 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViVa: A Video-Generative Value Model for Robot Reinforcement Learning
Apr 09, 2026Vision-language-action (VLA) models have advanced robot manipulation through large-scale pretraining, but real-world deployment remains challenging due to partial observability and delayed feedback. Reinforcement learning addresses this via value functions, which assess task progress and guide policy improvement. However, existing value models built on vision-language models (VLMs) struggle to capture temporal dynamics, undermining reliable value estimation in long-horizon tasks. In this paper, we propose ViVa, a video-generative value model that repurposes a pretrained video generator for value estimation. Taking the current observation and robot proprioception as input, ViVa jointly predicts future proprioception and a scalar value for the current state. By leveraging the spatiotemporal priors of a pretrained video generator, our approach grounds value estimation in anticipated embodiment dynamics, moving beyond static snapshots to intrinsically couple value with foresight. Integrated into RECAP, ViVa delivers substantial improvements on real-world box assembly. Qualitative analysis across all three tasks confirms that ViVa produces more reliable value signals, accurately reflecting task progress. By leveraging spatiotemporal priors from video corpora, ViVa also generalizes to novel objects, highlighting the promise of video-generative models for value estimation.
StreamingClaw Technical Report
Mar 23, 2026Applications such as embodied intelligence rely on a real-time perception-decision-action closed loop, posing stringent challenges for streaming video understanding. However, current agents suffer from fragmented capabilities, such as supporting only offline video understanding, lacking long-term multimodal memory mechanisms, or struggling to achieve real-time reasoning and proactive interaction under streaming inputs. These shortcomings have become a key bottleneck for preventing them from sustaining perception, making real-time decisions, and executing actions in real-world environments. To alleviate these issues, we propose StreamingClaw, a unified agent framework for streaming video understanding and embodied intelligence. It is also an OpenClaw-compatible framework that supports real-time, multimodal streaming interaction. StreamingClaw integrates five core capabilities: (1) It supports real-time streaming reasoning. (2) It supports reasoning about future events and proactive interaction under the online evolution of interaction objectives. (3) It supports multimodal long-term storage, hierarchical evolution, and efficient retrieval of shared memory across multiple agents. (4) It supports a closed-loop of perception-decision-action. In addition to conventional tools and skills, it also provides streaming tools and action-centric skills tailored for real-world physical environments. (5) It is compatible with the OpenClaw framework, allowing it to fully leverage the resources and support of the open-source community. With these designs, StreamingClaw integrates online real-time reasoning, multimodal long-term memory, and proactive interaction within a unified framework. Moreover, by translating decisions into executable actions, it enables direct control of the physical world, supporting practical deployment of embodied interaction.
VAMPO: Policy Optimization for Improving Visual Dynamics in Video Action Models
Mar 19, 2026Video action models are an appealing foundation for Vision--Language--Action systems because they can learn visual dynamics from large-scale video data and transfer this knowledge to downstream robot control. Yet current diffusion-based video predictors are trained with likelihood-surrogate objectives, which encourage globally plausible predictions without explicitly optimizing the precision-critical visual dynamics needed for manipulation. This objective mismatch often leads to subtle errors in object pose, spatial relations, and contact timing that can be amplified by downstream policies. We propose VAMPO, a post-training framework that directly improves visual dynamics in video action models through policy optimization. Our key idea is to formulate multi-step denoising as a sequential decision process and optimize the denoising policy with rewards defined over expert visual dynamics in latent space. To make this optimization practical, we introduce an Euler Hybrid sampler that injects stochasticity only at the first denoising step, enabling tractable low-variance policy-gradient estimation while preserving the coherence of the remaining denoising trajectory. We further combine this design with GRPO and a verifiable non-adversarial reward. Across diverse simulated and real-world manipulation tasks, VAMPO improves task-relevant visual dynamics, leading to better downstream action generation and stronger generalization. The homepage is https://vampo-robot.github.io/VAMPO/.
GigaWorld-Policy: An Efficient Action-Centered World--Action Model
Mar 18, 2026World-Action Models (WAM) initialized from pre-trained video generation backbones have demonstrated remarkable potential for robot policy learning. However, existing approaches face two critical bottlenecks that hinder performance and deployment. First, jointly reasoning over future visual dynamics and corresponding actions incurs substantial inference overhead. Second, joint modeling often entangles visual and motion representations, making motion prediction accuracy heavily dependent on the quality of future video forecasts. To address these issues, we introduce GigaWorld-Policy, an action-centered WAM that learns 2D pixel-action dynamics while enabling efficient action decoding, with optional video generation. Specifically, we formulate policy training into two coupled components: the model predicts future action sequences conditioned on the current observation, and simultaneously generates future videos conditioned on the predicted actions and the same observation. The policy is supervised by both action prediction and video generation, providing richer learning signals and encouraging physically plausible actions through visual-dynamics constraints. With a causal design that prevents future-video tokens from influencing action tokens, explicit future-video generation is optional at inference time, allowing faster action prediction during deployment. To support this paradigm, we curate a diverse, large-scale robot dataset to pre-train an action-centered video generation model, which is then adapted as the backbone for robot policy learning. Experimental results on real-world robotic platforms show that GigaWorld-Policy runs 9x faster than the leading WAM baseline, Motus, while improving task success rates by 7%. Moreover, compared with pi-0.5, GigaWorld-Policy improves performance by 95% on RoboTwin 2.0.
A Simple Image Segmentation Framework via In-Context Examples
Oct 07, 2024Recently, there have been explorations of generalist segmentation models that can effectively tackle a variety of image segmentation tasks within a unified in-context learning framework. However, these methods still struggle with task ambiguity in in-context segmentation, as not all in-context examples can accurately convey the task information. In order to address this issue, we present SINE, a simple image Segmentation framework utilizing in-context examples. Our approach leverages a Transformer encoder-decoder structure, where the encoder provides high-quality image representations, and the decoder is designed to yield multiple task-specific output masks to effectively eliminate task ambiguity. Specifically, we introduce an In-context Interaction module to complement in-context information and produce correlations between the target image and the in-context example and a Matching Transformer that uses fixed matching and a Hungarian algorithm to eliminate differences between different tasks. In addition, we have further perfected the current evaluation system for in-context image segmentation, aiming to facilitate a holistic appraisal of these models. Experiments on various segmentation tasks show the effectiveness of the proposed method.
SegPrompt: Boosting Open-world Segmentation via Category-level Prompt Learning
Aug 12, 2023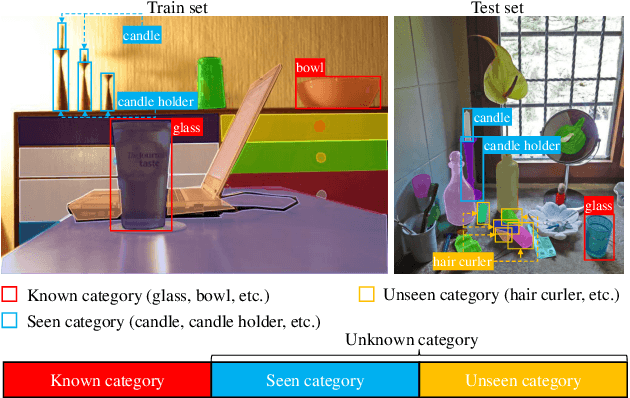

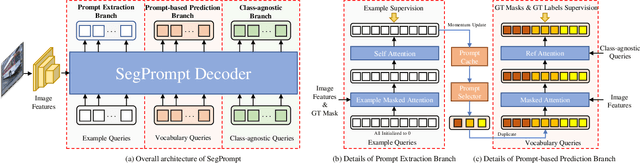

Current closed-set instance segmentation models rely on pre-defined class labels for each mask during training and evaluation, largely limiting their ability to detect novel objects. Open-world instance segmentation (OWIS) models address this challenge by detecting unknown objects in a class-agnostic manner. However, previous OWIS approaches completely erase category information during training to keep the model's ability to generalize to unknown objects. In this work, we propose a novel training mechanism termed SegPrompt that uses category information to improve the model's class-agnostic segmentation ability for both known and unknown categories. In addition, the previous OWIS training setting exposes the unknown classes to the training set and brings information leakage, which is unreasonable in the real world. Therefore, we provide a new open-world benchmark closer to a real-world scenario by dividing the dataset classes into known-seen-unseen parts. For the first time, we focus on the model's ability to discover objects that never appear in the training set images. Experiments show that SegPrompt can improve the overall and unseen detection performance by 5.6% and 6.1% in AR on our new benchmark without affecting the inference efficiency. We further demonstrate the effectiveness of our method on existing cross-dataset transfer and strongly supervised settings, leading to 5.5% and 12.3% relative improvement.
Matcher: Segment Anything with One Shot Using All-Purpose Feature Matching
May 22, 2023Powered by large-scale pre-training, vision foundation models exhibit significant potential in open-world image understanding. Even though individual models have limited capabilities, combining multiple such models properly can lead to positive synergies and unleash their full potential. In this work, we present Matcher, which segments anything with one shot by integrating an all-purpose feature extraction model and a class-agnostic segmentation model. Naively connecting the models results in unsatisfying performance, e.g., the models tend to generate matching outliers and false-positive mask fragments. To address these issues, we design a bidirectional matching strategy for accurate cross-image semantic dense matching and a robust prompt sampler for mask proposal generation. In addition, we propose a novel instance-level matching strategy for controllable mask merging. The proposed Matcher method delivers impressive generalization performance across various segmentation tasks, all without training. For example, it achieves 52.7% mIoU on COCO-20$^i$ for one-shot semantic segmentation, surpassing the state-of-the-art specialist model by 1.6%. In addition, our visualization results show open-world generality and flexibility on images in the wild. The code shall be released at https://github.com/aim-uofa/Matcher.