 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Pooling Enhances NCA-based Classification of Microscopy Images
Aug 17, 2025Neural Cellular Automata (NCA) offer a robust and interpretable approach to image classification, making them a promising choice for microscopy image analysis. However, a performance gap remains between NCA and larger, more complex architectures. We address this challenge by integrating attention pooling with NCA to enhance feature extraction and improve classification accuracy. The attention pooling mechanism refines the focus on the most informative regions, leading to more accurate predictions. We evaluate our method on eight diverse microscopy image datasets and demonstrate that our approach significantly outperforms existing NCA methods while remaining parameter-efficient and explainable. Furthermore, we compare our method with traditional lightweight convolutional neural network and vision transformer architectures, showing improved performance while maintaining a significantly lower parameter count. Our results highlight the potential of NCA-based models an alternative for explainable image classification.
Neural Cellular Automata for Weakly Supervised Segmentation of White Blood Cells
Aug 17, 2025The detection and segmentation of white blood cells in blood smear images is a key step in medical diagnostics, supporting various downstream tasks such as automated blood cell counting, morphological analysis, cell classification, and disease diagnosis and monitoring. Training robust and accurate models requires large amounts of labeled data, which is both time-consuming and expensive to acquire. In this work, we propose a novel approach for weakly supervised segmentation using neural cellular automata (NCA-WSS). By leveraging the feature maps generated by NCA during classification, we can extract segmentation masks without the need for retraining with segmentation labels. We evaluate our method on three white blood cell microscopy datasets and demonstrate that NCA-WSS significantly outperforms existing weakly supervised approaches. Our work illustrates the potential of NCA for both classification and segmentation in a weakly supervised framework, providing a scalable and efficient solution for medical image analysis.
Business as Rulesual: A Benchmark and Framework for Business Rule Flow Modeling with LLMs
May 29, 2025Process mining aims to discover, monitor and optimize the actual behaviors of real processes. While prior work has mainly focused on extracting procedural action flows from instructional texts, rule flows embedded in business documents remain underexplored. To this end, we introduce a novel annotated Chinese dataset, BPRF, which contains 50 business process documents with 326 explicitly labeled business rules across multiple domains. Each rule is represented as a <Condition, Action> pair, and we annotate logical dependencies between rules (sequential, conditional, or parallel). We also propose ExIde, a framework for automatic business rule extraction and dependency relationship identification using large language models (LLMs). We evaluate ExIde using 12 state-of-the-art (SOTA) LLMs on the BPRF dataset, benchmarking performance on both rule extraction and dependency classification tasks of current LLMs. Our results demonstrate the effectiveness of ExIde in extracting structured business rules and analyzing their interdependencies for current SOTA LLMs, paving the way for more automated and interpretable business process automation.
Business as \textit{Rule}sual: A Benchmark and Framework for Business Rule Flow Modeling with LLMs
May 24, 2025Process mining aims to discover, monitor and optimize the actual behaviors of real processes. While prior work has mainly focused on extracting procedural action flows from instructional texts, rule flows embedded in business documents remain underexplored. To this end, we introduce a novel annotated Chinese dataset, \textbf{BPRF}, which contains 50 business process documents with 326 explicitly labeled business rules across multiple domains. Each rule is represented as a <Condition, Action> pair, and we annotate logical dependencies between rules (sequential, conditional, or parallel). We also propose \textbf{ExIde}, a framework for automatic business rule extraction and dependency relationship identification using large language models (LLMs). We evaluate ExIde using 12 state-of-the-art (SOTA) LLMs on the BPRF dataset, benchmarking performance on both rule extraction and dependency classification tasks of current LLMs. Our results demonstrate the effectiveness of ExIde in extracting structured business rules and analyzing their interdependencies for current SOTA LLMs, paving the way for more automated and interpretable business process automation.
BehaveGPT: A Foundation Model for Large-scale User Behavior Modeling
May 23, 2025In recent years, foundational models have revolutionized the fields of language and vision, demonstrating remarkable abilities in understanding and generating complex data; however, similar advances in user behavior modeling have been limited, largely due to the complexity of behavioral data and the challenges involved in capturing intricate temporal and contextual relationships in user activities. To address this, we propose BehaveGPT, a foundational model designed specifically for large-scale user behavior prediction. Leveraging transformer-based architecture and a novel pretraining paradigm, BehaveGPT is trained on vast user behavior datasets, allowing it to learn complex behavior patterns and support a range of downstream tasks, including next behavior prediction, long-term generation, and cross-domain adaptation. Our approach introduces the DRO-based pretraining paradigm tailored for user behavior data, which improves model generalization and transferability by equitably modeling both head and tail behaviors. Extensive experiments on real-world datasets demonstrate that BehaveGPT outperforms state-of-the-art baselines, achieving more than a 10% improvement in macro and weighted recall, showcasing its ability to effectively capture and predict user behavior. Furthermore, we measure the scaling law in the user behavior domain for the first time on the Honor dataset, providing insights into how model performance scales with increased data and parameter sizes.
Tuning Language Models for Robust Prediction of Diverse User Behaviors
May 23, 2025Predicting user behavior is essential for intelligent assistant services, yet deep learning models often struggle to capture long-tailed behaviors. Large language models (LLMs), with their pretraining on vast corpora containing rich behavioral knowledge, offer promise. However, existing fine-tuning approaches tend to overfit to frequent ``anchor'' behaviors, reducing their ability to predict less common ``tail'' behaviors. In this paper, we introduce BehaviorLM, a progressive fine-tuning approach that addresses this issue. In the first stage, LLMs are fine-tuned on anchor behaviors while preserving general behavioral knowledge. In the second stage, fine-tuning uses a balanced subset of all behaviors based on sample difficulty to improve tail behavior predictions without sacrificing anchor performance. Experimental results on two real-world datasets demonstrate that BehaviorLM robustly predicts both anchor and tail behaviors and effectively leverages LLM behavioral knowledge to master tail behavior prediction with few-shot examples.
MMAR: A Challenging Benchmark for Deep Reasoning in Speech, Audio, Music, and Their Mix
May 19, 2025



We introduce MMAR, a new benchmark designed to evaluate the deep reasoning capabilities of Audio-Language Models (ALMs) across massive multi-disciplinary tasks. MMAR comprises 1,000 meticulously curated audio-question-answer triplets, collected from real-world internet videos and refined through iterative error corrections and quality checks to ensure high quality. Unlike existing benchmarks that are limited to specific domains of sound, music, or speech, MMAR extends them to a broad spectrum of real-world audio scenarios, including mixed-modality combinations of sound, music, and speech. Each question in MMAR is hierarchically categorized across four reasoning layers: Signal, Perception, Semantic, and Cultural, with additional sub-categories within each layer to reflect task diversity and complexity. To further foster research in this area, we annotate every question with a Chain-of-Thought (CoT) rationale to promote future advancements in audio reasoning. Each item in the benchmark demands multi-step deep reasoning beyond surface-level understanding. Moreover, a part of the questions requires graduate-level perceptual and domain-specific knowledge, elevating the benchmark's difficulty and depth. We evaluate MMAR using a broad set of models, including Large Audio-Language Models (LALMs), Large Audio Reasoning Models (LARMs), Omni Language Models (OLMs), Large Language Models (LLMs), and Large Reasoning Models (LRMs), with audio caption inputs. The performance of these models on MMAR highlights the benchmark's challenging nature, and our analysis further reveals critical limitations of understanding and reasoning capabilities among current models. We hope MMAR will serve as a catalyst for future advances in this important but little-explored area.
Using LLMs in Generating Design Rationale for Software Architecture Decisions
Apr 29, 2025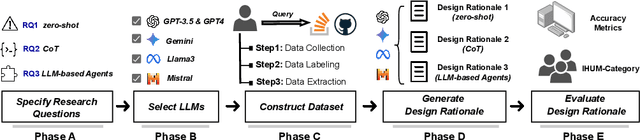
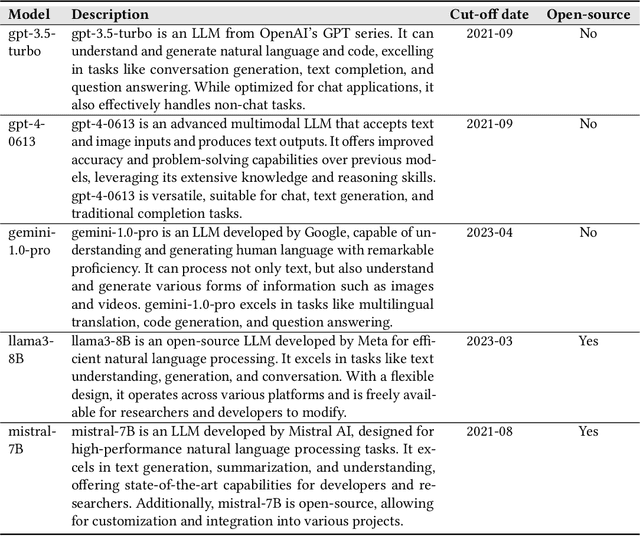
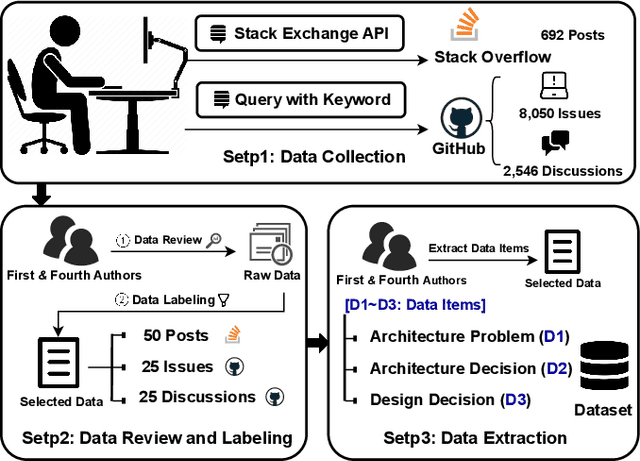
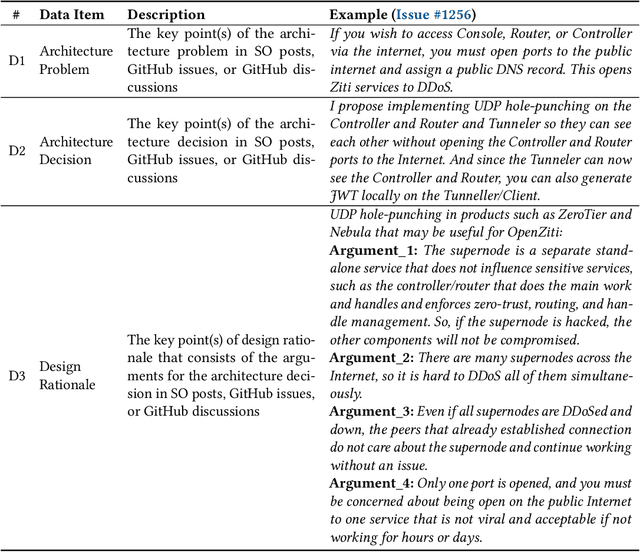
Design Rationale (DR) for software architecture decisions refers to the reasoning underlying architectural choices, which provides valuable insights into the different phases of the architecting process throughout software development. However, in practice, DR is often inadequately documented due to a lack of motivation and effort from developers. With the recent advancements in Large Language Models (LLMs), their capabilities in text comprehension, reasoning, and generation may enable the generation and recovery of DR for architecture decisions. In this study, we evaluated the performance of LLMs in generating DR for architecture decisions. First, we collected 50 Stack Overflow (SO) posts, 25 GitHub issues, and 25 GitHub discussions related to architecture decisions to construct a dataset of 100 architecture-related problems. Then, we selected five LLMs to generate DR for the architecture decisions with three prompting strategies, including zero-shot, chain of thought (CoT), and LLM-based agents. With the DR provided by human experts as ground truth, the Precision of LLM-generated DR with the three prompting strategies ranges from 0.267 to 0.278, Recall from 0.627 to 0.715, and F1-score from 0.351 to 0.389. Additionally, 64.45% to 69.42% of the arguments of DR not mentioned by human experts are also helpful, 4.12% to 4.87% of the arguments have uncertain correctness, and 1.59% to 3.24% of the arguments are potentially misleading. Based on the results, we further discussed the pros and cons of the three prompting strategies and the strengths and limitations of the DR generated by LLMs.
EmoVoice: LLM-based Emotional Text-To-Speech Model with Freestyle Text Prompting
Apr 22, 2025Human speech goes beyond the mere transfer of information; it is a profound exchange of emotions and a connection between individuals. While Text-to-Speech (TTS) models have made huge progress, they still face challenges in controlling the emotional expression in the generated speech. In this work, we propose EmoVoice, a novel emotion-controllable TTS model that exploits large language models (LLMs) to enable fine-grained freestyle natural language emotion control, and a phoneme boost variant design that makes the model output phoneme tokens and audio tokens in parallel to enhance content consistency, inspired by chain-of-thought (CoT) and chain-of-modality (CoM) techniques. Besides, we introduce EmoVoice-DB, a high-quality 40-hour English emotion dataset featuring expressive speech and fine-grained emotion labels with natural language descriptions. EmoVoice achieves state-of-the-art performance on the English EmoVoice-DB test set using only synthetic training data, and on the Chinese Secap test set using our in-house data. We further investigate the reliability of existing emotion evaluation metrics and their alignment with human perceptual preferences, and explore using SOTA multimodal LLMs GPT-4o-audio and Gemini to assess emotional speech. Demo samples are available at https://yanghaha0908.github.io/EmoVoice/. Dataset, code, and checkpoints will be released.
Dereflection Any Image with Diffusion Priors and Diversified Data
Mar 21, 2025Reflection removal of a single image remains a highly challenging task due to the complex entanglement between target scenes and unwanted reflections. Despite significant progress, existing methods are hindered by the scarcity of high-quality, diverse data and insufficient restoration priors, resulting in limited generalization across various real-world scenarios. In this paper, we propose Dereflection Any Image, a comprehensive solution with an efficient data preparation pipeline and a generalizable model for robust reflection removal. First, we introduce a dataset named Diverse Reflection Removal (DRR) created by randomly rotating reflective mediums in target scenes, enabling variation of reflection angles and intensities, and setting a new benchmark in scale, quality, and diversity. Second, we propose a diffusion-based framework with one-step diffusion for deterministic outputs and fast inference. To ensure stable learning, we design a three-stage progressive training strategy, including reflection-invariant finetuning to encourage consistent outputs across varying reflection patterns that characterize our dataset. Extensive experiments show that our method achieves SOTA performance on both common benchmarks and challenging in-the-wild images, showing superior generalization across diverse real-world scenes.