 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWarmServe: Enabling One-for-Many GPU Prewarming for Multi-LLM Serving
Dec 10, 2025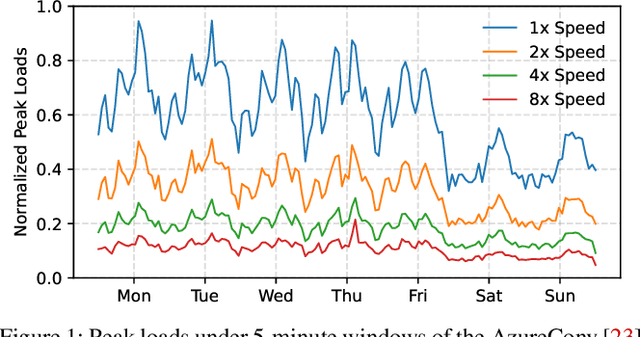
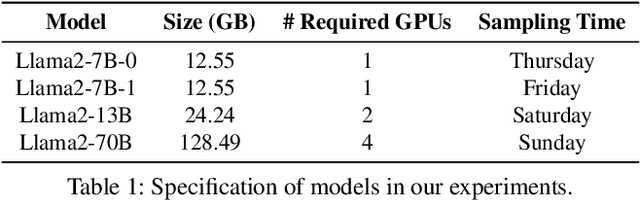
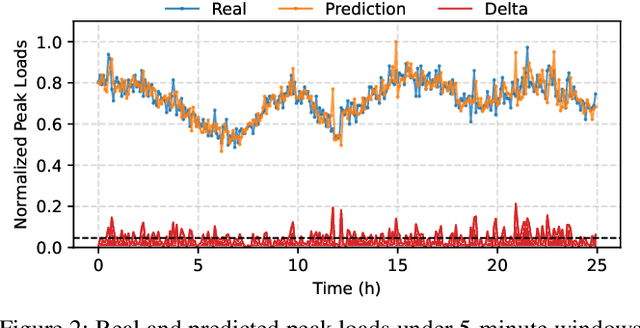
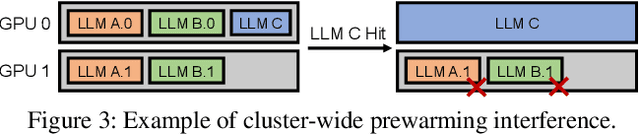
Deploying multiple models within shared GPU clusters is promising for improving resource efficiency in large language model (LLM) serving. Existing multi-LLM serving systems optimize GPU utilization at the cost of worse inference performance, especially time-to-first-token (TTFT). We identify the root cause of such compromise as their unawareness of future workload characteristics. In contrast, recent analysis on real-world traces has shown the high periodicity and long-term predictability of LLM serving workloads. We propose universal GPU workers to enable one-for-many GPU prewarming that loads models with knowledge of future workloads. Based on universal GPU workers, we design and build WarmServe, a multi-LLM serving system that (1) mitigates cluster-wide prewarming interference by adopting an evict-aware model placement strategy, (2) prepares universal GPU workers in advance by proactive prewarming, and (3) manages GPU memory with a zero-overhead memory switching mechanism. Evaluation under real-world datasets shows that WarmServe improves TTFT by up to 50.8$\times$ compared to the state-of-the-art autoscaling-based system, while being capable of serving up to 2.5$\times$ more requests compared to the GPU-sharing system.
Pose-Aware Multi-Level Motion Parsing for Action Quality Assessment
Nov 06, 2025Human pose serves as a cornerstone of action quality assessment (AQA), where subtle spatial-temporal variations in pose often distinguish excellence from mediocrity. In high-level competitions, these nuanced differences become decisive factors in scoring. In this paper, we propose a novel multi-level motion parsing framework for AQA based on enhanced spatial-temporal pose features. On the first level, the Action-Unit Parser is designed with the help of pose extraction to achieve precise action segmentation and comprehensive local-global pose representations. On the second level, Motion Parser is used by spatial-temporal feature learning to capture pose changes and appearance details for each action-unit. Meanwhile, some special conditions other than body-related will impact action scoring, like water splash in diving. In this work, we design an additional Condition Parser to offer users more flexibility in their choices. Finally, Weight-Adjust Scoring Module is introduced to better accommodate the diverse requirements of various action types and the multi-scale nature of action-units. Extensive evaluations on large-scale diving sports datasets demonstrate that our multi-level motion parsing framework achieves state-of-the-art performance in both action segmentation and action scoring tasks.
What is an "Abstract Reasoner"? Revisiting Experiments and Arguments about Large Language Models
Jul 30, 2025



Recent work has argued that large language models (LLMs) are not "abstract reasoners", citing their poor zero-shot performance on a variety of challenging tasks as evidence. We revisit these experiments in order to add nuance to the claim. First, we show that while LLMs indeed perform poorly in a zero-shot setting, even tuning a small subset of parameters for input encoding can enable near-perfect performance. However, we also show that this finetuning does not necessarily transfer across datasets. We take this collection of empirical results as an invitation to (re-)open the discussion of what it means to be an "abstract reasoner", and why it matters whether LLMs fit the bill.
CoInfra: A Large-Scale Cooperative Infrastructure Perception System and Dataset in Adverse Weather
Jul 03, 2025We present CoInfra, a large-scale cooperative infrastructure perception system and dataset designed to advance robust multi-agent perception under real-world and adverse weather conditions. The CoInfra system includes 14 fully synchronized sensor nodes, each equipped with dual RGB cameras and a LiDAR, deployed across a shared region and operating continuously to capture all traffic participants in real-time. A robust, delay-aware synchronization protocol and a scalable system architecture that supports real-time data fusion, OTA management, and remote monitoring are provided in this paper. On the other hand, the dataset was collected in different weather scenarios, including sunny, rainy, freezing rain, and heavy snow and includes 195k LiDAR frames and 390k camera images from 8 infrastructure nodes that are globally time-aligned and spatially calibrated. Furthermore, comprehensive 3D bounding box annotations for five object classes (i.e., car, bus, truck, person, and bicycle) are provided in both global and individual node frames, along with high-definition maps for contextual understanding. Baseline experiments demonstrate the trade-offs between early and late fusion strategies, the significant benefits of HD map integration are discussed. By openly releasing our dataset, codebase, and system documentation at https://github.com/NingMingHao/CoInfra, we aim to enable reproducible research and drive progress in infrastructure-supported autonomous driving, particularly in challenging, real-world settings.
DiffMark: Diffusion-based Robust Watermark Against Deepfakes
Jul 02, 2025Deepfakes pose significant security and privacy threats through malicious facial manipulations. While robust watermarking can aid in authenticity verification and source tracking, existing methods often lack the sufficient robustness against Deepfake manipulations. Diffusion models have demonstrated remarkable performance in image generation, enabling the seamless fusion of watermark with image during generation. In this study, we propose a novel robust watermarking framework based on diffusion model, called DiffMark. By modifying the training and sampling scheme, we take the facial image and watermark as conditions to guide the diffusion model to progressively denoise and generate corresponding watermarked image. In the construction of facial condition, we weight the facial image by a timestep-dependent factor that gradually reduces the guidance intensity with the decrease of noise, thus better adapting to the sampling process of diffusion model. To achieve the fusion of watermark condition, we introduce a cross information fusion (CIF) module that leverages a learnable embedding table to adaptively extract watermark features and integrates them with image features via cross-attention. To enhance the robustness of the watermark against Deepfake manipulations, we integrate a frozen autoencoder during training phase to simulate Deepfake manipulations. Additionally, we introduce Deepfake-resistant guidance that employs specific Deepfake model to adversarially guide the diffusion sampling process to generate more robust watermarked images. Experimental results demonstrate the effectiveness of the proposed DiffMark on typical Deepfakes. Our code will be available at https://github.com/vpsg-research/DiffMark.
xbench: Tracking Agents Productivity Scaling with Profession-Aligned Real-World Evaluations
Jun 16, 2025


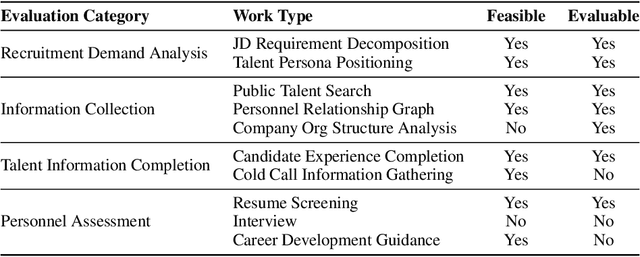
We introduce xbench, a dynamic, profession-aligned evaluation suite designed to bridge the gap between AI agent capabilities and real-world productivity. While existing benchmarks often focus on isolated technical skills, they may not accurately reflect the economic value agents deliver in professional settings. To address this, xbench targets commercially significant domains with evaluation tasks defined by industry professionals. Our framework creates metrics that strongly correlate with productivity value, enables prediction of Technology-Market Fit (TMF), and facilitates tracking of product capabilities over time. As our initial implementations, we present two benchmarks: Recruitment and Marketing. For Recruitment, we collect 50 tasks from real-world headhunting business scenarios to evaluate agents' abilities in company mapping, information retrieval, and talent sourcing. For Marketing, we assess agents' ability to match influencers with advertiser needs, evaluating their performance across 50 advertiser requirements using a curated pool of 836 candidate influencers. We present initial evaluation results for leading contemporary agents, establishing a baseline for these professional domains. Our continuously updated evalsets and evaluations are available at https://xbench.org.
Generalizable Trajectory Prediction via Inverse Reinforcement Learning with Mamba-Graph Architecture
Jun 14, 2025Accurate driving behavior modeling is fundamental to safe and efficient trajectory prediction, yet remains challenging in complex traffic scenarios. This paper presents a novel Inverse Reinforcement Learning (IRL) framework that captures human-like decision-making by inferring diverse reward functions, enabling robust cross-scenario adaptability. The learned reward function is utilized to maximize the likelihood of output by the encoder-decoder architecture that combines Mamba blocks for efficient long-sequence dependency modeling with graph attention networks to encode spatial interactions among traffic agents. Comprehensive evaluations on urban intersections and roundabouts demonstrate that the proposed method not only outperforms various popular approaches in prediction accuracy but also achieves 2 times higher generalization performance to unseen scenarios compared to other IRL-based method.
MS4UI: A Dataset for Multi-modal Summarization of User Interface Instructional Videos
Jun 14, 2025We study multi-modal summarization for instructional videos, whose goal is to provide users an efficient way to learn skills in the form of text instructions and key video frames. We observe that existing benchmarks focus on generic semantic-level video summarization, and are not suitable for providing step-by-step executable instructions and illustrations, both of which are crucial for instructional videos. We propose a novel benchmark for user interface (UI) instructional video summarization to fill the gap. We collect a dataset of 2,413 UI instructional videos, which spans over 167 hours. These videos are manually annotated for video segmentation, text summarization, and video summarization, which enable the comprehensive evaluations for concise and executable video summarization. We conduct extensive experiments on our collected MS4UI dataset, which suggest that state-of-the-art multi-modal summarization methods struggle on UI video summarization, and highlight the importance of new methods for UI instructional video summarization.
Self-Adapting Improvement Loops for Robotic Learning
Jun 07, 2025



Video generative models trained on expert demonstrations have been utilized as performant text-conditioned visual planners for solving robotic tasks. However, generalization to unseen tasks remains a challenge. Whereas improved generalization may be facilitated by leveraging learned prior knowledge from additional pre-collected offline data sources, such as web-scale video datasets, in the era of experience we aim to design agents that can continuously improve in an online manner from self-collected behaviors. In this work we thus propose the Self-Adapting Improvement Loop (SAIL), where an in-domain video model iteratively updates itself on self-produced trajectories, collected through adaptation with an internet-scale pretrained video model, and steadily improves its performance for a specified task of interest. We apply SAIL to a diverse suite of MetaWorld tasks, as well as two manipulation tasks on a real robot arm, and find that performance improvements continuously emerge over multiple iterations for novel tasks initially unseen during original in-domain video model training. Furthermore, we discover that SAIL is surprisingly robust regarding if and how the self-collected experience is filtered, and the quality of the initial in-domain demonstrations. Through adaptation with summarized internet-scale data, and learning through online experience, we thus demonstrate a way to iteratively bootstrap a high-performance video model for solving novel robotic tasks through self-improvement.
Force Prompting: Video Generation Models Can Learn and Generalize Physics-based Control Signals
May 26, 2025



Recent advances in video generation models have sparked interest in world models capable of simulating realistic environments. While navigation has been well-explored, physically meaningful interactions that mimic real-world forces remain largely understudied. In this work, we investigate using physical forces as a control signal for video generation and propose force prompts which enable users to interact with images through both localized point forces, such as poking a plant, and global wind force fields, such as wind blowing on fabric. We demonstrate that these force prompts can enable videos to respond realistically to physical control signals by leveraging the visual and motion prior in the original pretrained model, without using any 3D asset or physics simulator at inference. The primary challenge of force prompting is the difficulty in obtaining high quality paired force-video training data, both in the real world due to the difficulty of obtaining force signals, and in synthetic data due to limitations in the visual quality and domain diversity of physics simulators. Our key finding is that video generation models can generalize remarkably well when adapted to follow physical force conditioning from videos synthesized by Blender, even with limited demonstrations of few objects. Our method can generate videos which simulate forces across diverse geometries, settings, and materials. We also try to understand the source of this generalization and perform ablations that reveal two key elements: visual diversity and the use of specific text keywords during training. Our approach is trained on only around 15k training examples for a single day on four A100 GPUs, and outperforms existing methods on force adherence and physics realism, bringing world models closer to real-world physics interactions. We release all datasets, code, weights, and interactive video demos at our project page.