 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeTeam: An LLM-Powered Multi-Agent Framework for Repository-Level Code Generation
Jun 20, 2026Natural language to repository generation (NL2Repo) requires a system to construct an entire software repository from a natural-language requirements document. Compared with function-level code generation, this task demands longer planning horizons, stable interfaces across files, and iterative debugging of cross-file inconsistencies. To address these challenges, we propose CodeTeam, an LLM-based multi-agent framework that separates planning, decision making, and implementation into distinct, coordinated stages. In the planning stage, multiple Architect agents draft competing software design sketches (SDS), optionally grounded by retrieved design references. A CTO agent then evaluates, selects, and normalizes the most promising SDS into a machine-checkable contract that specifies file ownership, public interfaces, and dependency constraints. In the implementation stage, Developer agents generate code under a dependency-aware scheduler with bounded context and lightweight Git-based coordination, while a QA agent runs tests and drives iterative repairs. On the synthesis-based SketchEval benchmark, we explicitly compare CodeTeam's prompt-engineering (PE) and supervised fine-tuning (SFT) variants with the corresponding CodeS variants, where CodeTeam improves the overall SketchBLEU by 4.1 and 2.9 absolute points, respectively. On the execution-based NL2Repo-Bench benchmark, used as an external validation protocol, CodeTeam achieves the highest average test pass rate in both settings (34.6% PE, 42.3% SFT), confirming that the sketch-improvements extend to functional correctness under upstream test suites. Ablation results show that project-specific developer allocation and retrieval-augmented planning each contribute substantially to the SketchBLEU improvement (9.9% and 8.1% relative, respectively). CodeTeam and the experimental results are available at https://github.com/WhitenWhiten/CodeTeam
Rule Taxonomy and Evolution in AI IDEs: A Mining and Survey Study
Jun 10, 2026The adoption of AI-powered Integrated Development Environments (AI IDEs) has introduced "Rules" as a novel software artifact, allowing developers to persistently inject project-specific constraints and architectural guidelines into the context of Large Language Models (LLMs). Despite their role in aligning AI behavior with developer intent, the taxonomy, evolution, and practical impact of these rules remain largely unexplored. To bridge this gap, we conducted a mixed-methods empirical study on AI IDE rules. By mining 83 open-source projects and extracting 7,310 rules, we established a comprehensive taxonomy comprising 5 primary and 25 secondary categories. We then triangulated these artifacts with survey responses from 99 practitioners. Our analysis identified a contrast between developer priorities and actual configurations: while practitioners rate architectural constraints as highly important, rule files in repositories primarily consist of low-level workflow and code formatting constraints. Furthermore, our analysis of 1,540 rule evolution events revealed that rules are updated frequently. Repository data further indicate that rule evolution is primarily driven by constructive context expansions (29.17%) and enrichments (26.59%). In contrast, surveyed developers reported modifying rules primarily to correct AI errors (77.78%), typically by adding new negative constraints rather than editing existing ones. Finally, an artifact compliance assessment of 160 rule evolution events revealed that updating rules significantly improves the adherence of software artifacts, with the average artifact compliance rate increasing by 22.99% (from 49.14% to 72.13%) following an update. Our study provides empirical insights that can help developers optimize prompting strategies and guide tool builders in designing automated conflict-detection and context-management mechanisms for AI IDEs.
Bridging Requirements and Architecture: Multi-Agent Orchestration with External Knowledge and Hierarchical Memory
May 31, 2026Software architecture design is a critical yet inherently complex and knowledge-intensive phase that requires balancing competing quality attributes and adapting to evolving requirements. Traditionally, this process has been time-consuming, labor-intensive, and heavily reliant on architects, often resulting in limited exploration of alternative architectural decompositions and styles, especially under the pressures of agile development. While LLM-based agents have shown promising performance across various software engineering tasks, their application to architecture design remains relatively scarce and requires systematic exploration. To address these challenges, we proposed MAAD (Multi-Agent Architecture Design), a knowledge-driven framework that orchestrates four specialized agents (i.e., Analyst, Modeler, Designer and Evaluator) to autonomously and collaboratively transform requirements specifications into comprehensive, multi-view architectural blueprints with quality attribute assessments. MAAD incorporates RAG to inject recognized architectural standards and patterns into the workflow and leverages a hierarchical memory mechanism that captures design history for iterative refinement. We evaluated MAAD through comparative experiments against MetaGPT, using quantitative architecture-level metrics across 10 case studies and qualitative feedback from industry architects on 10 real-world specifications. Results show that MAAD generates more complete, modular, and traceable architectures than the baseline, and its dedicated Evaluator agent autonomously produces structured quality evaluation reports that significantly reduce manual validation efforts. Furthermore, we found that the quality of the generated architecture heavily depends on the underlying LLM's reasoning capacity, with GPT-5.2 and Qwen3.5 outperforming other models across most evaluation settings.
Beyond Functional Correctness: Design Issues in AI IDE-Generated Large-Scale Projects
Apr 07, 2026New generation of AI coding tools, including AI-powered IDEs equipped with agentic capabilities, can generate code within the context of the project. These AI IDEs are increasingly perceived as capable of producing project-level code at scale. However, there is limited empirical evidence on the extent to which they can generate large-scale software systems and what design issues such systems may exhibit. To address this gap, we conducted a study to explore the capability of Cursor in generating large-scale projects and to evaluate the design quality of projects generated by Cursor. First, we propose a Feature-Driven Human-In-The-Loop (FD-HITL) framework that systematically guides project generation from curated project descriptions. We generated 10 projects using Cursor with the FD-HITL framework across three application domains and multiple technologies. We assessed the functional correctness of these projects through manual evaluation, obtaining an average functional correctness score of 91%. Next, we analyzed the generated projects using two static analysis tools, CodeScene and SonarQube, to detect design issues. We identified 1,305 design issues categorized into 9 categories by CodeScene and 3,193 issues in 11 categories by SonarQube. Our findings show that (1) when used with the FD-HITL framework, Cursor can generate functional large-scale projects averaging 16,965 LoC and 114 files; (2) the generated projects nevertheless contain design issues that may pose long-term maintainability and evolvability risks, requiring careful review by experienced developers; (3) the most prevalent issues include Code Duplication, high Code Complexity, Large Methods, Framework Best-Practice Violations, Exception-Handling Issues and Accessibility Issues; (4) these design issues violate design principles such as SRP, SoC, and DRY. The replication package is at https://github.com/Kashifraz/DIinAGP
FasterPy: An LLM-based Code Execution Efficiency Optimization Framework
Dec 28, 2025Code often suffers from performance bugs. These bugs necessitate the research and practice of code optimization. Traditional rule-based methods rely on manually designing and maintaining rules for specific performance bugs (e.g., redundant loops, repeated computations), making them labor-intensive and limited in applicability. In recent years, machine learning and deep learning-based methods have emerged as promising alternatives by learning optimization heuristics from annotated code corpora and performance measurements. However, these approaches usually depend on specific program representations and meticulously crafted training datasets, making them costly to develop and difficult to scale. With the booming of Large Language Models (LLMs), their remarkable capabilities in code generation have opened new avenues for automated code optimization. In this work, we proposed FasterPy, a low-cost and efficient framework that adapts LLMs to optimize the execution efficiency of Python code. FasterPy combines Retrieval-Augmented Generation (RAG), supported by a knowledge base constructed from existing performance-improving code pairs and corresponding performance measurements, with Low-Rank Adaptation (LoRA) to enhance code optimization performance. Our experimental results on the Performance Improving Code Edits (PIE) benchmark demonstrate that our method outperforms existing models on multiple metrics. The FasterPy tool and the experimental results are available at https://github.com/WuYue22/fasterpy.
Designing LLM-based Multi-Agent Systems for Software Engineering Tasks: Quality Attributes, Design Patterns and Rationale
Nov 11, 2025As the complexity of Software Engineering (SE) tasks continues to escalate, Multi-Agent Systems (MASs) have emerged as a focal point of research and practice due to their autonomy and scalability. Furthermore, through leveraging the reasoning and planning capabilities of Large Language Models (LLMs), the application of LLM-based MASs in the field of SE is garnering increasing attention. However, there is no dedicated study that systematically explores the design of LLM-based MASs, including the Quality Attributes (QAs) on which the designers mainly focus, the design patterns used by the designers, and the rationale guiding the design of LLM-based MASs for SE tasks. To this end, we conducted a study to identify the QAs that LLM-based MASs for SE tasks focus on, the design patterns used in the MASs, and the design rationale for the MASs. We collected 94 papers on LLM-based MASs for SE tasks as the source. Our study shows that: (1) Code Generation is the most common SE task solved by LLM-based MASs among ten identified SE tasks, (2) Functional Suitability is the QA on which designers of LLM-based MASs pay the most attention, (3) Role-Based Cooperation is the design pattern most frequently employed among 16 patterns used to construct LLM-based MASs, and (4) Improving the Quality of Generated Code is the most common rationale behind the design of LLM-based MASs. Based on the study results, we presented the implications for the design of LLM-based MASs to support SE tasks.
Using LLMs in Generating Design Rationale for Software Architecture Decisions
Apr 29, 2025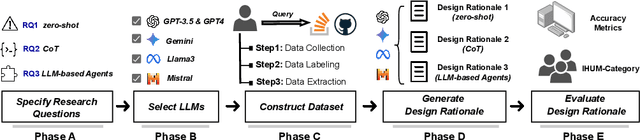
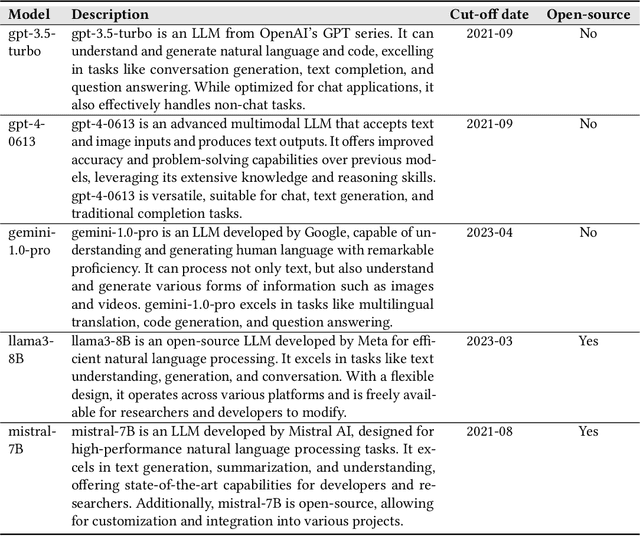
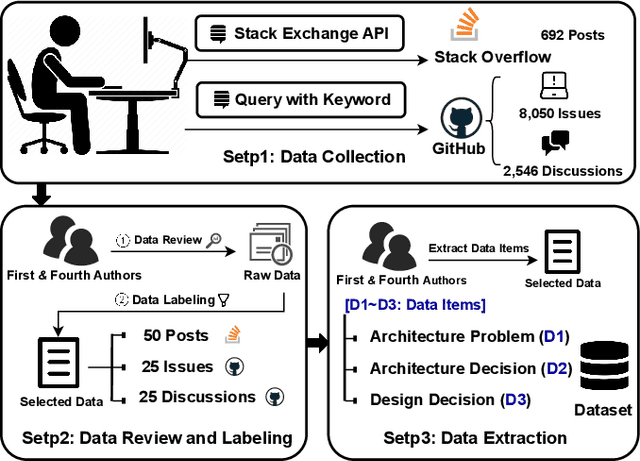
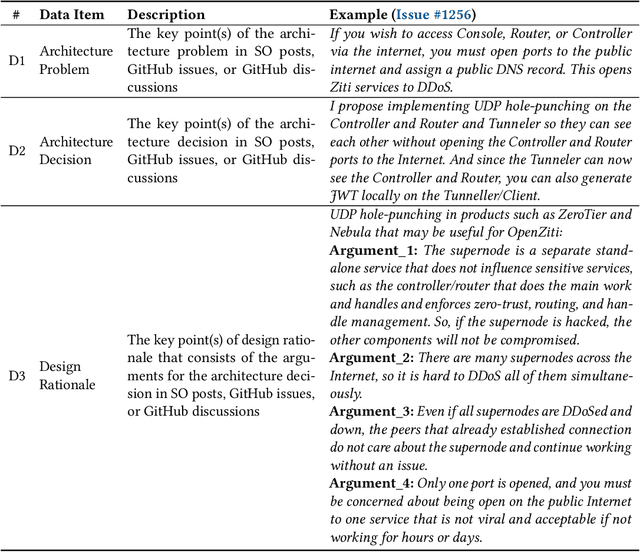
Design Rationale (DR) for software architecture decisions refers to the reasoning underlying architectural choices, which provides valuable insights into the different phases of the architecting process throughout software development. However, in practice, DR is often inadequately documented due to a lack of motivation and effort from developers. With the recent advancements in Large Language Models (LLMs), their capabilities in text comprehension, reasoning, and generation may enable the generation and recovery of DR for architecture decisions. In this study, we evaluated the performance of LLMs in generating DR for architecture decisions. First, we collected 50 Stack Overflow (SO) posts, 25 GitHub issues, and 25 GitHub discussions related to architecture decisions to construct a dataset of 100 architecture-related problems. Then, we selected five LLMs to generate DR for the architecture decisions with three prompting strategies, including zero-shot, chain of thought (CoT), and LLM-based agents. With the DR provided by human experts as ground truth, the Precision of LLM-generated DR with the three prompting strategies ranges from 0.267 to 0.278, Recall from 0.627 to 0.715, and F1-score from 0.351 to 0.389. Additionally, 64.45% to 69.42% of the arguments of DR not mentioned by human experts are also helpful, 4.12% to 4.87% of the arguments have uncertain correctness, and 1.59% to 3.24% of the arguments are potentially misleading. Based on the results, we further discussed the pros and cons of the three prompting strategies and the strengths and limitations of the DR generated by LLMs.