 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlimmable Generative Adversarial Networks
Dec 15, 2020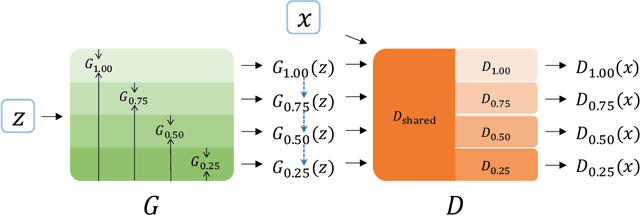
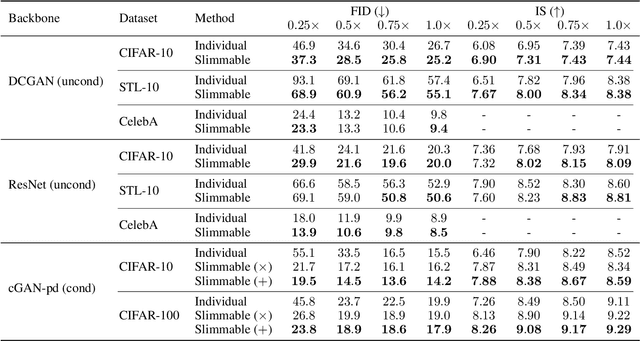


Generative adversarial networks (GANs) have achieved remarkable progress in recent years, but the continuously growing scale of models make them challenging to deploy widely in practical applications. In particular, for real-time generation tasks, different devices require generators of different sizes due to varying computing power. In this paper, we introduce slimmable GANs (SlimGANs), which can flexibly switch the width of the generator to accommodate various quality-efficiency trade-offs at runtime. Specifically, we leverage multiple discriminators that share partial parameters to train the slimmable generator. To facilitate the consistency between generators of different widths, we present a stepwise inplace distillation technique that encourages narrow generators to learn from wide ones. As for class-conditional generation, we propose a sliceable conditional batch normalization that incorporates the label information into different widths. Our methods are validated, both quantitatively and qualitatively, by extensive experiments and a detailed ablation study.
OneNet: Towards End-to-End One-Stage Object Detection
Dec 10, 2020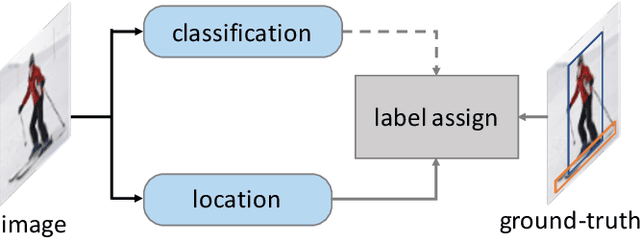

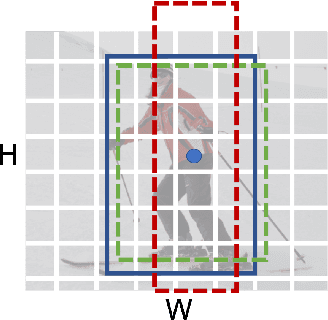

End-to-end one-stage object detection trailed thus far. This paper discovers that the lack of classification cost between sample and ground-truth in label assignment is the main obstacle for one-stage detectors to remove Non-maximum Suppression(NMS) and reach end-to-end. Existing one-stage object detectors assign labels by only location cost, e.g. box IoU or point distance. Without classification cost, sole location cost leads to redundant boxes of high confidence scores in inference, making NMS necessary post-processing. To design an end-to-end one-stage object detector, we propose Minimum Cost Assignment. The cost is the summation of classification cost and location cost between sample and ground-truth. For each object ground-truth, only one sample of minimum cost is assigned as the positive sample; others are all negative samples. To evaluate the effectiveness of our method, we design an extremely simple one-stage detector named OneNet. Our results show that when trained with Minimum Cost Assignment, OneNet avoids producing duplicated boxes and achieves to end-to-end detector. On COCO dataset, OneNet achieves 35.0 AP/80 FPS and 37.7 AP/50 FPS with image size of 512 pixels. We hope OneNet could serve as an effective baseline for end-to-end one-stage object detection. The code is available at: \url{https://github.com/PeizeSun/OneNet}.
F2Net: Learning to Focus on the Foreground for Unsupervised Video Object Segmentation
Dec 04, 2020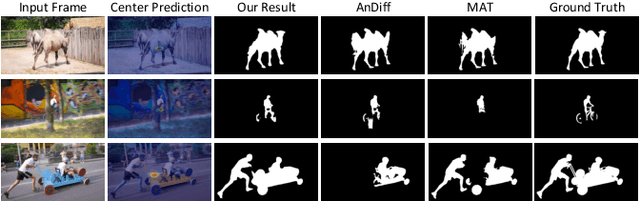
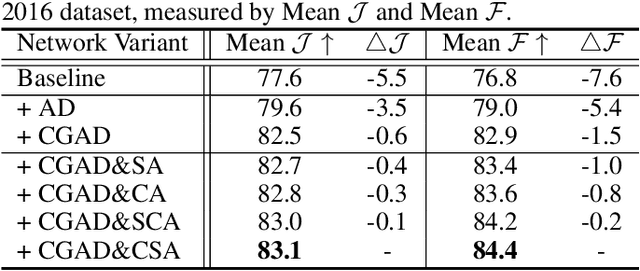
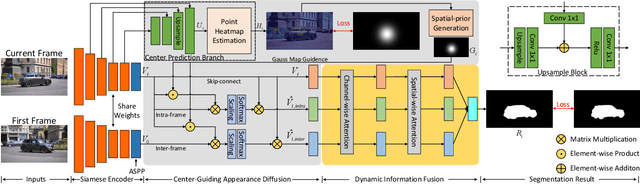
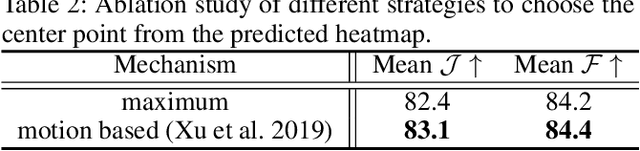
Although deep learning based methods have achieved great progress in unsupervised video object segmentation, difficult scenarios (e.g., visual similarity, occlusions, and appearance changing) are still not well-handled. To alleviate these issues, we propose a novel Focus on Foreground Network (F2Net), which delves into the intra-inter frame details for the foreground objects and thus effectively improve the segmentation performance. Specifically, our proposed network consists of three main parts: Siamese Encoder Module, Center Guiding Appearance Diffusion Module, and Dynamic Information Fusion Module. Firstly, we take a siamese encoder to extract the feature representations of paired frames (reference frame and current frame). Then, a Center Guiding Appearance Diffusion Module is designed to capture the inter-frame feature (dense correspondences between reference frame and current frame), intra-frame feature (dense correspondences in current frame), and original semantic feature of current frame. Specifically, we establish a Center Prediction Branch to predict the center location of the foreground object in current frame and leverage the center point information as spatial guidance prior to enhance the inter-frame and intra-frame feature extraction, and thus the feature representation considerably focus on the foreground objects. Finally, we propose a Dynamic Information Fusion Module to automatically select relatively important features through three aforementioned different level features. Extensive experiments on DAVIS2016, Youtube-object, and FBMS datasets show that our proposed F2Net achieves the state-of-the-art performance with significant improvement.
Sparse R-CNN: End-to-End Object Detection with Learnable Proposals
Nov 25, 2020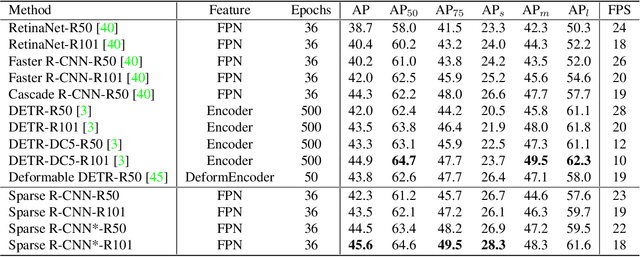
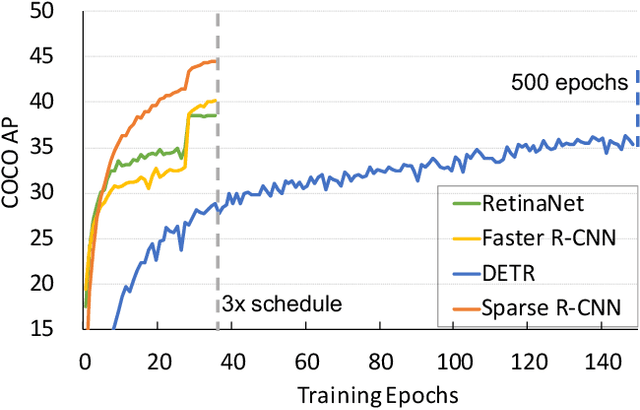

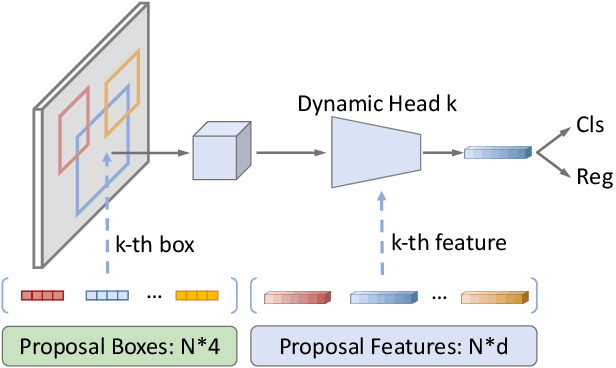
We present Sparse R-CNN, a purely sparse method for object detection in images. Existing works on object detection heavily rely on dense object candidates, such as $k$ anchor boxes pre-defined on all grids of image feature map of size $H\times W$. In our method, however, a fixed sparse set of learned object proposals, total length of $N$, are provided to object recognition head to perform classification and location. By eliminating $HWk$ (up to hundreds of thousands) hand-designed object candidates to $N$ (e.g. 100) learnable proposals, Sparse R-CNN completely avoids all efforts related to object candidates design and many-to-one label assignment. More importantly, final predictions are directly output without non-maximum suppression post-procedure. Sparse R-CNN demonstrates accuracy, run-time and training convergence performance on par with the well-established detector baselines on the challenging COCO dataset, e.g., achieving 44.5 AP in standard $3\times$ training schedule and running at 22 fps using ResNet-50 FPN model. We hope our work could inspire re-thinking the convention of dense prior in object detectors. The code is available at: https://github.com/PeizeSun/SparseR-CNN.
Learning the Best Pooling Strategy for Visual Semantic Embedding
Nov 09, 2020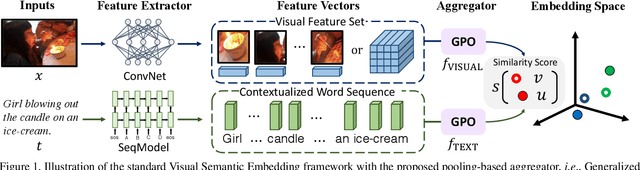
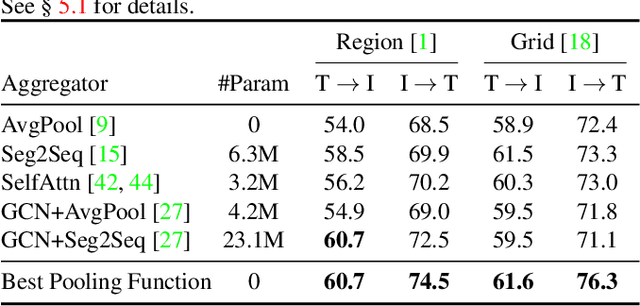
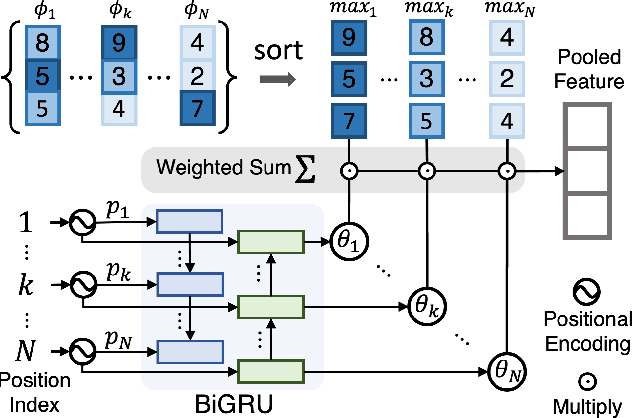
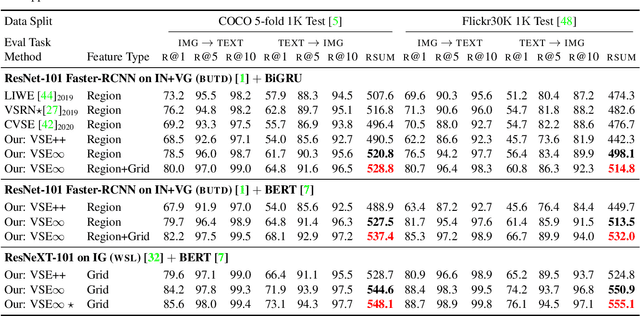
Visual Semantic Embedding (VSE) is a dominant approach for vision-language retrieval, which aims at learning a deep embedding space such that visual data are embedded close to their semantic text labels or descriptions. Recent VSE models use complex methods to better contextualize and aggregate multi-modal features into holistic embeddings. However, we discover that surprisingly simple (but carefully selected) global pooling functions (e.g., max pooling) outperform those complex models, across different feature extractors. Despite its simplicity and effectiveness, seeking the best pooling function for different data modality and feature extractor is costly and tedious, especially when the size of features varies (e.g., text, video). Therefore, we propose a Generalized Pooling Operator (GPO), which learns to automatically adapt itself to the best pooling strategy for different features, requiring no manual tuning while staying effective and efficient. We extend the VSE model using this proposed GPO and denote it as VSE$\infty$. Without bells and whistles, VSE$\infty$ outperforms previous VSE methods significantly on image-text retrieval benchmarks across popular feature extractors. With a simple adaptation, variants of VSE$\infty$ further demonstrate its strength by achieving the new state of the art on two video-text retrieval datasets. Comprehensive experiments and visualizations confirm that GPO always discovers the best pooling strategy and can be a plug-and-play feature aggregation module for standard VSE models.
Context Encoding for Video Retrieval with Contrastive Learning
Aug 04, 2020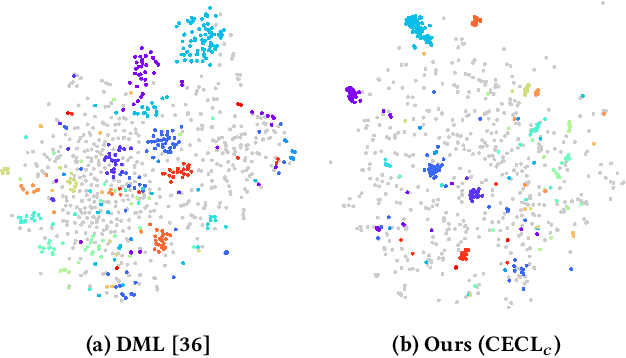
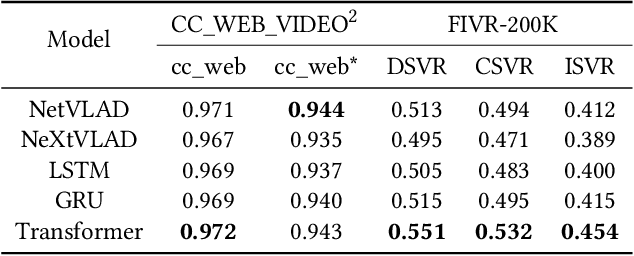
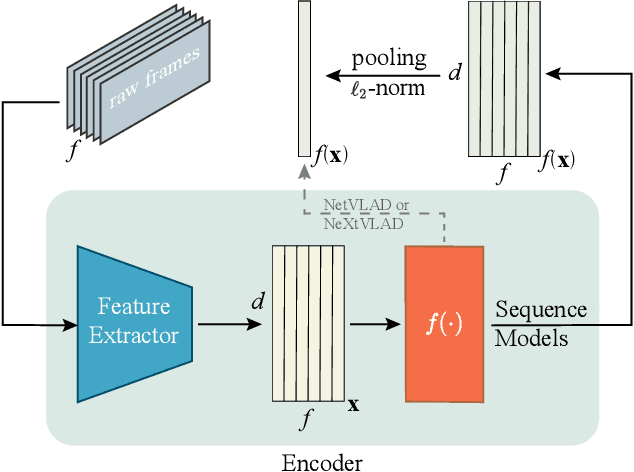

Content-based video retrieval plays an important role in areas such as video recommendation, copyright protection, etc. Existing video retrieval methods mainly extract frame-level features independently, therefore lack of efficient aggregation of features between frames, and it is difficult to effectively deal with poor quality frames, such as frames with motion blur, out of focus, etc. In this paper, we propose CECL (Context Encoding for video retrieval with Contrastive Learning), a video representation learning framework that aggregates the context information of frame-level descriptors, and a supervised contrastive learning method that performs automatic hard negative mining, and utilizes the memory bank mechanism to increase the capacity of negative samples. Extensive experiments are conducted on multi video retrieval tasks, such as FIVR, CC_WEB_VIDEO and EVVE. The proposed method shows a significant performance advantage (~17% mAP on FIVR-200K) over state-of-the-art methods with video-level features, and deliver competitive results with much lower computational cost when compared with frame-level features.
Towards Good Practices for Instance Segmentation
Oct 28, 2019
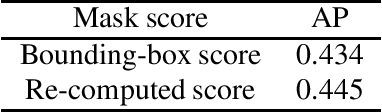


Instance Segmentation is an interesting yet challenging task in computer vision. In this paper, we conduct a series of refinements with the Hybrid Task Cascade (HTC) Network, and empirically evaluate their impact on the final model performance through ablation studies. By taking all the refinements, we achieve 0.47 on the COCO test-dev dataset and 0.47 on the COCO test-challenge dataset.
Towards Good Practices for Multi-Person Pose Estimation
Oct 28, 2019



Multi-Person Pose Estimation is an interesting yet challenging task in computer vision. In this paper, we conduct a series of refinements with the MSPN and PoseFix Networks, and empirically evaluate their impact on the final model performance through ablation studies. By taking all the refinements, we achieve 78.7 on the COCO test-dev dataset and 76.3 on the COCO test-challenge dataset.
Towards Good Practices for Video Object Segmentation
Sep 30, 2019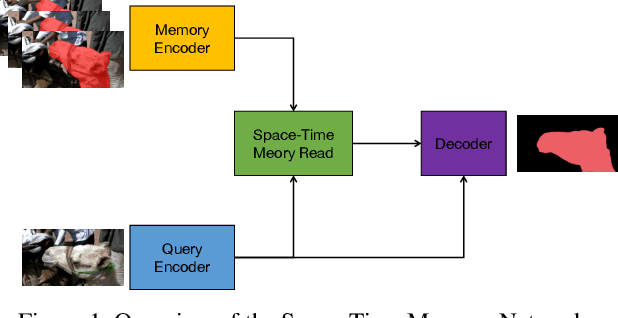

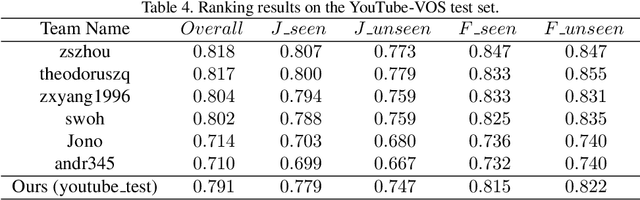
Semi-supervised video object segmentation is an interesting yet challenging task in machine learning. In this work, we conduct a series of refinements with the propagation-based video object segmentation method and empirically evaluate their impact on the final model performance through ablation study. By taking all the refinements, we improve the space-time memory networks to achieve a Overall of 79.1 on the Youtube-VOS Challenge 2019.
Deformable Tube Network for Action Detection in Videos
Jul 03, 2019



We address the problem of spatio-temporal action detection in videos. Existing methods commonly either ignore temporal context in action recognition and localization, or lack the modelling of flexible shapes of action tubes. In this paper, we propose a two-stage action detector called Deformable Tube Network (DTN), which is composed of a Deformation Tube Proposal Network (DTPN) and a Deformable Tube Recognition Network (DTRN) similar to the Faster R-CNN architecture. In DTPN, a fast proposal linking algorithm (FTL) is introduced to connect region proposals across frames to generate multiple deformable action tube proposals. To perform action detection, we design a 3D convolution network with skip connections for tube classification and regression. Modelling action proposals as deformable tubes explicitly considers the shape of action tubes compared to 3D cuboids. Moreover, 3D convolution based recognition network can learn temporal dynamics sufficiently for action detection. Our experimental results show that we significantly outperform the methods with 3D cuboids and obtain the state-of-the-art results on both UCF-Sports and AVA datasets.