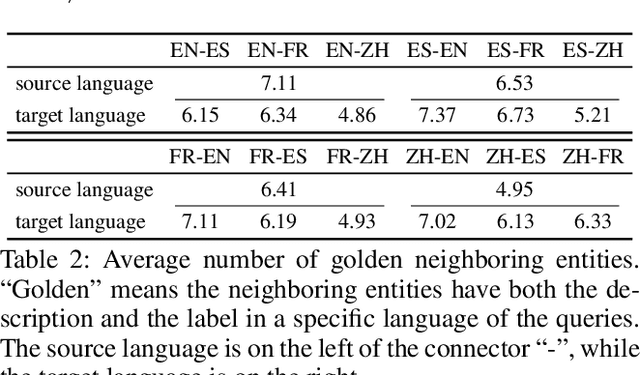
Cross-Lingual Information Retrieval (CLIR) aims to rank the documents written in a language different from the user's query. The intrinsic gap between different languages is an essential challenge for CLIR. In this paper, we introduce the multilingual knowledge graph (KG) to the CLIR task due to the sufficient information of entities in multiple languages. It is regarded as a "silver bullet" to simultaneously perform explicit alignment between queries and documents and also broaden the representations of queries. And we propose a model named CLIR with hierarchical knowledge enhancement (HIKE) for our task. The proposed model encodes the textual information in queries, documents and the KG with multilingual BERT, and incorporates the KG information in the query-document matching process with a hierarchical information fusion mechanism. Particularly, HIKE first integrates the entities and their neighborhood in KG into query representations with a knowledge-level fusion, then combines the knowledge from both source and target languages to further mitigate the linguistic gap with a language-level fusion. Finally, experimental results demonstrate that HIKE achieves substantial improvements over state-of-the-art competitors.
Kaleido-BERT: Vision-Language Pre-training on Fashion Domain
Apr 15, 2021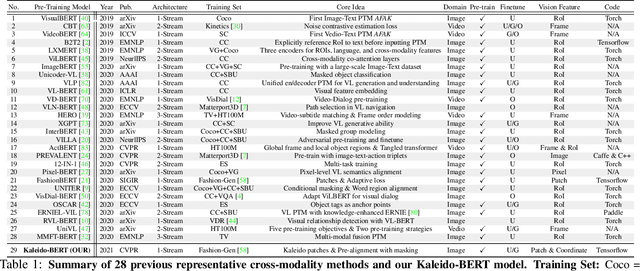
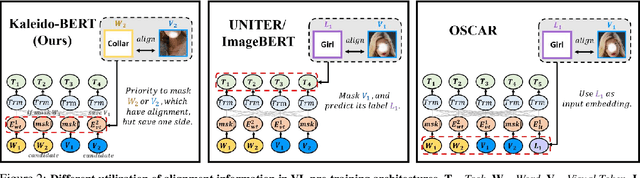
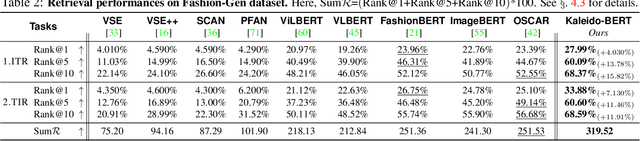
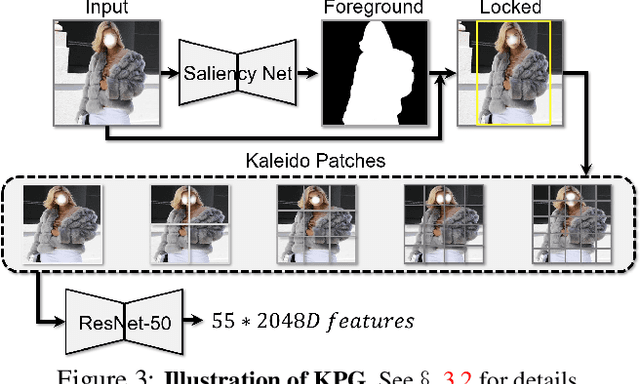
We present a new vision-language (VL) pre-training model dubbed Kaleido-BERT, which introduces a novel kaleido strategy for fashion cross-modality representations from transformers. In contrast to random masking strategy of recent VL models, we design alignment guided masking to jointly focus more on image-text semantic relations. To this end, we carry out five novel tasks, i.e., rotation, jigsaw, camouflage, grey-to-color, and blank-to-color for self-supervised VL pre-training at patches of different scale. Kaleido-BERT is conceptually simple and easy to extend to the existing BERT framework, it attains new state-of-the-art results by large margins on four downstream tasks, including text retrieval (R@1: 4.03% absolute improvement), image retrieval (R@1: 7.13% abs imv.), category recognition (ACC: 3.28% abs imv.), and fashion captioning (Bleu4: 1.2 abs imv.). We validate the efficiency of Kaleido-BERT on a wide range of e-commerical websites, demonstrating its broader potential in real-world applications.
Network Clustering for Multi-task Learning
Jan 22, 2021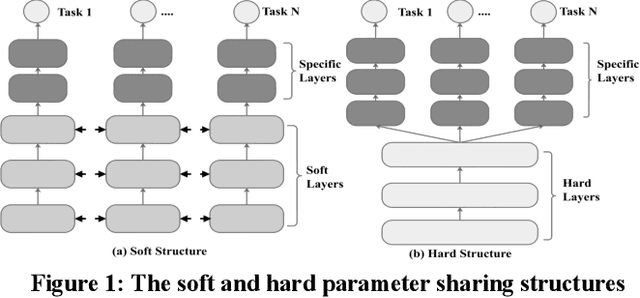
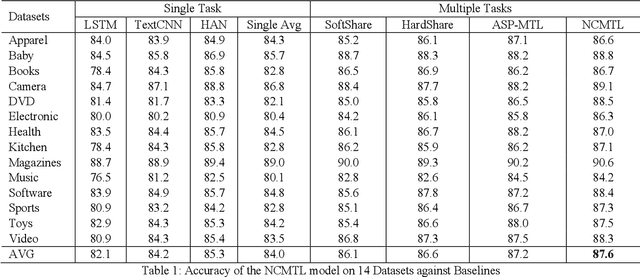
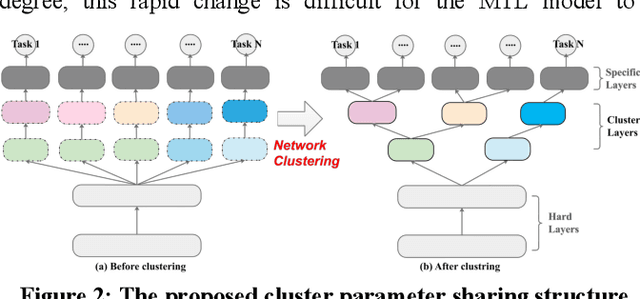
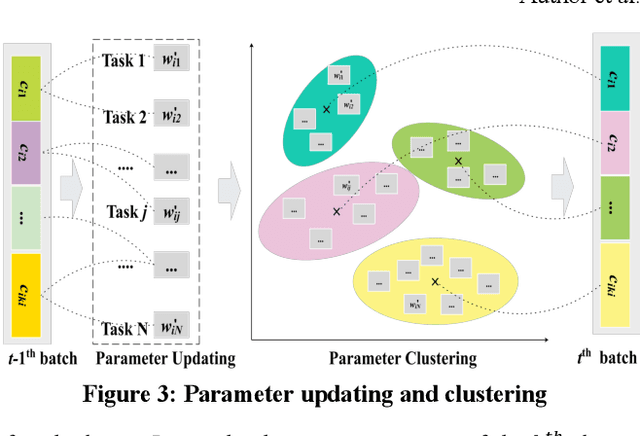
The Multi-Task Learning (MTL) technique has been widely studied by word-wide researchers. The majority of current MTL studies adopt the hard parameter sharing structure, where hard layers tend to learn general representations over all tasks and specific layers are prone to learn specific representations for each task. Since the specific layers directly follow the hard layers, the MTL model needs to estimate this direct change (from general to specific) as well. To alleviate this problem, we introduce the novel cluster layer, which groups tasks into clusters during training procedures. In a cluster layer, the tasks in the same cluster are further required to share the same network. By this way, the cluster layer produces the general presentation for the same cluster, while produces relatively specific presentations for different clusters. As transitions the cluster layers are used between the hard layers and the specific layers. The MTL model thus learns general representations to specific representations gradually. We evaluate our model with MTL document classification and the results demonstrate the cluster layer is quite efficient in MTL.
Transformer-based Language Model Fine-tuning Methods for COVID-19 Fake News Detection
Jan 18, 2021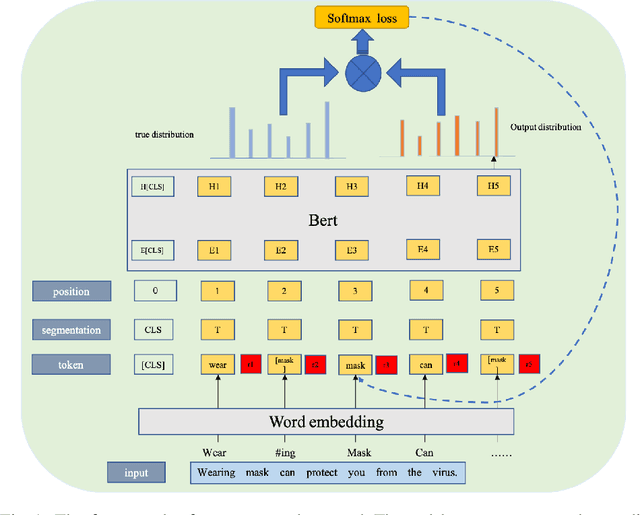
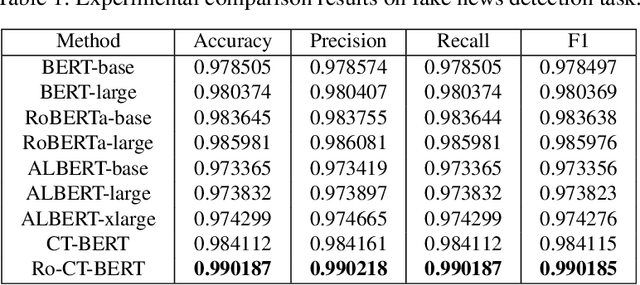
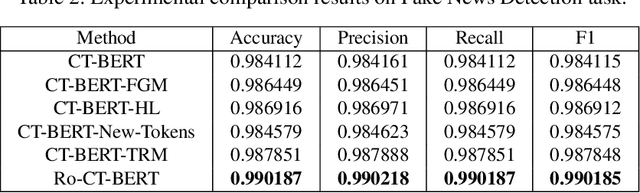
With the pandemic of COVID-19, relevant fake news is spreading all over the sky throughout the social media. Believing in them without discrimination can cause great trouble to people's life. However, universal language models may perform weakly in these fake news detection for lack of large-scale annotated data and sufficient semantic understanding of domain-specific knowledge. While the model trained on corresponding corpora is also mediocre for insufficient learning. In this paper, we propose a novel transformer-based language model fine-tuning approach for these fake news detection. First, the token vocabulary of individual model is expanded for the actual semantics of professional phrases. Second, we adapt the heated-up softmax loss to distinguish the hard-mining samples, which are common for fake news because of the disambiguation of short text. Then, we involve adversarial training to improve the model's robustness. Last, the predicted features extracted by universal language model RoBERTa and domain-specific model CT-BERT are fused by one multiple layer perception to integrate fine-grained and high-level specific representations. Quantitative experimental results evaluated on existing COVID-19 fake news dataset show its superior performances compared to the state-of-the-art methods among various evaluation metrics. Furthermore, the best weighted average F1 score achieves 99.02%.