 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAFEVPR: Patch-Based Conformal Verification for Safe Cross-Condition Sequence Visual Place Recognition
May 27, 2026Sequence-based visual place recognition (VPR) for SLAM and robot relocalization must decide whether the retrieved top-1 candidate is safe to accept. Conformal prediction is a natural framework for this accept/reject decision, but its finite-sample guarantees rely on exchangeability between calibration and deployment (test) data, which is violated under cross-condition deployment. We introduce SAFEVPR, a non-trainable verification-and-calibration pipeline for safe cross-condition sequence VPR. SAFEVPR replaces the standard backbone cosine similarity with a mutual-nearest-neighbour (MNN) patch-matching score computed from frozen DINOv2 ViT features, and replaces flat Learn-Then-Test calibration with Mondrian conformal LTT, fitting separate Bonferroni-corrected thresholds across score bins. Under exchangeability, these thresholds would provide finite-sample false-discovery-rate (FDR) control; under condition shift, we evaluate empirical validity per deployment. Across 23 cross-condition setups from Oxford RobotCar, NCLT, and St Lucia datasets, using three frozen VPR backbones, SAFEVPR is empirically valid on 23/23 setups at target FDR alpha = 0.10, achieving mean accepted FDR 0.014 and mean true-positive rate (TPR) 0.75. The results show that raw discrimination alone is not sufficient for conformal validity: AnyLoc-VLAD and Super-Point+LightGlue reach comparable area under the receiver operating characteristic curve (AUROC) but fail more setups under the same calibration. On textureless repetitive scenery, SAFEVPR safely abstains rather than accepting unreliable matches. Code is available at https://github.com/Hasar12139/SafeVPR.
Scalable Dexterous Robot Learning with AR-based Remote Human-Robot Interactions
Feb 07, 2026This paper focuses on the scalable robot learning for manipulation in the dexterous robot arm-hand systems, where the remote human-robot interactions via augmented reality (AR) are established to collect the expert demonstration data for improving efficiency. In such a system, we present a unified framework to address the general manipulation task problem. Specifically, the proposed method consists of two phases: i) In the first phase for pretraining, the policy is created in a behavior cloning (BC) manner, through leveraging the learning data from our AR-based remote human-robot interaction system; ii) In the second phase, a contrastive learning empowered reinforcement learning (RL) method is developed to obtain more efficient and robust policy than the BC, and thus a projection head is designed to accelerate the learning progress. An event-driven augmented reward is adopted for enhancing the safety. To validate the proposed method, both the physics simulations via PyBullet and real-world experiments are carried out. The results demonstrate that compared to the classic proximal policy optimization and soft actor-critic policies, our method not only significantly speeds up the inference, but also achieves much better performance in terms of the success rate for fulfilling the manipulation tasks. By conducting the ablation study, it is confirmed that the proposed RL with contrastive learning overcomes policy collapse. Supplementary demonstrations are available at https://cyberyyc.github.io/.
A Sensor-Aware Phenomenological Framework for Lidar Degradation Simulation and SLAM Robustness Evaluation
Dec 09, 2025



Lidar-based SLAM systems are highly sensitive to adverse conditions such as occlusion, noise, and field-of-view (FoV) degradation, yet existing robustness evaluation methods either lack physical grounding or do not capture sensor-specific behavior. This paper presents a sensor-aware, phenomenological framework for simulating interpretable lidar degradations directly on real point clouds, enabling controlled and reproducible SLAM stress testing. Unlike image-derived corruption benchmarks (e.g., SemanticKITTI-C) or simulation-only approaches (e.g., lidarsim), the proposed system preserves per-point geometry, intensity, and temporal structure while applying structured dropout, FoV reduction, Gaussian noise, occlusion masking, sparsification, and motion distortion. The framework features autonomous topic and sensor detection, modular configuration with four severity tiers (light--extreme), and real-time performance (less than 20 ms per frame) compatible with ROS workflows. Experimental validation across three lidar architectures and five state-of-the-art SLAM systems reveals distinct robustness patterns shaped by sensor design and environmental context. The open-source implementation provides a practical foundation for benchmarking lidar-based SLAM under physically meaningful degradation scenarios.
EventDiff: A Unified and Efficient Diffusion Model Framework for Event-based Video Frame Interpolation
May 13, 2025



Video Frame Interpolation (VFI) is a fundamental yet challenging task in computer vision, particularly under conditions involving large motion, occlusion, and lighting variation. Recent advancements in event cameras have opened up new opportunities for addressing these challenges. While existing event-based VFI methods have succeeded in recovering large and complex motions by leveraging handcrafted intermediate representations such as optical flow, these designs often compromise high-fidelity image reconstruction under subtle motion scenarios due to their reliance on explicit motion modeling. Meanwhile, diffusion models provide a promising alternative for VFI by reconstructing frames through a denoising process, eliminating the need for explicit motion estimation or warping operations. In this work, we propose EventDiff, a unified and efficient event-based diffusion model framework for VFI. EventDiff features a novel Event-Frame Hybrid AutoEncoder (HAE) equipped with a lightweight Spatial-Temporal Cross Attention (STCA) module that effectively fuses dynamic event streams with static frames. Unlike previous event-based VFI methods, EventDiff performs interpolation directly in the latent space via a denoising diffusion process, making it more robust across diverse and challenging VFI scenarios. Through a two-stage training strategy that first pretrains the HAE and then jointly optimizes it with the diffusion model, our method achieves state-of-the-art performance across multiple synthetic and real-world event VFI datasets. The proposed method outperforms existing state-of-the-art event-based VFI methods by up to 1.98dB in PSNR on Vimeo90K-Triplet and shows superior performance in SNU-FILM tasks with multiple difficulty levels. Compared to the emerging diffusion-based VFI approach, our method achieves up to 5.72dB PSNR gain on Vimeo90K-Triplet and 4.24X faster inference.
Event-Based Eye Tracking. 2025 Event-based Vision Workshop
Apr 25, 2025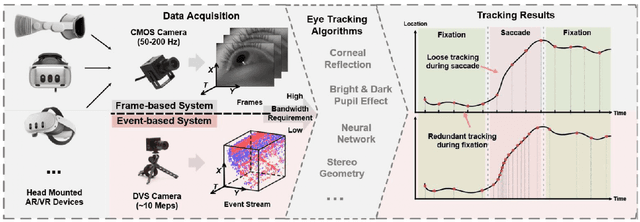
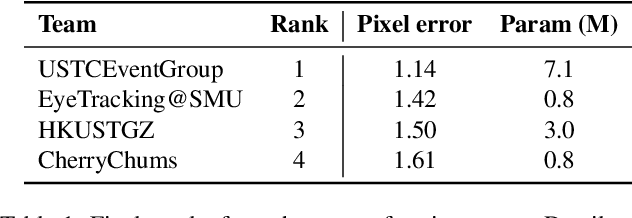
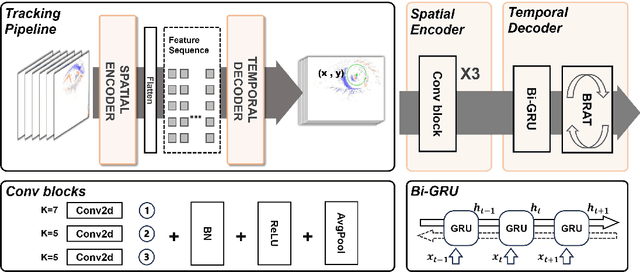

This survey serves as a review for the 2025 Event-Based Eye Tracking Challenge organized as part of the 2025 CVPR event-based vision workshop. This challenge focuses on the task of predicting the pupil center by processing event camera recorded eye movement. We review and summarize the innovative methods from teams rank the top in the challenge to advance future event-based eye tracking research. In each method, accuracy, model size, and number of operations are reported. In this survey, we also discuss event-based eye tracking from the perspective of hardware design.
UAV Tracking with Lidar as a Camera Sensors in GNSS-Denied Environments
Mar 01, 2023LiDAR has become one of the primary sensors in robotics and autonomous system for high-accuracy situational awareness. In recent years, multi-modal LiDAR systems emerged, and among them, LiDAR-as-a-camera sensors provide not only 3D point clouds but also fixed-resolution 360{\deg}panoramic images by encoding either depth, reflectivity, or near-infrared light in the image pixels. This potentially brings computer vision capabilities on top of the potential of LiDAR itself. In this paper, we are specifically interested in utilizing LiDARs and LiDAR-generated images for tracking Unmanned Aerial Vehicles (UAVs) in real-time which can benefit applications including docking, remote identification, or counter-UAV systems, among others. This is, to the best of our knowledge, the first work that explores the possibility of fusing the images and point cloud generated by a single LiDAR sensor to track a UAV without a priori known initialized position. We trained a custom YOLOv5 model for detecting UAVs based on the panoramic images collected in an indoor experiment arena with a MOCAP system. By integrating with the point cloud, we are able to continuously provide the position of the UAV. Our experiment demonstrated the effectiveness of the proposed UAV tracking approach compared with methods based only on point clouds or images. Additionally, we evaluated the real-time performance of our approach on the Nvidia Jetson Nano, a popular mobile computing platform.
A Benchmark for Multi-Modal Lidar SLAM with Ground Truth in GNSS-Denied Environments
Oct 03, 2022


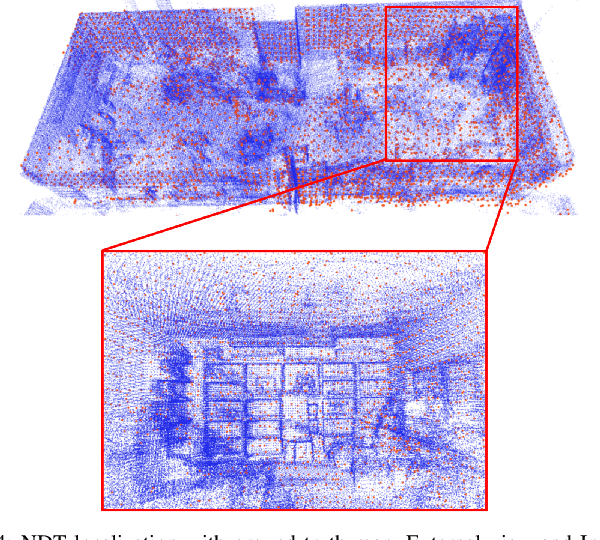
Lidar-based simultaneous localization and mapping (SLAM) approaches have obtained considerable success in autonomous robotic systems. This is in part owing to the high-accuracy of robust SLAM algorithms and the emergence of new and lower-cost lidar products. This study benchmarks current state-of-the-art lidar SLAM algorithms with a multi-modal lidar sensor setup showcasing diverse scanning modalities (spinning and solid-state) and sensing technologies, and lidar cameras, mounted on a mobile sensing and computing platform. We extend our previous multi-modal multi-lidar dataset with additional sequences and new sources of ground truth data. Specifically, we propose a new multi-modal multi-lidar SLAM-assisted and ICP-based sensor fusion method for generating ground truth maps. With these maps, we then match real-time pointcloud data using a natural distribution transform (NDT) method to obtain the ground truth with full 6 DOF pose estimation. This novel ground truth data leverages high-resolution spinning and solid-state lidars. We also include new open road sequences with GNSS-RTK data and additional indoor sequences with motion capture (MOCAP) ground truth, complementing the previous forest sequences with MOCAP data. We perform an analysis of the positioning accuracy achieved with ten different SLAM algorithm and lidar combinations. We also report the resource utilization in four different computational platforms and a total of five settings (Intel and Jetson ARM CPUs). Our experimental results show that current state-of-the-art lidar SLAM algorithms perform very differently for different types of sensors. More results, code, and the dataset can be found at: \href{https://github.com/TIERS/tiers-lidars-dataset-enhanced}{github.com/TIERS/tiers-lidars-dataset-enhanced.
Multi Sensor Fusion for Navigation and Mapping in Autonomous Vehicles: Accurate Localization in Urban Environments
Mar 25, 2021

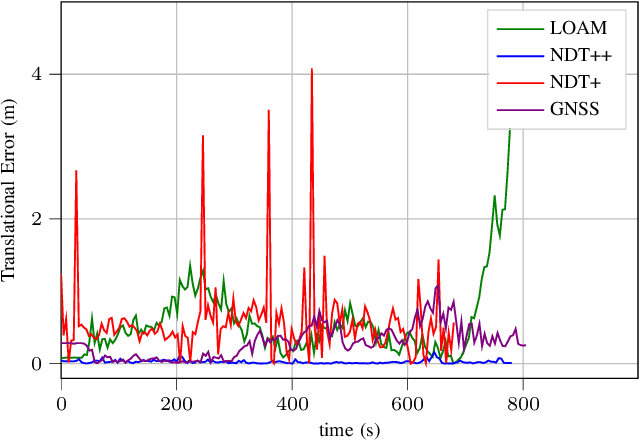
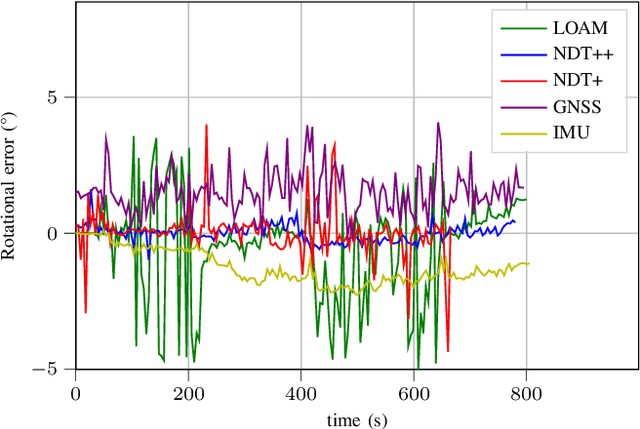
The combination of data from multiple sensors, also known as sensor fusion or data fusion, is a key aspect in the design of autonomous robots. In particular, algorithms able to accommodate sensor fusion techniques enable increased accuracy, and are more resilient against the malfunction of individual sensors. The development of algorithms for autonomous navigation, mapping and localization have seen big advancements over the past two decades. Nonetheless, challenges remain in developing robust solutions for accurate localization in dense urban environments, where the so called last-mile delivery occurs. In these scenarios, local motion estimation is combined with the matching of real-time data with a detailed pre-built map. In this paper, we utilize data gathered with an autonomous delivery robot to compare different sensor fusion techniques and evaluate which are the algorithms providing the highest accuracy depending on the environment. The techniques we analyze and propose in this paper utilize 3D lidar data, inertial data, GNSS data and wheel encoder readings. We show how lidar scan matching combined with other sensor data can be used to increase the accuracy of the robot localization and, in consequence, its navigation. Moreover, we propose a strategy to reduce the impact on navigation performance when a change in the environment renders map data invalid or part of the available map is corrupted.
UWB-Based Localization for Multi-UAV Systems and Collaborative Heterogeneous Multi-Robot Systems: a Survey
Apr 28, 2020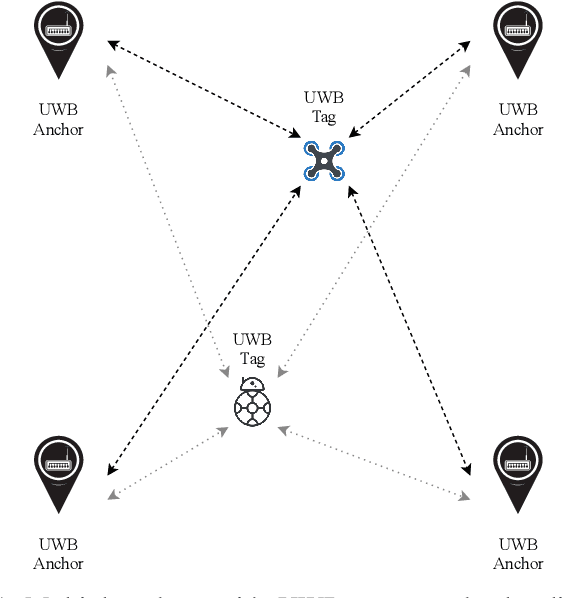
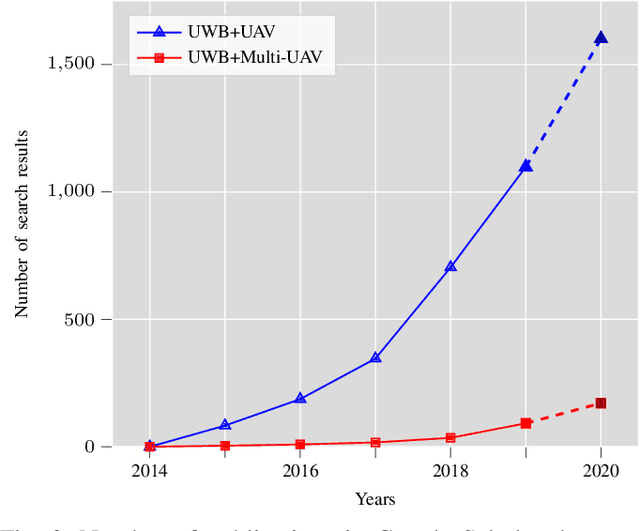
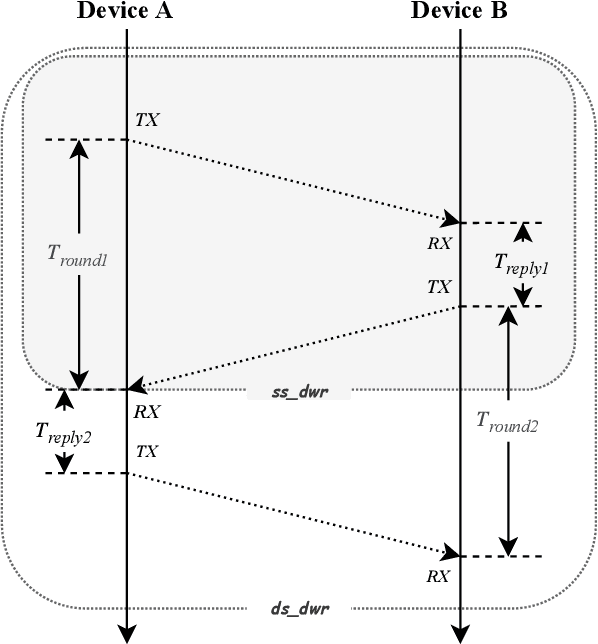
Ultra-wideband technology has emerged in recent years as a robust solution for localization in GNSS denied environments. In particular, its high accuracy when compared to other wireless localization solutions is enabling a wider range of collaborative and multi-robot application scenarios, being able to replace more complex and expensive motion-capture areas for use cases where accuracy in the order of tens of centimeters is sufficient. We present the first survey of UWB-based localization focused on multi-UAV systems and heterogeneous multi-robot systems. We have found that previous literature reviews do not consider in-depth the challenges in both aerial navigation and navigation with multiple robots, but also in terms of heterogeneous multi-robot systems. In particular, this is, to the best of our knowledge, the first survey to review recent advances in UWB-based (i) methods that enable ad-hoc and dynamic deployments; (ii) collaborative localization techniques; and (iii) cooperative sensing and cooperative maneuvers such as UAV docking on mobile platforms. Finally, we also review existing datasets and discuss the potential of this technology for both localization in GNSS-denied environments and collaboration in multi-robot systems.