 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Core Guided Contrastive Learning for Balanced Multi-modal Prognosis Prediction of Stroke
May 14, 2026Deep learning and multi-modal fusion have demonstrated transformative potential in medical diagnosis by integrating diverse data sources. However, accurate prognosis for ischemic stroke remains challenging due to limitations in existing multi-modal approaches. First, current methods are predominantly confined to dual-modal fusion, lacking a framework that effectively integrates the trifecta of medical images, structured clinical data, and unstructured text. Second, they often fail to establish deep bidirectional interactions between modalities; To address these critical gaps, this paper proposes a novel tri-modal fusion model for ischemic stroke prognosis. Our approach first enriches the data representation by employing a Large Language Model (LLM) to automatically generate semi-structured diagnostic text from brain MRIs. This process not only addresses the scarcity of expert annotations but also serves as a regularized semantic enhancement, improving multimodal fusion robustness. Furthermore, we design a core component termed the Vision-Conditioned Dual Alignment Fusion Module (VDAFM), which strategically uses visual features as a conditional prior to guide fine-grained interaction with the generated text. This module achieves a dynamic and profound fusion through a dual semantic alignment loss, effectively mitigating modal heterogeneity. Extensive experiments on a real-world clinical dataset demonstrate that our model achieves state-of-the-art performance.
Flow of Truth: Proactive Temporal Forensics for Image-to-Video Generation
Apr 16, 2026The rapid rise of image-to-video (I2V) generation enables realistic videos to be created from a single image but also brings new forensic demands. Unlike static images, I2V content evolves over time, requiring forensics to move beyond 2D pixel-level tampering localization toward tracing how pixels flow and transform throughout the video. As frames progress, embedded traces drift and deform, making traditional spatial forensics ineffective. To address this unexplored dimension, we present **Flow of Truth**, the first proactive framework focusing on temporal forensics in I2V generation. A key challenge lies in discovering a forensic signature that can evolve consistently with the generation process, which is inherently a creative transformation rather than a deterministic reconstruction. Despite this intrinsic difficulty, we innovatively redefine video generation as *the motion of pixels through time rather than the synthesis of frames*. Building on this view, we propose a learnable forensic template that follows pixel motion and a template-guided flow module that decouples motion from image content, enabling robust temporal tracing. Experiments show that Flow of Truth generalizes across commercial and open-source I2V models, substantially improving temporal forensics performance.
Event Tensor: A Unified Abstraction for Compiling Dynamic Megakernel
Apr 14, 2026Modern GPU workloads, especially large language model (LLM) inference, suffer from kernel launch overheads and coarse synchronization that limit inter-kernel parallelism. Recent megakernel techniques fuse multiple operators into a single persistent kernel to eliminate launch gaps and expose inter-kernel parallelism, but struggle to handle dynamic shapes and data-dependent computation in real workloads. We present Event Tensor, a unified compiler abstraction for dynamic megakernels. Event Tensor encodes dependencies between tiled tasks, and enables first-class support for both shape and data-dependent dynamism. Built atop this abstraction, our Event Tensor Compiler (ETC) applies static and dynamic scheduling transformations to generate high-performance persistent kernels. Evaluations show that ETC achieves state-of-the-art LLM serving latency while significantly reducing system warmup overhead.
Allocentric Perceiver: Disentangling Allocentric Reasoning from Egocentric Visual Priors via Frame Instantiation
Feb 05, 2026With the rising need for spatially grounded tasks such as Vision-Language Navigation/Action, allocentric perception capabilities in Vision-Language Models (VLMs) are receiving growing focus. However, VLMs remain brittle on allocentric spatial queries that require explicit perspective shifts, where the answer depends on reasoning in a target-centric frame rather than the observed camera view. Thus, we introduce Allocentric Perceiver, a training-free strategy that recovers metric 3D states from one or more images with off-the-shelf geometric experts, and then instantiates a query-conditioned allocentric reference frame aligned with the instruction's semantic intent. By deterministically transforming reconstructed geometry into the target frame and prompting the backbone VLM with structured, geometry-grounded representations, Allocentric Perceriver offloads mental rotation from implicit reasoning to explicit computation. We evaluate Allocentric Perciver across multiple backbone families on spatial reasoning benchmarks, observing consistent and substantial gains ($\sim$10%) on allocentric tasks while maintaining strong egocentric performance, and surpassing both spatial-perception-finetuned models and state-of-the-art open-source and proprietary models.
Axe: A Simple Unified Layout Abstraction for Machine Learning Compilers
Jan 27, 2026Scaling modern deep learning workloads demands coordinated placement of data and compute across device meshes, memory hierarchies, and heterogeneous accelerators. We present Axe Layout, a hardware-aware abstraction that maps logical tensor coordinates to a multi-axis physical space via named axes. Axe unifies tiling, sharding, replication, and offsets across inter-device distribution and on-device layouts, enabling collective primitives to be expressed consistently from device meshes to threads. Building on Axe, we design a multi-granularity, distribution-aware DSL and compiler that composes thread-local control with collective operators in a single kernel. Experiments show that our unified approach can bring performance close to hand-tuned kernels on across latest GPU devices and multi-device environments and accelerator backends.
XGrammar 2: Dynamic and Efficient Structured Generation Engine for Agentic LLMs
Jan 07, 2026Modern LLM agents are required to handle increasingly complex structured generation tasks, such as tool calling and conditional structured generation. These tasks are significantly more dynamic than predefined structures, posing new challenges to the current structured generation engines. In this paper, we propose XGrammar 2, a highly optimized structured generation engine for agentic LLMs. XGrammar 2 accelerates the mask generation for these dynamic structured generation tasks through a new dynamic dispatching semantics: TagDispatch. We further introduce a just-in-time (JIT) compilation method to reduce compilation time and a cross-grammar caching mechanism to leverage the common sub-structures across different grammars. Additionally, we extend the previous PDA-based mask generation algorithm to the Earley-parser-based one and design a repetition compression algorithm to handle repetition structures in grammars. Evaluation results show that XGrammar 2 can achieve more than 6x speedup over the existing structured generation engines. Integrated with an LLM inference engine, XGrammar 2 can handle dynamic structured generation tasks with near-zero overhead.
FreeText: Training-Free Text Rendering in Diffusion Transformers via Attention Localization and Spectral Glyph Injection
Jan 02, 2026Large-scale text-to-image (T2I) diffusion models excel at open-domain synthesis but still struggle with precise text rendering, especially for multi-line layouts, dense typography, and long-tailed scripts such as Chinese. Prior solutions typically require costly retraining or rigid external layout constraints, which can degrade aesthetics and limit flexibility. We propose \textbf{FreeText}, a training-free, plug-and-play framework that improves text rendering by exploiting intrinsic mechanisms of \emph{Diffusion Transformer (DiT)} models. \textbf{FreeText} decomposes the problem into \emph{where to write} and \emph{what to write}. For \emph{where to write}, we localize writing regions by reading token-wise spatial attribution from endogenous image-to-text attention, using sink-like tokens as stable spatial anchors and topology-aware refinement to produce high-confidence masks. For \emph{what to write}, we introduce Spectral-Modulated Glyph Injection (SGMI), which injects a noise-aligned glyph prior with frequency-domain band-pass modulation to strengthen glyph structure and suppress semantic leakage (rendering the concept instead of the word). Extensive experiments on Qwen-Image, FLUX.1-dev, and SD3 variants across longText-Benchmark, CVTG, and our CLT-Bench show consistent gains in text readability while largely preserving semantic alignment and aesthetic quality, with modest inference overhead.
AuthSig: Safeguarding Scanned Signatures Against Unauthorized Reuse in Paperless Workflows
Nov 12, 2025With the deepening trend of paperless workflows, signatures as a means of identity authentication are gradually shifting from traditional ink-on-paper to electronic formats.Despite the availability of dynamic pressure-sensitive and PKI-based digital signatures, static scanned signatures remain prevalent in practice due to their convenience. However, these static images, having almost lost their authentication attributes, cannot be reliably verified and are vulnerable to malicious copying and reuse. To address these issues, we propose AuthSig, a novel static electronic signature framework based on generative models and watermark, which binds authentication information to the signature image. Leveraging the human visual system's insensitivity to subtle style variations, AuthSig finely modulates style embeddings during generation to implicitly encode watermark bits-enforcing a One Signature, One Use policy.To overcome the scarcity of handwritten signature data and the limitations of traditional augmentation methods, we introduce a keypoint-driven data augmentation strategy that effectively enhances style diversity to support robust watermark embedding. Experimental results show that AuthSig achieves over 98% extraction accuracy under both digital-domain distortions and signature-specific degradations, and remains effective even in print-scan scenarios.
Autoregressive Image Generation Guided by Chains of Thought
Feb 26, 2025In the field of autoregressive (AR) image generation, models based on the 'next-token prediction' paradigm of LLMs have shown comparable performance to diffusion models by reducing inductive biases. However, directly applying LLMs to complex image generation can struggle with reconstructing the structure and details of the image, impacting the accuracy and stability of generation. Additionally, the 'next-token prediction' paradigm in the AR model does not align with the contextual scanning and logical reasoning processes involved in human visual perception, limiting effective image generation. Chain-of-Thought (CoT), as a key reasoning capability of LLMs, utilizes reasoning prompts to guide the model, improving reasoning performance on complex natural language process (NLP) tasks, enhancing accuracy and stability of generation, and helping the model maintain contextual coherence and logical consistency, similar to human reasoning. Inspired by CoT from the field of NLP, we propose autoregressive Image Generation with Thoughtful Reasoning (IGTR) to enhance autoregressive image generation. IGTR adds reasoning prompts without modifying the model structure or raster generation order. Specifically, we design specialized image-related reasoning prompts for AR image generation to simulate the human reasoning process, which enhances contextual reasoning by allowing the model to first perceive overall distribution information before generating the image, and improve generation stability by increasing the inference steps. Compared to the AR method without prompts, our method shows outstanding performance and achieves an approximate improvement of 20%.
HeadText: Exploring Hands-free Text Entry using Head Gestures by Motion Sensing on a Smart Earpiece
May 23, 2022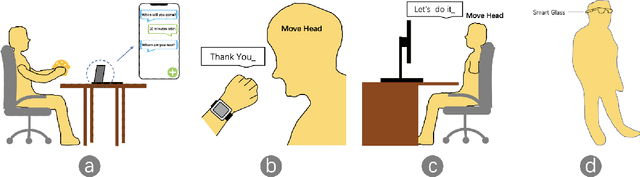
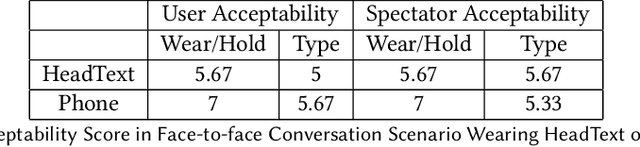
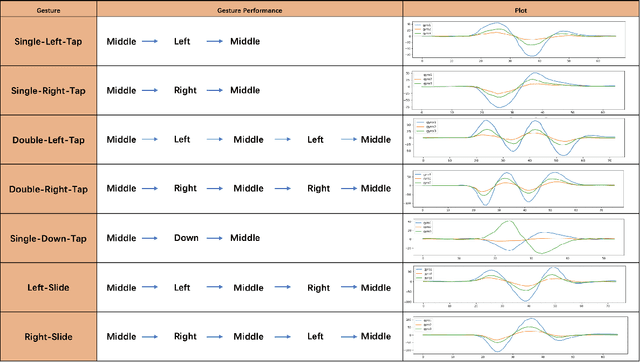
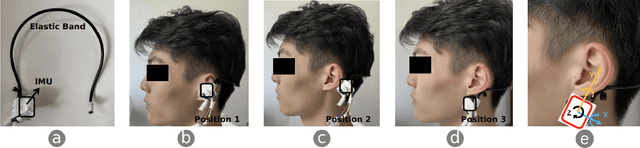
We present HeadText, a hands-free technique on a smart earpiece for text entry by motion sensing. Users input text utilizing only 7 head gestures for key selection, word selection, word commitment and word cancelling tasks. Head gesture recognition is supported by motion sensing on a smart earpiece to capture head moving signals and machine learning algorithms (K-Nearest-Neighbor (KNN) with a Dynamic Time Warping (DTW) distance measurement). A 10-participant user study proved that HeadText could recognize 7 head gestures at an accuracy of 94.29%. After that, the second user study presented that HeadText could achieve a maximum accuracy of 10.65 WPM and an average accuracy of 9.84 WPM for text entry. Finally, we demonstrate potential applications of HeadText in hands-free scenarios for (a). text entry of people with motor impairments, (b). private text entry, and (c). socially acceptable text entry.