 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMalRAG: A Retrieval-Augmented LLM Framework for Open-set Malicious Traffic Identification
Nov 18, 2025Fine-grained identification of IDS-flagged suspicious traffic is crucial in cybersecurity. In practice, cyber threats evolve continuously, making the discovery of novel malicious traffic a critical necessity as well as the identification of known classes. Recent studies have advanced this goal with deep models, but they often rely on task-specific architectures that limit transferability and require per-dataset tuning. In this paper we introduce MalRAG, the first LLM driven retrieval-augmented framework for open-set malicious traffic identification. MalRAG freezes the LLM and operates via comprehensive traffic knowledge construction, adaptive retrieval, and prompt engineering. Concretely, we construct a multi-view traffic database by mining prior malicious traffic from content, structural, and temporal perspectives. Furthermore, we introduce a Coverage-Enhanced Retrieval Algorithm that queries across these views to assemble the most probable candidates, thereby improving the inclusion of correct evidence. We then employ Traffic-Aware Adaptive Pruning to select a variable subset of these candidates based on traffic-aware similarity scores, suppressing incorrect matches and yielding reliable retrieved evidence. Moreover, we develop a suite of guidance prompts where task instruction, evidence referencing, and decision guidance are integrated with the retrieved evidence to improve LLM performance. Across diverse real-world datasets and settings, MalRAG delivers state-of-the-art results in both fine-grained identification of known classes and novel malicious traffic discovery. Ablation and deep-dive analyses further show that MalRAG effective leverages LLM capabilities yet achieves open-set malicious traffic identification without relying on a specific LLM.
S2D-ALIGN: Shallow-to-Deep Auxiliary Learning for Anatomically-Grounded Radiology Report Generation
Nov 14, 2025



Radiology Report Generation (RRG) aims to automatically generate diagnostic reports from radiology images. To achieve this, existing methods have leveraged the powerful cross-modal generation capabilities of Multimodal Large Language Models (MLLMs), primarily focusing on optimizing cross-modal alignment between radiographs and reports through Supervised Fine-Tuning (SFT). However, by only performing instance-level alignment with the image-text pairs, the standard SFT paradigm fails to establish anatomically-grounded alignment, where the templated nature of reports often leads to sub-optimal generation quality. To address this, we propose \textsc{S2D-Align}, a novel SFT paradigm that establishes anatomically-grounded alignment by leveraging auxiliary signals of varying granularities. \textsc{S2D-Align} implements a shallow-to-deep strategy, progressively enriching the alignment process: it begins with the coarse radiograph-report pairing, then introduces reference reports for instance-level guidance, and ultimately utilizes key phrases to ground the generation in specific anatomical details. To bridge the different alignment stages, we introduce a memory-based adapter that empowers feature sharing, thereby integrating coarse and fine-grained guidance. For evaluation, we conduct experiments on the public \textsc{MIMIC-CXR} and \textsc{IU X-Ray} benchmarks, where \textsc{S2D-Align} achieves state-of-the-art performance compared to existing methods. Ablation studies validate the effectiveness of our multi-stage, auxiliary-guided approach, highlighting a promising direction for enhancing grounding capabilities in complex, multi-modal generation tasks.
AuthSig: Safeguarding Scanned Signatures Against Unauthorized Reuse in Paperless Workflows
Nov 12, 2025With the deepening trend of paperless workflows, signatures as a means of identity authentication are gradually shifting from traditional ink-on-paper to electronic formats.Despite the availability of dynamic pressure-sensitive and PKI-based digital signatures, static scanned signatures remain prevalent in practice due to their convenience. However, these static images, having almost lost their authentication attributes, cannot be reliably verified and are vulnerable to malicious copying and reuse. To address these issues, we propose AuthSig, a novel static electronic signature framework based on generative models and watermark, which binds authentication information to the signature image. Leveraging the human visual system's insensitivity to subtle style variations, AuthSig finely modulates style embeddings during generation to implicitly encode watermark bits-enforcing a One Signature, One Use policy.To overcome the scarcity of handwritten signature data and the limitations of traditional augmentation methods, we introduce a keypoint-driven data augmentation strategy that effectively enhances style diversity to support robust watermark embedding. Experimental results show that AuthSig achieves over 98% extraction accuracy under both digital-domain distortions and signature-specific degradations, and remains effective even in print-scan scenarios.
Omics-scale polymer computational database transferable to real-world artificial intelligence applications
Nov 07, 2025Developing large-scale foundational datasets is a critical milestone in advancing artificial intelligence (AI)-driven scientific innovation. However, unlike AI-mature fields such as natural language processing, materials science, particularly polymer research, has significantly lagged in developing extensive open datasets. This lag is primarily due to the high costs of polymer synthesis and property measurements, along with the vastness and complexity of the chemical space. This study presents PolyOmics, an omics-scale computational database generated through fully automated molecular dynamics simulation pipelines that provide diverse physical properties for over $10^5$ polymeric materials. The PolyOmics database is collaboratively developed by approximately 260 researchers from 48 institutions to bridge the gap between academia and industry. Machine learning models pretrained on PolyOmics can be efficiently fine-tuned for a wide range of real-world downstream tasks, even when only limited experimental data are available. Notably, the generalisation capability of these simulation-to-real transfer models improve significantly as the size of the PolyOmics database increases, exhibiting power-law scaling. The emergence of scaling laws supports the "more is better" principle, highlighting the significance of ultralarge-scale computational materials data for improving real-world prediction performance. This unprecedented omics-scale database reveals vast unexplored regions of polymer materials, providing a foundation for AI-driven polymer science.
TimeSearch-R: Adaptive Temporal Search for Long-Form Video Understanding via Self-Verification Reinforcement Learning
Nov 07, 2025Temporal search aims to identify a minimal set of relevant frames from tens of thousands based on a given query, serving as a foundation for accurate long-form video understanding. Existing works attempt to progressively narrow the search space. However, these approaches typically rely on a hand-crafted search process, lacking end-to-end optimization for learning optimal search strategies. In this paper, we propose TimeSearch-R, which reformulates temporal search as interleaved text-video thinking, seamlessly integrating searching video clips into the reasoning process through reinforcement learning (RL). However, applying RL training methods, such as Group Relative Policy Optimization (GRPO), to video reasoning can result in unsupervised intermediate search decisions. This leads to insufficient exploration of the video content and inconsistent logical reasoning. To address these issues, we introduce GRPO with Completeness Self-Verification (GRPO-CSV), which gathers searched video frames from the interleaved reasoning process and utilizes the same policy model to verify the adequacy of searched frames, thereby improving the completeness of video reasoning. Additionally, we construct datasets specifically designed for the SFT cold-start and RL training of GRPO-CSV, filtering out samples with weak temporal dependencies to enhance task difficulty and improve temporal search capabilities. Extensive experiments demonstrate that TimeSearch-R achieves significant improvements on temporal search benchmarks such as Haystack-LVBench and Haystack-Ego4D, as well as long-form video understanding benchmarks like VideoMME and MLVU. Notably, TimeSearch-R establishes a new state-of-the-art on LongVideoBench with 4.1% improvement over the base model Qwen2.5-VL and 2.0% over the advanced video reasoning model Video-R1. Our code is available at https://github.com/Time-Search/TimeSearch-R.
BoRe-Depth: Self-supervised Monocular Depth Estimation with Boundary Refinement for Embedded Systems
Nov 06, 2025



Depth estimation is one of the key technologies for realizing 3D perception in unmanned systems. Monocular depth estimation has been widely researched because of its low-cost advantage, but the existing methods face the challenges of poor depth estimation performance and blurred object boundaries on embedded systems. In this paper, we propose a novel monocular depth estimation model, BoRe-Depth, which contains only 8.7M parameters. It can accurately estimate depth maps on embedded systems and significantly improves boundary quality. Firstly, we design an Enhanced Feature Adaptive Fusion Module (EFAF) which adaptively fuses depth features to enhance boundary detail representation. Secondly, we integrate semantic knowledge into the encoder to improve the object recognition and boundary perception capabilities. Finally, BoRe-Depth is deployed on NVIDIA Jetson Orin, and runs efficiently at 50.7 FPS. We demonstrate that the proposed model significantly outperforms previous lightweight models on multiple challenging datasets, and we provide detailed ablation studies for the proposed methods. The code is available at https://github.com/liangxiansheng093/BoRe-Depth.
GTCN-G: A Residual Graph-Temporal Fusion Network for Imbalanced Intrusion Detection (Preprint)
Oct 08, 2025The escalating complexity of network threats and the inherent class imbalance in traffic data present formidable challenges for modern Intrusion Detection Systems (IDS). While Graph Neural Networks (GNNs) excel in modeling topological structures and Temporal Convolutional Networks (TCNs) are proficient in capturing time-series dependencies, a framework that synergistically integrates both while explicitly addressing data imbalance remains an open challenge. This paper introduces a novel deep learning framework, named Gated Temporal Convolutional Network and Graph (GTCN-G), engineered to overcome these limitations. Our model uniquely fuses a Gated TCN (G-TCN) for extracting hierarchical temporal features from network flows with a Graph Convolutional Network (GCN) designed to learn from the underlying graph structure. The core innovation lies in the integration of a residual learning mechanism, implemented via a Graph Attention Network (GAT). This mechanism preserves original feature information through residual connections, which is critical for mitigating the class imbalance problem and enhancing detection sensitivity for rare malicious activities (minority classes). We conducted extensive experiments on two public benchmark datasets, UNSW-NB15 and ToN-IoT, to validate our approach. The empirical results demonstrate that the proposed GTCN-G model achieves state-of-the-art performance, significantly outperforming existing baseline models in both binary and multi-class classification tasks.
Probing the Critical Point (CritPt) of AI Reasoning: a Frontier Physics Research Benchmark
Oct 01, 2025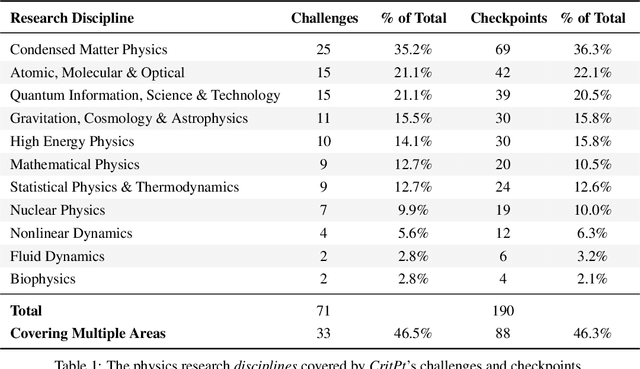



While large language models (LLMs) with reasoning capabilities are progressing rapidly on high-school math competitions and coding, can they reason effectively through complex, open-ended challenges found in frontier physics research? And crucially, what kinds of reasoning tasks do physicists want LLMs to assist with? To address these questions, we present the CritPt (Complex Research using Integrated Thinking - Physics Test, pronounced "critical point"), the first benchmark designed to test LLMs on unpublished, research-level reasoning tasks that broadly covers modern physics research areas, including condensed matter, quantum physics, atomic, molecular & optical physics, astrophysics, high energy physics, mathematical physics, statistical physics, nuclear physics, nonlinear dynamics, fluid dynamics and biophysics. CritPt consists of 71 composite research challenges designed to simulate full-scale research projects at the entry level, which are also decomposed to 190 simpler checkpoint tasks for more fine-grained insights. All problems are newly created by 50+ active physics researchers based on their own research. Every problem is hand-curated to admit a guess-resistant and machine-verifiable answer and is evaluated by an automated grading pipeline heavily customized for advanced physics-specific output formats. We find that while current state-of-the-art LLMs show early promise on isolated checkpoints, they remain far from being able to reliably solve full research-scale challenges: the best average accuracy among base models is only 4.0% , achieved by GPT-5 (high), moderately rising to around 10% when equipped with coding tools. Through the realistic yet standardized evaluation offered by CritPt, we highlight a large disconnect between current model capabilities and realistic physics research demands, offering a foundation to guide the development of scientifically grounded AI tools.
Enhancing Vehicle Detection under Adverse Weather Conditions with Contrastive Learning
Sep 26, 2025Aside from common challenges in remote sensing like small, sparse targets and computation cost limitations, detecting vehicles from UAV images in the Nordic regions faces strong visibility challenges and domain shifts caused by diverse levels of snow coverage. Although annotated data are expensive, unannotated data is cheaper to obtain by simply flying the drones. In this work, we proposed a sideload-CL-adaptation framework that enables the use of unannotated data to improve vehicle detection using lightweight models. Specifically, we propose to train a CNN-based representation extractor through contrastive learning on the unannotated data in the pretraining stage, and then sideload it to a frozen YOLO11n backbone in the fine-tuning stage. To find a robust sideload-CL-adaptation, we conducted extensive experiments to compare various fusion methods and granularity. Our proposed sideload-CL-adaptation model improves the detection performance by 3.8% to 9.5% in terms of mAP50 on the NVD dataset.
Investigating Student Interaction Patterns with Large Language Model-Powered Course Assistants in Computer Science Courses
Sep 10, 2025Providing students with flexible and timely academic support is a challenge at most colleges and universities, leaving many students without help outside scheduled hours. Large language models (LLMs) are promising for bridging this gap, but interactions between students and LLMs are rarely overseen by educators. We developed and studied an LLM-powered course assistant deployed across multiple computer science courses to characterize real-world use and understand pedagogical implications. By Spring 2024, our system had been deployed to approximately 2,000 students across six courses at three institutions. Analysis of the interaction data shows that usage remains strong in the evenings and nights and is higher in introductory courses, indicating that our system helps address temporal support gaps and novice learner needs. We sampled 200 conversations per course for manual annotation: most sampled responses were judged correct and helpful, with a small share unhelpful or erroneous; few responses included dedicated examples. We also examined an inquiry-based learning strategy: only around 11% of sampled conversations contained LLM-generated follow-up questions, which were often ignored by students in advanced courses. A Bloom's taxonomy analysis reveals that current LLM capabilities are limited in generating higher-order cognitive questions. These patterns suggest opportunities for pedagogically oriented LLM-based educational systems and greater educator involvement in configuring prompts, content, and policies.