 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Exhaustive Correlation for Spectral Super-Resolution: Where Unified Spatial-Spectral Attention Meets Mutual Linear Dependence
Dec 20, 2023Spectral super-resolution from the easily obtainable RGB image to hyperspectral image (HSI) has drawn increasing interest in the field of computational photography. The crucial aspect of spectral super-resolution lies in exploiting the correlation within HSIs. However, two types of bottlenecks in existing Transformers limit performance improvement and practical applications. First, existing Transformers often separately emphasize either spatial-wise or spectral-wise correlation, disrupting the 3D features of HSI and hindering the exploitation of unified spatial-spectral correlation. Second, the existing self-attention mechanism learns the correlation between pairs of tokens and captures the full-rank correlation matrix, leading to its inability to establish mutual linear dependence among multiple tokens. To address these issues, we propose a novel Exhaustive Correlation Transformer (ECT) for spectral super-resolution. First, we propose a Spectral-wise Discontinuous 3D (SD3D) splitting strategy, which models unified spatial-spectral correlation by simultaneously utilizing spatial-wise continuous splitting and spectral-wise discontinuous splitting. Second, we propose a Dynamic Low-Rank Mapping (DLRM) model, which captures mutual linear dependence among multiple tokens through a dynamically calculated low-rank dependence map. By integrating unified spatial-spectral attention with mutual linear dependence, our ECT can establish exhaustive correlation within HSI. The experimental results on both simulated and real data indicate that our method achieves state-of-the-art performance. Codes and pretrained models will be available later.
All Languages Matter: On the Multilingual Safety of Large Language Models
Oct 02, 2023Safety lies at the core of developing and deploying large language models (LLMs). However, previous safety benchmarks only concern the safety in one language, e.g. the majority language in the pretraining data such as English. In this work, we build the first multilingual safety benchmark for LLMs, XSafety, in response to the global deployment of LLMs in practice. XSafety covers 14 kinds of commonly used safety issues across 10 languages that span several language families. We utilize XSafety to empirically study the multilingual safety for 4 widely-used LLMs, including both close-API and open-source models. Experimental results show that all LLMs produce significantly more unsafe responses for non-English queries than English ones, indicating the necessity of developing safety alignment for non-English languages. In addition, we propose several simple and effective prompting methods to improve the multilingual safety of ChatGPT by evoking safety knowledge and improving cross-lingual generalization of safety alignment. Our prompting method can significantly reduce the ratio of unsafe responses from 19.1% to 9.7% for non-English queries. We release our data at https://github.com/Jarviswang94/Multilingual_safety_benchmark.
An Image is Worth a Thousand Toxic Words: A Metamorphic Testing Framework for Content Moderation Software
Aug 18, 2023



The exponential growth of social media platforms has brought about a revolution in communication and content dissemination in human society. Nevertheless, these platforms are being increasingly misused to spread toxic content, including hate speech, malicious advertising, and pornography, leading to severe negative consequences such as harm to teenagers' mental health. Despite tremendous efforts in developing and deploying textual and image content moderation methods, malicious users can evade moderation by embedding texts into images, such as screenshots of the text, usually with some interference. We find that modern content moderation software's performance against such malicious inputs remains underexplored. In this work, we propose OASIS, a metamorphic testing framework for content moderation software. OASIS employs 21 transform rules summarized from our pilot study on 5,000 real-world toxic contents collected from 4 popular social media applications, including Twitter, Instagram, Sina Weibo, and Baidu Tieba. Given toxic textual contents, OASIS can generate image test cases, which preserve the toxicity yet are likely to bypass moderation. In the evaluation, we employ OASIS to test five commercial textual content moderation software from famous companies (i.e., Google Cloud, Microsoft Azure, Baidu Cloud, Alibaba Cloud and Tencent Cloud), as well as a state-of-the-art moderation research model. The results show that OASIS achieves up to 100% error finding rates. Moreover, through retraining the models with the test cases generated by OASIS, the robustness of the moderation model can be improved without performance degradation.
Validating Multimedia Content Moderation Software via Semantic Fusion
May 23, 2023The exponential growth of social media platforms, such as Facebook and TikTok, has revolutionized communication and content publication in human society. Users on these platforms can publish multimedia content that delivers information via the combination of text, audio, images, and video. Meanwhile, the multimedia content release facility has been increasingly exploited to propagate toxic content, such as hate speech, malicious advertisements, and pornography. To this end, content moderation software has been widely deployed on these platforms to detect and blocks toxic content. However, due to the complexity of content moderation models and the difficulty of understanding information across multiple modalities, existing content moderation software can fail to detect toxic content, which often leads to extremely negative impacts. We introduce Semantic Fusion, a general, effective methodology for validating multimedia content moderation software. Our key idea is to fuse two or more existing single-modal inputs (e.g., a textual sentence and an image) into a new input that combines the semantics of its ancestors in a novel manner and has toxic nature by construction. This fused input is then used for validating multimedia content moderation software. We realized Semantic Fusion as DUO, a practical content moderation software testing tool. In our evaluation, we employ DUO to test five commercial content moderation software and two state-of-the-art models against three kinds of toxic content. The results show that DUO achieves up to 100% error finding rate (EFR) when testing moderation software. In addition, we leverage the test cases generated by DUO to retrain the two models we explored, which largely improves model robustness while maintaining the accuracy on the original test set.
Toward DNN of LUTs: Learning Efficient Image Restoration with Multiple Look-Up Tables
Mar 25, 2023



The widespread usage of high-definition screens on edge devices stimulates a strong demand for efficient image restoration algorithms. The way of caching deep learning models in a look-up table (LUT) is recently introduced to respond to this demand. However, the size of a single LUT grows exponentially with the increase of its indexing capacity, which restricts its receptive field and thus the performance. To overcome this intrinsic limitation of the single-LUT solution, we propose a universal method to construct multiple LUTs like a neural network, termed MuLUT. Firstly, we devise novel complementary indexing patterns, as well as a general implementation for arbitrary patterns, to construct multiple LUTs in parallel. Secondly, we propose a re-indexing mechanism to enable hierarchical indexing between cascaded LUTs. Finally, we introduce channel indexing to allow cross-channel interaction, enabling LUTs to process color channels jointly. In these principled ways, the total size of MuLUT is linear to its indexing capacity, yielding a practical solution to obtain superior performance with the enlarged receptive field. We examine the advantage of MuLUT on various image restoration tasks, including super-resolution, demosaicing, denoising, and deblocking. MuLUT achieves a significant improvement over the single-LUT solution, e.g., up to 1.1dB PSNR for super-resolution and up to 2.8dB PSNR for grayscale denoising, while preserving its efficiency, which is 100$\times$ less in energy cost compared with lightweight deep neural networks. Our code and trained models are publicly available at https://github.com/ddlee-cn/MuLUT.
TA-MoE: Topology-Aware Large Scale Mixture-of-Expert Training
Feb 20, 2023Sparsely gated Mixture-of-Expert (MoE) has demonstrated its effectiveness in scaling up deep neural networks to an extreme scale. Despite that numerous efforts have been made to improve the performance of MoE from the model design or system optimization perspective, existing MoE dispatch patterns are still not able to fully exploit the underlying heterogeneous network environments. In this paper, we propose TA-MoE, a topology-aware routing strategy for large-scale MoE trainging, from a model-system co-design perspective, which can dynamically adjust the MoE dispatch pattern according to the network topology. Based on communication modeling, we abstract the dispatch problem into an optimization objective and obtain the approximate dispatch pattern under different topologies. On top of that, we design a topology-aware auxiliary loss, which can adaptively route the data to fit in the underlying topology without sacrificing the model accuracy. Experiments show that TA-MoE can substantially outperform its counterparts on various hardware and model configurations, with roughly 1.01x-1.61x, 1.01x-4.77x, 1.25x-1.54x improvements over the popular DeepSpeed-MoE, FastMoE and FasterMoE.
GARF:Geometry-Aware Generalized Neural Radiance Field
Dec 07, 2022



Neural Radiance Field (NeRF) has revolutionized free viewpoint rendering tasks and achieved impressive results. However, the efficiency and accuracy problems hinder its wide applications. To address these issues, we propose Geometry-Aware Generalized Neural Radiance Field (GARF) with a geometry-aware dynamic sampling (GADS) strategy to perform real-time novel view rendering and unsupervised depth estimation on unseen scenes without per-scene optimization. Distinct from most existing generalized NeRFs, our framework infers the unseen scenes on both pixel-scale and geometry-scale with only a few input images. More specifically, our method learns common attributes of novel-view synthesis by an encoder-decoder structure and a point-level learnable multi-view feature fusion module which helps avoid occlusion. To preserve scene characteristics in the generalized model, we introduce an unsupervised depth estimation module to derive the coarse geometry, narrow down the ray sampling interval to proximity space of the estimated surface and sample in expectation maximum position, constituting Geometry-Aware Dynamic Sampling strategy (GADS). Moreover, we introduce a Multi-level Semantic Consistency loss (MSC) to assist more informative representation learning. Extensive experiments on indoor and outdoor datasets show that comparing with state-of-the-art generalized NeRF methods, GARF reduces samples by more than 25\%, while improving rendering quality and 3D geometry estimation.
Towards Real World HDRTV Reconstruction: A Data Synthesis-based Approach
Nov 06, 2022Existing deep learning based HDRTV reconstruction methods assume one kind of tone mapping operators (TMOs) as the degradation procedure to synthesize SDRTV-HDRTV pairs for supervised training. In this paper, we argue that, although traditional TMOs exploit efficient dynamic range compression priors, they have several drawbacks on modeling the realistic degradation: information over-preservation, color bias and possible artifacts, making the trained reconstruction networks hard to generalize well to real-world cases. To solve this problem, we propose a learning-based data synthesis approach to learn the properties of real-world SDRTVs by integrating several tone mapping priors into both network structures and loss functions. In specific, we design a conditioned two-stream network with prior tone mapping results as a guidance to synthesize SDRTVs by both global and local transformations. To train the data synthesis network, we form a novel self-supervised content loss to constraint different aspects of the synthesized SDRTVs at regions with different brightness distributions and an adversarial loss to emphasize the details to be more realistic. To validate the effectiveness of our approach, we synthesize SDRTV-HDRTV pairs with our method and use them to train several HDRTV reconstruction networks. Then we collect two inference datasets containing both labeled and unlabeled real-world SDRTVs, respectively. Experimental results demonstrate that, the networks trained with our synthesized data generalize significantly better to these two real-world datasets than existing solutions.
Reversed Image Signal Processing and RAW Reconstruction. AIM 2022 Challenge Report
Oct 20, 2022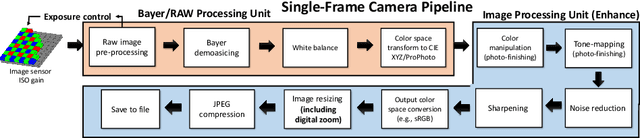
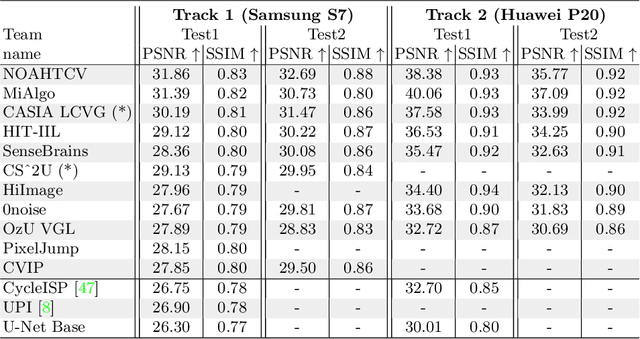
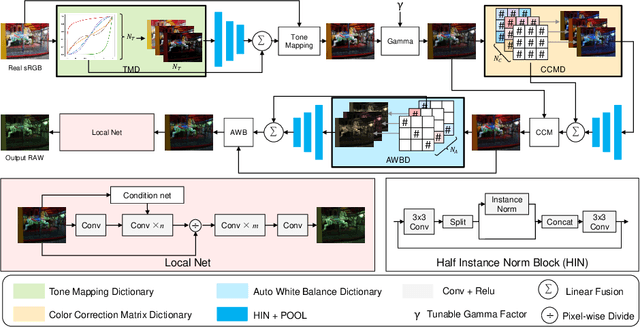
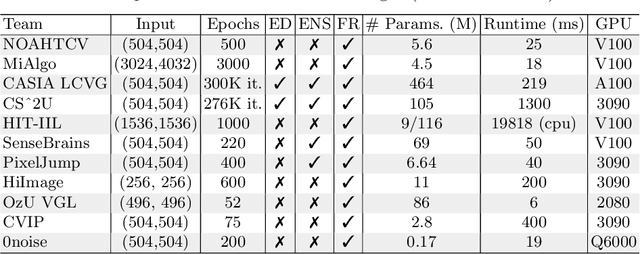
Cameras capture sensor RAW images and transform them into pleasant RGB images, suitable for the human eyes, using their integrated Image Signal Processor (ISP). Numerous low-level vision tasks operate in the RAW domain (e.g. image denoising, white balance) due to its linear relationship with the scene irradiance, wide-range of information at 12bits, and sensor designs. Despite this, RAW image datasets are scarce and more expensive to collect than the already large and public RGB datasets. This paper introduces the AIM 2022 Challenge on Reversed Image Signal Processing and RAW Reconstruction. We aim to recover raw sensor images from the corresponding RGBs without metadata and, by doing this, "reverse" the ISP transformation. The proposed methods and benchmark establish the state-of-the-art for this low-level vision inverse problem, and generating realistic raw sensor readings can potentially benefit other tasks such as denoising and super-resolution.
Trans4Map: Revisiting Holistic Top-down Mapping from Egocentric Images to Allocentric Semantics with Vision Transformers
Jul 13, 2022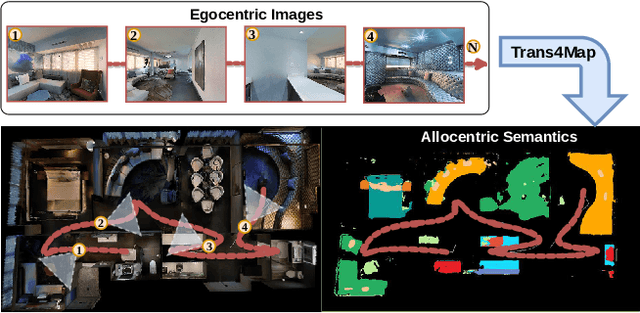
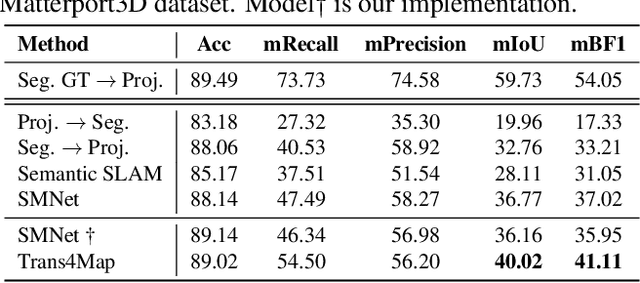
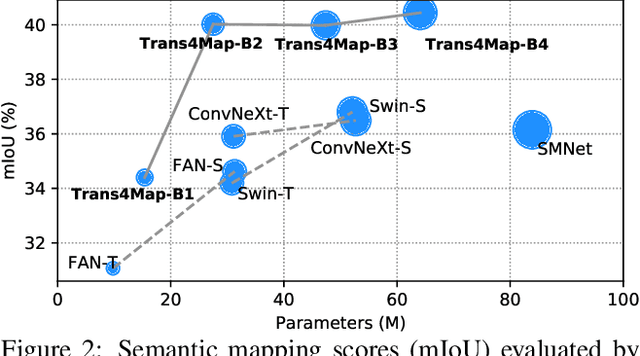
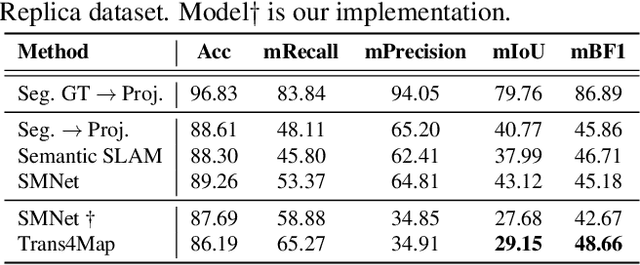
Humans have an innate ability to sense their surroundings, as they can extract the spatial representation from the egocentric perception and form an allocentric semantic map via spatial transformation and memory updating. However, endowing mobile agents with such a spatial sensing ability is still a challenge, due to two difficulties: (1) the previous convolutional models are limited by the local receptive field, thus, struggling to capture holistic long-range dependencies during observation; (2) the excessive computational budgets required for success, often lead to a separation of the mapping pipeline into stages, resulting the entire mapping process inefficient. To address these issues, we propose an end-to-end one-stage Transformer-based framework for Mapping, termed Trans4Map. Our egocentric-to-allocentric mapping process includes three steps: (1) the efficient transformer extracts the contextual features from a batch of egocentric images; (2) the proposed Bidirectional Allocentric Memory (BAM) module projects egocentric features into the allocentric memory; (3) the map decoder parses the accumulated memory and predicts the top-down semantic segmentation map. In contrast, Trans4Map achieves state-of-the-art results, reducing 67.2% parameters, yet gaining a +3.25% mIoU and a +4.09% mBF1 improvements on the Matterport3D dataset. Code will be made publicly available at https://github.com/jamycheung/Trans4Map.