 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMentalMAC: Enhancing Large Language Models for Detecting Mental Manipulation via Multi-Task Anti-Curriculum Distillation
May 21, 2025Mental manipulation is a subtle yet pervasive form of psychological abuse that poses serious threats to mental health. Its covert nature and the complexity of manipulation strategies make it challenging to detect, even for state-of-the-art large language models (LLMs). This concealment also hinders the manual collection of large-scale, high-quality annotations essential for training effective models. Although recent efforts have sought to improve LLM's performance on this task, progress remains limited due to the scarcity of real-world annotated datasets. To address these challenges, we propose MentalMAC, a multi-task anti-curriculum distillation method that enhances LLMs' ability to detect mental manipulation in multi-turn dialogue. Our approach includes: (i) EvoSA, an unsupervised data expansion method based on evolutionary operations and speech act theory; (ii) teacher-model-generated multi-task supervision; and (iii) progressive knowledge distillation from complex to simpler tasks. We then constructed the ReaMent dataset with 5,000 real-world dialogue samples, using a MentalMAC-distilled model to assist human annotation. Vast experiments demonstrate that our method significantly narrows the gap between student and teacher models and outperforms competitive LLMs across key evaluation metrics. All code, datasets, and checkpoints will be released upon paper acceptance. Warning: This paper contains content that may be offensive to readers.
Overview of the NLPCC 2025 Shared Task 4: Multi-modal, Multilingual, and Multi-hop Medical Instructional Video Question Answering Challenge
May 11, 2025Following the successful hosts of the 1-st (NLPCC 2023 Foshan) CMIVQA and the 2-rd (NLPCC 2024 Hangzhou) MMIVQA challenges, this year, a new task has been introduced to further advance research in multi-modal, multilingual, and multi-hop medical instructional question answering (M4IVQA) systems, with a specific focus on medical instructional videos. The M4IVQA challenge focuses on evaluating models that integrate information from medical instructional videos, understand multiple languages, and answer multi-hop questions requiring reasoning over various modalities. This task consists of three tracks: multi-modal, multilingual, and multi-hop Temporal Answer Grounding in Single Video (M4TAGSV), multi-modal, multilingual, and multi-hop Video Corpus Retrieval (M4VCR) and multi-modal, multilingual, and multi-hop Temporal Answer Grounding in Video Corpus (M4TAGVC). Participants in M4IVQA are expected to develop algorithms capable of processing both video and text data, understanding multilingual queries, and providing relevant answers to multi-hop medical questions. We believe the newly introduced M4IVQA challenge will drive innovations in multimodal reasoning systems for healthcare scenarios, ultimately contributing to smarter emergency response systems and more effective medical education platforms in multilingual communities. Our official website is https://cmivqa.github.io/
Emotion-Qwen: Training Hybrid Experts for Unified Emotion and General Vision-Language Understanding
May 10, 2025Emotion understanding in videos aims to accurately recognize and interpret individuals' emotional states by integrating contextual, visual, textual, and auditory cues. While Large Multimodal Models (LMMs) have demonstrated significant progress in general vision-language (VL) tasks, their performance in emotion-specific scenarios remains limited. Moreover, fine-tuning LMMs on emotion-related tasks often leads to catastrophic forgetting, hindering their ability to generalize across diverse tasks. To address these challenges, we present Emotion-Qwen, a tailored multimodal framework designed to enhance both emotion understanding and general VL reasoning. Emotion-Qwen incorporates a sophisticated Hybrid Compressor based on the Mixture of Experts (MoE) paradigm, which dynamically routes inputs to balance emotion-specific and general-purpose processing. The model is pre-trained in a three-stage pipeline on large-scale general and emotional image datasets to support robust multimodal representations. Furthermore, we construct the Video Emotion Reasoning (VER) dataset, comprising more than 40K bilingual video clips with fine-grained descriptive annotations, to further enrich Emotion-Qwen's emotional reasoning capability. Experimental results demonstrate that Emotion-Qwen achieves state-of-the-art performance on multiple emotion recognition benchmarks, while maintaining competitive results on general VL tasks. Code and models are available at https://anonymous.4open.science/r/Emotion-Qwen-Anonymous.
PICD: Versatile Perceptual Image Compression with Diffusion Rendering
May 09, 2025



Recently, perceptual image compression has achieved significant advancements, delivering high visual quality at low bitrates for natural images. However, for screen content, existing methods often produce noticeable artifacts when compressing text. To tackle this challenge, we propose versatile perceptual screen image compression with diffusion rendering (PICD), a codec that works well for both screen and natural images. More specifically, we propose a compression framework that encodes the text and image separately, and renders them into one image using diffusion model. For this diffusion rendering, we integrate conditional information into diffusion models at three distinct levels: 1). Domain level: We fine-tune the base diffusion model using text content prompts with screen content. 2). Adaptor level: We develop an efficient adaptor to control the diffusion model using compressed image and text as input. 3). Instance level: We apply instance-wise guidance to further enhance the decoding process. Empirically, our PICD surpasses existing perceptual codecs in terms of both text accuracy and perceptual quality. Additionally, without text conditions, our approach serves effectively as a perceptual codec for natural images.
ReGraP-LLaVA: Reasoning enabled Graph-based Personalized Large Language and Vision Assistant
May 06, 2025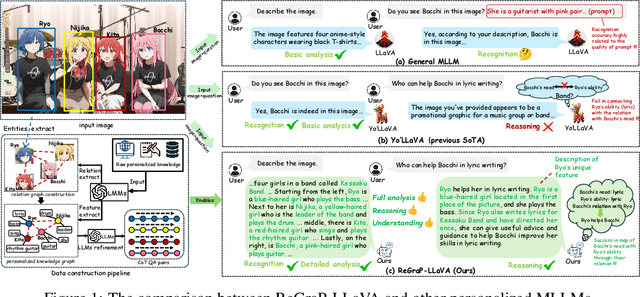

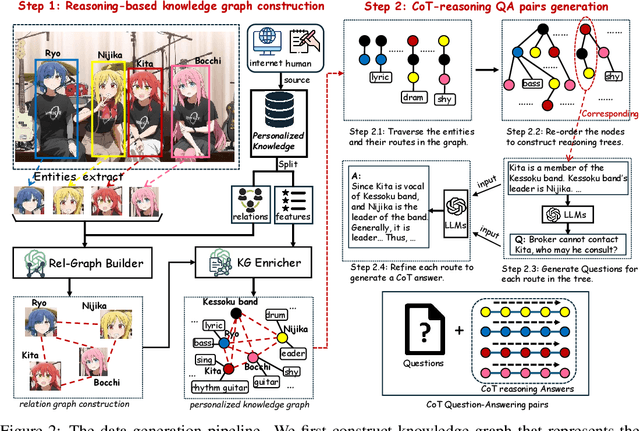
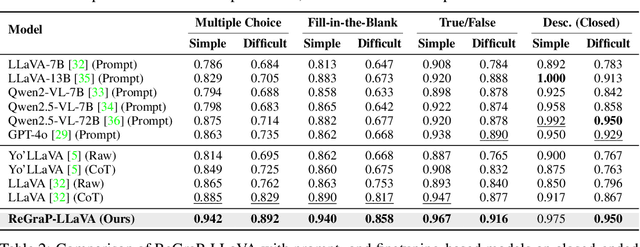
Recent advances in personalized MLLMs enable effective capture of user-specific concepts, supporting both recognition of personalized concepts and contextual captioning. However, humans typically explore and reason over relations among objects and individuals, transcending surface-level information to achieve more personalized and contextual understanding. To this end, existing methods may face three main limitations: Their training data lacks multi-object sets in which relations among objects are learnable. Building on the limited training data, their models overlook the relations between different personalized concepts and fail to reason over them. Their experiments mainly focus on a single personalized concept, where evaluations are limited to recognition and captioning tasks. To address the limitations, we present a new dataset named ReGraP, consisting of 120 sets of personalized knowledge. Each set includes images, KGs, and CoT QA pairs derived from the KGs, enabling more structured and sophisticated reasoning pathways. We propose ReGraP-LLaVA, an MLLM trained with the corresponding KGs and CoT QA pairs, where soft and hard graph prompting methods are designed to align KGs within the model's semantic space. We establish the ReGraP Benchmark, which contains diverse task types: multiple-choice, fill-in-the-blank, True/False, and descriptive questions in both open- and closed-ended settings. The proposed benchmark is designed to evaluate the relational reasoning and knowledge-connection capability of personalized MLLMs. We conduct experiments on the proposed ReGraP-LLaVA and other competitive MLLMs. Results show that the proposed model not only learns personalized knowledge but also performs relational reasoning in responses, achieving the SoTA performance compared with the competitive methods. All the codes and datasets are released at: https://github.com/xyfyyds/ReGraP.
XeMap: Contextual Referring in Large-Scale Remote Sensing Environments
Apr 30, 2025



Advancements in remote sensing (RS) imagery have provided high-resolution detail and vast coverage, yet existing methods, such as image-level captioning/retrieval and object-level detection/segmentation, often fail to capture mid-scale semantic entities essential for interpreting large-scale scenes. To address this, we propose the conteXtual referring Map (XeMap) task, which focuses on contextual, fine-grained localization of text-referred regions in large-scale RS scenes. Unlike traditional approaches, XeMap enables precise mapping of mid-scale semantic entities that are often overlooked in image-level or object-level methods. To achieve this, we introduce XeMap-Network, a novel architecture designed to handle the complexities of pixel-level cross-modal contextual referring mapping in RS. The network includes a fusion layer that applies self- and cross-attention mechanisms to enhance the interaction between text and image embeddings. Furthermore, we propose a Hierarchical Multi-Scale Semantic Alignment (HMSA) module that aligns multiscale visual features with the text semantic vector, enabling precise multimodal matching across large-scale RS imagery. To support XeMap task, we provide a novel, annotated dataset, XeMap-set, specifically tailored for this task, overcoming the lack of XeMap datasets in RS imagery. XeMap-Network is evaluated in a zero-shot setting against state-of-the-art methods, demonstrating superior performance. This highlights its effectiveness in accurately mapping referring regions and providing valuable insights for interpreting large-scale RS environments.
Ask2Loc: Learning to Locate Instructional Visual Answers by Asking Questions
Apr 22, 2025Locating specific segments within an instructional video is an efficient way to acquire guiding knowledge. Generally, the task of obtaining video segments for both verbal explanations and visual demonstrations is known as visual answer localization (VAL). However, users often need multiple interactions to obtain answers that align with their expectations when using the system. During these interactions, humans deepen their understanding of the video content by asking themselves questions, thereby accurately identifying the location. Therefore, we propose a new task, named In-VAL, to simulate the multiple interactions between humans and videos in the procedure of obtaining visual answers. The In-VAL task requires interactively addressing several semantic gap issues, including 1) the ambiguity of user intent in the input questions, 2) the incompleteness of language in video subtitles, and 3) the fragmentation of content in video segments. To address these issues, we propose Ask2Loc, a framework for resolving In-VAL by asking questions. It includes three key modules: 1) a chatting module to refine initial questions and uncover clear intentions, 2) a rewriting module to generate fluent language and create complete descriptions, and 3) a searching module to broaden local context and provide integrated content. We conduct extensive experiments on three reconstructed In-VAL datasets. Compared to traditional end-to-end and two-stage methods, our proposed Ask2Loc can improve performance by up to 14.91 (mIoU) on the In-VAL task. Our code and datasets can be accessed at https://github.com/changzong/Ask2Loc.
Hierarchical Modeling for Medical Visual Question Answering with Cross-Attention Fusion
Apr 10, 2025



Medical Visual Question Answering (Med-VQA) answers clinical questions using medical images, aiding diagnosis. Designing the MedVQA system holds profound importance in assisting clinical diagnosis and enhancing diagnostic accuracy. Building upon this foundation, Hierarchical Medical VQA extends Medical VQA by organizing medical questions into a hierarchical structure and making level-specific predictions to handle fine-grained distinctions. Recently, many studies have proposed hierarchical MedVQA tasks and established datasets, However, several issues still remain: (1) imperfect hierarchical modeling leads to poor differentiation between question levels causing semantic fragmentation across hierarchies. (2) Excessive reliance on implicit learning in Transformer-based cross-modal self-attention fusion methods, which obscures crucial local semantic correlations in medical scenarios. To address these issues, this study proposes a HiCA-VQA method, including two modules: Hierarchical Prompting for fine-grained medical questions and Hierarchical Answer Decoders. The hierarchical prompting module pre-aligns hierarchical text prompts with image features to guide the model in focusing on specific image regions according to question types, while the hierarchical decoder performs separate predictions for questions at different levels to improve accuracy across granularities. The framework also incorporates a cross-attention fusion module where images serve as queries and text as key-value pairs. Experiments on the Rad-Restruct benchmark demonstrate that the HiCA-VQA framework better outperforms existing state-of-the-art methods in answering hierarchical fine-grained questions. This study provides an effective pathway for hierarchical visual question answering systems, advancing medical image understanding.
Event Signal Filtering via Probability Flux Estimation
Apr 10, 2025Events offer a novel paradigm for capturing scene dynamics via asynchronous sensing, but their inherent randomness often leads to degraded signal quality. Event signal filtering is thus essential for enhancing fidelity by reducing this internal randomness and ensuring consistent outputs across diverse acquisition conditions. Unlike traditional time series that rely on fixed temporal sampling to capture steady-state behaviors, events encode transient dynamics through polarity and event intervals, making signal modeling significantly more complex. To address this, the theoretical foundation of event generation is revisited through the lens of diffusion processes. The state and process information within events is modeled as continuous probability flux at threshold boundaries of the underlying irradiance diffusion. Building on this insight, a generative, online filtering framework called Event Density Flow Filter (EDFilter) is introduced. EDFilter estimates event correlation by reconstructing the continuous probability flux from discrete events using nonparametric kernel smoothing, and then resamples filtered events from this flux. To optimize fidelity over time, spatial and temporal kernels are employed in a time-varying optimization framework. A fast recursive solver with O(1) complexity is proposed, leveraging state-space models and lookup tables for efficient likelihood computation. Furthermore, a new real-world benchmark Rotary Event Dataset (RED) is released, offering microsecond-level ground truth irradiance for full-reference event filtering evaluation. Extensive experiments validate EDFilter's performance across tasks like event filtering, super-resolution, and direct event-based blob tracking. Significant gains in downstream applications such as SLAM and video reconstruction underscore its robustness and effectiveness.
EffOWT: Transfer Visual Language Models to Open-World Tracking Efficiently and Effectively
Apr 09, 2025Open-World Tracking (OWT) aims to track every object of any category, which requires the model to have strong generalization capabilities. Trackers can improve their generalization ability by leveraging Visual Language Models (VLMs). However, challenges arise with the fine-tuning strategies when VLMs are transferred to OWT: full fine-tuning results in excessive parameter and memory costs, while the zero-shot strategy leads to sub-optimal performance. To solve the problem, EffOWT is proposed for efficiently transferring VLMs to OWT. Specifically, we build a small and independent learnable side network outside the VLM backbone. By freezing the backbone and only executing backpropagation on the side network, the model's efficiency requirements can be met. In addition, EffOWT enhances the side network by proposing a hybrid structure of Transformer and CNN to improve the model's performance in the OWT field. Finally, we implement sparse interactions on the MLP, thus reducing parameter updates and memory costs significantly. Thanks to the proposed methods, EffOWT achieves an absolute gain of 5.5% on the tracking metric OWTA for unknown categories, while only updating 1.3% of the parameters compared to full fine-tuning, with a 36.4% memory saving. Other metrics also demonstrate obvious improvement.