 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Functional Correctness: Design Issues in AI IDE-Generated Large-Scale Projects
Apr 07, 2026New generation of AI coding tools, including AI-powered IDEs equipped with agentic capabilities, can generate code within the context of the project. These AI IDEs are increasingly perceived as capable of producing project-level code at scale. However, there is limited empirical evidence on the extent to which they can generate large-scale software systems and what design issues such systems may exhibit. To address this gap, we conducted a study to explore the capability of Cursor in generating large-scale projects and to evaluate the design quality of projects generated by Cursor. First, we propose a Feature-Driven Human-In-The-Loop (FD-HITL) framework that systematically guides project generation from curated project descriptions. We generated 10 projects using Cursor with the FD-HITL framework across three application domains and multiple technologies. We assessed the functional correctness of these projects through manual evaluation, obtaining an average functional correctness score of 91%. Next, we analyzed the generated projects using two static analysis tools, CodeScene and SonarQube, to detect design issues. We identified 1,305 design issues categorized into 9 categories by CodeScene and 3,193 issues in 11 categories by SonarQube. Our findings show that (1) when used with the FD-HITL framework, Cursor can generate functional large-scale projects averaging 16,965 LoC and 114 files; (2) the generated projects nevertheless contain design issues that may pose long-term maintainability and evolvability risks, requiring careful review by experienced developers; (3) the most prevalent issues include Code Duplication, high Code Complexity, Large Methods, Framework Best-Practice Violations, Exception-Handling Issues and Accessibility Issues; (4) these design issues violate design principles such as SRP, SoC, and DRY. The replication package is at https://github.com/Kashifraz/DIinAGP
Age Matters: Analyzing Age-Related Discussions in App Reviews
Jan 29, 2026In recent years, mobile applications have become indispensable tools for managing various aspects of life. From enhancing productivity to providing personalized entertainment, mobile apps have revolutionized people's daily routines. Despite this rapid growth and popularity, gaps remain in how these apps address the needs of users from different age groups. Users of varying ages face distinct challenges when interacting with mobile apps, from younger users dealing with inappropriate content to older users having difficulty with usability due to age-related vision and cognition impairments. Although there have been initiatives to create age-inclusive apps, a limited understanding of user perspectives on age-related issues may hinder developers from recognizing specific challenges and implementing effective solutions. In this study, we explore age discussions in app reviews to gain insights into how mobile apps should cater to users across different age groups.We manually curated a dataset of 4,163 app reviews from the Google Play Store and identified 1,429 age-related reviews and 2,734 non-age-related reviews. We employed eight machine learning, deep learning, and large language models to automatically detect age discussions, with RoBERTa performing the best, achieving a precision of 92.46%. Additionally, a qualitative analysis of the 1,429 age-related reviews uncovers six dominant themes reflecting user concerns.
FasterPy: An LLM-based Code Execution Efficiency Optimization Framework
Dec 28, 2025Code often suffers from performance bugs. These bugs necessitate the research and practice of code optimization. Traditional rule-based methods rely on manually designing and maintaining rules for specific performance bugs (e.g., redundant loops, repeated computations), making them labor-intensive and limited in applicability. In recent years, machine learning and deep learning-based methods have emerged as promising alternatives by learning optimization heuristics from annotated code corpora and performance measurements. However, these approaches usually depend on specific program representations and meticulously crafted training datasets, making them costly to develop and difficult to scale. With the booming of Large Language Models (LLMs), their remarkable capabilities in code generation have opened new avenues for automated code optimization. In this work, we proposed FasterPy, a low-cost and efficient framework that adapts LLMs to optimize the execution efficiency of Python code. FasterPy combines Retrieval-Augmented Generation (RAG), supported by a knowledge base constructed from existing performance-improving code pairs and corresponding performance measurements, with Low-Rank Adaptation (LoRA) to enhance code optimization performance. Our experimental results on the Performance Improving Code Edits (PIE) benchmark demonstrate that our method outperforms existing models on multiple metrics. The FasterPy tool and the experimental results are available at https://github.com/WuYue22/fasterpy.
Designing LLM-based Multi-Agent Systems for Software Engineering Tasks: Quality Attributes, Design Patterns and Rationale
Nov 11, 2025As the complexity of Software Engineering (SE) tasks continues to escalate, Multi-Agent Systems (MASs) have emerged as a focal point of research and practice due to their autonomy and scalability. Furthermore, through leveraging the reasoning and planning capabilities of Large Language Models (LLMs), the application of LLM-based MASs in the field of SE is garnering increasing attention. However, there is no dedicated study that systematically explores the design of LLM-based MASs, including the Quality Attributes (QAs) on which the designers mainly focus, the design patterns used by the designers, and the rationale guiding the design of LLM-based MASs for SE tasks. To this end, we conducted a study to identify the QAs that LLM-based MASs for SE tasks focus on, the design patterns used in the MASs, and the design rationale for the MASs. We collected 94 papers on LLM-based MASs for SE tasks as the source. Our study shows that: (1) Code Generation is the most common SE task solved by LLM-based MASs among ten identified SE tasks, (2) Functional Suitability is the QA on which designers of LLM-based MASs pay the most attention, (3) Role-Based Cooperation is the design pattern most frequently employed among 16 patterns used to construct LLM-based MASs, and (4) Improving the Quality of Generated Code is the most common rationale behind the design of LLM-based MASs. Based on the study results, we presented the implications for the design of LLM-based MASs to support SE tasks.
Using LLMs in Generating Design Rationale for Software Architecture Decisions
Apr 29, 2025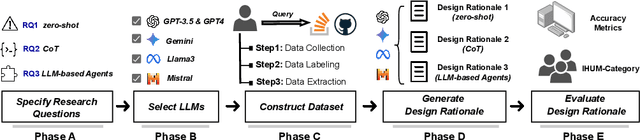
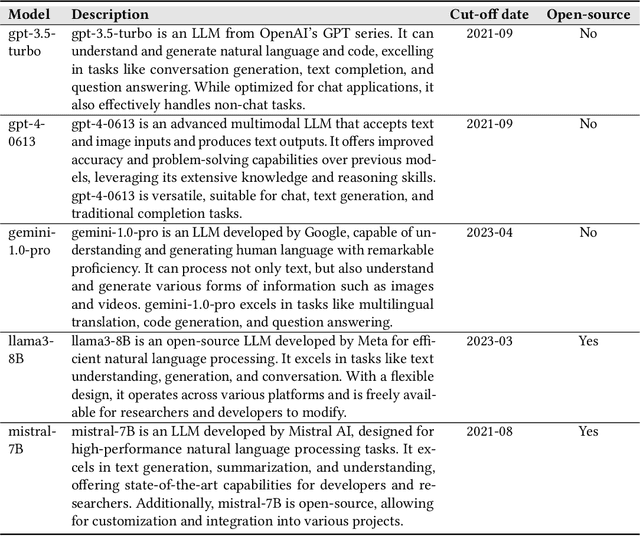
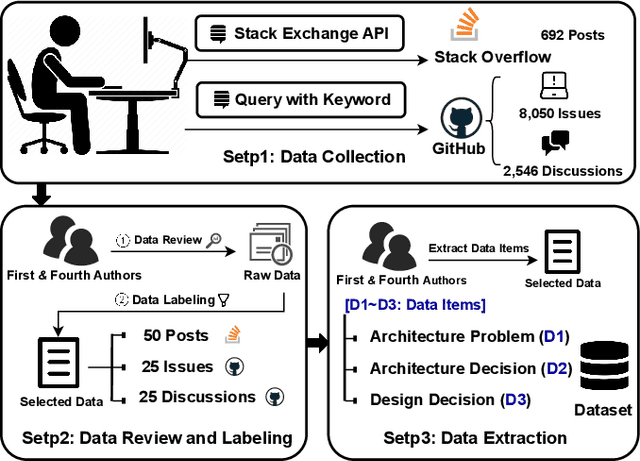
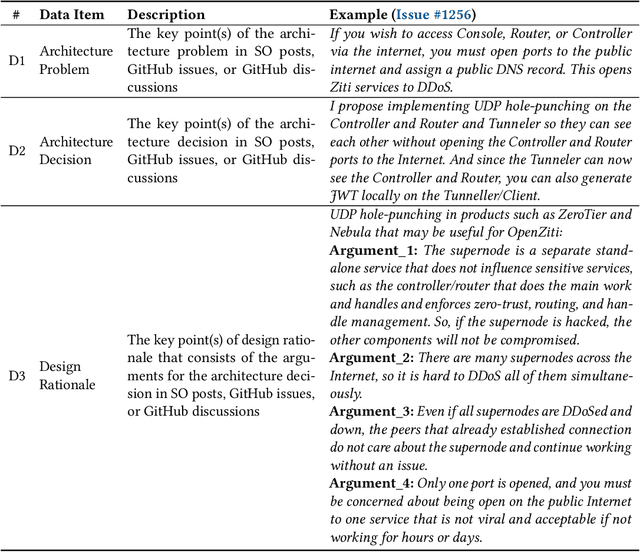
Design Rationale (DR) for software architecture decisions refers to the reasoning underlying architectural choices, which provides valuable insights into the different phases of the architecting process throughout software development. However, in practice, DR is often inadequately documented due to a lack of motivation and effort from developers. With the recent advancements in Large Language Models (LLMs), their capabilities in text comprehension, reasoning, and generation may enable the generation and recovery of DR for architecture decisions. In this study, we evaluated the performance of LLMs in generating DR for architecture decisions. First, we collected 50 Stack Overflow (SO) posts, 25 GitHub issues, and 25 GitHub discussions related to architecture decisions to construct a dataset of 100 architecture-related problems. Then, we selected five LLMs to generate DR for the architecture decisions with three prompting strategies, including zero-shot, chain of thought (CoT), and LLM-based agents. With the DR provided by human experts as ground truth, the Precision of LLM-generated DR with the three prompting strategies ranges from 0.267 to 0.278, Recall from 0.627 to 0.715, and F1-score from 0.351 to 0.389. Additionally, 64.45% to 69.42% of the arguments of DR not mentioned by human experts are also helpful, 4.12% to 4.87% of the arguments have uncertain correctness, and 1.59% to 3.24% of the arguments are potentially misleading. Based on the results, we further discussed the pros and cons of the three prompting strategies and the strengths and limitations of the DR generated by LLMs.
Demystifying Issues, Causes and Solutions in LLM Open-Source Projects
Sep 25, 2024With the advancements of Large Language Models (LLMs), an increasing number of open-source software projects are using LLMs as their core functional component. Although research and practice on LLMs are capturing considerable interest, no dedicated studies explored the challenges faced by practitioners of LLM open-source projects, the causes of these challenges, and potential solutions. To fill this research gap, we conducted an empirical study to understand the issues that practitioners encounter when developing and using LLM open-source software, the possible causes of these issues, and potential solutions.We collected all closed issues from 15 LLM open-source projects and labelled issues that met our requirements. We then randomly selected 994 issues from the labelled issues as the sample for data extraction and analysis to understand the prevalent issues, their underlying causes, and potential solutions. Our study results show that (1) Model Issue is the most common issue faced by practitioners, (2) Model Problem, Configuration and Connection Problem, and Feature and Method Problem are identified as the most frequent causes of the issues, and (3) Optimize Model is the predominant solution to the issues. Based on the study results, we provide implications for practitioners and researchers of LLM open-source projects.
Security Code Review by LLMs: A Deep Dive into Responses
Jan 29, 2024Security code review aims to combine automated tools and manual efforts to detect security defects during development. The rapid development of Large Language Models (LLMs) has shown promising potential in software development, as well as opening up new possibilities in automated security code review. To explore the challenges of applying LLMs in practical code review for security defect detection, this study compared the detection performance of three state-of-the-art LLMs (Gemini Pro, GPT-4, and GPT-3.5) under five prompts on 549 code files that contain security defects from real-world code reviews. Through analyzing 82 responses generated by the best-performing LLM-prompt combination based on 100 randomly selected code files, we extracted and categorized quality problems present in these responses into 5 themes and 16 categories. Our results indicate that the responses produced by LLMs often suffer from verbosity, vagueness, and incompleteness, highlighting the necessity to enhance their conciseness, understandability, and compliance to security defect detection. This work reveals the deficiencies of LLM-generated responses in security code review and paves the way for future optimization of LLMs towards this task.
A Study of Fairness Concerns in AI-based Mobile App Reviews
Jan 16, 2024



With the growing application of AI-based systems in our lives and society, there is a rising need to ensure that AI-based systems are developed and used in a responsible way. Fairness is one of the socio-technical concerns that must be addressed in AI-based systems for this purpose. Unfair AI-based systems, particularly, unfair AI-based mobile apps, can pose difficulties for a significant proportion of the global populace. This paper aims to deeply analyze fairness concerns in AI-based app reviews. We first manually constructed a ground-truth dataset including a statistical sample of fairness and non-fairness reviews. Leveraging the ground-truth dataset, we then developed and evaluated a set of machine learning and deep learning classifiers that distinguish fairness reviews from non-fairness reviews. Our experiments show that our best-performing classifier can detect fairness reviews with a precision of 94%. We then applied the best-performing classifier on approximately 9.5M reviews collected from 108 AI-based apps and identified around 92K fairness reviews. While the fairness reviews appear in 23 app categories, we found that the 'communication' and 'social' app categories have the highest percentage of fairness reviews. Next, applying the K-means clustering technique to the 92K fairness reviews, followed by manual analysis, led to the identification of six distinct types of fairness concerns (e.g., 'receiving different quality of features and services in different platforms and devices' and 'lack of transparency and fairness in dealing with user-generated content'). Finally, the manual analysis of 2,248 app owners' responses to the fairness reviews identified six root causes (e.g., 'copyright issues', 'external factors', 'development cost') that app owners report to justify fairness concerns.