 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Requirements and Architecture: Multi-Agent Orchestration with External Knowledge and Hierarchical Memory
May 31, 2026Software architecture design is a critical yet inherently complex and knowledge-intensive phase that requires balancing competing quality attributes and adapting to evolving requirements. Traditionally, this process has been time-consuming, labor-intensive, and heavily reliant on architects, often resulting in limited exploration of alternative architectural decompositions and styles, especially under the pressures of agile development. While LLM-based agents have shown promising performance across various software engineering tasks, their application to architecture design remains relatively scarce and requires systematic exploration. To address these challenges, we proposed MAAD (Multi-Agent Architecture Design), a knowledge-driven framework that orchestrates four specialized agents (i.e., Analyst, Modeler, Designer and Evaluator) to autonomously and collaboratively transform requirements specifications into comprehensive, multi-view architectural blueprints with quality attribute assessments. MAAD incorporates RAG to inject recognized architectural standards and patterns into the workflow and leverages a hierarchical memory mechanism that captures design history for iterative refinement. We evaluated MAAD through comparative experiments against MetaGPT, using quantitative architecture-level metrics across 10 case studies and qualitative feedback from industry architects on 10 real-world specifications. Results show that MAAD generates more complete, modular, and traceable architectures than the baseline, and its dedicated Evaluator agent autonomously produces structured quality evaluation reports that significantly reduce manual validation efforts. Furthermore, we found that the quality of the generated architecture heavily depends on the underlying LLM's reasoning capacity, with GPT-5.2 and Qwen3.5 outperforming other models across most evaluation settings.
Beyond Functional Correctness: Design Issues in AI IDE-Generated Large-Scale Projects
Apr 07, 2026New generation of AI coding tools, including AI-powered IDEs equipped with agentic capabilities, can generate code within the context of the project. These AI IDEs are increasingly perceived as capable of producing project-level code at scale. However, there is limited empirical evidence on the extent to which they can generate large-scale software systems and what design issues such systems may exhibit. To address this gap, we conducted a study to explore the capability of Cursor in generating large-scale projects and to evaluate the design quality of projects generated by Cursor. First, we propose a Feature-Driven Human-In-The-Loop (FD-HITL) framework that systematically guides project generation from curated project descriptions. We generated 10 projects using Cursor with the FD-HITL framework across three application domains and multiple technologies. We assessed the functional correctness of these projects through manual evaluation, obtaining an average functional correctness score of 91%. Next, we analyzed the generated projects using two static analysis tools, CodeScene and SonarQube, to detect design issues. We identified 1,305 design issues categorized into 9 categories by CodeScene and 3,193 issues in 11 categories by SonarQube. Our findings show that (1) when used with the FD-HITL framework, Cursor can generate functional large-scale projects averaging 16,965 LoC and 114 files; (2) the generated projects nevertheless contain design issues that may pose long-term maintainability and evolvability risks, requiring careful review by experienced developers; (3) the most prevalent issues include Code Duplication, high Code Complexity, Large Methods, Framework Best-Practice Violations, Exception-Handling Issues and Accessibility Issues; (4) these design issues violate design principles such as SRP, SoC, and DRY. The replication package is at https://github.com/Kashifraz/DIinAGP
FasterPy: An LLM-based Code Execution Efficiency Optimization Framework
Dec 28, 2025Code often suffers from performance bugs. These bugs necessitate the research and practice of code optimization. Traditional rule-based methods rely on manually designing and maintaining rules for specific performance bugs (e.g., redundant loops, repeated computations), making them labor-intensive and limited in applicability. In recent years, machine learning and deep learning-based methods have emerged as promising alternatives by learning optimization heuristics from annotated code corpora and performance measurements. However, these approaches usually depend on specific program representations and meticulously crafted training datasets, making them costly to develop and difficult to scale. With the booming of Large Language Models (LLMs), their remarkable capabilities in code generation have opened new avenues for automated code optimization. In this work, we proposed FasterPy, a low-cost and efficient framework that adapts LLMs to optimize the execution efficiency of Python code. FasterPy combines Retrieval-Augmented Generation (RAG), supported by a knowledge base constructed from existing performance-improving code pairs and corresponding performance measurements, with Low-Rank Adaptation (LoRA) to enhance code optimization performance. Our experimental results on the Performance Improving Code Edits (PIE) benchmark demonstrate that our method outperforms existing models on multiple metrics. The FasterPy tool and the experimental results are available at https://github.com/WuYue22/fasterpy.
ParaDySe: A Parallel-Strategy Switching Framework for Dynamic Sequence Lengths in Transformer
Nov 17, 2025Dynamic sequences with varying lengths have been widely used in the training of Transformer-based large language models (LLMs). However, current training frameworks adopt a pre-defined static parallel strategy for these sequences, causing neither communication-parallelization cancellation on short sequences nor out-of-memory on long sequences. To mitigate these issues, we propose ParaDySe, a novel adaptive Parallel strategy switching framework for Dynamic Sequences. ParaDySe enables on-the-fly optimal strategy adoption according to the immediate input sequence. It first implements the modular function libraries for parallel strategies with unified tensor layout specifications, and then builds sequence-aware memory and time cost models with hybrid methods. Guided by cost models, ParaDySe selects optimal layer-wise strategies for dynamic sequences via an efficient heuristic algorithm. By integrating these techniques together, ParaDySe achieves seamless hot-switching of optimal strategies through its well-designed function libraries. We compare ParaDySe with baselines on representative LLMs under datasets with sequence lengths up to 624K. Experimental results indicate that ParaDySe addresses OOM and CPC bottlenecks in LLM training by systematically integrating long-sequence optimizations with existing frameworks.
Designing LLM-based Multi-Agent Systems for Software Engineering Tasks: Quality Attributes, Design Patterns and Rationale
Nov 11, 2025As the complexity of Software Engineering (SE) tasks continues to escalate, Multi-Agent Systems (MASs) have emerged as a focal point of research and practice due to their autonomy and scalability. Furthermore, through leveraging the reasoning and planning capabilities of Large Language Models (LLMs), the application of LLM-based MASs in the field of SE is garnering increasing attention. However, there is no dedicated study that systematically explores the design of LLM-based MASs, including the Quality Attributes (QAs) on which the designers mainly focus, the design patterns used by the designers, and the rationale guiding the design of LLM-based MASs for SE tasks. To this end, we conducted a study to identify the QAs that LLM-based MASs for SE tasks focus on, the design patterns used in the MASs, and the design rationale for the MASs. We collected 94 papers on LLM-based MASs for SE tasks as the source. Our study shows that: (1) Code Generation is the most common SE task solved by LLM-based MASs among ten identified SE tasks, (2) Functional Suitability is the QA on which designers of LLM-based MASs pay the most attention, (3) Role-Based Cooperation is the design pattern most frequently employed among 16 patterns used to construct LLM-based MASs, and (4) Improving the Quality of Generated Code is the most common rationale behind the design of LLM-based MASs. Based on the study results, we presented the implications for the design of LLM-based MASs to support SE tasks.
Fine-Tuning Code Language Models to Detect Cross-Language Bugs
Jul 29, 2025Multilingual programming, which involves using multiple programming languages (PLs) in a single project, is increasingly common due to its benefits. However, it introduces cross-language bugs (CLBs), which arise from interactions between different PLs and are difficult to detect by single-language bug detection tools. This paper investigates the potential of pre-trained code language models (CodeLMs) in CLB detection. We developed CLCFinder, a cross-language code identification tool, and constructed a CLB dataset involving three PL combinations (Python-C/C++, Java-C/C++, and Python-Java) with nine interaction types. We fine-tuned 13 CodeLMs on this dataset and evaluated their performance, analyzing the effects of dataset size, token sequence length, and code comments. Results show that all CodeLMs performed poorly before fine-tuning, but exhibited varying degrees of performance improvement after fine-tuning, with UniXcoder-base achieving the best F1 score (0.7407). Notably, small fine-tuned CodeLMs tended to performe better than large ones. CodeLMs fine-tuned on single-language bug datasets performed poorly on CLB detection, demonstrating the distinction between CLBs and single-language bugs. Additionally, increasing the fine-tuning dataset size significantly improved performance, while longer token sequences did not necessarily improve the model performance. The impact of code comments varied across models. Some fine-tuned CodeLMs' performance was improved, while others showed degraded performance.
Using LLMs in Generating Design Rationale for Software Architecture Decisions
Apr 29, 2025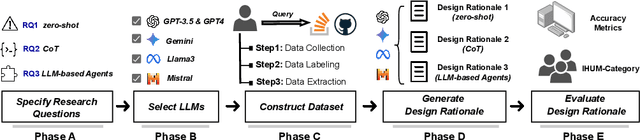
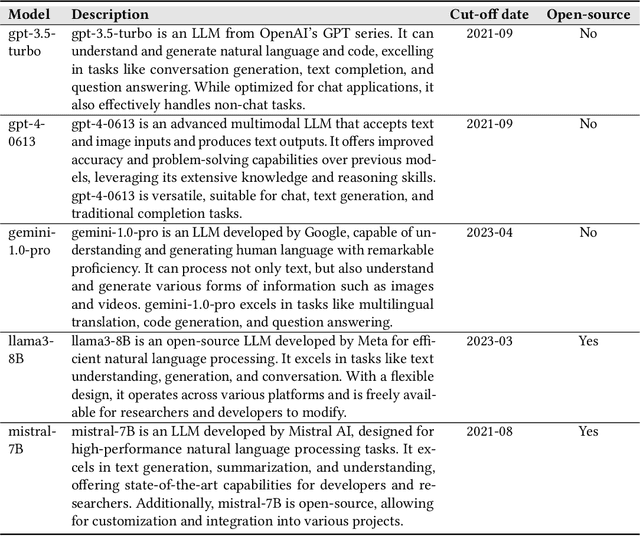
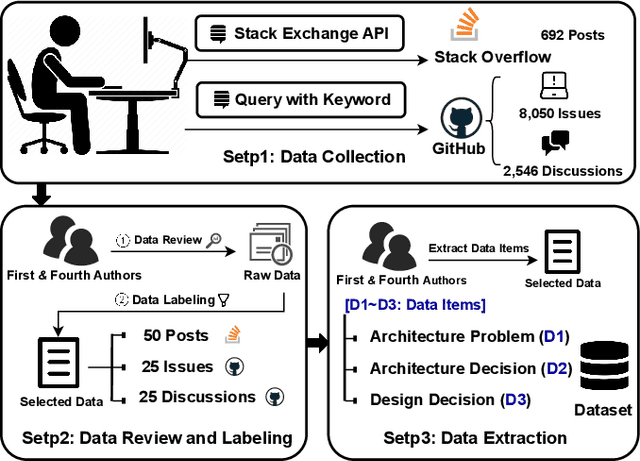
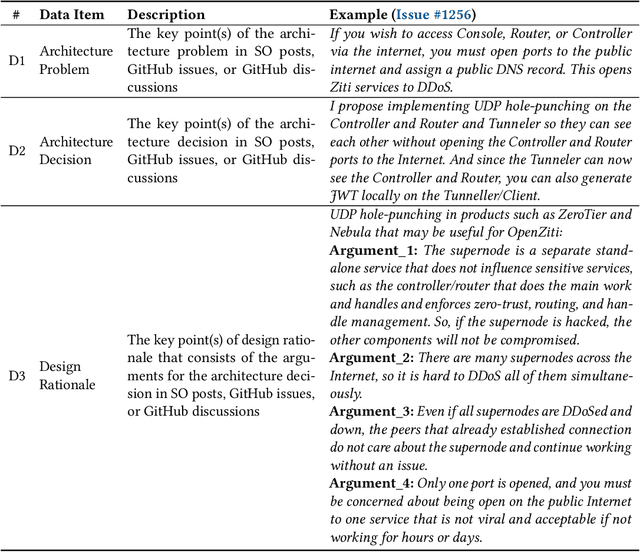
Design Rationale (DR) for software architecture decisions refers to the reasoning underlying architectural choices, which provides valuable insights into the different phases of the architecting process throughout software development. However, in practice, DR is often inadequately documented due to a lack of motivation and effort from developers. With the recent advancements in Large Language Models (LLMs), their capabilities in text comprehension, reasoning, and generation may enable the generation and recovery of DR for architecture decisions. In this study, we evaluated the performance of LLMs in generating DR for architecture decisions. First, we collected 50 Stack Overflow (SO) posts, 25 GitHub issues, and 25 GitHub discussions related to architecture decisions to construct a dataset of 100 architecture-related problems. Then, we selected five LLMs to generate DR for the architecture decisions with three prompting strategies, including zero-shot, chain of thought (CoT), and LLM-based agents. With the DR provided by human experts as ground truth, the Precision of LLM-generated DR with the three prompting strategies ranges from 0.267 to 0.278, Recall from 0.627 to 0.715, and F1-score from 0.351 to 0.389. Additionally, 64.45% to 69.42% of the arguments of DR not mentioned by human experts are also helpful, 4.12% to 4.87% of the arguments have uncertain correctness, and 1.59% to 3.24% of the arguments are potentially misleading. Based on the results, we further discussed the pros and cons of the three prompting strategies and the strengths and limitations of the DR generated by LLMs.
On Developers' Self-Declaration of AI-Generated Code: An Analysis of Practices
Apr 23, 2025AI code generation tools have gained significant popularity among developers, who use them to assist in software development due to their capability to generate code. Existing studies mainly explored the quality, e.g., correctness and security, of AI-generated code, while in real-world software development, the prerequisite is to distinguish AI-generated code from human-written code, which emphasizes the need to explicitly declare AI-generated code by developers. To this end, this study intends to understand the ways developers use to self-declare AI-generated code and explore the reasons why developers choose to self-declare or not. We conducted a mixed-methods study consisting of two phases. In the first phase, we mined GitHub repositories and collected 613 instances of AI-generated code snippets. In the second phase, we conducted a follow-up industrial survey, which received 111 valid responses. Our research revealed the practices followed by developers to self-declare AI-generated code. Most practitioners (76.6%) always or sometimes self-declare AI-generated code. In contrast, other practitioners (23.4%) noted that they never self-declare AI-generated code. The reasons for self-declaring AI-generated code include the need to track and monitor the code for future review and debugging, and ethical considerations. The reasons for not self-declaring AI-generated code include extensive modifications to AI-generated code and the developers' perception that self-declaration is an unnecessary activity. We finally provided guidelines for practitioners to self-declare AI-generated code, addressing ethical and code quality concerns.
Integrating Various Software Artifacts for Better LLM-based Bug Localization and Program Repair
Dec 05, 2024



LLMs have garnered considerable attention for their potential to streamline Automated Program Repair (APR). LLM-based approaches can either insert the correct code or directly generate patches when provided with buggy methods. However, most of LLM-based APR methods rely on a single type of software information, without fully leveraging different software artifacts. Despite this, many LLM-based approaches do not explore which specific types of information best assist in APR. Addressing this gap is crucial for advancing LLM-based APR techniques. We propose DEVLoRe to use issue content (description and message) and stack error traces to localize buggy methods, then rely on debug information in buggy methods and issue content and stack error to localize buggy lines and generate plausible patches which can pass all unit tests. The results show that while issue content is particularly effective in assisting LLMs with fault localization and program repair, different types of software artifacts complement each other. By incorporating different artifacts, DEVLoRe successfully locates 49.3% and 47.6% of single and non-single buggy methods and generates 56.0% and 14.5% plausible patches for the Defects4J v2.0 dataset, respectively. This outperforms current state-of-the-art APR methods. The source code and experimental results of this work for replication are available at https://github.com/XYZboom/DEVLoRe.
Knowledge-Guided Prompt Learning for Request Quality Assurance in Public Code Review
Oct 29, 2024



Public Code Review (PCR) is an assistant to the internal code review of the development team, in the form of a public Software Question Answering (SQA) community, to help developers access high-quality and efficient review services. Current methods on PCR mainly focus on the reviewer's perspective, including finding a capable reviewer, predicting comment quality, and recommending/generating review comments. However, it is not well studied that how to satisfy the review necessity requests posted by developers which can increase their visibility, which in turn acts as a prerequisite for better review responses. To this end, we propose a Knowledge-guided Prompt learning for Public Code Review (KP-PCR) to achieve developer-based code review request quality assurance (i.e., predicting request necessity and recommending tags subtask). Specifically, we reformulate the two subtasks via 1) text prompt tuning which converts both of them into a Masked Language Model (MLM) by constructing prompt templates using hard prompt; 2) knowledge and code prefix tuning which introduces external knowledge by soft prompt, and uses data flow diagrams to characterize code snippets. Finally, both of the request necessity prediction and tag recommendation subtasks output predicted results through an answer engineering module. In addition, we further analysis the time complexity of our KP-PCR that has lightweight prefix based the operation of introducing knowledge. Experimental results on the PCR dataset for the period 2011-2023 demonstrate that our KP-PCR outperforms baselines by 8.3%-28.8% in the request necessity prediction and by 0.1%-29.5% in the tag recommendation. The code implementation is released at https://github.com/WUT-IDEA/KP-PCR.