 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Functional Correctness: Design Issues in AI IDE-Generated Large-Scale Projects
Apr 07, 2026New generation of AI coding tools, including AI-powered IDEs equipped with agentic capabilities, can generate code within the context of the project. These AI IDEs are increasingly perceived as capable of producing project-level code at scale. However, there is limited empirical evidence on the extent to which they can generate large-scale software systems and what design issues such systems may exhibit. To address this gap, we conducted a study to explore the capability of Cursor in generating large-scale projects and to evaluate the design quality of projects generated by Cursor. First, we propose a Feature-Driven Human-In-The-Loop (FD-HITL) framework that systematically guides project generation from curated project descriptions. We generated 10 projects using Cursor with the FD-HITL framework across three application domains and multiple technologies. We assessed the functional correctness of these projects through manual evaluation, obtaining an average functional correctness score of 91%. Next, we analyzed the generated projects using two static analysis tools, CodeScene and SonarQube, to detect design issues. We identified 1,305 design issues categorized into 9 categories by CodeScene and 3,193 issues in 11 categories by SonarQube. Our findings show that (1) when used with the FD-HITL framework, Cursor can generate functional large-scale projects averaging 16,965 LoC and 114 files; (2) the generated projects nevertheless contain design issues that may pose long-term maintainability and evolvability risks, requiring careful review by experienced developers; (3) the most prevalent issues include Code Duplication, high Code Complexity, Large Methods, Framework Best-Practice Violations, Exception-Handling Issues and Accessibility Issues; (4) these design issues violate design principles such as SRP, SoC, and DRY. The replication package is at https://github.com/Kashifraz/DIinAGP
FasterPy: An LLM-based Code Execution Efficiency Optimization Framework
Dec 28, 2025Code often suffers from performance bugs. These bugs necessitate the research and practice of code optimization. Traditional rule-based methods rely on manually designing and maintaining rules for specific performance bugs (e.g., redundant loops, repeated computations), making them labor-intensive and limited in applicability. In recent years, machine learning and deep learning-based methods have emerged as promising alternatives by learning optimization heuristics from annotated code corpora and performance measurements. However, these approaches usually depend on specific program representations and meticulously crafted training datasets, making them costly to develop and difficult to scale. With the booming of Large Language Models (LLMs), their remarkable capabilities in code generation have opened new avenues for automated code optimization. In this work, we proposed FasterPy, a low-cost and efficient framework that adapts LLMs to optimize the execution efficiency of Python code. FasterPy combines Retrieval-Augmented Generation (RAG), supported by a knowledge base constructed from existing performance-improving code pairs and corresponding performance measurements, with Low-Rank Adaptation (LoRA) to enhance code optimization performance. Our experimental results on the Performance Improving Code Edits (PIE) benchmark demonstrate that our method outperforms existing models on multiple metrics. The FasterPy tool and the experimental results are available at https://github.com/WuYue22/fasterpy.
Designing LLM-based Multi-Agent Systems for Software Engineering Tasks: Quality Attributes, Design Patterns and Rationale
Nov 11, 2025As the complexity of Software Engineering (SE) tasks continues to escalate, Multi-Agent Systems (MASs) have emerged as a focal point of research and practice due to their autonomy and scalability. Furthermore, through leveraging the reasoning and planning capabilities of Large Language Models (LLMs), the application of LLM-based MASs in the field of SE is garnering increasing attention. However, there is no dedicated study that systematically explores the design of LLM-based MASs, including the Quality Attributes (QAs) on which the designers mainly focus, the design patterns used by the designers, and the rationale guiding the design of LLM-based MASs for SE tasks. To this end, we conducted a study to identify the QAs that LLM-based MASs for SE tasks focus on, the design patterns used in the MASs, and the design rationale for the MASs. We collected 94 papers on LLM-based MASs for SE tasks as the source. Our study shows that: (1) Code Generation is the most common SE task solved by LLM-based MASs among ten identified SE tasks, (2) Functional Suitability is the QA on which designers of LLM-based MASs pay the most attention, (3) Role-Based Cooperation is the design pattern most frequently employed among 16 patterns used to construct LLM-based MASs, and (4) Improving the Quality of Generated Code is the most common rationale behind the design of LLM-based MASs. Based on the study results, we presented the implications for the design of LLM-based MASs to support SE tasks.
Fine-Tuning Code Language Models to Detect Cross-Language Bugs
Jul 29, 2025Multilingual programming, which involves using multiple programming languages (PLs) in a single project, is increasingly common due to its benefits. However, it introduces cross-language bugs (CLBs), which arise from interactions between different PLs and are difficult to detect by single-language bug detection tools. This paper investigates the potential of pre-trained code language models (CodeLMs) in CLB detection. We developed CLCFinder, a cross-language code identification tool, and constructed a CLB dataset involving three PL combinations (Python-C/C++, Java-C/C++, and Python-Java) with nine interaction types. We fine-tuned 13 CodeLMs on this dataset and evaluated their performance, analyzing the effects of dataset size, token sequence length, and code comments. Results show that all CodeLMs performed poorly before fine-tuning, but exhibited varying degrees of performance improvement after fine-tuning, with UniXcoder-base achieving the best F1 score (0.7407). Notably, small fine-tuned CodeLMs tended to performe better than large ones. CodeLMs fine-tuned on single-language bug datasets performed poorly on CLB detection, demonstrating the distinction between CLBs and single-language bugs. Additionally, increasing the fine-tuning dataset size significantly improved performance, while longer token sequences did not necessarily improve the model performance. The impact of code comments varied across models. Some fine-tuned CodeLMs' performance was improved, while others showed degraded performance.
Using LLMs in Generating Design Rationale for Software Architecture Decisions
Apr 29, 2025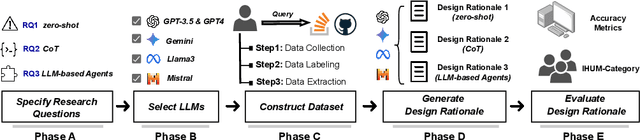
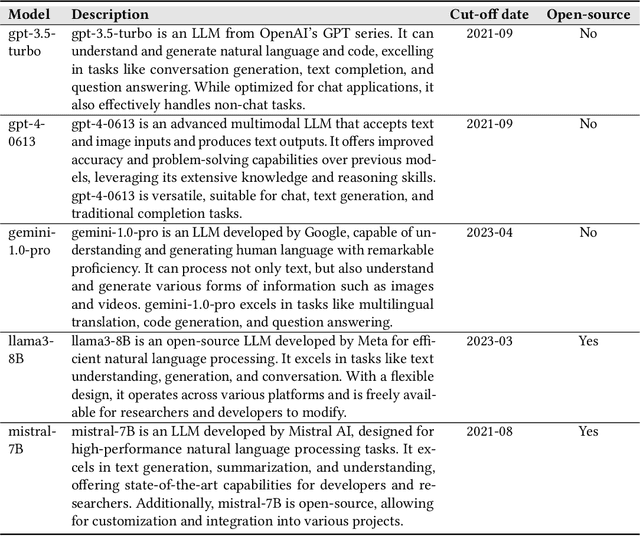
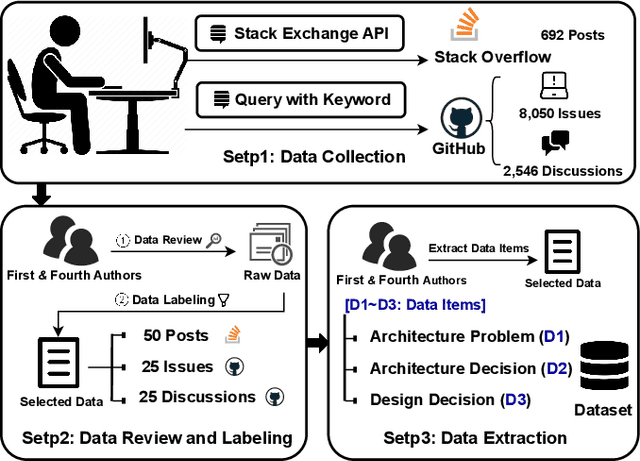
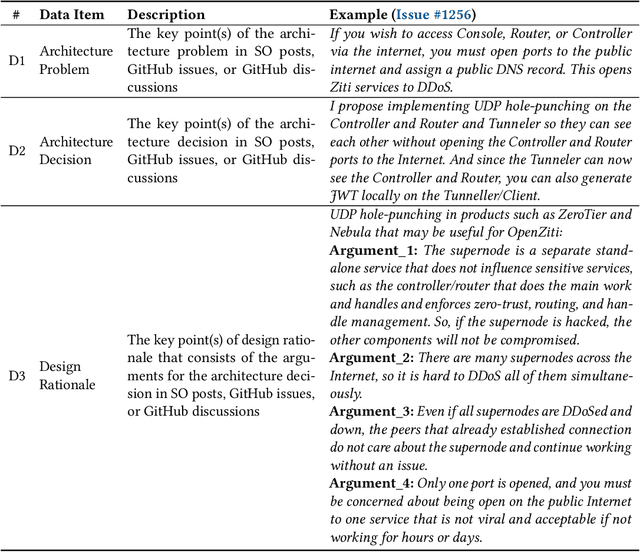
Design Rationale (DR) for software architecture decisions refers to the reasoning underlying architectural choices, which provides valuable insights into the different phases of the architecting process throughout software development. However, in practice, DR is often inadequately documented due to a lack of motivation and effort from developers. With the recent advancements in Large Language Models (LLMs), their capabilities in text comprehension, reasoning, and generation may enable the generation and recovery of DR for architecture decisions. In this study, we evaluated the performance of LLMs in generating DR for architecture decisions. First, we collected 50 Stack Overflow (SO) posts, 25 GitHub issues, and 25 GitHub discussions related to architecture decisions to construct a dataset of 100 architecture-related problems. Then, we selected five LLMs to generate DR for the architecture decisions with three prompting strategies, including zero-shot, chain of thought (CoT), and LLM-based agents. With the DR provided by human experts as ground truth, the Precision of LLM-generated DR with the three prompting strategies ranges from 0.267 to 0.278, Recall from 0.627 to 0.715, and F1-score from 0.351 to 0.389. Additionally, 64.45% to 69.42% of the arguments of DR not mentioned by human experts are also helpful, 4.12% to 4.87% of the arguments have uncertain correctness, and 1.59% to 3.24% of the arguments are potentially misleading. Based on the results, we further discussed the pros and cons of the three prompting strategies and the strengths and limitations of the DR generated by LLMs.
Detection-Friendly Nonuniformity Correction: A Union Framework for Infrared UAVTarget Detection
Apr 05, 2025



Infrared unmanned aerial vehicle (UAV) images captured using thermal detectors are often affected by temperature dependent low-frequency nonuniformity, which significantly reduces the contrast of the images. Detecting UAV targets under nonuniform conditions is crucial in UAV surveillance applications. Existing methods typically treat infrared nonuniformity correction (NUC) as a preprocessing step for detection, which leads to suboptimal performance. Balancing the two tasks while enhancing detection beneficial information remains challenging. In this paper, we present a detection-friendly union framework, termed UniCD, that simultaneously addresses both infrared NUC and UAV target detection tasks in an end-to-end manner. We first model NUC as a small number of parameter estimation problem jointly driven by priors and data to generate detection-conducive images. Then, we incorporate a new auxiliary loss with target mask supervision into the backbone of the infrared UAV target detection network to strengthen target features while suppressing the background. To better balance correction and detection, we introduce a detection-guided self-supervised loss to reduce feature discrepancies between the two tasks, thereby enhancing detection robustness to varying nonuniformity levels. Additionally, we construct a new benchmark composed of 50,000 infrared images in various nonuniformity types, multi-scale UAV targets and rich backgrounds with target annotations, called IRBFD. Extensive experiments on IRBFD demonstrate that our UniCD is a robust union framework for NUC and UAV target detection while achieving real-time processing capabilities. Dataset can be available at https://github.com/IVPLaboratory/UniCD.
Demystifying Issues, Causes and Solutions in LLM Open-Source Projects
Sep 25, 2024With the advancements of Large Language Models (LLMs), an increasing number of open-source software projects are using LLMs as their core functional component. Although research and practice on LLMs are capturing considerable interest, no dedicated studies explored the challenges faced by practitioners of LLM open-source projects, the causes of these challenges, and potential solutions. To fill this research gap, we conducted an empirical study to understand the issues that practitioners encounter when developing and using LLM open-source software, the possible causes of these issues, and potential solutions.We collected all closed issues from 15 LLM open-source projects and labelled issues that met our requirements. We then randomly selected 994 issues from the labelled issues as the sample for data extraction and analysis to understand the prevalent issues, their underlying causes, and potential solutions. Our study results show that (1) Model Issue is the most common issue faced by practitioners, (2) Model Problem, Configuration and Connection Problem, and Feature and Method Problem are identified as the most frequent causes of the issues, and (3) Optimize Model is the predominant solution to the issues. Based on the study results, we provide implications for practitioners and researchers of LLM open-source projects.
Copilot Refinement: Addressing Code Smells in Copilot-Generated Python Code
Jan 25, 2024



As one of the most popular dynamic languages, Python experiences a decrease in readability and maintainability when code smells are present. Recent advancements in Large Language Models have sparked growing interest in AI-enabled tools for both code generation and refactoring. GitHub Copilot is one such tool that has gained widespread usage. Copilot Chat, released on September 2023, functions as an interactive tool aims at facilitating natural language-powered coding. However, limited attention has been given to understanding code smells in Copilot-generated Python code and Copilot's ability to fix the code smells it generates. To this end, we built a dataset comprising 102 code smells in Copilot-generated Python code. Our aim is to first explore the occurrence of code smells in Copilot-generated Python code and then evaluate the effectiveness of Copilot in fixing these code smells employing different prompts. The results show that 8 out of 10 types of Python smells can be detected in Copilot-generated Python code, among which Multiply-Nested Container is the most common one. For these code smells, Copilot Chat achieves a highest fixing rate of 87.1%, showing promise in fixing Python code smells generated by Copilot itself. Besides, the effectiveness of Copilot Chat in fixing these smells can be improved with the provision of more detailed prompts. However, using Copilot Chat to fix these smells might introduce new code smells.
Understanding Bugs in Multi-Language Deep Learning Frameworks
Mar 05, 2023



Deep learning frameworks (DLFs) have been playing an increasingly important role in this intelligence age since they act as a basic infrastructure for an increasingly wide range of AIbased applications. Meanwhile, as multi-programming-language (MPL) software systems, DLFs are inevitably suffering from bugs caused by the use of multiple programming languages (PLs). Hence, it is of paramount significance to understand the bugs (especially the bugs involving multiple PLs, i.e., MPL bugs) of DLFs, which can provide a foundation for preventing, detecting, and resolving bugs in the development of DLFs. To this end, we manually analyzed 1497 bugs in three MPL DLFs, namely MXNet, PyTorch, and TensorFlow. First, we classified bugs in these DLFs into 12 types (e.g., algorithm design bugs and memory bugs) according to their bug labels and characteristics. Second, we further explored the impacts of different bug types on the development of DLFs, and found that deployment bugs and memory bugs negatively impact the development of DLFs in different aspects the most. Third, we found that 28.6%, 31.4%, and 16.0% of bugs in MXNet, PyTorch, and TensorFlow are MPL bugs, respectively; the PL combination of Python and C/C++ is most used in fixing more than 92% MPL bugs in all DLFs. Finally, the code change complexity of MPL bug fixes is significantly greater than that of single-programming-language (SPL) bug fixes in all the three DLFs, while in PyTorch MPL bug fixes have longer open time and greater communication complexity than SPL bug fixes. These results provide insights for bug management in DLFs.