 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Adapted Retrieval for In-Context Annotation of Pedagogical Dialogue Acts
Apr 03, 2026Automated annotation of pedagogical dialogue is a high-stakes task where LLMs often fail without sufficient domain grounding. We present a domain-adapted RAG pipeline for tutoring move annotation. Rather than fine-tuning the generative model, we adapt retrieval by fine-tuning a lightweight embedding model on tutoring corpora and indexing dialogues at the utterance level to retrieve labeled few-shot demonstrations. Evaluated across two real tutoring dialogue datasets (TalkMoves and Eedi) and three LLM backbones (GPT-5.2, Claude Sonnet 4.6, Qwen3-32b), our best configuration achieves Cohen's $κ$ of 0.526-0.580 on TalkMoves and 0.659-0.743 on Eedi, substantially outperforming no-retrieval baselines ($κ= 0.275$-$0.413$ and $0.160$-$0.410$). An ablation study reveals that utterance-level indexing, rather than embedding quality alone, is the primary driver of these gains, with top-1 label match rates improving from 39.7\% to 62.0\% on TalkMoves and 52.9\% to 73.1\% on Eedi under domain-adapted retrieval. Retrieval also corrects systematic label biases present in zero-shot prompting and yields the largest improvements for rare and context-dependent labels. These findings suggest that adapting the retrieval component alone is a practical and effective path toward expert-level pedagogical dialogue annotation while keeping the generative model frozen.
Optimizing LLM Annotation of Classroom Discourse through Multi-Agent Orchestration
Mar 08, 2026Large language models (LLMs) are increasingly positioned as scalable tools for annotating educational data, including classroom discourse, interaction logs, and qualitative learning artifacts. Their ability to rapidly summarize instructional interactions and assign rubric-aligned labels has fueled optimism about reducing the cost and time associated with expert human annotation. However, growing evidence suggests that single-pass LLM outputs remain unreliable for high-stakes educational constructs that require contextual, pedagogical, or normative judgment, such as instructional intent or discourse moves. This tension between scale and validity sits at the core of contemporary education data science. In this work, we present and empirically evaluate a hierarchical, cost-aware orchestration framework for LLM-based annotation that improves reliability while explicitly modeling computational tradeoffs. Rather than treating annotation as a one-shot prediction problem, we conceptualize it as a multi-stage epistemic process comprising (1) an unverified single-pass annotation stage, in which models independently assign labels based on the rubric; (2) a self-verification stage, in which each model audits its own output against rubric definitions and revises its label if inconsistencies are detected; and (3) a disagreement-centric adjudication stage, in which an independent adjudicator model examines the verified labels and justifications and determines a final label in accordance with the rubric. This structure mirrors established human annotation workflows in educational research, where initial coding is followed by self-checking and expert resolution of disagreements.
LLM Reasoning Predicts When Models Are Right: Evidence from Coding Classroom Discourse
Feb 10, 2026Large Language Models (LLMs) are increasingly deployed to automatically label and analyze educational dialogue at scale, yet current pipelines lack reliable ways to detect when models are wrong. We investigate whether reasoning generated by LLMs can be used to predict the correctness of a model's own predictions. We analyze 30,300 teacher utterances from classroom dialogue, each labeled by multiple state-of-the-art LLMs with an instructional move construct and an accompanying reasoning. Using human-verified ground-truth labels, we frame the task as predicting whether a model's assigned label for a given utterance is correct. We encode LLM reasoning using Term Frequency-Inverse Document Frequency (TF-IDF) and evaluate five supervised classifiers. A Random Forest classifier achieves an F1 score of 0.83 (Recall = 0.854), successfully identifying most incorrect predictions and outperforming baselines. Training specialist detectors for specific instructional move constructs further improves performance on difficult constructs, indicating that error detection benefits from construct-specific linguistic cues. Using the Linguistic Inquiry and Word Count (LIWC) framework, we examine four linguistic markers of correctness: Causation, Differentiation, Tentativeness, and Insight. Correct predictions exhibit grounded causal language (e.g., because, therefore), while incorrect reasoning is substantially more likely to rely on epistemic hedging (e.g., might, could) and performative metacognition (e.g., think, realize). Syntactic complexity does not distinguish correct from incorrect reasoning, and longer reasoning is not more reliable. These findings demonstrate that reasoning-based error detection offers a practical and scalable approach to quality control in automated educational dialogue analysis.
Codebook-Injected Dialogue Segmentation for Multi-Utterance Constructs Annotation: LLM-Assisted and Gold-Label-Free Evaluation
Jan 17, 2026Dialogue Act (DA) annotation typically treats communicative or pedagogical intent as localized to individual utterances or turns. This leads annotators to agree on the underlying action while disagreeing on segment boundaries, reducing apparent reliability. We propose codebook-injected segmentation, which conditions boundary decisions on downstream annotation criteria, and evaluate LLM-based segmenters against standard and retrieval-augmented baselines. To assess these without gold labels, we introduce evaluation metrics for span consistency, distinctiveness, and human-AI distributional agreement. We found DA-awareness produces segments that are internally more consistent than text-only baselines. While LLMs excel at creating construct-consistent spans, coherence-based baselines remain superior at detecting global shifts in dialogue flow. Across two datasets, no single segmenter dominates. Improvements in within-segment coherence frequently trade off against boundary distinctiveness and human-AI distributional agreement. These results highlight segmentation as a consequential design choice that should be optimized for downstream objectives rather than a single performance score.
How well do Large Language Models Recognize Instructional Moves? Establishing Baselines for Foundation Models in Educational Discourse
Dec 22, 2025Large language models (LLMs) are increasingly adopted in educational technologies for a variety of tasks, from generating instructional materials and assisting with assessment design to tutoring. While prior work has investigated how models can be adapted or optimized for specific tasks, far less is known about how well LLMs perform at interpreting authentic educational scenarios without significant customization. As LLM-based systems become widely adopted by learners and educators in everyday academic contexts, understanding their out-of-the-box capabilities is increasingly important for setting expectations and benchmarking. We compared six LLMs to estimate their baseline performance on a simple but important task: classifying instructional moves in authentic classroom transcripts. We evaluated typical prompting methods: zero-shot, one-shot, and few-shot prompting. We found that while zero-shot performance was moderate, providing comprehensive examples (few-shot prompting) significantly improved performance for state-of-the-art models, with the strongest configuration reaching Cohen's Kappa = 0.58 against expert-coded annotations. At the same time, improvements were neither uniform nor complete: performance varied considerably by instructional move, and higher recall frequently came at the cost of increased false positives. Overall, these findings indicate that foundation models demonstrate meaningful yet limited capacity to interpret instructional discourse, with prompt design helping to surface capability but not eliminating fundamental reliability constraints.
AI Annotation Orchestration: Evaluating LLM verifiers to Improve the Quality of LLM Annotations in Learning Analytics
Nov 12, 2025Large Language Models (LLMs) are increasingly used to annotate learning interactions, yet concerns about reliability limit their utility. We test whether verification-oriented orchestration-prompting models to check their own labels (self-verification) or audit one another (cross-verification)-improves qualitative coding of tutoring discourse. Using transcripts from 30 one-to-one math sessions, we compare three production LLMs (GPT, Claude, Gemini) under three conditions: unverified annotation, self-verification, and cross-verification across all orchestration configurations. Outputs are benchmarked against a blinded, disagreement-focused human adjudication using Cohen's kappa. Overall, orchestration yields a 58 percent improvement in kappa. Self-verification nearly doubles agreement relative to unverified baselines, with the largest gains for challenging tutor moves. Cross-verification achieves a 37 percent improvement on average, with pair- and construct-dependent effects: some verifier-annotator pairs exceed self-verification, while others reduce alignment, reflecting differences in verifier strictness. We contribute: (1) a flexible orchestration framework instantiating control, self-, and cross-verification; (2) an empirical comparison across frontier LLMs on authentic tutoring data with blinded human "gold" labels; and (3) a concise notation, verifier(annotator) (e.g., Gemini(GPT) or Claude(Claude)), to standardize reporting and make directional effects explicit for replication. Results position verification as a principled design lever for reliable, scalable LLM-assisted annotation in Learning Analytics.
Investigating Student Interaction Patterns with Large Language Model-Powered Course Assistants in Computer Science Courses
Sep 10, 2025Providing students with flexible and timely academic support is a challenge at most colleges and universities, leaving many students without help outside scheduled hours. Large language models (LLMs) are promising for bridging this gap, but interactions between students and LLMs are rarely overseen by educators. We developed and studied an LLM-powered course assistant deployed across multiple computer science courses to characterize real-world use and understand pedagogical implications. By Spring 2024, our system had been deployed to approximately 2,000 students across six courses at three institutions. Analysis of the interaction data shows that usage remains strong in the evenings and nights and is higher in introductory courses, indicating that our system helps address temporal support gaps and novice learner needs. We sampled 200 conversations per course for manual annotation: most sampled responses were judged correct and helpful, with a small share unhelpful or erroneous; few responses included dedicated examples. We also examined an inquiry-based learning strategy: only around 11% of sampled conversations contained LLM-generated follow-up questions, which were often ignored by students in advanced courses. A Bloom's taxonomy analysis reveals that current LLM capabilities are limited in generating higher-order cognitive questions. These patterns suggest opportunities for pedagogically oriented LLM-based educational systems and greater educator involvement in configuring prompts, content, and policies.
Auditing and Mitigating Cultural Bias in LLMs
Nov 23, 2023



Culture fundamentally shapes people's reasoning, behavior, and communication. Generative artificial intelligence (AI) technologies may cause a shift towards a dominant culture. As people increasingly use AI to expedite and even automate various professional and personal tasks, cultural values embedded in AI models may bias authentic expression. We audit large language models for cultural bias, comparing their responses to nationally representative survey data, and evaluate country-specific prompting as a mitigation strategy. We find that GPT-4, 3.5 and 3 exhibit cultural values resembling English-speaking and Protestant European countries. Our mitigation strategy reduces cultural bias in recent models but not for all countries/territories. To avoid cultural bias in generative AI, especially in high-stakes contexts, we suggest using culture matching and ongoing cultural audits.
Augmenting Holistic Review in University Admission using Natural Language Processing for Essays and Recommendation Letters
Jun 30, 2023


University admission at many highly selective institutions uses a holistic review process, where all aspects of the application, including protected attributes (e.g., race, gender), grades, essays, and recommendation letters are considered, to compose an excellent and diverse class. In this study, we empirically evaluate how influential protected attributes are for predicting admission decisions using a machine learning (ML) model, and in how far textual information (e.g., personal essay, teacher recommendation) may substitute for the loss of protected attributes in the model. Using data from 14,915 applicants to an undergraduate admission office at a selective U.S. institution in the 2022-2023 cycle, we find that the exclusion of protected attributes from the ML model leads to substantially reduced admission-prediction performance. The inclusion of textual information via both a TF-IDF representation and a Latent Dirichlet allocation (LDA) model partially restores model performance, but does not appear to provide a full substitute for admitting a similarly diverse class. In particular, while the text helps with gender diversity, the proportion of URM applicants is severely impacted by the exclusion of protected attributes, and the inclusion of new attributes generated from the textual information does not recover this performance loss.
On the limits of algorithmic prediction across the globe
Mar 28, 2021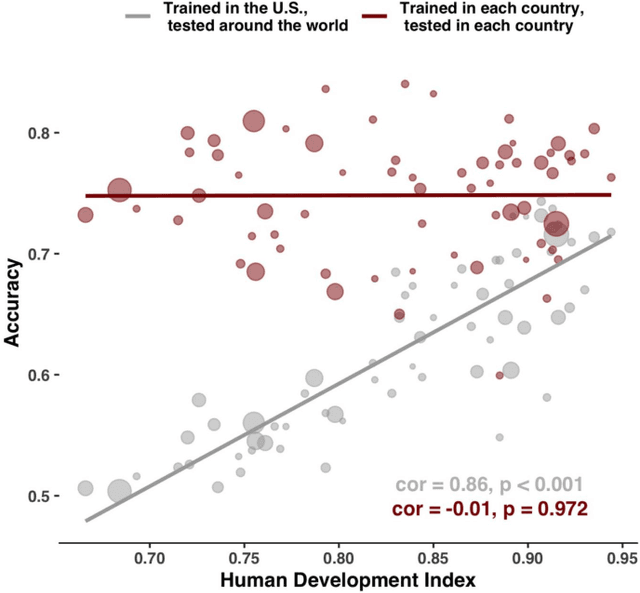
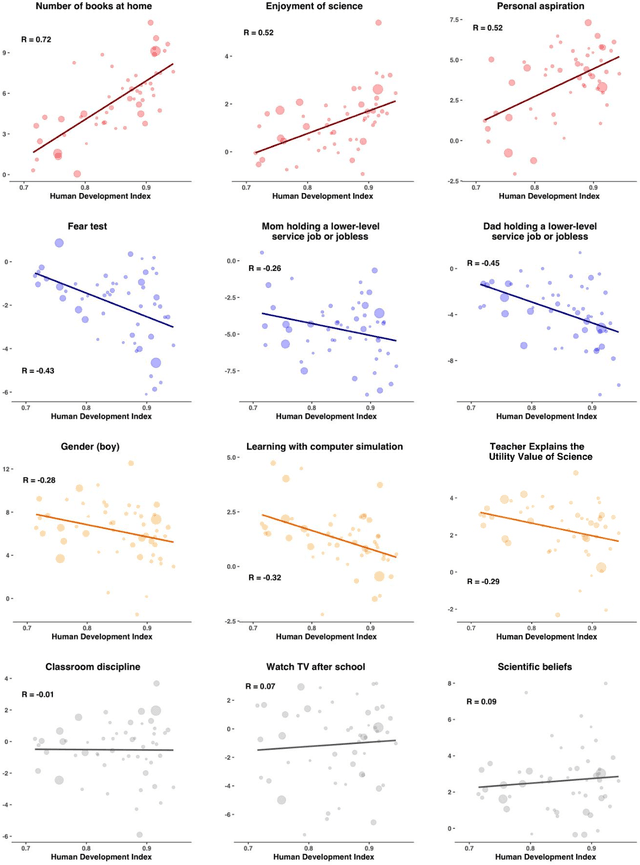
The impact of predictive algorithms on people's lives and livelihoods has been noted in medicine, criminal justice, finance, hiring and admissions. Most of these algorithms are developed using data and human capital from highly developed nations. We tested how well predictive models of human behavior trained in a developed country generalize to people in less developed countries by modeling global variation in 200 predictors of academic achievement on nationally representative student data for 65 countries. Here we show that state-of-the-art machine learning models trained on data from the United States can predict achievement with high accuracy and generalize to other developed countries with comparable accuracy. However, accuracy drops linearly with national development due to global variation in the importance of different achievement predictors, providing a useful heuristic for policymakers. Training the same model on national data yields high accuracy in every country, which highlights the value of local data collection.