 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Prompt Tuning for Zero-Shot Generalization in Vision-Language Models
Sep 15, 2022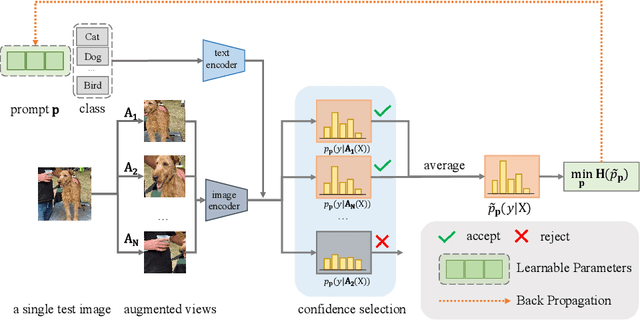
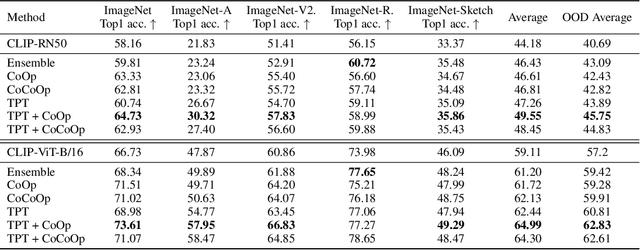
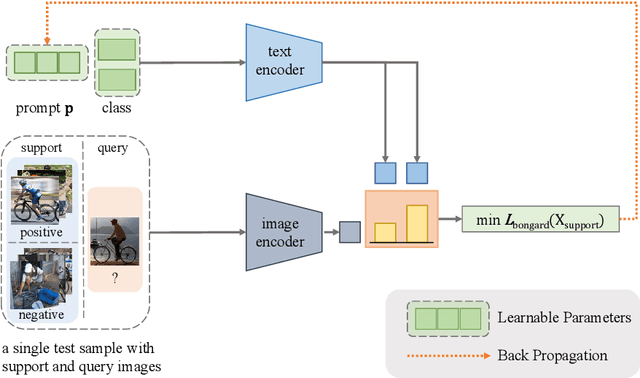
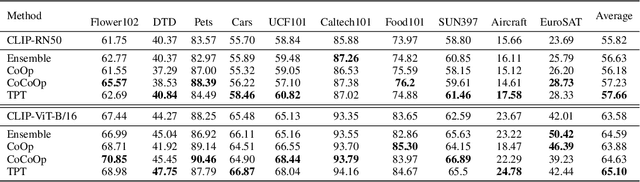
Pre-trained vision-language models (e.g., CLIP) have shown promising zero-shot generalization in many downstream tasks with properly designed text prompts. Instead of relying on hand-engineered prompts, recent works learn prompts using the training data from downstream tasks. While effective, training on domain-specific data reduces a model's generalization capability to unseen new domains. In this work, we propose test-time prompt tuning (TPT), a method that can learn adaptive prompts on the fly with a single test sample. For image classification, TPT optimizes the prompt by minimizing the entropy with confidence selection so that the model has consistent predictions across different augmented views of each test sample. In evaluating generalization to natural distribution shifts, TPT improves the zero-shot top-1 accuracy of CLIP by 3.6% on average, surpassing previous prompt tuning approaches that require additional task-specific training data. In evaluating cross-dataset generalization with unseen categories, TPT performs on par with the state-of-the-art approaches that use additional training data. Project page: https://azshue.github.io/TPT.
Identifying Auxiliary or Adversarial Tasks Using Necessary Condition Analysis for Adversarial Multi-task Video Understanding
Aug 22, 2022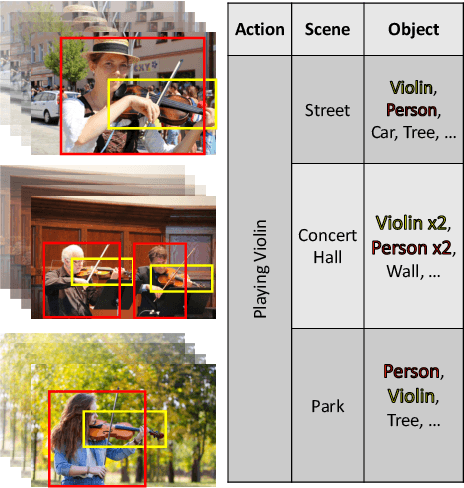
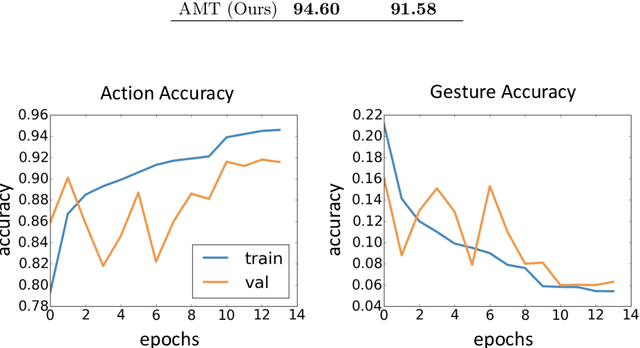
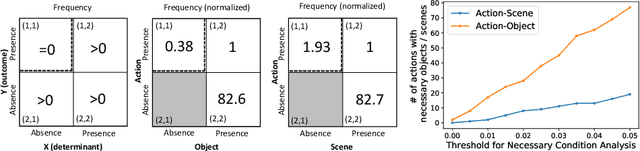
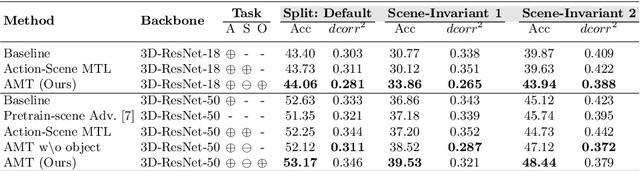
There has been an increasing interest in multi-task learning for video understanding in recent years. In this work, we propose a generalized notion of multi-task learning by incorporating both auxiliary tasks that the model should perform well on and adversarial tasks that the model should not perform well on. We employ Necessary Condition Analysis (NCA) as a data-driven approach for deciding what category these tasks should fall in. Our novel proposed framework, Adversarial Multi-Task Neural Networks (AMT), penalizes adversarial tasks, determined by NCA to be scene recognition in the Holistic Video Understanding (HVU) dataset, to improve action recognition. This upends the common assumption that the model should always be encouraged to do well on all tasks in multi-task learning. Simultaneously, AMT still retains all the benefits of multi-task learning as a generalization of existing methods and uses object recognition as an auxiliary task to aid action recognition. We introduce two challenging Scene-Invariant test splits of HVU, where the model is evaluated on action-scene co-occurrences not encountered in training. We show that our approach improves accuracy by ~3% and encourages the model to attend to action features instead of correlation-biasing scene features.
MinVIS: A Minimal Video Instance Segmentation Framework without Video-based Training
Aug 03, 2022
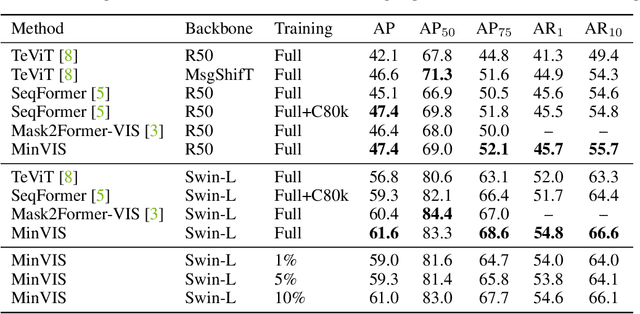
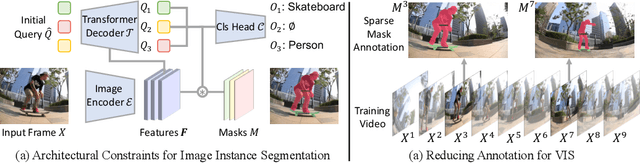
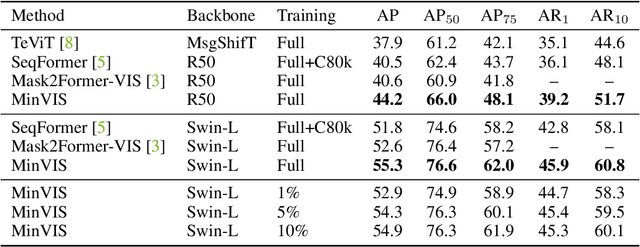
We propose MinVIS, a minimal video instance segmentation (VIS) framework that achieves state-of-the-art VIS performance with neither video-based architectures nor training procedures. By only training a query-based image instance segmentation model, MinVIS outperforms the previous best result on the challenging Occluded VIS dataset by over 10% AP. Since MinVIS treats frames in training videos as independent images, we can drastically sub-sample the annotated frames in training videos without any modifications. With only 1% of labeled frames, MinVIS outperforms or is comparable to fully-supervised state-of-the-art approaches on YouTube-VIS 2019/2021. Our key observation is that queries trained to be discriminative between intra-frame object instances are temporally consistent and can be used to track instances without any manually designed heuristics. MinVIS thus has the following inference pipeline: we first apply the trained query-based image instance segmentation to video frames independently. The segmented instances are then tracked by bipartite matching of the corresponding queries. This inference is done in an online fashion and does not need to process the whole video at once. MinVIS thus has the practical advantages of reducing both the labeling costs and the memory requirements, while not sacrificing the VIS performance. Code is available at: https://github.com/NVlabs/MinVIS
MineDojo: Building Open-Ended Embodied Agents with Internet-Scale Knowledge
Jun 17, 2022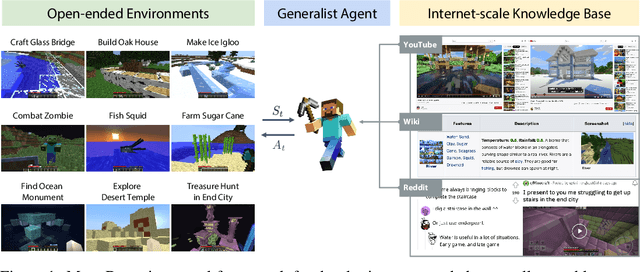
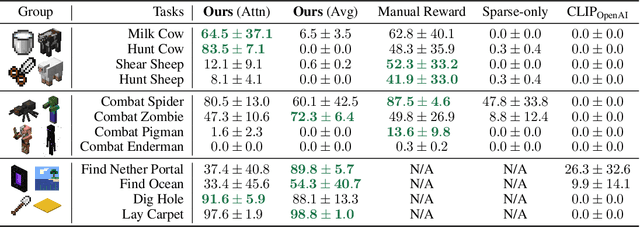
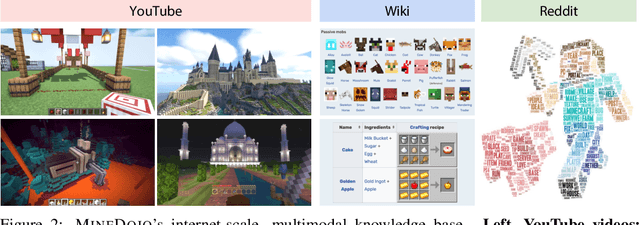

Autonomous agents have made great strides in specialist domains like Atari games and Go. However, they typically learn tabula rasa in isolated environments with limited and manually conceived objectives, thus failing to generalize across a wide spectrum of tasks and capabilities. Inspired by how humans continually learn and adapt in the open world, we advocate a trinity of ingredients for building generalist agents: 1) an environment that supports a multitude of tasks and goals, 2) a large-scale database of multimodal knowledge, and 3) a flexible and scalable agent architecture. We introduce MineDojo, a new framework built on the popular Minecraft game that features a simulation suite with thousands of diverse open-ended tasks and an internet-scale knowledge base with Minecraft videos, tutorials, wiki pages, and forum discussions. Using MineDojo's data, we propose a novel agent learning algorithm that leverages large pre-trained video-language models as a learned reward function. Our agent is able to solve a variety of open-ended tasks specified in free-form language without any manually designed dense shaping reward. We open-source the simulation suite and knowledge bases (https://minedojo.org) to promote research towards the goal of generally capable embodied agents.
Auditing AI models for Verified Deployment under Semantic Specifications
Sep 25, 2021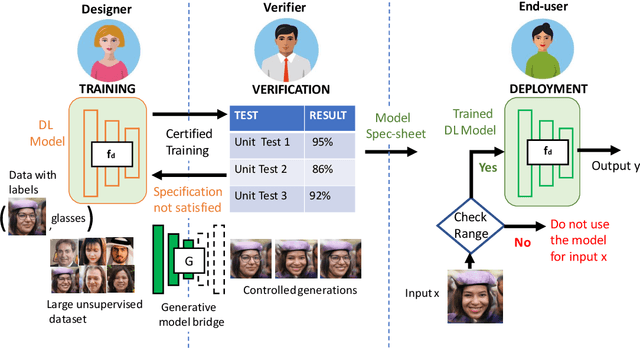
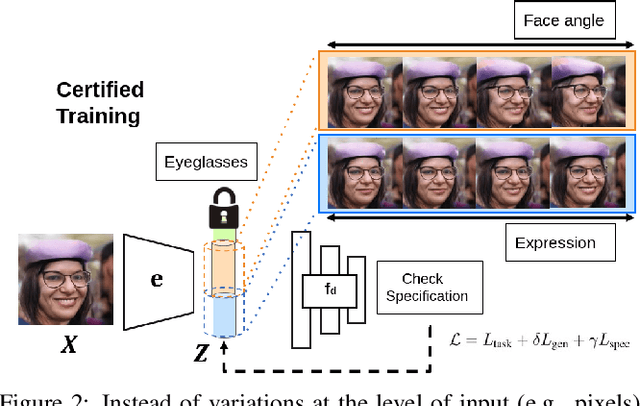


Auditing trained deep learning (DL) models prior to deployment is vital in preventing unintended consequences. One of the biggest challenges in auditing is in understanding how we can obtain human-interpretable specifications that are directly useful to the end-user. We address this challenge through a sequence of semantically-aligned unit tests, where each unit test verifies whether a predefined specification (e.g., accuracy over 95%) is satisfied with respect to controlled and semantically aligned variations in the input space (e.g., in face recognition, the angle relative to the camera). We perform these unit tests by directly verifying the semantically aligned variations in an interpretable latent space of a generative model. Our framework, AuditAI, bridges the gap between interpretable formal verification and scalability. With evaluations on four different datasets, covering images of towers, chest X-rays, human faces, and ImageNet classes, we show how AuditAI allows us to obtain controlled variations for verification and certified training while addressing the limitations of verifying using only pixel-space perturbations. A blog post accompanying the paper is at this link https://developer.nvidia.com/blog/nvidia-research-auditing-ai-models-for-verified-deployment-under-semantic-specifications
PlaTe: Visually-Grounded Planning with Transformers in Procedural Tasks
Sep 10, 2021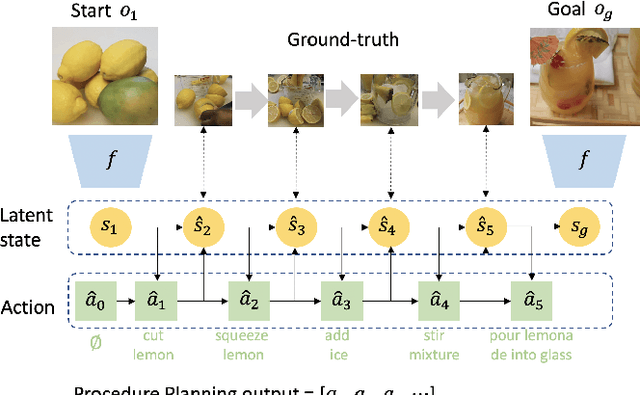
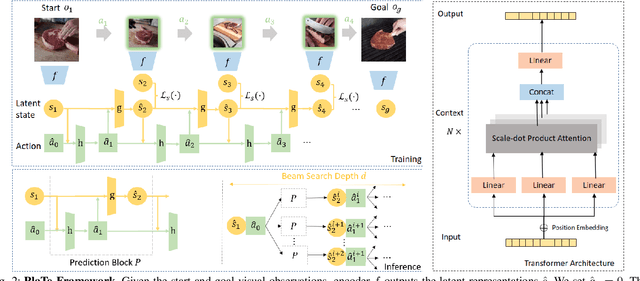
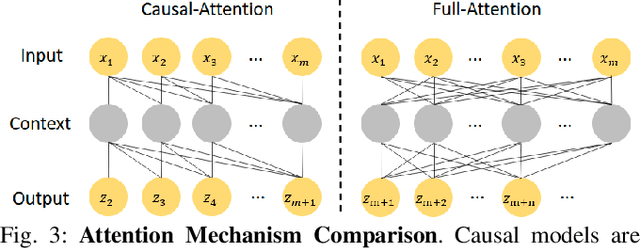

In this work, we study the problem of how to leverage instructional videos to facilitate the understanding of human decision-making processes, focusing on training a model with the ability to plan a goal-directed procedure from real-world videos. Learning structured and plannable state and action spaces directly from unstructured videos is the key technical challenge of our task. There are two problems: first, the appearance gap between the training and validation datasets could be large for unstructured videos; second, these gaps lead to decision errors that compound over the steps. We address these limitations with Planning Transformer (PlaTe), which has the advantage of circumventing the compounding prediction errors that occur with single-step models during long model-based rollouts. Our method simultaneously learns the latent state and action information of assigned tasks and the representations of the decision-making process from human demonstrations. Experiments conducted on real-world instructional videos and an interactive environment show that our method can achieve a better performance in reaching the indicated goal than previous algorithms. We also validated the possibility of applying procedural tasks on a UR-5 platform.
SECANT: Self-Expert Cloning for Zero-Shot Generalization of Visual Policies
Jun 17, 2021
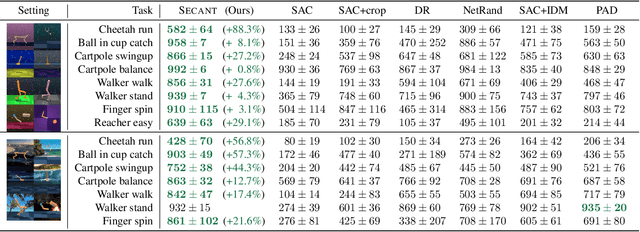
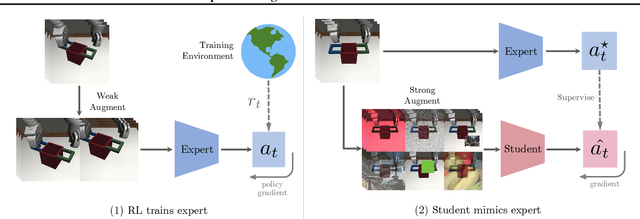
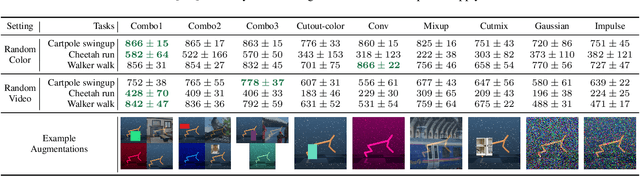
Generalization has been a long-standing challenge for reinforcement learning (RL). Visual RL, in particular, can be easily distracted by irrelevant factors in high-dimensional observation space. In this work, we consider robust policy learning which targets zero-shot generalization to unseen visual environments with large distributional shift. We propose SECANT, a novel self-expert cloning technique that leverages image augmentation in two stages to decouple robust representation learning from policy optimization. Specifically, an expert policy is first trained by RL from scratch with weak augmentations. A student network then learns to mimic the expert policy by supervised learning with strong augmentations, making its representation more robust against visual variations compared to the expert. Extensive experiments demonstrate that SECANT significantly advances the state of the art in zero-shot generalization across 4 challenging domains. Our average reward improvements over prior SOTAs are: DeepMind Control (+26.5%), robotic manipulation (+337.8%), vision-based autonomous driving (+47.7%), and indoor object navigation (+15.8%). Code release and video are available at https://linxifan.github.io/secant-site/.
Spatio-Temporal Graph for Video Captioning with Knowledge Distillation
Mar 31, 2020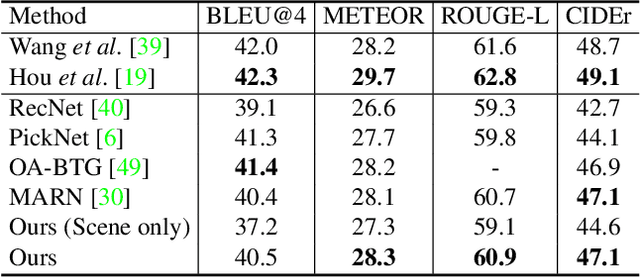
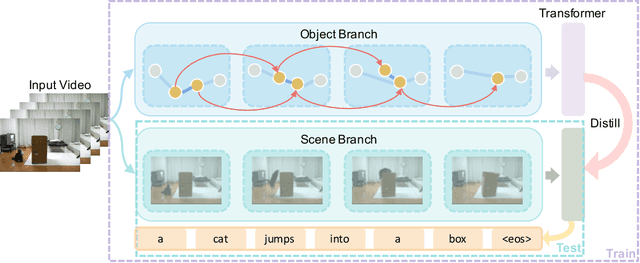
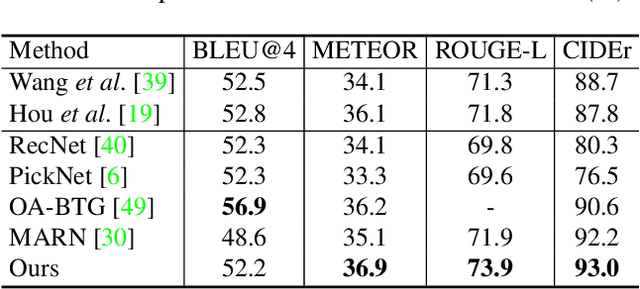
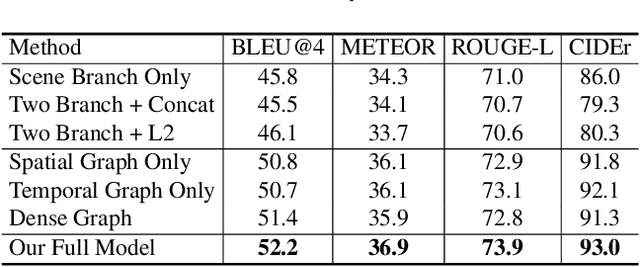
Video captioning is a challenging task that requires a deep understanding of visual scenes. State-of-the-art methods generate captions using either scene-level or object-level information but without explicitly modeling object interactions. Thus, they often fail to make visually grounded predictions, and are sensitive to spurious correlations. In this paper, we propose a novel spatio-temporal graph model for video captioning that exploits object interactions in space and time. Our model builds interpretable links and is able to provide explicit visual grounding. To avoid unstable performance caused by the variable number of objects, we further propose an object-aware knowledge distillation mechanism, in which local object information is used to regularize global scene features. We demonstrate the efficacy of our approach through extensive experiments on two benchmarks, showing our approach yields competitive performance with interpretable predictions.
Motion Reasoning for Goal-Based Imitation Learning
Nov 13, 2019
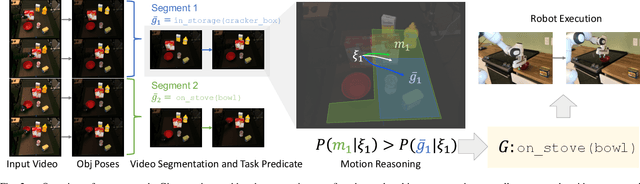
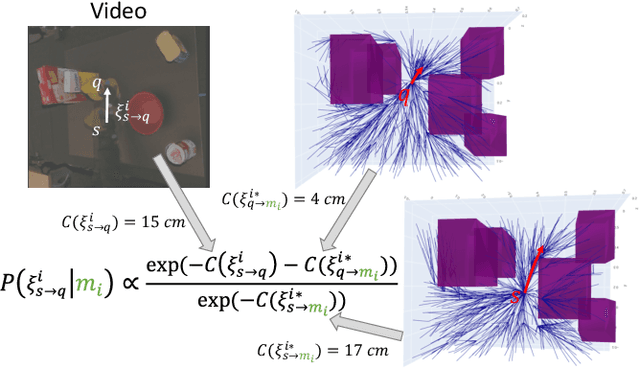

We address goal-based imitation learning, where the aim is to output the symbolic goal from a third-person video demonstration. This enables the robot to plan for execution and reproduce the same goal in a completely different environment. The key challenge is that the goal of a video demonstration is often ambiguous at the level of semantic actions. The human demonstrators might unintentionally achieve certain subgoals in the demonstrations with their actions. Our main contribution is to propose a motion reasoning framework that combines task and motion planning to disambiguate the true intention of the demonstrator in the video demonstration. This allows us to robustly recognize the goals that cannot be disambiguated by previous action-based approaches. We evaluate our approach by collecting a dataset of 96 video demonstrations in a mockup kitchen environment. We show that our motion reasoning plays an important role in recognizing the actual goal of the demonstrator and improves the success rate by over 20%. We further show that by using the automatically inferred goal from the video demonstration, our robot is able to reproduce the same task in a real kitchen environment.
Regression Planning Networks
Sep 28, 2019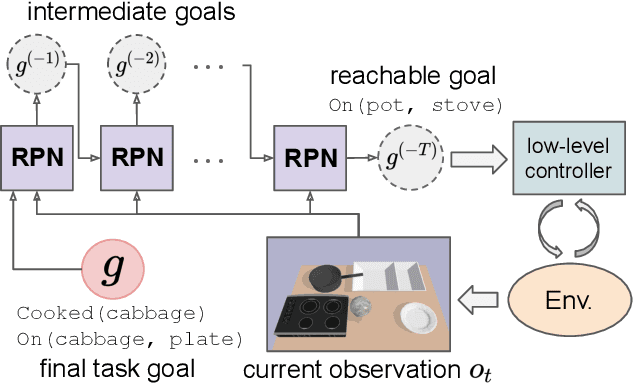
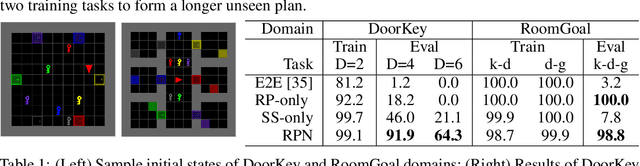
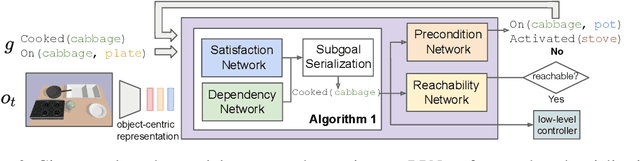
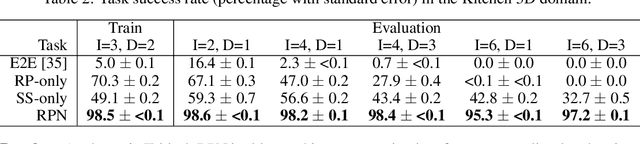
Recent learning-to-plan methods have shown promising results on planning directly from observation space. Yet, their ability to plan for long-horizon tasks is limited by the accuracy of the prediction model. On the other hand, classical symbolic planners show remarkable capabilities in solving long-horizon tasks, but they require predefined symbolic rules and symbolic states, restricting their real-world applicability. In this work, we combine the benefits of these two paradigms and propose a learning-to-plan method that can directly generate a long-term symbolic plan conditioned on high-dimensional observations. We borrow the idea of regression (backward) planning from classical planning literature and introduce Regression Planning Networks (RPN), a neural network architecture that plans backward starting at a task goal and generates a sequence of intermediate goals that reaches the current observation. We show that our model not only inherits many favorable traits from symbolic planning, e.g., the ability to solve previously unseen tasks but also can learn from visual inputs in an end-to-end manner. We evaluate the capabilities of RPN in a grid world environment and a simulated 3D kitchen environment featuring complex visual scenes and long task horizons, and show that it achieves near-optimal performance in completely new task instances.