 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAiraXiv: An AI-Driven Open-Access Platform for Human and AI Scientists
May 20, 2026Recent advances in artificial intelligence (AI) have accelerated the growth of both human-authored and AI-generated research outputs, placing increasing strain on traditional academic publishing systems and challenging the scalability of conference- and journal-centered paradigms amid rising submission volumes, reviewer workload, and venue size. To address these challenges, we explore an AI-era publishing paradigm in which both human and AI scientists participate as authors and readers, and papers evolve through continuous, feedback-driven iteration. We propose AiraXiv, an AI-driven open-access platform built on open preprints, AI-augmented analysis and review, and reader feedback. AiraXiv supports human scientists through an interactive UI and AI scientists through Model Context Protocol (MCP)-based interactions. We validate AiraXiv through real-world deployments, including serving as the submission platform for ICAIS 2025, demonstrating its potential as a fast, inclusive, and scalable research infrastructure for the AI era. AiraXiv is publicly available at https://airaxiv.com.
AutoFigure: Generating and Refining Publication-Ready Scientific Illustrations
Feb 03, 2026High-quality scientific illustrations are crucial for effectively communicating complex scientific and technical concepts, yet their manual creation remains a well-recognized bottleneck in both academia and industry. We present FigureBench, the first large-scale benchmark for generating scientific illustrations from long-form scientific texts. It contains 3,300 high-quality scientific text-figure pairs, covering diverse text-to-illustration tasks from scientific papers, surveys, blogs, and textbooks. Moreover, we propose AutoFigure, the first agentic framework that automatically generates high-quality scientific illustrations based on long-form scientific text. Specifically, before rendering the final result, AutoFigure engages in extensive thinking, recombination, and validation to produce a layout that is both structurally sound and aesthetically refined, outputting a scientific illustration that achieves both structural completeness and aesthetic appeal. Leveraging the high-quality data from FigureBench, we conduct extensive experiments to test the performance of AutoFigure against various baseline methods. The results demonstrate that AutoFigure consistently surpasses all baseline methods, producing publication-ready scientific illustrations. The code, dataset and huggingface space are released in https://github.com/ResearAI/AutoFigure.
DeepScientist: Advancing Frontier-Pushing Scientific Findings Progressively
Sep 30, 2025



While previous AI Scientist systems can generate novel findings, they often lack the focus to produce scientifically valuable contributions that address pressing human-defined challenges. We introduce DeepScientist, a system designed to overcome this by conducting goal-oriented, fully autonomous scientific discovery over month-long timelines. It formalizes discovery as a Bayesian Optimization problem, operationalized through a hierarchical evaluation process consisting of "hypothesize, verify, and analyze". Leveraging a cumulative Findings Memory, this loop intelligently balances the exploration of novel hypotheses with exploitation, selectively promoting the most promising findings to higher-fidelity levels of validation. Consuming over 20,000 GPU hours, the system generated about 5,000 unique scientific ideas and experimentally validated approximately 1100 of them, ultimately surpassing human-designed state-of-the-art (SOTA) methods on three frontier AI tasks by 183.7\%, 1.9\%, and 7.9\%. This work provides the first large-scale evidence of an AI achieving discoveries that progressively surpass human SOTA on scientific tasks, producing valuable findings that genuinely push the frontier of scientific discovery. To facilitate further research into this process, we will open-source all experimental logs and system code at https://github.com/ResearAI/DeepScientist/.
T-Detect: Tail-Aware Statistical Normalization for Robust Detection of Adversarial Machine-Generated Text
Jul 31, 2025



The proliferation of sophisticated text generation models necessitates the development of robust detection methods capable of identifying machine-generated content, particularly text designed to evade detection through adversarial perturbations. Existing zero-shot detectors often rely on statistical measures that implicitly assume Gaussian distributions, a premise that falters when confronted with the heavy-tailed statistical artifacts characteristic of adversarial or non-native English texts. This paper introduces T-Detect, a novel detection method that fundamentally redesigns the statistical core of curvature-based detectors. Our primary innovation is the replacement of standard Gaussian normalization with a heavy-tailed discrepancy score derived from the Student's t-distribution. This approach is theoretically grounded in the empirical observation that adversarial texts exhibit significant leptokurtosis, rendering traditional statistical assumptions inadequate. T-Detect computes a detection score by normalizing the log-likelihood of a passage against the expected moments of a t-distribution, providing superior resilience to statistical outliers. We validate our approach on the challenging RAID benchmark for adversarial text and the comprehensive HART dataset. Experiments show that T-Detect provides a consistent performance uplift over strong baselines, improving AUROC by up to 3.9\% in targeted domains. When integrated into a two-dimensional detection framework (CT), our method achieves state-of-the-art performance, with an AUROC of 0.926 on the Books domain of RAID. Our contributions are a new, theoretically-justified statistical foundation for text detection, an ablation-validated method that demonstrates superior robustness, and a comprehensive analysis of its performance under adversarial conditions. Ours code are released at https://github.com/ResearAI/t-detect.
AutoTIR: Autonomous Tools Integrated Reasoning via Reinforcement Learning
Jul 29, 2025Large Language Models (LLMs), when enhanced through reasoning-oriented post-training, evolve into powerful Large Reasoning Models (LRMs). Tool-Integrated Reasoning (TIR) further extends their capabilities by incorporating external tools, but existing methods often rely on rigid, predefined tool-use patterns that risk degrading core language competence. Inspired by the human ability to adaptively select tools, we introduce AutoTIR, a reinforcement learning framework that enables LLMs to autonomously decide whether and which tool to invoke during the reasoning process, rather than following static tool-use strategies. AutoTIR leverages a hybrid reward mechanism that jointly optimizes for task-specific answer correctness, structured output adherence, and penalization of incorrect tool usage, thereby encouraging both precise reasoning and efficient tool integration. Extensive evaluations across diverse knowledge-intensive, mathematical, and general language modeling tasks demonstrate that AutoTIR achieves superior overall performance, significantly outperforming baselines and exhibits superior generalization in tool-use behavior. These results highlight the promise of reinforcement learning in building truly generalizable and scalable TIR capabilities in LLMs. The code and data are available at https://github.com/weiyifan1023/AutoTIR.
Overview of the NLPCC 2025 Shared Task 4: Multi-modal, Multilingual, and Multi-hop Medical Instructional Video Question Answering Challenge
May 11, 2025Following the successful hosts of the 1-st (NLPCC 2023 Foshan) CMIVQA and the 2-rd (NLPCC 2024 Hangzhou) MMIVQA challenges, this year, a new task has been introduced to further advance research in multi-modal, multilingual, and multi-hop medical instructional question answering (M4IVQA) systems, with a specific focus on medical instructional videos. The M4IVQA challenge focuses on evaluating models that integrate information from medical instructional videos, understand multiple languages, and answer multi-hop questions requiring reasoning over various modalities. This task consists of three tracks: multi-modal, multilingual, and multi-hop Temporal Answer Grounding in Single Video (M4TAGSV), multi-modal, multilingual, and multi-hop Video Corpus Retrieval (M4VCR) and multi-modal, multilingual, and multi-hop Temporal Answer Grounding in Video Corpus (M4TAGVC). Participants in M4IVQA are expected to develop algorithms capable of processing both video and text data, understanding multilingual queries, and providing relevant answers to multi-hop medical questions. We believe the newly introduced M4IVQA challenge will drive innovations in multimodal reasoning systems for healthcare scenarios, ultimately contributing to smarter emergency response systems and more effective medical education platforms in multilingual communities. Our official website is https://cmivqa.github.io/
ReGraP-LLaVA: Reasoning enabled Graph-based Personalized Large Language and Vision Assistant
May 06, 2025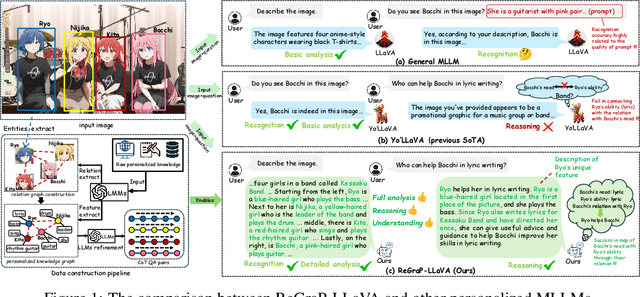

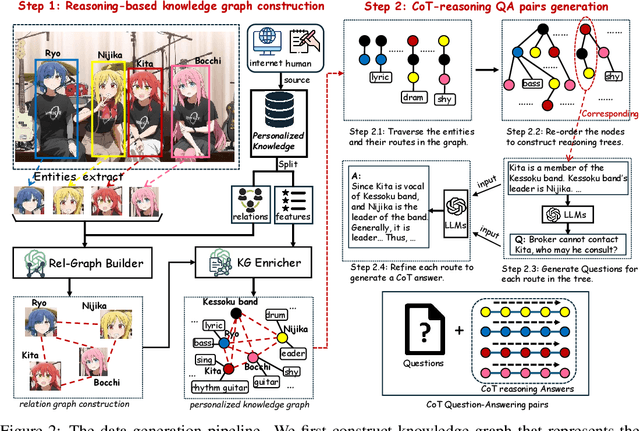
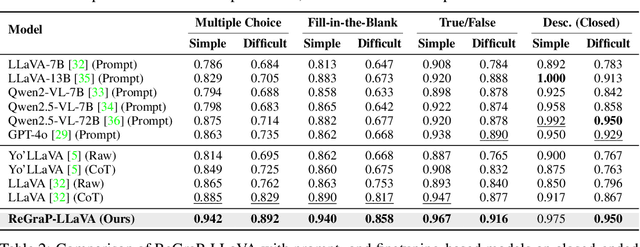
Recent advances in personalized MLLMs enable effective capture of user-specific concepts, supporting both recognition of personalized concepts and contextual captioning. However, humans typically explore and reason over relations among objects and individuals, transcending surface-level information to achieve more personalized and contextual understanding. To this end, existing methods may face three main limitations: Their training data lacks multi-object sets in which relations among objects are learnable. Building on the limited training data, their models overlook the relations between different personalized concepts and fail to reason over them. Their experiments mainly focus on a single personalized concept, where evaluations are limited to recognition and captioning tasks. To address the limitations, we present a new dataset named ReGraP, consisting of 120 sets of personalized knowledge. Each set includes images, KGs, and CoT QA pairs derived from the KGs, enabling more structured and sophisticated reasoning pathways. We propose ReGraP-LLaVA, an MLLM trained with the corresponding KGs and CoT QA pairs, where soft and hard graph prompting methods are designed to align KGs within the model's semantic space. We establish the ReGraP Benchmark, which contains diverse task types: multiple-choice, fill-in-the-blank, True/False, and descriptive questions in both open- and closed-ended settings. The proposed benchmark is designed to evaluate the relational reasoning and knowledge-connection capability of personalized MLLMs. We conduct experiments on the proposed ReGraP-LLaVA and other competitive MLLMs. Results show that the proposed model not only learns personalized knowledge but also performs relational reasoning in responses, achieving the SoTA performance compared with the competitive methods. All the codes and datasets are released at: https://github.com/xyfyyds/ReGraP.
DeepReview: Improving LLM-based Paper Review with Human-like Deep Thinking Process
Mar 11, 2025Large Language Models (LLMs) are increasingly utilized in scientific research assessment, particularly in automated paper review. However, existing LLM-based review systems face significant challenges, including limited domain expertise, hallucinated reasoning, and a lack of structured evaluation. To address these limitations, we introduce DeepReview, a multi-stage framework designed to emulate expert reviewers by incorporating structured analysis, literature retrieval, and evidence-based argumentation. Using DeepReview-13K, a curated dataset with structured annotations, we train DeepReviewer-14B, which outperforms CycleReviewer-70B with fewer tokens. In its best mode, DeepReviewer-14B achieves win rates of 88.21\% and 80.20\% against GPT-o1 and DeepSeek-R1 in evaluations. Our work sets a new benchmark for LLM-based paper review, with all resources publicly available. The code, model, dataset and demo have be released in http://ai-researcher.net.
Small but Mighty: Enhancing Time Series Forecasting with Lightweight LLMs
Mar 05, 2025While LLMs have demonstrated remarkable potential in time series forecasting, their practical deployment remains constrained by excessive computational demands and memory footprints. Existing LLM-based approaches typically suffer from three critical limitations: Inefficient parameter utilization in handling numerical time series patterns; Modality misalignment between continuous temporal signals and discrete text embeddings; and Inflexibility for real-time expert knowledge integration. We present SMETimes, the first systematic investigation of sub-3B parameter SLMs for efficient and accurate time series forecasting. Our approach centers on three key innovations: A statistically-enhanced prompting mechanism that bridges numerical time series with textual semantics through descriptive statistical features; A adaptive fusion embedding architecture that aligns temporal patterns with language model token spaces through learnable parameters; And a dynamic mixture-of-experts framework enabled by SLMs' computational efficiency, adaptively combining base predictions with domain-specific models. Extensive evaluations across seven benchmark datasets demonstrate that our 3B-parameter SLM achieves state-of-the-art performance on five primary datasets while maintaining 3.8x faster training and 5.2x lower memory consumption compared to 7B-parameter LLM baselines. Notably, the proposed model exhibits better learning capabilities, achieving 12.3% lower MSE than conventional LLM. Ablation studies validate that our statistical prompting and cross-modal fusion modules respectively contribute 15.7% and 18.2% error reduction in long-horizon forecasting tasks. By redefining the efficiency-accuracy trade-off landscape, this work establishes SLMs as viable alternatives to resource-intensive LLMs for practical time series forecasting. Code and models are available at https://github.com/xiyan1234567/SMETimes.
CycleResearcher: Improving Automated Research via Automated Review
Oct 28, 2024The automation of scientific discovery has been a long-standing goal within the research community, driven by the potential to accelerate knowledge creation. While significant progress has been made using commercial large language models (LLMs) as research assistants or idea generators, the possibility of automating the entire research process with open-source LLMs remains largely unexplored. This paper explores the feasibility of using open-source post-trained LLMs as autonomous agents capable of performing the full cycle of automated research and review, from literature review and manuscript preparation to peer review and paper revision. Our iterative preference training framework consists of CycleResearcher, which conducts research tasks, and CycleReviewer, which simulates the peer review process, providing iterative feedback via reinforcement learning. To train these models, we develop two new datasets, Review-5k and Research-14k, reflecting real-world machine learning research and peer review dynamics. Our results demonstrate that CycleReviewer achieves a 26.89\% improvement in mean absolute error (MAE) over individual human reviewers in predicting paper scores, indicating that LLMs can surpass expert-level performance in research evaluation. In research, the papers generated by the CycleResearcher model achieved a score of 5.36 in simulated peer reviews, surpassing the preprint level of 5.24 from human experts and approaching the accepted paper level of 5.69. This work represents a significant step toward fully automated scientific inquiry, providing ethical safeguards and advancing AI-driven research capabilities. The code, dataset and model weight are released at \url{http://github/minjun-zhu/Researcher}.