 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRibSeg v2: A Large-scale Benchmark for Rib Labeling and Anatomical Centerline Extraction
Oct 18, 2022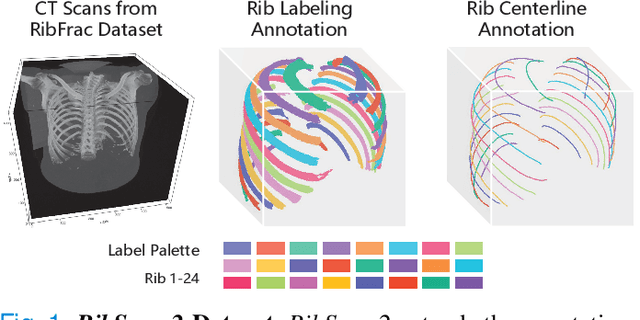

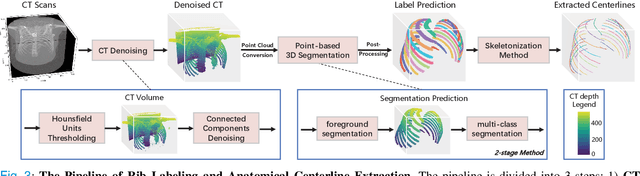
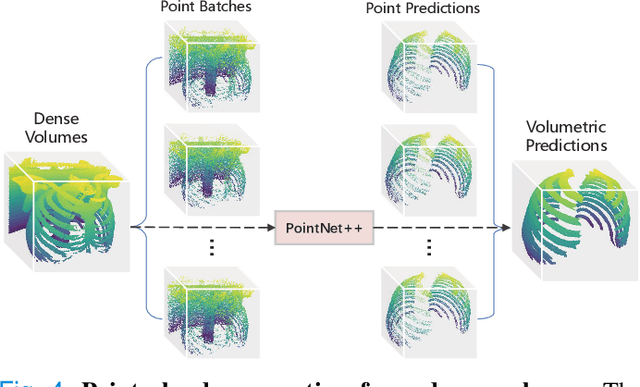
Automatic rib labeling and anatomical centerline extraction are common prerequisites for various clinical applications. Prior studies either use in-house datasets that are inaccessible to communities, or focus on rib segmentation that neglects the clinical significance of rib labeling. To address these issues, we extend our prior dataset (RibSeg) on the binary rib segmentation task to a comprehensive benchmark, named RibSeg v2, with 660 CT scans (15,466 individual ribs in total) and annotations manually inspected by experts for rib labeling and anatomical centerline extraction. Based on the RibSeg v2, we develop a pipeline including deep learning-based methods for rib labeling, and a skeletonization-based method for centerline extraction. To improve computational efficiency, we propose a sparse point cloud representation of CT scans and compare it with standard dense voxel grids. Moreover, we design and analyze evaluation metrics to address the key challenges of each task. Our dataset, code, and model are available online to facilitate open research at https://github.com/M3DV/RibSeg
Skeleton2Humanoid: Animating Simulated Characters for Physically-plausible Motion In-betweening
Oct 09, 2022
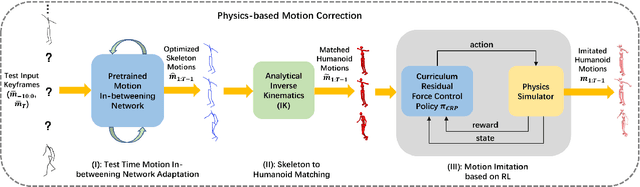

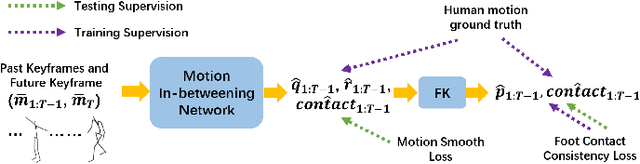
Human motion synthesis is a long-standing problem with various applications in digital twins and the Metaverse. However, modern deep learning based motion synthesis approaches barely consider the physical plausibility of synthesized motions and consequently they usually produce unrealistic human motions. In order to solve this problem, we propose a system ``Skeleton2Humanoid'' which performs physics-oriented motion correction at test time by regularizing synthesized skeleton motions in a physics simulator. Concretely, our system consists of three sequential stages: (I) test time motion synthesis network adaptation, (II) skeleton to humanoid matching and (III) motion imitation based on reinforcement learning (RL). Stage I introduces a test time adaptation strategy, which improves the physical plausibility of synthesized human skeleton motions by optimizing skeleton joint locations. Stage II performs an analytical inverse kinematics strategy, which converts the optimized human skeleton motions to humanoid robot motions in a physics simulator, then the converted humanoid robot motions can be served as reference motions for the RL policy to imitate. Stage III introduces a curriculum residual force control policy, which drives the humanoid robot to mimic complex converted reference motions in accordance with the physical law. We verify our system on a typical human motion synthesis task, motion-in-betweening. Experiments on the challenging LaFAN1 dataset show our system can outperform prior methods significantly in terms of both physical plausibility and accuracy. Code will be released for research purposes at: https://github.com/michaelliyunhao/Skeleton2Humanoid
Neural Annotation Refinement: Development of a New 3D Dataset for Adrenal Gland Analysis
Jul 08, 2022



The human annotations are imperfect, especially when produced by junior practitioners. Multi-expert consensus is usually regarded as golden standard, while this annotation protocol is too expensive to implement in many real-world projects. In this study, we propose a method to refine human annotation, named Neural Annotation Refinement (NeAR). It is based on a learnable implicit function, which decodes a latent vector into represented shape. By integrating the appearance as an input of implicit functions, the appearance-aware NeAR fixes the annotation artefacts. Our method is demonstrated on the application of adrenal gland analysis. We first show that the NeAR can repair distorted golden standards on a public adrenal gland segmentation dataset. Besides, we develop a new Adrenal gLand ANalysis (ALAN) dataset with the proposed NeAR, where each case consists of a 3D shape of adrenal gland and its diagnosis label (normal vs. abnormal) assigned by experts. We show that models trained on the shapes repaired by the NeAR can diagnose adrenal glands better than the original ones. The ALAN dataset will be open-source, with 1,584 shapes for adrenal gland diagnosis, which serves as a new benchmark for medical shape analysis. Code and dataset are available at https://github.com/M3DV/NeAR.
Differentiable Projection from Optical Coherence Tomography B-Scan without Retinal Layer Segmentation Supervision
Jun 11, 2022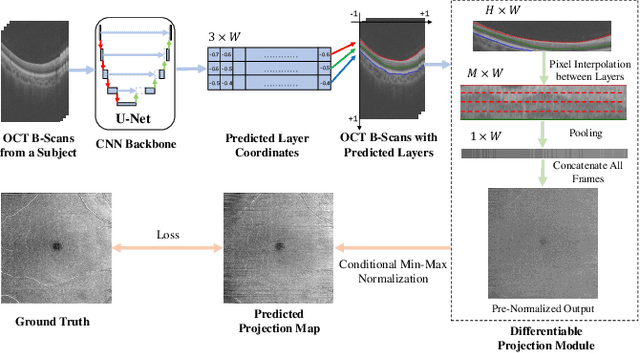
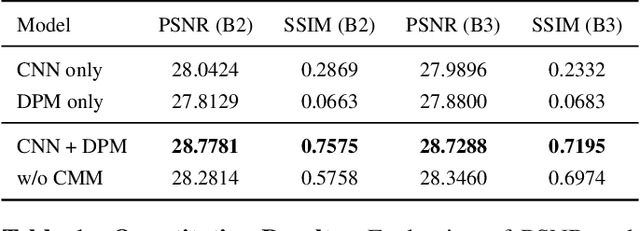

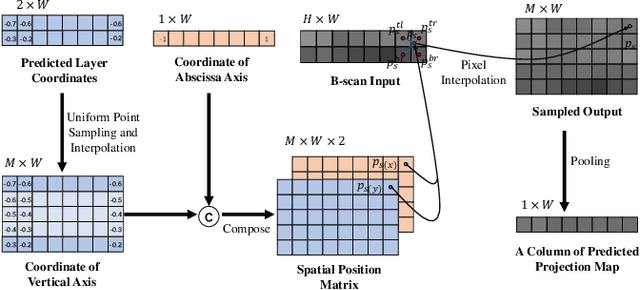
Projection map (PM) from optical coherence tomography (OCT) B-scan is an important tool to diagnose retinal diseases, which typically requires retinal layer segmentation. In this study, we present a novel end-to-end framework to predict PMs from B-scans. Instead of segmenting retinal layers explicitly, we represent them implicitly as predicted coordinates. By pixel interpolation on uniformly sampled coordinates between retinal layers, the corresponding PMs could be easily obtained with pooling. Notably, all the operators are differentiable; therefore, this Differentiable Projection Module (DPM) enables end-to-end training with the ground truth of PMs rather than retinal layer segmentation. Our framework produces high-quality PMs, significantly outperforming baselines, including a vanilla CNN without DPM and an optimization-based DPM without a deep prior. Furthermore, the proposed DPM, as a novel neural representation of areas/volumes between curves/surfaces, could be of independent interest for geometric deep learning.
HIRL: A General Framework for Hierarchical Image Representation Learning
May 26, 2022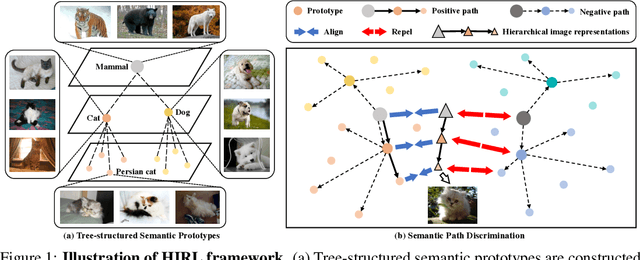
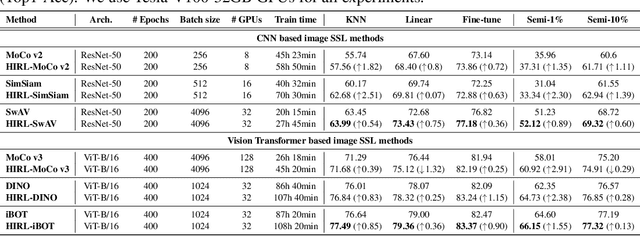


Learning self-supervised image representations has been broadly studied to boost various visual understanding tasks. Existing methods typically learn a single level of image semantics like pairwise semantic similarity or image clustering patterns. However, these methods can hardly capture multiple levels of semantic information that naturally exists in an image dataset, e.g., the semantic hierarchy of "Persian cat to cat to mammal" encoded in an image database for species. It is thus unknown whether an arbitrary image self-supervised learning (SSL) approach can benefit from learning such hierarchical semantics. To answer this question, we propose a general framework for Hierarchical Image Representation Learning (HIRL). This framework aims to learn multiple semantic representations for each image, and these representations are structured to encode image semantics from fine-grained to coarse-grained. Based on a probabilistic factorization, HIRL learns the most fine-grained semantics by an off-the-shelf image SSL approach and learns multiple coarse-grained semantics by a novel semantic path discrimination scheme. We adopt six representative image SSL methods as baselines and study how they perform under HIRL. By rigorous fair comparison, performance gain is observed on all the six methods for diverse downstream tasks, which, for the first time, verifies the general effectiveness of learning hierarchical image semantics. All source code and model weights are available at https://github.com/hirl-team/HIRL
Representation-Agnostic Shape Fields
Mar 19, 2022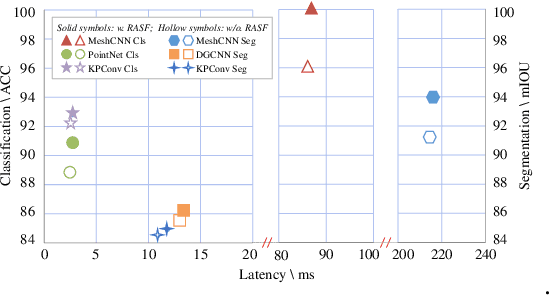
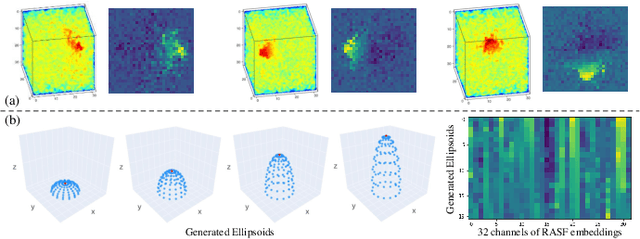
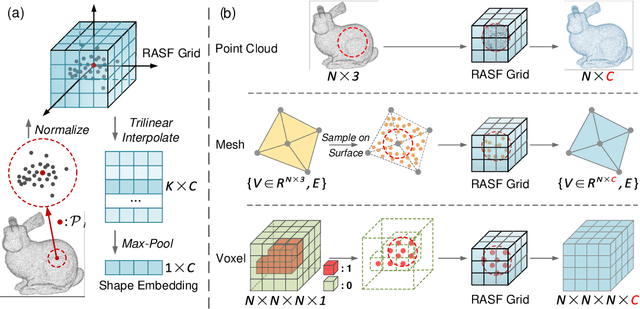

3D shape analysis has been widely explored in the era of deep learning. Numerous models have been developed for various 3D data representation formats, e.g., MeshCNN for meshes, PointNet for point clouds and VoxNet for voxels. In this study, we present Representation-Agnostic Shape Fields (RASF), a generalizable and computation-efficient shape embedding module for 3D deep learning. RASF is implemented with a learnable 3D grid with multiple channels to store local geometry. Based on RASF, shape embeddings for various 3D shape representations (point clouds, meshes and voxels) are retrieved by coordinate indexing. While there are multiple ways to optimize the learnable parameters of RASF, we provide two effective schemes among all in this paper for RASF pre-training: shape reconstruction and normal estimation. Once trained, RASF becomes a plug-and-play performance booster with negligible cost. Extensive experiments on diverse 3D representation formats, networks and applications, validate the universal effectiveness of the proposed RASF. Code and pre-trained models are publicly available https://github.com/seanywang0408/RASF
* The Tenth International Conference on Learning Representations (ICLR 2022). Code is available at https://github.com/seanywang0408/RASF
Gradient Correction beyond Gradient Descent
Mar 16, 2022
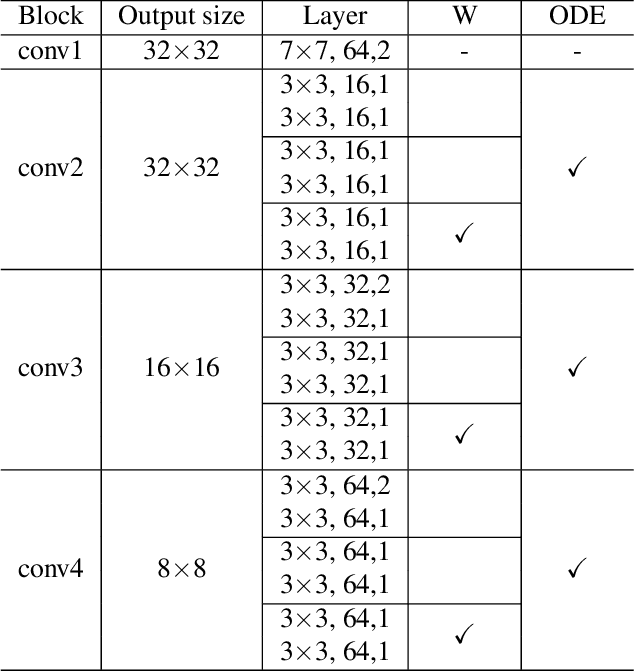
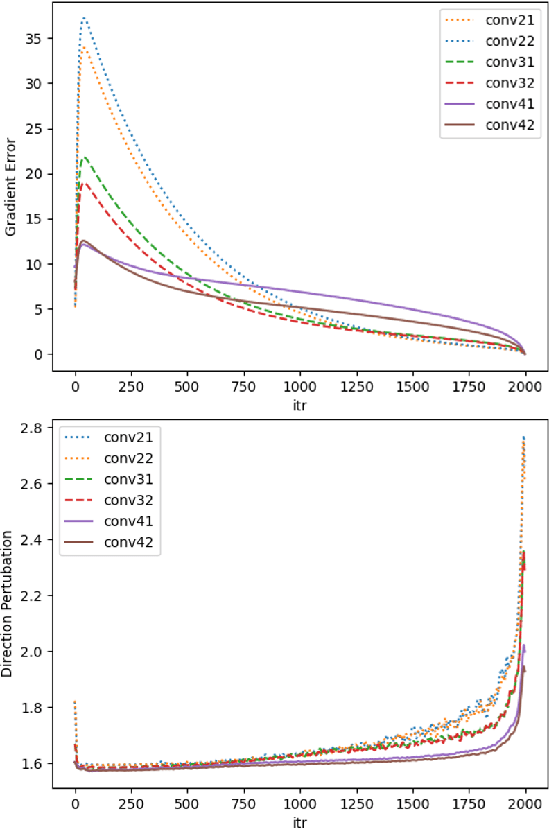
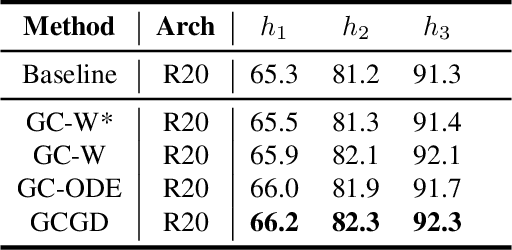
The great success neural networks have achieved is inseparable from the application of gradient-descent (GD) algorithms. Based on GD, many variant algorithms have emerged to improve the GD optimization process. The gradient for back-propagation is apparently the most crucial aspect for the training of a neural network. The quality of the calculated gradient can be affected by multiple aspects, e.g., noisy data, calculation error, algorithm limitation, and so on. To reveal gradient information beyond gradient descent, we introduce a framework (\textbf{GCGD}) to perform gradient correction. GCGD consists of two plug-in modules: 1) inspired by the idea of gradient prediction, we propose a \textbf{GC-W} module for weight gradient correction; 2) based on Neural ODE, we propose a \textbf{GC-ODE} module for hidden states gradient correction. Experiment results show that our gradient correction framework can effectively improve the gradient quality to reduce training epochs by $\sim$ 20\% and also improve the network performance.
HCSC: Hierarchical Contrastive Selective Coding
Feb 01, 2022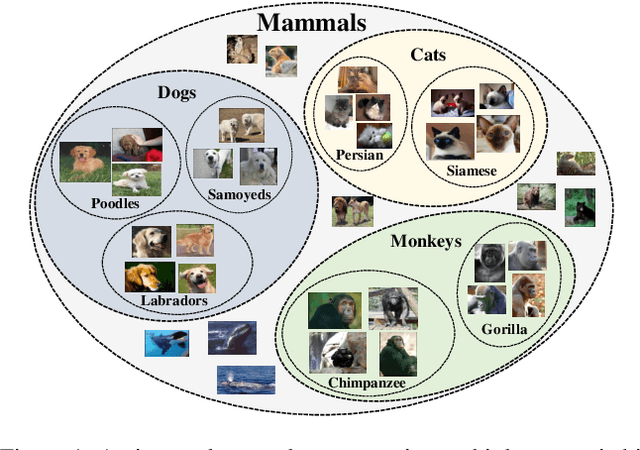
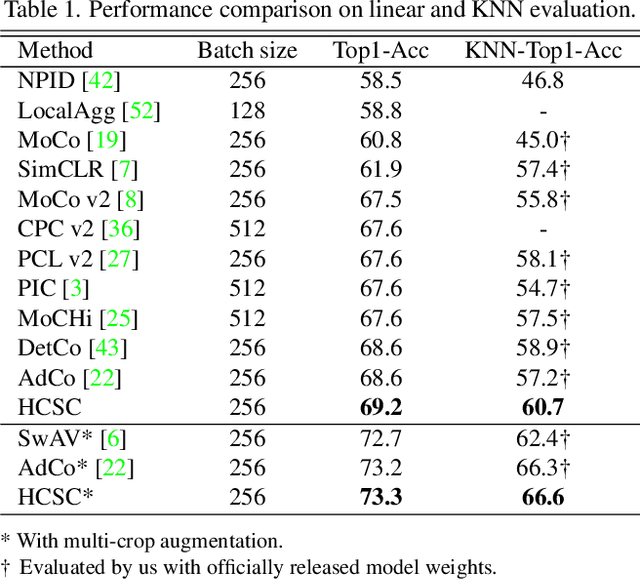
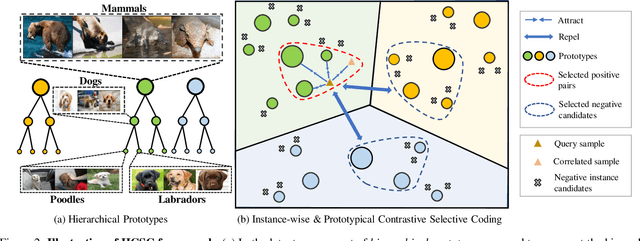
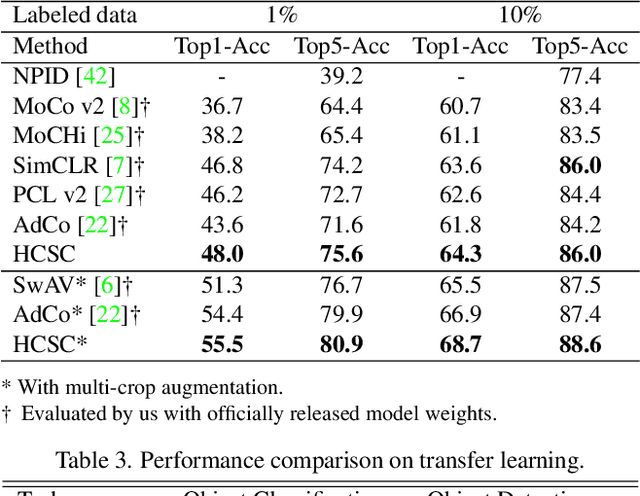
Hierarchical semantic structures naturally exist in an image dataset, in which several semantically relevant image clusters can be further integrated into a larger cluster with coarser-grained semantics. Capturing such structures with image representations can greatly benefit the semantic understanding on various downstream tasks. Existing contrastive representation learning methods lack such an important model capability. In addition, the negative pairs used in these methods are not guaranteed to be semantically distinct, which could further hamper the structural correctness of learned image representations. To tackle these limitations, we propose a novel contrastive learning framework called Hierarchical Contrastive Selective Coding (HCSC). In this framework, a set of hierarchical prototypes are constructed and also dynamically updated to represent the hierarchical semantic structures underlying the data in the latent space. To make image representations better fit such semantic structures, we employ and further improve conventional instance-wise and prototypical contrastive learning via an elaborate pair selection scheme. This scheme seeks to select more diverse positive pairs with similar semantics and more precise negative pairs with truly distinct semantics. On extensive downstream tasks, we verify the superior performance of HCSC over state-of-the-art contrastive methods, and the effectiveness of major model components is proved by plentiful analytical studies. Our source code and model weights are available at https://github.com/gyfastas/HCSC
Fully Context-Aware Image Inpainting with a Learned Semantic Pyramid
Dec 08, 2021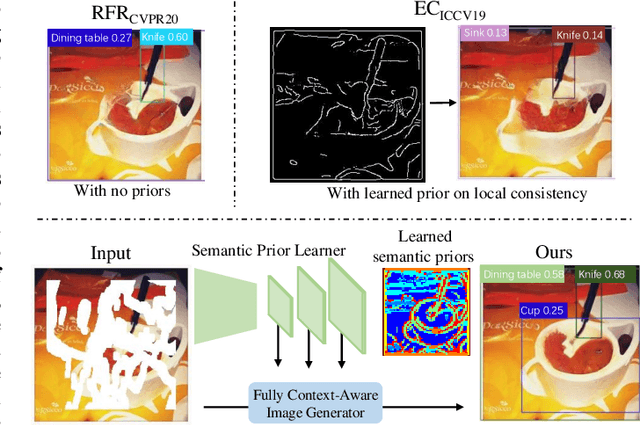

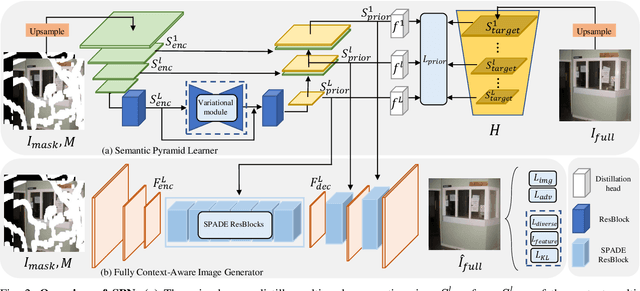
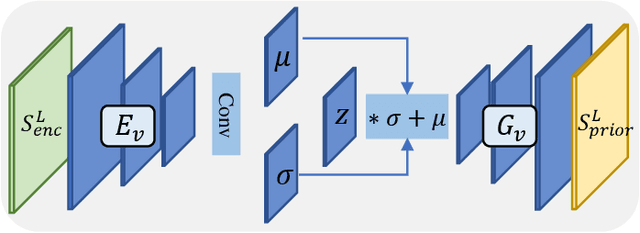
Restoring reasonable and realistic content for arbitrary missing regions in images is an important yet challenging task. Although recent image inpainting models have made significant progress in generating vivid visual details, they can still lead to texture blurring or structural distortions due to contextual ambiguity when dealing with more complex scenes. To address this issue, we propose the Semantic Pyramid Network (SPN) motivated by the idea that learning multi-scale semantic priors from specific pretext tasks can greatly benefit the recovery of locally missing content in images. SPN consists of two components. First, it distills semantic priors from a pretext model into a multi-scale feature pyramid, achieving a consistent understanding of the global context and local structures. Within the prior learner, we present an optional module for variational inference to realize probabilistic image inpainting driven by various learned priors. The second component of SPN is a fully context-aware image generator, which adaptively and progressively refines low-level visual representations at multiple scales with the (stochastic) prior pyramid. We train the prior learner and the image generator as a unified model without any post-processing. Our approach achieves the state of the art on multiple datasets, including Places2, Paris StreetView, CelebA, and CelebA-HQ, under both deterministic and probabilistic inpainting setups.
Global-Local Context Network for Person Search
Dec 05, 2021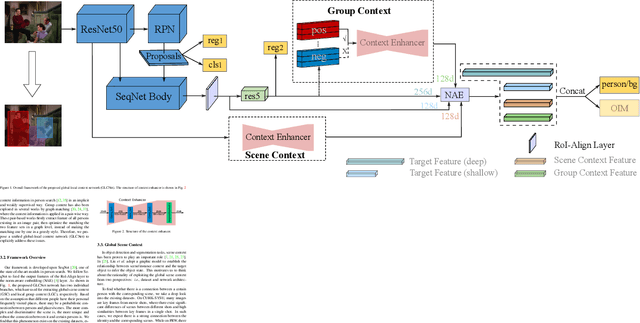
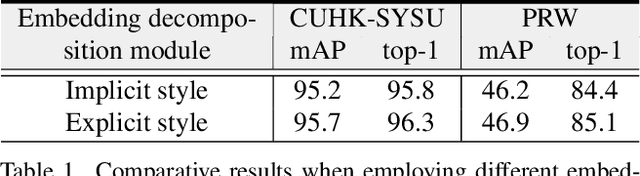
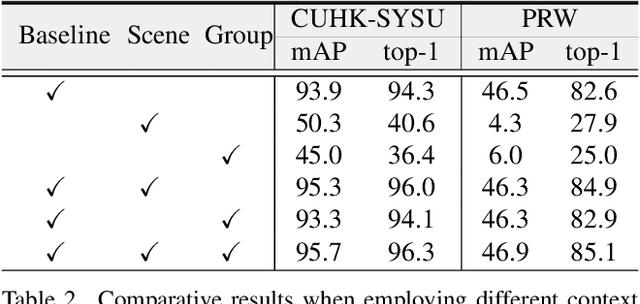
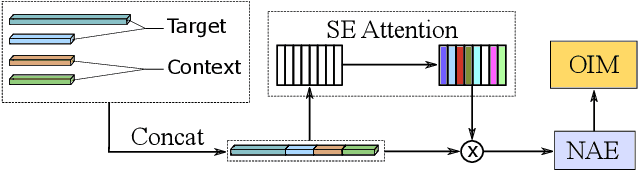
Person search aims to jointly localize and identify a query person from natural, uncropped images, which has been actively studied in the computer vision community over the past few years. In this paper, we delve into the rich context information globally and locally surrounding the target person, which we refer to scene and group context, respectively. Unlike previous works that treat the two types of context individually, we exploit them in a unified global-local context network (GLCNet) with the intuitive aim of feature enhancement. Specifically, re-ID embeddings and context features are enhanced simultaneously in a multi-stage fashion, ultimately leading to enhanced, discriminative features for person search. We conduct the experiments on two person search benchmarks (i.e., CUHK-SYSU and PRW) as well as extend our approach to a more challenging setting (i.e., character search on MovieNet). Extensive experimental results demonstrate the consistent improvement of the proposed GLCNet over the state-of-the-art methods on the three datasets. Our source codes, pre-trained models, and the new setting for character search are available at: https://github.com/ZhengPeng7/GLCNet.