 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongAV-Compass: Towards Unified Evaluation of Minute-Scale Audio-Visual Generation Across T2AV, I2AV, and V2AV
May 25, 2026Audio-visual generation is rapidly advancing from short clips to minute-long content, while existing evaluation protocols remain largely confined to short-form settings. Existing benchmarks primarily focus on 5--10 second text-conditioned generation and rarely support unified evaluation across text, image, and video conditioning modalities. Moreover, they provide limited insight into how identity consistency, narrative coherence, and audio-visual alignment degrade over extended temporal horizons. To bridge this gap, we introduce LongAV-Compass, a systematic benchmark for minute-long audio-visual generation. LongAV-Compass contains 284 curated test cases spanning text-to-audio-video (T2AV), image-to-audio-video (I2AV), and video-to-audio-video (V2AV), organized by application scenario and generation complexity. The benchmark combines taxonomy-guided benchmark construction with a unified evaluation framework that integrates MLLM-assisted assessment with complementary perceptual and multimodal metrics, including DINO-v2, ArcFace, CLIP, and ImageBind. The framework evaluates more than 20 fine-grained dimensions covering within-segment quality, cross-segment consistency, global narrative coherence, semantic alignment, and audio-visual synchronization. Through experiments on 11 representative models together with human-alignment validation, LongAV-Compass provides a diagnostic testbed for analyzing the limitations of current systems in sustaining coherent, semantically aligned, and temporally consistent minute-scale audio-visual generation across diverse input modalities.
Artifact-Bench: Evaluating MLLMs on Detecting and Assessing the Artifacts of AI-Generated Videos
May 18, 2026Recent video generative models have greatly improved the realism of AI-generated videos, yet their outputs still exhibit artifacts such as temporal inconsistencies, structural distortions, and semantic incoherence. While Multimodal Large Language Models (MLLMs) show strong visual understanding capabilities, their ability to perceive and reason about such artifacts remains unclear. Existing benchmarks often lack systematic evaluation of artifact-aware perception and fine-grained diagnostic reasoning, especially across diverse AI-generated video domains beyond photorealistic content. To address this gap, we introduce Artifact-Bench, a comprehensive benchmark for evaluating MLLMs on AI-generated video artifact detection and analysis. We first establish a three-level hierarchical taxonomy of realism artifacts, covering photorealistic, animated, and CG-style videos. Based on this taxonomy, Artifact-Bench defines three complementary tasks: real vs. AI-generated video classification, pairwise realism comparison, and fine-grained artifact identification. Experiments on 19 leading MLLMs reveal substantial limitations in artifact perception and reasoning, with many models approaching random or even below-random performance in challenging settings. We further observe significant misalignment between MLLM judgments and human perceptual preferences, highlighting their limited reliability as general evaluators for AI-generated video realism.
Edit-Compass & EditReward-Compass: A Unified Benchmark for Image Editing and Reward Modeling
May 13, 2026Recent image editing models have achieved remarkable progress in instruction following, multimodal understanding, and complex visual editing. However, existing benchmarks often fail to faithfully reflect human judgment, especially for strong frontier models, due to limited task difficulty and coarse-grained evaluation protocols. In parallel, reward models have become increasingly important for RL-based image editing optimization, yet existing reward model benchmarks still rely on unrealistic evaluation settings that deviate from practical RL scenarios. These limitations hinder reliable assessment of both image editing models and reward models. To address these challenges, we introduce Edit-Compass and EditReward-Compass, a unified evaluation suite for image editing and reward modeling. Edit-Compass contains 2,388 carefully annotated instances spanning six progressively challenging task categories, covering capabilities such as world knowledge reasoning, visual reasoning, and multi-image editing. Beyond broad task coverage, Edit-Compass adopts a fine-grained multidimensional evaluation framework based on structured reasoning and carefully designed scoring rubrics. In parallel, EditReward-Compass contains 2,251 preference pairs that simulate realistic reward modeling scenarios during RL optimization.
Beyond the Last Layer: Multi-Layer Representation Fusion for Visual Tokenizatio
May 11, 2026Representation autoencoders that reuse frozen pretrained vision encoders as visual tokenizers have achieved strong reconstruction and generation quality. However, existing methods universally extract features from only the last encoder layer, discarding the rich hierarchical information distributed across intermediate layers. We show that low-level visual details survive in the last layer merely as attenuated residuals after multiple layers of semantic abstraction, and that explicitly fusing multi-layer features can substantially recover this lost information. We propose DRoRAE (Depth-Routed Representation AutoEncoder), a lightweight fusion module that adaptively aggregates all encoder layers via energy-constrained routing and incremental correction, producing an enriched latent compatible with a frozen pretrained decoder. A three-phase decoupled training strategy first learns the fusion under the implicit distributional constraint of the frozen decoder, then fine-tunes the decoder to fully exploit the enriched representation. On ImageNet-256, DRoRAE reduces rFID from 0.57 to 0.29 and improves generation FID from 1.74 to 1.65 (with AutoGuidance), with gains also transferring to text-to-image synthesis. Furthermore, we uncover a log-linear scaling law ($R^2{=}0.86$) between fusion capacity and reconstruction quality, identifying \textit{representation richness} as a new, predictably scalable dimension for visual tokenizers analogous to vocabulary size in NLP.
MMVIAD: Multi-view Multi-task Video Understanding for Industrial Anomaly Detection
May 11, 2026Industrial anomaly detection is critical for manufacturing quality control, yet existing datasets mainly focus on static images or sparse views, which do not fully reflect continuous inspection processes in real industrial scenarios. We introduce MMVIAD (Multi-view Multi-task Video Industrial Anomaly Detection), to the best of our knowledge the first continuous multi-view video dataset for industrial anomaly detection and understanding, together with a benchmark for multi-task evaluation. MMVIAD contains object-centric 2-second inspection clips with approximately 120 degrees of camera motion, covering 48 object categories, 14 environments, and 6 structural anomaly types. It supports anomaly detection, defect classification, object classification, and anomaly visible-time localization. Systematic evaluations on MMVIAD show that current commercial and open-source video MLLMs remain far below human performance, especially for fine-grained defect recognition and temporal grounding. To improve transferable anomaly understanding, we further develop a two-stage post-training pipeline where PS-SFT (Perception-Structured Supervised Fine-Tuning) initializes perception-structured reasoning and VISTA-GRPO (Visibility-grounded Industrial Structured Temporal Anomaly Group Relative Policy Optimization) refines the model with semantic-gated defect reward and visibility-aware temporal reward, producing the final model VISTA. On MMVIAD-Unseen, VISTA improves the base model's average score across the four tasks from 45.0 to 57.5, surpassing GPT-5.4. Source code is available at https://github.com/Georgekeepmoving/MMVIAD.
Unveiling Fine-Grained Visual Traces: Evaluating Multimodal Interleaved Reasoning Chains in Multimodal STEM Tasks
Apr 21, 2026Multimodal large language models (MLLMs) have shown promising reasoning abilities, yet evaluating their performance in specialized domains remains challenging. STEM reasoning is a particularly valuable testbed because it provides highly verifiable feedback, but existing benchmarks often permit unimodal shortcuts due to modality redundancy and focus mainly on final-answer accuracy, overlooking the reasoning process itself. To address this challenge, we introduce StepSTEM: a graduate-level benchmark of 283 problems across mathematics, physics, chemistry, biology, and engineering for fine-grained evaluation of cross-modal reasoning in MLLMs. StepSTEM is constructed through a rigorous curation pipeline that enforces strict complementarity between textual and visual inputs. We further propose a general step-level evaluation framework for both text-only chain-of-thought and interleaved image-text reasoning, using dynamic programming to align predicted reasoning steps with multiple reference solutions. Experiments across a wide range of models show that current MLLMs still rely heavily on textual reasoning, with even Gemini 3.1 Pro and Claude Opus 4.6 achieving only 38.29% accuracy. These results highlight substantial headroom for genuine cross-modal STEM reasoning and position StepSTEM as a benchmark for fine-grained evaluation of multimodal reasoning. Source code is available at https://github.com/lll-hhh/STEPSTEM.
LongCat-Next: Lexicalizing Modalities as Discrete Tokens
Mar 29, 2026The prevailing Next-Token Prediction (NTP) paradigm has driven the success of large language models through discrete autoregressive modeling. However, contemporary multimodal systems remain language-centric, often treating non-linguistic modalities as external attachments, leading to fragmented architectures and suboptimal integration. To transcend this limitation, we introduce Discrete Native Autoregressive (DiNA), a unified framework that represents multimodal information within a shared discrete space, enabling a consistent and principled autoregressive modeling across modalities. A key innovation is the Discrete Native Any-resolution Visual Transformer (dNaViT), which performs tokenization and de-tokenization at arbitrary resolutions, transforming continuous visual signals into hierarchical discrete tokens. Building on this foundation, we develop LongCat-Next, a native multimodal model that processes text, vision, and audio under a single autoregressive objective with minimal modality-specific design. As an industrial-strength foundation model, it excels at seeing, painting, and talking within a single framework, achieving strong performance across a wide range of multimodal benchmarks. In particular, LongCat-Next addresses the long-standing performance ceiling of discrete vision modeling on understanding tasks and provides a unified approach to effectively reconcile the conflict between understanding and generation. As an attempt toward native multimodality, we open-source the LongCat-Next and its tokenizers, hoping to foster further research and development in the community. GitHub: https://github.com/meituan-longcat/LongCat-Next
VTC-Bench: Evaluating Agentic Multimodal Models via Compositional Visual Tool Chaining
Mar 16, 2026Recent advancements extend Multimodal Large Language Models (MLLMs) beyond standard visual question answering to utilizing external tools for advanced visual tasks. Despite this progress, precisely executing and effectively composing diverse tools for complex tasks remain persistent bottleneck. Constrained by sparse tool-sets and simple tool-use trajectories, existing benchmarks fail to capture complex and diverse tool interactions, falling short in evaluating model performance under practical, real-world conditions. To bridge this gap, we introduce VisualToolChain-Bench~(VTC-Bench), a comprehensive benchmark designed to evaluate tool-use proficiency in MLLMs. To align with realistic computer vision pipelines, our framework features 32 diverse OpenCV-based visual operations. This rich tool-set enables extensive combinations, allowing VTC-Bench to rigorously assess multi-tool composition and long-horizon, multi-step plan execution. For precise evaluation, we provide 680 curated problems structured across a nine-category cognitive hierarchy, each with ground-truth execution trajectories. Extensive experiments on 19 leading MLLMs reveal critical limitations in current models' visual agentic capabilities. Specifically, models struggle to adapt to diverse tool-sets and generalize to unseen operations, with the leading model Gemini-3.0-Pro only achieving 51\% on our benchmark. Furthermore, multi-tool composition remains a persistent challenge. When facing complex tasks, models struggle to formulate efficient execution plans, relying heavily on a narrow, suboptimal subset of familiar functions rather than selecting the optimal tools. By identifying these fundamental challenges, VTC-Bench establishes a rigorous baseline to guide the development of more generalized visual agentic models.
HIRL: A General Framework for Hierarchical Image Representation Learning
May 26, 2022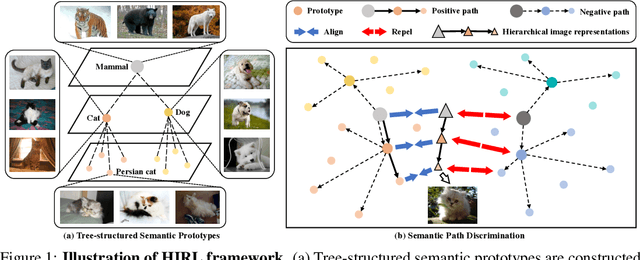
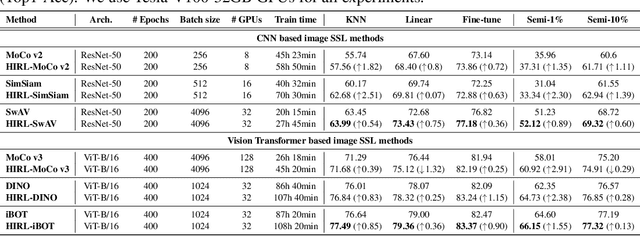


Learning self-supervised image representations has been broadly studied to boost various visual understanding tasks. Existing methods typically learn a single level of image semantics like pairwise semantic similarity or image clustering patterns. However, these methods can hardly capture multiple levels of semantic information that naturally exists in an image dataset, e.g., the semantic hierarchy of "Persian cat to cat to mammal" encoded in an image database for species. It is thus unknown whether an arbitrary image self-supervised learning (SSL) approach can benefit from learning such hierarchical semantics. To answer this question, we propose a general framework for Hierarchical Image Representation Learning (HIRL). This framework aims to learn multiple semantic representations for each image, and these representations are structured to encode image semantics from fine-grained to coarse-grained. Based on a probabilistic factorization, HIRL learns the most fine-grained semantics by an off-the-shelf image SSL approach and learns multiple coarse-grained semantics by a novel semantic path discrimination scheme. We adopt six representative image SSL methods as baselines and study how they perform under HIRL. By rigorous fair comparison, performance gain is observed on all the six methods for diverse downstream tasks, which, for the first time, verifies the general effectiveness of learning hierarchical image semantics. All source code and model weights are available at https://github.com/hirl-team/HIRL
BFRnet: A deep learning-based MR background field removal method for QSM of the brain containing significant pathological susceptibility sources
Apr 06, 2022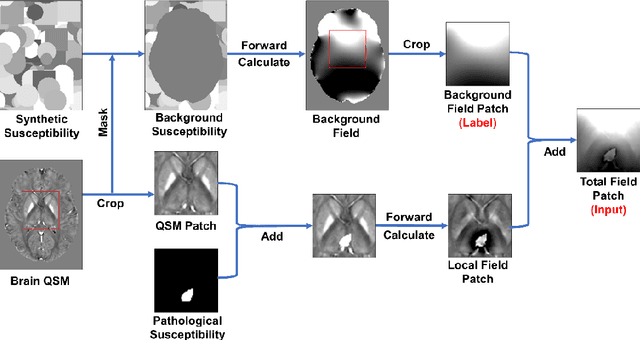

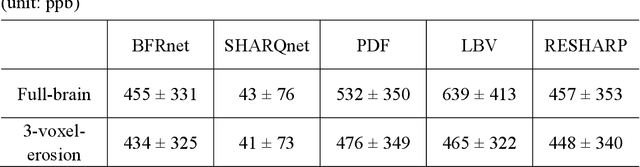
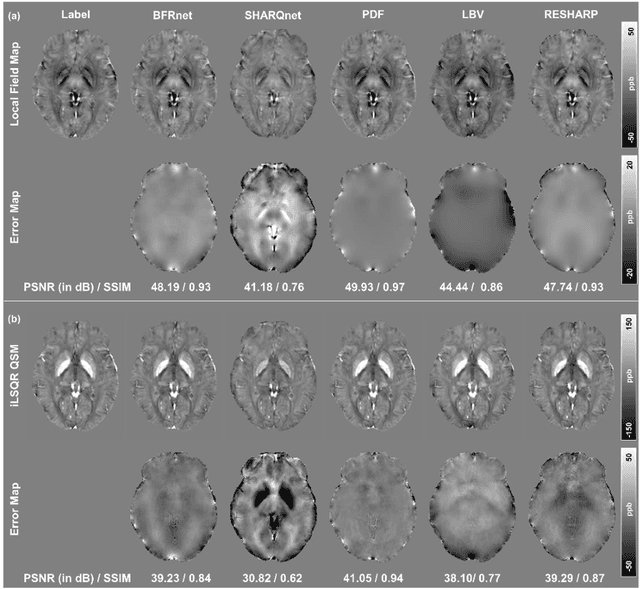
Introduction: Background field removal (BFR) is a critical step required for successful quantitative susceptibility mapping (QSM). However, eliminating the background field in brains containing significant susceptibility sources, such as intracranial hemorrhages, is challenging due to the relatively large scale of the field induced by these pathological susceptibility sources. Method: This study proposes a new deep learning-based method, BFRnet, to remove background field in healthy and hemorrhagic subjects. The network is built with the dual-frequency octave convolutions on the U-net architecture, trained with synthetic field maps containing significant susceptibility sources. The BFRnet method is compared with three conventional BFR methods and one previous deep learning method using simulated and in vivo brains from 4 healthy and 2 hemorrhagic subjects. Robustness against acquisition field-of-view (FOV) orientation and brain masking are also investigated. Results: For both simulation and in vivo experiments, BFRnet led to the best visually appealing results in the local field and QSM results with the minimum contrast loss and the most accurate hemorrhage susceptibility measurements among all five methods. In addition, BFRnet produced the most consistent local field and susceptibility maps between different sizes of brain masks, while conventional methods depend drastically on precise brain extraction and further brain edge erosions. It is also observed that BFRnet performed the best among all BFR methods for acquisition FOVs oblique to the main magnetic field. Conclusion: The proposed BFRnet improved the accuracy of local field reconstruction in the hemorrhagic subjects compared with conventional BFR algorithms. The BFRnet method was effective for acquisitions of titled orientations and retained whole brains without edge erosion as often required by traditional BFR methods.