 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVulnLLM-R: Specialized Reasoning LLM with Agent Scaffold for Vulnerability Detection
Dec 08, 2025We propose VulnLLM-R, the~\emph{first specialized reasoning LLM} for vulnerability detection. Our key insight is that LLMs can reason about program states and analyze the potential vulnerabilities, rather than simple pattern matching. This can improve the model's generalizability and prevent learning shortcuts. However, SOTA reasoning LLMs are typically ultra-large, closed-source, or have limited performance in vulnerability detection. To address this, we propose a novel training recipe with specialized data selection, reasoning data generation, reasoning data filtering and correction, and testing-phase optimization. Using our proposed methodology, we train a reasoning model with seven billion parameters. Through extensive experiments on SOTA datasets across Python, C/C++, and Java, we show that VulnLLM-R has superior effectiveness and efficiency than SOTA static analysis tools and both open-source and commercial large reasoning models. We further conduct a detailed ablation study to validate the key designs in our training recipe. Finally, we construct an agent scaffold around our model and show that it outperforms CodeQL and AFL++ in real-world projects. Our agent further discovers a set of zero-day vulnerabilities in actively maintained repositories. This work represents a pioneering effort to enable real-world, project-level vulnerability detection using AI agents powered by specialized reasoning models. The code is available at~\href{https://github.com/ucsb-mlsec/VulnLLM-R}{github}.
Scaling Spatial Intelligence with Multimodal Foundation Models
Nov 17, 2025



Despite remarkable progress, multimodal foundation models still exhibit surprising deficiencies in spatial intelligence. In this work, we explore scaling up multimodal foundation models to cultivate spatial intelligence within the SenseNova-SI family, built upon established multimodal foundations including visual understanding models (i.e., Qwen3-VL and InternVL3) and unified understanding and generation models (i.e., Bagel). We take a principled approach to constructing high-performing and robust spatial intelligence by systematically curating SenseNova-SI-8M: eight million diverse data samples under a rigorous taxonomy of spatial capabilities. SenseNova-SI demonstrates unprecedented performance across a broad range of spatial intelligence benchmarks: 68.7% on VSI-Bench, 43.3% on MMSI, 85.6% on MindCube, 54.6% on ViewSpatial, and 50.1% on SITE, while maintaining strong general multimodal understanding (e.g., 84.9% on MMBench-En). More importantly, we analyze the impact of data scaling, discuss early signs of emergent generalization capabilities enabled by diverse data training, analyze the risk of overfitting and language shortcuts, present a preliminary study on spatial chain-of-thought reasoning, and validate the potential downstream application. SenseNova-SI is an ongoing project, and this report will be updated continuously. All newly trained multimodal foundation models are publicly released to facilitate further research in this direction.
Think, Speak, Decide: Language-Augmented Multi-Agent Reinforcement Learning for Economic Decision-Making
Nov 17, 2025



Economic decision-making depends not only on structured signals such as prices and taxes, but also on unstructured language, including peer dialogue and media narratives. While multi-agent reinforcement learning (MARL) has shown promise in optimizing economic decisions, it struggles with the semantic ambiguity and contextual richness of language. We propose LAMP (Language-Augmented Multi-Agent Policy), a framework that integrates language into economic decision-making and narrows the gap to real-world settings. LAMP follows a Think-Speak-Decide pipeline: (1) Think interprets numerical observations to extract short-term shocks and long-term trends, caching high-value reasoning trajectories; (2) Speak crafts and exchanges strategic messages based on reasoning, updating beliefs by parsing peer communications; and (3) Decide fuses numerical data, reasoning, and reflections into a MARL policy to optimize language-augmented decision-making. Experiments in economic simulation show that LAMP outperforms both MARL and LLM-only baselines in cumulative return (+63.5%, +34.0%), robustness (+18.8%, +59.4%), and interpretability. These results demonstrate the potential of language-augmented policies to deliver more effective and robust economic strategies.
MAT-MPNN: A Mobility-Aware Transformer-MPNN Model for Dynamic Spatiotemporal Prediction of HIV Diagnoses in California, Florida, and New England
Nov 17, 2025Human Immunodeficiency Virus (HIV) has posed a major global health challenge for decades, and forecasting HIV diagnoses continues to be a critical area of research. However, capturing the complex spatial and temporal dependencies of HIV transmission remains challenging. Conventional Message Passing Neural Network (MPNN) models rely on a fixed binary adjacency matrix that only encodes geographic adjacency, which is unable to represent interactions between non-contiguous counties. Our study proposes a deep learning architecture Mobility-Aware Transformer-Message Passing Neural Network (MAT-MPNN) framework to predict county-level HIV diagnosis rates across California, Florida, and the New England region. The model combines temporal features extracted by a Transformer encoder with spatial relationships captured through a Mobility Graph Generator (MGG). The MGG improves conventional adjacency matrices by combining geographic and demographic information. Compared with the best-performing hybrid baseline, the Transformer MPNN model, MAT-MPNN reduced the Mean Squared Prediction Error (MSPE) by 27.9% in Florida, 39.1% in California, and 12.5% in New England, and improved the Predictive Model Choice Criterion (PMCC) by 7.7%, 3.5%, and 3.9%, respectively. MAT-MPNN also achieved better results than the Spatially Varying Auto-Regressive (SVAR) model in Florida and New England, with comparable performance in California. These results demonstrate that applying mobility-aware dynamic spatial structures substantially enhances predictive accuracy and calibration in spatiotemporal epidemiological prediction.
Uncovering and Aligning Anomalous Attention Heads to Defend Against NLP Backdoor Attacks
Nov 16, 2025



Backdoor attacks pose a serious threat to the security of large language models (LLMs), causing them to exhibit anomalous behavior under specific trigger conditions. The design of backdoor triggers has evolved from fixed triggers to dynamic or implicit triggers. This increased flexibility in trigger design makes it challenging for defenders to identify their specific forms accurately. Most existing backdoor defense methods are limited to specific types of triggers or rely on an additional clean model for support. To address this issue, we propose a backdoor detection method based on attention similarity, enabling backdoor detection without prior knowledge of the trigger. Our study reveals that models subjected to backdoor attacks exhibit unusually high similarity among attention heads when exposed to triggers. Based on this observation, we propose an attention safety alignment approach combined with head-wise fine-tuning to rectify potentially contaminated attention heads, thereby effectively mitigating the impact of backdoor attacks. Extensive experimental results demonstrate that our method significantly reduces the success rate of backdoor attacks while preserving the model's performance on downstream tasks.
Language Drift in Multilingual Retrieval-Augmented Generation: Characterization and Decoding-Time Mitigation
Nov 13, 2025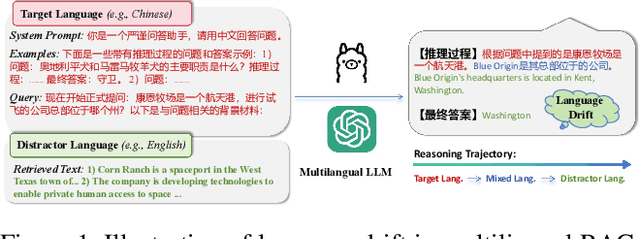
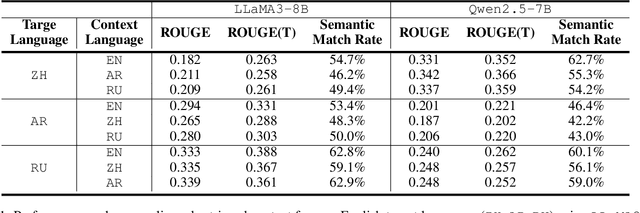
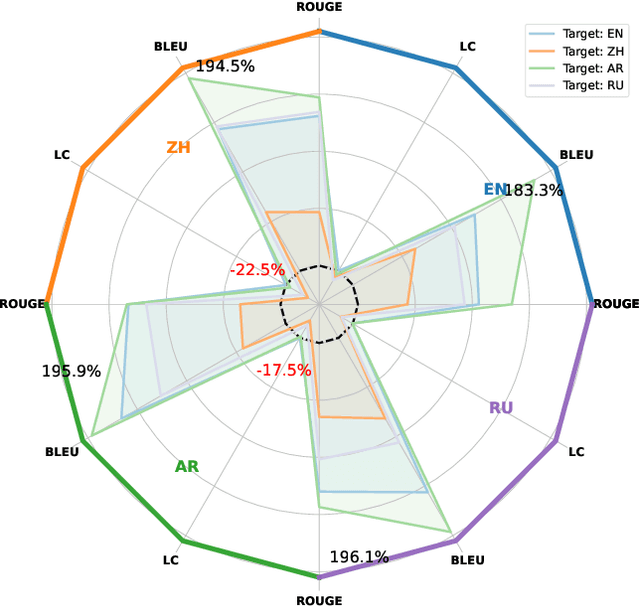
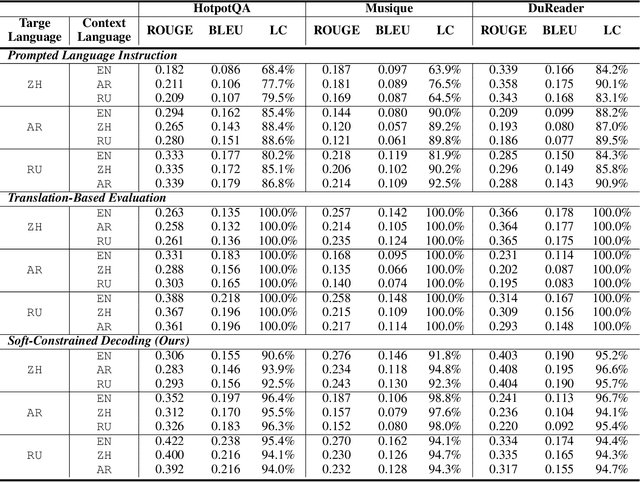
Multilingual Retrieval-Augmented Generation (RAG) enables large language models (LLMs) to perform knowledge-intensive tasks in multilingual settings by leveraging retrieved documents as external evidence. However, when the retrieved evidence differs in language from the user query and in-context exemplars, the model often exhibits language drift by generating responses in an unintended language. This phenomenon is especially pronounced during reasoning-intensive decoding, such as Chain-of-Thought (CoT) generation, where intermediate steps introduce further language instability. In this paper, we systematically study output language drift in multilingual RAG across multiple datasets, languages, and LLM backbones. Our controlled experiments reveal that the drift results not from comprehension failure but from decoder-level collapse, where dominant token distributions and high-frequency English patterns dominate the intended generation language. We further observe that English serves as a semantic attractor under cross-lingual conditions, emerging as both the strongest interference source and the most frequent fallback language. To mitigate this, we propose Soft Constrained Decoding (SCD), a lightweight, training-free decoding strategy that gently steers generation toward the target language by penalizing non-target-language tokens. SCD is model-agnostic and can be applied to any generation algorithm without modifying the architecture or requiring additional data. Experiments across three multilingual datasets and multiple typologically diverse languages show that SCD consistently improves language alignment and task performance, providing an effective and generalizable solution in multilingual RAG.
Modeling Uncertainty Trends for Timely Retrieval in Dynamic RAG
Nov 13, 2025Dynamic retrieval-augmented generation (RAG) allows large language models (LLMs) to fetch external knowledge on demand, offering greater adaptability than static RAG. A central challenge in this setting lies in determining the optimal timing for retrieval. Existing methods often trigger retrieval based on low token-level confidence, which may lead to delayed intervention after errors have already propagated. We introduce Entropy-Trend Constraint (ETC), a training-free method that determines optimal retrieval timing by modeling the dynamics of token-level uncertainty. Specifically, ETC utilizes first- and second-order differences of the entropy sequence to detect emerging uncertainty trends, enabling earlier and more precise retrieval. Experiments on six QA benchmarks with three LLM backbones demonstrate that ETC consistently outperforms strong baselines while reducing retrieval frequency. ETC is particularly effective in domain-specific scenarios, exhibiting robust generalization capabilities. Ablation studies and qualitative analyses further confirm that trend-aware uncertainty modeling yields more effective retrieval timing. The method is plug-and-play, model-agnostic, and readily integrable into existing decoding pipelines. Implementation code is included in the supplementary materials.
Scaling Agent Learning via Experience Synthesis
Nov 10, 2025



While reinforcement learning (RL) can empower autonomous agents by enabling self-improvement through interaction, its practical adoption remains challenging due to costly rollouts, limited task diversity, unreliable reward signals, and infrastructure complexity, all of which obstruct the collection of scalable experience data. To address these challenges, we introduce DreamGym, the first unified framework designed to synthesize diverse experiences with scalability in mind to enable effective online RL training for autonomous agents. Rather than relying on expensive real-environment rollouts, DreamGym distills environment dynamics into a reasoning-based experience model that derives consistent state transitions and feedback signals through step-by-step reasoning, enabling scalable agent rollout collection for RL. To improve the stability and quality of transitions, DreamGym leverages an experience replay buffer initialized with offline real-world data and continuously enriched with fresh interactions to actively support agent training. To improve knowledge acquisition, DreamGym adaptively generates new tasks that challenge the current agent policy, enabling more effective online curriculum learning. Experiments across diverse environments and agent backbones demonstrate that DreamGym substantially improves RL training, both in fully synthetic settings and in sim-to-real transfer scenarios. On non-RL-ready tasks like WebArena, DreamGym outperforms all baselines by over 30%. And in RL-ready but costly settings, it matches GRPO and PPO performance using only synthetic interactions. When transferring a policy trained purely on synthetic experiences to real-environment RL, DreamGym yields significant additional performance gains while requiring far fewer real-world interactions, providing a scalable warm-start strategy for general-purpose RL.
VMDT: Decoding the Trustworthiness of Video Foundation Models
Nov 07, 2025As foundation models become more sophisticated, ensuring their trustworthiness becomes increasingly critical; yet, unlike text and image, the video modality still lacks comprehensive trustworthiness benchmarks. We introduce VMDT (Video-Modal DecodingTrust), the first unified platform for evaluating text-to-video (T2V) and video-to-text (V2T) models across five key trustworthiness dimensions: safety, hallucination, fairness, privacy, and adversarial robustness. Through our extensive evaluation of 7 T2V models and 19 V2T models using VMDT, we uncover several significant insights. For instance, all open-source T2V models evaluated fail to recognize harmful queries and often generate harmful videos, while exhibiting higher levels of unfairness compared to image modality models. In V2T models, unfairness and privacy risks rise with scale, whereas hallucination and adversarial robustness improve -- though overall performance remains low. Uniquely, safety shows no correlation with model size, implying that factors other than scale govern current safety levels. Our findings highlight the urgent need for developing more robust and trustworthy video foundation models, and VMDT provides a systematic framework for measuring and tracking progress toward this goal. The code is available at https://sunblaze-ucb.github.io/VMDT-page/.
ArchPilot: A Proxy-Guided Multi-Agent Approach for Machine Learning Engineering
Nov 06, 2025Recent LLM-based agents have demonstrated strong capabilities in automated ML engineering. However, they heavily rely on repeated full training runs to evaluate candidate solutions, resulting in significant computational overhead, limited scalability to large search spaces, and slow iteration cycles. To address these challenges, we introduce ArchPilot, a multi-agent system that integrates architecture generation, proxy-based evaluation, and adaptive search into a unified framework. ArchPilot consists of three specialized agents: an orchestration agent that coordinates the search process using a Monte Carlo Tree Search (MCTS)-inspired novel algorithm with a restart mechanism and manages memory of previous candidates; a generation agent that iteratively generates, improves, and debugs candidate architectures; and an evaluation agent that executes proxy training runs, generates and optimizes proxy functions, and aggregates the proxy scores into a fidelity-aware performance metric. This multi-agent collaboration allows ArchPilot to prioritize high-potential candidates with minimal reliance on expensive full training runs, facilitating efficient ML engineering under limited budgets. Experiments on MLE-Bench demonstrate that ArchPilot outperforms SOTA baselines such as AIDE and ML-Master, validating the effectiveness of our multi-agent system.