 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChi-Square Wavelet Graph Neural Networks for Heterogeneous Graph Anomaly Detection
May 25, 2025



Graph Anomaly Detection (GAD) in heterogeneous networks presents unique challenges due to node and edge heterogeneity. Existing Graph Neural Network (GNN) methods primarily focus on homogeneous GAD and thus fail to address three key issues: (C1) Capturing abnormal signal and rich semantics across diverse meta-paths; (C2) Retaining high-frequency content in HIN dimension alignment; and (C3) Learning effectively from difficult anomaly samples with class imbalance. To overcome these, we propose ChiGAD, a spectral GNN framework based on a novel Chi-Square filter, inspired by the wavelet effectiveness in diverse domains. Specifically, ChiGAD consists of: (1) Multi-Graph Chi-Square Filter, which captures anomalous information via applying dedicated Chi-Square filters to each meta-path graph; (2) Interactive Meta-Graph Convolution, which aligns features while preserving high-frequency information and incorporates heterogeneous messages by a unified Chi-Square Filter; and (3) Contribution-Informed Cross-Entropy Loss, which prioritizes difficult anomalies to address class imbalance. Extensive experiments on public and industrial datasets show that ChiGAD outperforms state-of-the-art models on multiple metrics. Additionally, its homogeneous variant, ChiGNN, excels on seven GAD datasets, validating the effectiveness of Chi-Square filters. Our code is available at https://github.com/HsipingLi/ChiGAD.
CAS-IQA: Teaching Vision-Language Models for Synthetic Angiography Quality Assessment
May 23, 2025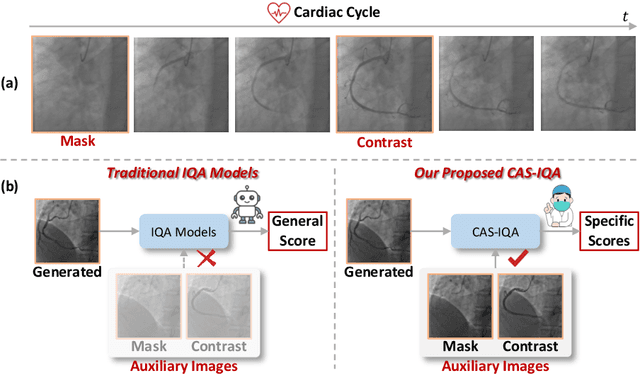
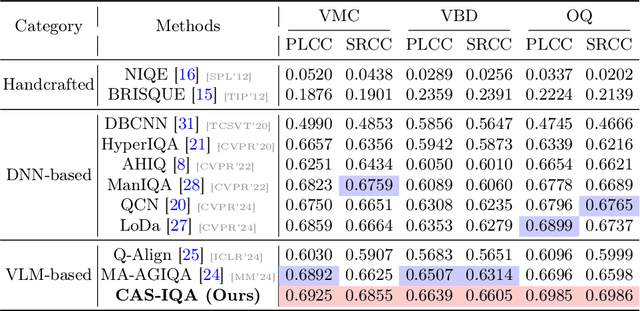
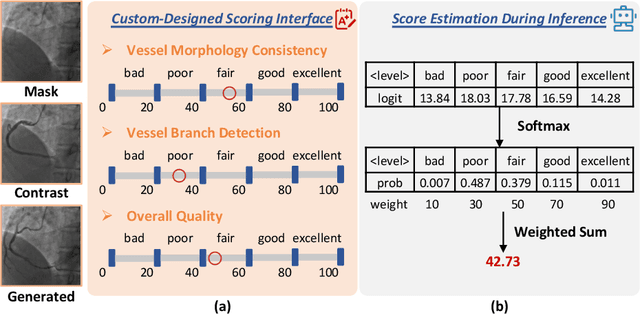

Synthetic X-ray angiographies generated by modern generative models hold great potential to reduce the use of contrast agents in vascular interventional procedures. However, low-quality synthetic angiographies can significantly increase procedural risk, underscoring the need for reliable image quality assessment (IQA) methods. Existing IQA models, however, fail to leverage auxiliary images as references during evaluation and lack fine-grained, task-specific metrics necessary for clinical relevance. To address these limitations, this paper proposes CAS-IQA, a vision-language model (VLM)-based framework that predicts fine-grained quality scores by effectively incorporating auxiliary information from related images. In the absence of angiography datasets, CAS-3K is constructed, comprising 3,565 synthetic angiographies along with score annotations. To ensure clinically meaningful assessment, three task-specific evaluation metrics are defined. Furthermore, a Multi-path featUre fuSion and rouTing (MUST) module is designed to enhance image representations by adaptively fusing and routing visual tokens to metric-specific branches. Extensive experiments on the CAS-3K dataset demonstrate that CAS-IQA significantly outperforms state-of-the-art IQA methods by a considerable margin.
SSR: Speculative Parallel Scaling Reasoning in Test-time
May 21, 2025Large language models (LLMs) have achieved impressive results on multi-step mathematical reasoning, yet at the cost of high computational overhead. This challenge is particularly acute for test-time scaling methods such as parallel decoding, which increase answer diversity but scale poorly in efficiency. To address this efficiency-accuracy trade-off, we propose SSR (Speculative Parallel Scaling Reasoning), a training-free framework that leverages a key insight: by introducing speculative decoding at the step level, we can accelerate reasoning without sacrificing correctness. SSR integrates two components: a Selective Parallel Module (SPM) that identifies a small set of promising reasoning strategies via model-internal scoring, and Step-level Speculative Decoding (SSD), which enables efficient draft-target collaboration for fine-grained reasoning acceleration. Experiments on three mathematical benchmarks-AIME 2024, MATH-500, and LiveMathBench - demonstrate that SSR achieves strong gains over baselines. For instance, on LiveMathBench, SSR improves pass@1 accuracy by 13.84% while reducing computation to 80.5% of the baseline FLOPs. On MATH-500, SSR reduces compute to only 30% with no loss in accuracy.
STORYANCHORS: Generating Consistent Multi-Scene Story Frames for Long-Form Narratives
May 13, 2025This paper introduces StoryAnchors, a unified framework for generating high-quality, multi-scene story frames with strong temporal consistency. The framework employs a bidirectional story generator that integrates both past and future contexts to ensure temporal consistency, character continuity, and smooth scene transitions throughout the narrative. Specific conditions are introduced to distinguish story frame generation from standard video synthesis, facilitating greater scene diversity and enhancing narrative richness. To further improve generation quality, StoryAnchors integrates Multi-Event Story Frame Labeling and Progressive Story Frame Training, enabling the model to capture both overarching narrative flow and event-level dynamics. This approach supports the creation of editable and expandable story frames, allowing for manual modifications and the generation of longer, more complex sequences. Extensive experiments show that StoryAnchors outperforms existing open-source models in key areas such as consistency, narrative coherence, and scene diversity. Its performance in narrative consistency and story richness is also on par with GPT-4o. Ultimately, StoryAnchors pushes the boundaries of story-driven frame generation, offering a scalable, flexible, and highly editable foundation for future research.
Canny2Palm: Realistic and Controllable Palmprint Generation for Large-scale Pre-training
May 08, 2025Palmprint recognition is a secure and privacy-friendly method of biometric identification. One of the major challenges to improve palmprint recognition accuracy is the scarcity of palmprint data. Recently, a popular line of research revolves around the synthesis of virtual palmprints for large-scale pre-training purposes. In this paper, we propose a novel synthesis method named Canny2Palm that extracts palm textures with Canny edge detector and uses them to condition a Pix2Pix network for realistic palmprint generation. By re-assembling palmprint textures from different identities, we are able to create new identities by seeding the generator with new assemblies. Canny2Palm not only synthesizes realistic data following the distribution of real palmprints but also enables controllable diversity to generate large-scale new identities. On open-set palmprint recognition benchmarks, models pre-trained with Canny2Palm synthetic data outperform the state-of-the-art with up to 7.2% higher identification accuracy. Moreover, the performance of models pre-trained with Canny2Palm continues to improve given 10,000 synthetic IDs while those with existing methods already saturate, demonstrating the potential of our method for large-scale pre-training.
Pangu Ultra MoE: How to Train Your Big MoE on Ascend NPUs
May 07, 2025



Sparse large language models (LLMs) with Mixture of Experts (MoE) and close to a trillion parameters are dominating the realm of most capable language models. However, the massive model scale poses significant challenges for the underlying software and hardware systems. In this paper, we aim to uncover a recipe to harness such scale on Ascend NPUs. The key goals are better usage of the computing resources under the dynamic sparse model structures and materializing the expected performance gain on the actual hardware. To select model configurations suitable for Ascend NPUs without repeatedly running the expensive experiments, we leverage simulation to compare the trade-off of various model hyperparameters. This study led to Pangu Ultra MoE, a sparse LLM with 718 billion parameters, and we conducted experiments on the model to verify the simulation results. On the system side, we dig into Expert Parallelism to optimize the communication between NPU devices to reduce the synchronization overhead. We also optimize the memory efficiency within the devices to further reduce the parameter and activation management overhead. In the end, we achieve an MFU of 30.0% when training Pangu Ultra MoE, with performance comparable to that of DeepSeek R1, on 6K Ascend NPUs, and demonstrate that the Ascend system is capable of harnessing all the training stages of the state-of-the-art language models. Extensive experiments indicate that our recipe can lead to efficient training of large-scale sparse language models with MoE. We also study the behaviors of such models for future reference.
DualRAG: A Dual-Process Approach to Integrate Reasoning and Retrieval for Multi-Hop Question Answering
Apr 25, 2025Multi-Hop Question Answering (MHQA) tasks permeate real-world applications, posing challenges in orchestrating multi-step reasoning across diverse knowledge domains. While existing approaches have been improved with iterative retrieval, they still struggle to identify and organize dynamic knowledge. To address this, we propose DualRAG, a synergistic dual-process framework that seamlessly integrates reasoning and retrieval. DualRAG operates through two tightly coupled processes: Reasoning-augmented Querying (RaQ) and progressive Knowledge Aggregation (pKA). They work in concert: as RaQ navigates the reasoning path and generates targeted queries, pKA ensures that newly acquired knowledge is systematically integrated to support coherent reasoning. This creates a virtuous cycle of knowledge enrichment and reasoning refinement. Through targeted fine-tuning, DualRAG preserves its sophisticated reasoning and retrieval capabilities even in smaller-scale models, demonstrating its versatility and core advantages across different scales. Extensive experiments demonstrate that this dual-process approach substantially improves answer accuracy and coherence, approaching, and in some cases surpassing, the performance achieved with oracle knowledge access. These results establish DualRAG as a robust and efficient solution for complex multi-hop reasoning tasks.
On-Device Qwen2.5: Efficient LLM Inference with Model Compression and Hardware Acceleration
Apr 24, 2025



Transformer-based Large Language Models (LLMs) have significantly advanced AI capabilities but pose considerable challenges for deployment on edge devices due to high computational demands, memory bandwidth constraints, and energy consumption. This paper addresses these challenges by presenting an efficient framework for deploying the Qwen2.5-0.5B model on the Xilinx Kria KV260 edge platform, a heterogeneous system integrating an ARM Cortex-A53 CPU with reconfigurable FPGA logic. Leveraging Activation-aware Weight Quantization (AWQ) with FPGA-accelerated execution pipelines, the proposed approach enhances both model compression rate and system throughput. Additionally, we propose a hybrid execution strategy that intelligently offloads compute-intensive operations to the FPGA while utilizing the CPU for lighter tasks, effectively balancing the computational workload and maximizing overall performance. Our framework achieves a model compression rate of 55.08% compared to the original model and produces output at a rate of 5.1 tokens per second, outperforming the baseline performance of 2.8 tokens per second.
SonarT165: A Large-scale Benchmark and STFTrack Framework for Acoustic Object Tracking
Apr 22, 2025



Underwater observation systems typically integrate optical cameras and imaging sonar systems. When underwater visibility is insufficient, only sonar systems can provide stable data, which necessitates exploration of the underwater acoustic object tracking (UAOT) task. Previous studies have explored traditional methods and Siamese networks for UAOT. However, the absence of a unified evaluation benchmark has significantly constrained the value of these methods. To alleviate this limitation, we propose the first large-scale UAOT benchmark, SonarT165, comprising 165 square sequences, 165 fan sequences, and 205K high-quality annotations. Experimental results demonstrate that SonarT165 reveals limitations in current state-of-the-art SOT trackers. To address these limitations, we propose STFTrack, an efficient framework for acoustic object tracking. It includes two novel modules, a multi-view template fusion module (MTFM) and an optimal trajectory correction module (OTCM). The MTFM module integrates multi-view feature of both the original image and the binary image of the dynamic template, and introduces a cross-attention-like layer to fuse the spatio-temporal target representations. The OTCM module introduces the acoustic-response-equivalent pixel property and proposes normalized pixel brightness response scores, thereby suppressing suboptimal matches caused by inaccurate Kalman filter prediction boxes. To further improve the model feature, STFTrack introduces a acoustic image enhancement method and a Frequency Enhancement Module (FEM) into its tracking pipeline. Comprehensive experiments show the proposed STFTrack achieves state-of-the-art performance on the proposed benchmark. The code is available at https://github.com/LiYunfengLYF/SonarT165.
Multi-scale DeepOnet (Mscale-DeepOnet) for Mitigating Spectral Bias in Learning High Frequency Operators of Oscillatory Functions
Apr 15, 2025



In this paper, a multi-scale DeepOnet (Mscale-DeepOnet) is proposed to reduce the spectral bias of the DeepOnet in learning high-frequency mapping between highly oscillatory functions, with an application to the nonlinear mapping between the coefficient of the Helmholtz equation and its solution. The Mscale-DeepOnet introduces the multiscale neural network in the branch and trunk networks of the original DeepOnet, the resulting Mscale-DeepOnet is shown to be able to capture various high-frequency components of the mapping itself and its image. Numerical results demonstrate the substantial improvement of the Mscale-DeepOnet for the problem of wave scattering in the high-frequency regime over the normal DeepOnet with a similar number of network parameters.