 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEveLoad: Cognitive Workload Recognition from Event-Based Eye Movements
Jun 23, 2026Cognitive workload monitoring is important for adaptive rehabilitation and assistive interfaces, where task difficulty, pacing, and feedback should be adjusted according to the user's cognitive state to avoid overload and under-challenge. Emerging extended reality and robot-assisted rehabilitation environments provide controllable training tasks, but they require unobtrusive sensing methods that can capture rapid ocular dynamics during interaction. Existing eye-movement-based cognitive workload recognition methods mainly rely on frame-based eye trackers, which often suffer from limited temporal resolution and degraded robustness under rapid eye movements. In contrast, event cameras provide microsecond-level temporal resolution, high dynamic range and low latency, making them suitable for capturing fine-grained ocular dynamics. Many previous studies rely on free-viewing or similar paradigms, where gaze locations can vary across tasks. As a result, models may learn associations between gaze-location distributions and cognitive workload, rather than workload-related eye movement characteristics themselves. In this work, we introduce EveLoad, which, to the best of our knowledge, is the first event-based eye-movement dataset with graded cognitive workload annotations, collected from 20 healthy participants under spatially constrained and task-driven conditions using a controlled N-back-guided fixation paradigm. Based on this dataset, we establish a benchmark for cognitive workload recognition with six workload levels and propose a learning framework that encodes spatiotemporal event representations. Experimental results show that our approach achieves an average subject-specific accuracy of 96.36% and 96.13% under mixed random split evaluation. These results suggest that event-based eye movements may provide a useful sensing pathway for future workload-aware rehabilitation.
When NPUs Are Not Always Faster: A Stage-Level Analysis of Mobile LLM Inference
May 22, 2026Deploying large language models (LLMs) on mobile devices increasingly relies on heterogeneous execution, yet no prior study has systematically characterized NPU effectiveness at the operator and pipeline level. We present the first stage-aware, multi-level benchmarking study of mobile LLM inference on a CPU-NPU heterogeneous SoC. We introduce an OPMASK-based controlled pipeline decomposition methodology that isolates communication, quantization, and computation overheads within the NPU execution path. Our results reveal a counter-intuitive stage-level performance reversal: CPUs outperform NPUs in the compute-intensive Prefill stage (up to 1.6x), while NPUs provide only limited acceleration in the memory-bound Decode stage (1.05-1.2x). We further show that scheduling overhead and cross-backend fallback reduce the practical benefits of NPU offloading. For the energy trend, increasing NPU offloading leads to higher energy consumption (up to 51%). Based on these findings, we derive design guidelines for NPU architects targeting on-device LLM inference.
Vib2ECG: A Paired Chest-Lead SCG-ECG Dataset and Benchmark for ECG Reconstruction
Mar 16, 2026Twelve-lead electrocardiography (ECG) is essential for cardiovascular diagnosis, but its long-term acquisition in daily life is constrained by complex and costly hardware. Recent efforts have explored reconstructing ECG from low-cost cardiac vibrational signals such as seismocardiography (SCG), however, due to the lack of a dataset, current methods are limited to limb leads, while clinical diagnosis requires multi-lead ECG, including chest leads. In this work, we propose Vib2ECG, the first paired, multi-channel electro-mechanical cardiac signal dataset, which includes complete twelve-lead ECGs and vibrational signals acquired by inertial measurement units (IMUs) at six chest-lead positions from 17 subjects. Based on this dataset, we also provide a benchmark. Experimental results demonstrate the feasibility of reconstructing electrical cardiac signals at variable locations from vibrational signals using a lightweight 364 K-parameter U-Net. Furthermore, we observe a hallucination phenomenon in the model, where ECG waveforms are generated in regions where no corresponding electrical activity is present. We analyze the causes of this phenomenon and propose potential directions for mitigation. This study demonstrates the feasibility of mobile-device-friendly ECG monitoring through chest-lead ECG prediction from low-cost vibrational signals acquired using IMU sensors. It expands the application of cardiac vibrational signals and provides new insights into the spatial relationship between cardiac electrical and mechanical activities with spatial location variation.
Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models
Jan 12, 2026While Mixture-of-Experts (MoE) scales capacity via conditional computation, Transformers lack a native primitive for knowledge lookup, forcing them to inefficiently simulate retrieval through computation. To address this, we introduce conditional memory as a complementary sparsity axis, instantiated via Engram, a module that modernizes classic $N$-gram embedding for O(1) lookup. By formulating the Sparsity Allocation problem, we uncover a U-shaped scaling law that optimizes the trade-off between neural computation (MoE) and static memory (Engram). Guided by this law, we scale Engram to 27B parameters, achieving superior performance over a strictly iso-parameter and iso-FLOPs MoE baseline. Most notably, while the memory module is expected to aid knowledge retrieval (e.g., MMLU +3.4; CMMLU +4.0), we observe even larger gains in general reasoning (e.g., BBH +5.0; ARC-Challenge +3.7) and code/math domains~(HumanEval +3.0; MATH +2.4). Mechanistic analyses reveal that Engram relieves the backbone's early layers from static reconstruction, effectively deepening the network for complex reasoning. Furthermore, by delegating local dependencies to lookups, it frees up attention capacity for global context, substantially boosting long-context retrieval (e.g., Multi-Query NIAH: 84.2 to 97.0). Finally, Engram establishes infrastructure-aware efficiency: its deterministic addressing enables runtime prefetching from host memory, incurring negligible overhead. We envision conditional memory as an indispensable modeling primitive for next-generation sparse models.
EvHand-FPV: Efficient Event-Based 3D Hand Tracking from First-Person View
Sep 17, 2025Hand tracking holds great promise for intuitive interaction paradigms, but frame-based methods often struggle to meet the requirements of accuracy, low latency, and energy efficiency, especially in resource-constrained settings such as Extended Reality (XR) devices. Event cameras provide $\mu$s-level temporal resolution at mW-level power by asynchronously sensing brightness changes. In this work, we present EvHand-FPV, a lightweight framework for egocentric First-Person-View 3D hand tracking from a single event camera. We construct an event-based FPV dataset that couples synthetic training data with 3D labels and real event data with 2D labels for evaluation to address the scarcity of egocentric benchmarks. EvHand-FPV also introduces a wrist-based region of interest (ROI) that localizes the hand region via geometric cues, combined with an end-to-end mapping strategy that embeds ROI offsets into the network to reduce computation without explicit reconstruction, and a multi-task learning strategy with an auxiliary geometric feature head that improves representations without test-time overhead. On our real FPV test set, EvHand-FPV improves 2D-AUCp from 0.77 to 0.85 while reducing parameters from 11.2M to 1.2M by 89% and FLOPs per inference from 1.648G to 0.185G by 89%. It also maintains a competitive 3D-AUCp of 0.84 on synthetic data. These results demonstrate accurate and efficient egocentric event-based hand tracking suitable for on-device XR applications. The dataset and code are available at https://github.com/zen5x5/EvHand-FPV.
TCN-DPD: Parameter-Efficient Temporal Convolutional Networks for Wideband Digital Predistortion
Jun 13, 2025Digital predistortion (DPD) is essential for mitigating nonlinearity in RF power amplifiers, particularly for wideband applications. This paper presents TCN-DPD, a parameter-efficient architecture based on temporal convolutional networks, integrating noncausal dilated convolutions with optimized activation functions. Evaluated on the OpenDPD framework with the DPA_200MHz dataset, TCN-DPD achieves simulated ACPRs of -51.58/-49.26 dBc (L/R), EVM of -47.52 dB, and NMSE of -44.61 dB with 500 parameters and maintains superior linearization than prior models down to 200 parameters, making it promising for efficient wideband PA linearization.
AS-ASR: A Lightweight Framework for Aphasia-Specific Automatic Speech Recognition
Jun 06, 2025This paper proposes AS-ASR, a lightweight aphasia-specific speech recognition framework based on Whisper-tiny, tailored for low-resource deployment on edge devices. Our approach introduces a hybrid training strategy that systematically combines standard and aphasic speech at varying ratios, enabling robust generalization, and a GPT-4-based reference enhancement method that refines noisy aphasic transcripts, improving supervision quality. We conduct extensive experiments across multiple data mixing configurations and evaluation settings. Results show that our fine-tuned model significantly outperforms the zero-shot baseline, reducing WER on aphasic speech by over 30% while preserving performance on standard speech. The proposed framework offers a scalable, efficient solution for real-world disordered speech recognition.
Event-Based Eye Tracking. 2025 Event-based Vision Workshop
Apr 25, 2025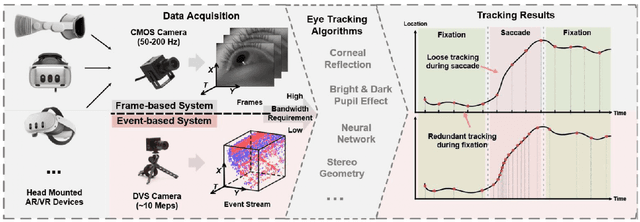
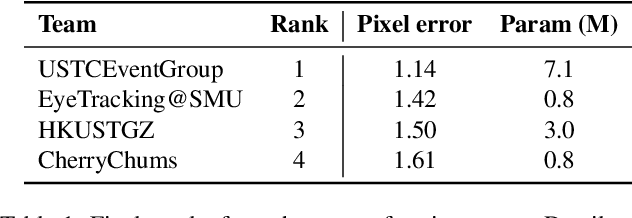
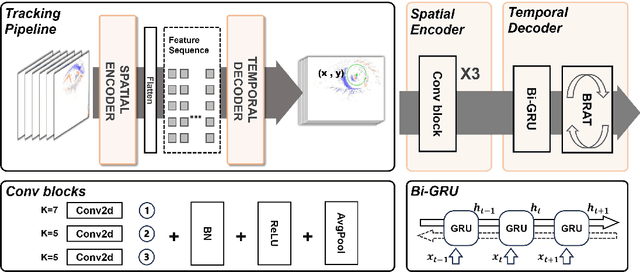

This survey serves as a review for the 2025 Event-Based Eye Tracking Challenge organized as part of the 2025 CVPR event-based vision workshop. This challenge focuses on the task of predicting the pupil center by processing event camera recorded eye movement. We review and summarize the innovative methods from teams rank the top in the challenge to advance future event-based eye tracking research. In each method, accuracy, model size, and number of operations are reported. In this survey, we also discuss event-based eye tracking from the perspective of hardware design.
DeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
DPD-NeuralEngine: A 22-nm 6.6-TOPS/W/mm$^2$ Recurrent Neural Network Accelerator for Wideband Power Amplifier Digital Pre-Distortion
Oct 15, 2024



The increasing adoption of Deep Neural Network (DNN)-based Digital Pre-distortion (DPD) in modern communication systems necessitates efficient hardware implementations. This paper presents DPD-NeuralEngine, an ultra-fast, tiny-area, and power-efficient DPD accelerator based on a Gated Recurrent Unit (GRU) neural network (NN). Leveraging a co-designed software and hardware approach, our 22 nm CMOS implementation operates at 2 GHz, capable of processing I/Q signals up to 250 MSps. Experimental results demonstrate a throughput of 256.5 GOPS and power efficiency of 1.32 TOPS/W with DPD linearization performance measured in Adjacent Channel Power Ratio (ACPR) of -45.3 dBc and Error Vector Magnitude (EVM) of -39.8 dB. To our knowledge, this work represents the first AI-based DPD application-specific integrated circuit (ASIC) accelerator, achieving a power-area efficiency (PAE) of 6.6 TOPS/W/mm$^2$.