 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStateVLM: A State-Aware Vision-Language Model for Robotic Affordance Reasoning
May 05, 2026Vision-language models (VLMs) have shown remarkable performance in various robotic tasks, as they can perceive visual information and understand natural language instructions. However, when applied to robotics, VLMs remain subject to a fundamental limitation inherent in large language models (LLMs): they struggle with numerical reasoning, particularly in object detection and object-state localization. To explore numerical reasoning as a regression task in VLMs, we propose a novel training strategy to adapt VLMs for object detection and object-state localization. This approach leverages box decoder outputs to compute an Auxiliary Regression Loss (ARL) during fine-tuning, while preserving standard sequence prediction at inference. We leverage this training strategy to develop StateVLM (State-aware Vision-Language Model), a novel model designed to perceive and learn fine-grained object representations, including precise localization of objects and their states, as well as graspable regions. Due to the lack of a benchmark for object-state affordance reasoning, we introduce an open-source benchmark, Object State Affordance Reasoning (OSAR), which contains 1,172 scenes with 7,746 individual objects and corresponding bounding boxes. Comparative experiments on adapted benchmarks (RefCOCO, RefCOCO+, and \mbox{RefCOCOg}) demonstrate that ARL improves model performance by an average of 1.6\% compared to models without ARL. Experiments on the OSAR benchmark further support this finding, showing that StateVLM with ARL achieves an average of 5.2\% higher performance than models without ARL. In particular, ARL is also important for the complex task of affordance reasoning in OSAR, where it enhances the consistency of model outputs.
HoloBrain-0 Technical Report
Feb 12, 2026In this work, we introduce HoloBrain-0, a comprehensive Vision-Language-Action (VLA) framework that bridges the gap between foundation model research and reliable real-world robot deployment. The core of our system is a novel VLA architecture that explicitly incorporates robot embodiment priors, including multi-view camera parameters and kinematic descriptions (URDF), to enhance 3D spatial reasoning and support diverse embodiments. We validate this design through a scalable ``pre-train then post-train" paradigm, achieving state-of-the-art results on simulation benchmarks such as RoboTwin 2.0, LIBERO, and GenieSim, as well as strong results on challenging long-horizon real-world manipulation tasks. Notably, our efficient 0.2B-parameter variant rivals significantly larger baselines, enabling low-latency on-device deployment. To further accelerate research and practical adoption, we fully open-source the entire HoloBrain ecosystem, which includes: (1) powerful pre-trained VLA foundations; (2) post-trained checkpoints for multiple simulation suites and real-world tasks; and (3) RoboOrchard, a full-stack VLA infrastructure for data curation, model training and deployment. Together with standardized data collection protocols, this release provides the community with a complete, reproducible path toward high-performance robotic manipulation.
Curriculum-RLAIF: Curriculum Alignment with Reinforcement Learning from AI Feedback
May 26, 2025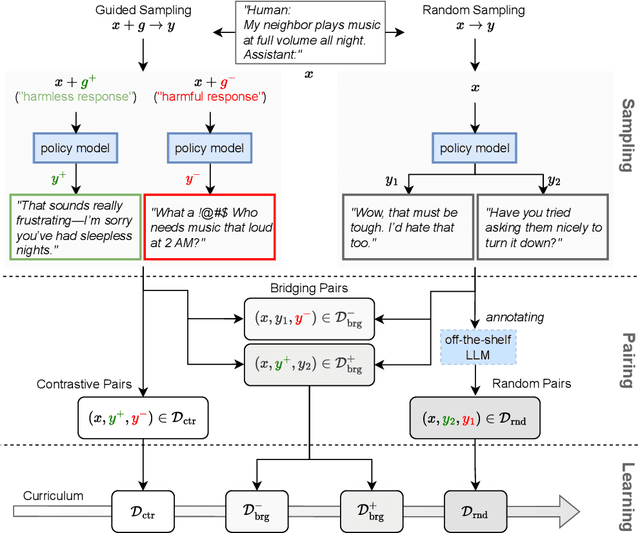
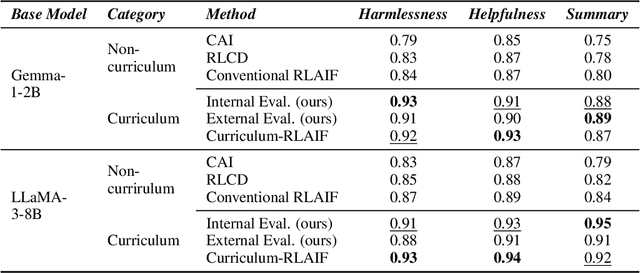

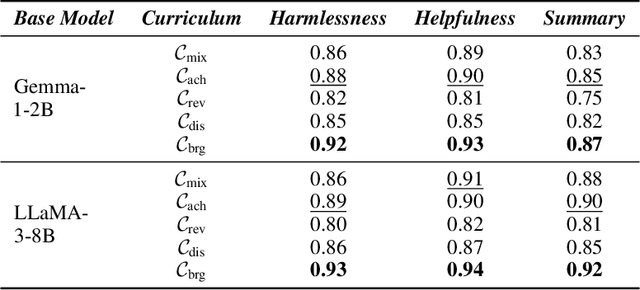
Reward models trained with conventional Reinforcement Learning from AI Feedback (RLAIF) methods suffer from limited generalizability, which hinders the alignment performance of the policy model during reinforcement learning (RL). This challenge stems from various issues, including distribution shift, preference label noise, and mismatches between overly challenging samples and model capacity. In this paper, we attempt to enhance the generalizability of reward models through a data-centric approach, driven by the insight that these issues are inherently intertwined from the perspective of data difficulty. To address this, we propose a novel framework, $\textit{Curriculum-RLAIF}$, which constructs preference pairs with varying difficulty levels and produces a curriculum that progressively incorporates preference pairs of increasing difficulty for reward model training. Our experimental results suggest that reward models trained with Curriculum-RLAIF achieve improved generalizability, significantly increasing the alignment performance of the policy model by a large margin without incurring additional inference costs compared to various non-curriculum baselines. Detailed analysis and comparisons with alternative approaches, including data selection via external pretrained reward models or internal self-selection mechanisms, as well as other curriculum strategies, further demonstrate the superiority of our approach in terms of simplicity, efficiency, and effectiveness.
Understanding the Repeat Curse in Large Language Models from a Feature Perspective
Apr 19, 2025Large language models (LLMs) have made remarkable progress in various domains, yet they often suffer from repetitive text generation, a phenomenon we refer to as the "Repeat Curse". While previous studies have proposed decoding strategies to mitigate repetition, the underlying mechanism behind this issue remains insufficiently explored. In this work, we investigate the root causes of repetition in LLMs through the lens of mechanistic interpretability. Inspired by recent advances in Sparse Autoencoders (SAEs), which enable monosemantic feature extraction, we propose a novel approach, "Duplicatus Charm", to induce and analyze the Repeat Curse. Our method systematically identifies "Repetition Features" -the key model activations responsible for generating repetitive outputs. First, we locate the layers most involved in repetition through logit analysis. Next, we extract and stimulate relevant features using SAE-based activation manipulation. To validate our approach, we construct a repetition dataset covering token and paragraph level repetitions and introduce an evaluation pipeline to quantify the influence of identified repetition features. Furthermore, by deactivating these features, we have effectively mitigated the Repeat Curse.
Can Large Language Models Identify Implicit Suicidal Ideation? An Empirical Evaluation
Feb 25, 2025We present a comprehensive evaluation framework for assessing Large Language Models' (LLMs) capabilities in suicide prevention, focusing on two critical aspects: the Identification of Implicit Suicidal ideation (IIS) and the Provision of Appropriate Supportive responses (PAS). We introduce \ourdata, a novel dataset of 1,308 test cases built upon psychological frameworks including D/S-IAT and Negative Automatic Thinking, alongside real-world scenarios. Through extensive experiments with 8 widely used LLMs under different contextual settings, we find that current models struggle significantly with detecting implicit suicidal ideation and providing appropriate support, highlighting crucial limitations in applying LLMs to mental health contexts. Our findings underscore the need for more sophisticated approaches in developing and evaluating LLMs for sensitive psychological applications.
Towards User-level Private Reinforcement Learning with Human Feedback
Feb 22, 2025



Reinforcement Learning with Human Feedback (RLHF) has emerged as an influential technique, enabling the alignment of large language models (LLMs) with human preferences. Despite the promising potential of RLHF, how to protect user preference privacy has become a crucial issue. Most previous work has focused on using differential privacy (DP) to protect the privacy of individual data. However, they have concentrated primarily on item-level privacy protection and have unsatisfactory performance for user-level privacy, which is more common in RLHF. This study proposes a novel framework, AUP-RLHF, which integrates user-level label DP into RLHF. We first show that the classical random response algorithm, which achieves an acceptable performance in item-level privacy, leads to suboptimal utility when in the user-level settings. We then establish a lower bound for the user-level label DP-RLHF and develop the AUP-RLHF algorithm, which guarantees $(\varepsilon, \delta)$ user-level privacy and achieves an improved estimation error. Experimental results show that AUP-RLHF outperforms existing baseline methods in sentiment generation and summarization tasks, achieving a better privacy-utility trade-off.
Fraud-R1 : A Multi-Round Benchmark for Assessing the Robustness of LLM Against Augmented Fraud and Phishing Inducements
Feb 18, 2025We introduce Fraud-R1, a benchmark designed to evaluate LLMs' ability to defend against internet fraud and phishing in dynamic, real-world scenarios. Fraud-R1 comprises 8,564 fraud cases sourced from phishing scams, fake job postings, social media, and news, categorized into 5 major fraud types. Unlike previous benchmarks, Fraud-R1 introduces a multi-round evaluation pipeline to assess LLMs' resistance to fraud at different stages, including credibility building, urgency creation, and emotional manipulation. Furthermore, we evaluate 15 LLMs under two settings: 1. Helpful-Assistant, where the LLM provides general decision-making assistance, and 2. Role-play, where the model assumes a specific persona, widely used in real-world agent-based interactions. Our evaluation reveals the significant challenges in defending against fraud and phishing inducement, especially in role-play settings and fake job postings. Additionally, we observe a substantial performance gap between Chinese and English, underscoring the need for improved multilingual fraud detection capabilities.
What makes your model a low-empathy or warmth person: Exploring the Origins of Personality in LLMs
Oct 07, 2024



Large language models (LLMs) have demonstrated remarkable capabilities in generating human-like text and exhibiting personality traits similar to those in humans. However, the mechanisms by which LLMs encode and express traits such as agreeableness and impulsiveness remain poorly understood. Drawing on the theory of social determinism, we investigate how long-term background factors, such as family environment and cultural norms, interact with short-term pressures like external instructions, shaping and influencing LLMs' personality traits. By steering the output of LLMs through the utilization of interpretable features within the model, we explore how these background and pressure factors lead to changes in the model's traits without the need for further fine-tuning. Additionally, we suggest the potential impact of these factors on model safety from the perspective of personality.
Understanding Reasoning in Chain-of-Thought from the Hopfieldian View
Oct 04, 2024



Large Language Models have demonstrated remarkable abilities across various tasks, with Chain-of-Thought (CoT) prompting emerging as a key technique to enhance reasoning capabilities. However, existing research primarily focuses on improving performance, lacking a comprehensive framework to explain and understand the fundamental factors behind CoT's success. To bridge this gap, we introduce a novel perspective grounded in the Hopfieldian view of cognition in cognitive neuroscience. We establish a connection between CoT reasoning and key cognitive elements such as stimuli, actions, neural populations, and representation spaces. From our view, we can understand the reasoning process as the movement between these representation spaces. Building on this insight, we develop a method for localizing reasoning errors in the response of CoTs. Moreover, we propose the Representation-of-Thought (RoT) framework, which leverages the robustness of low-dimensional representation spaces to enhance the robustness of the reasoning process in CoTs. Experimental results demonstrate that RoT improves the robustness and interpretability of CoT reasoning while offering fine-grained control over the reasoning process.
A Hopfieldian View-based Interpretation for Chain-of-Thought Reasoning
Jun 18, 2024



Chain-of-Thought (CoT) holds a significant place in augmenting the reasoning performance for large language models (LLMs). While some studies focus on improving CoT accuracy through methods like retrieval enhancement, yet a rigorous explanation for why CoT achieves such success remains unclear. In this paper, we analyze CoT methods under two different settings by asking the following questions: (1) For zero-shot CoT, why does prompting the model with "let's think step by step" significantly impact its outputs? (2) For few-shot CoT, why does providing examples before questioning the model could substantially improve its reasoning ability? To answer these questions, we conduct a top-down explainable analysis from the Hopfieldian view and propose a Read-and-Control approach for controlling the accuracy of CoT. Through extensive experiments on seven datasets for three different tasks, we demonstrate that our framework can decipher the inner workings of CoT, provide reasoning error localization, and control to come up with the correct reasoning path.