 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFBNetV3: Joint Architecture-Recipe Search using Neural Acquisition Function
Jun 07, 2020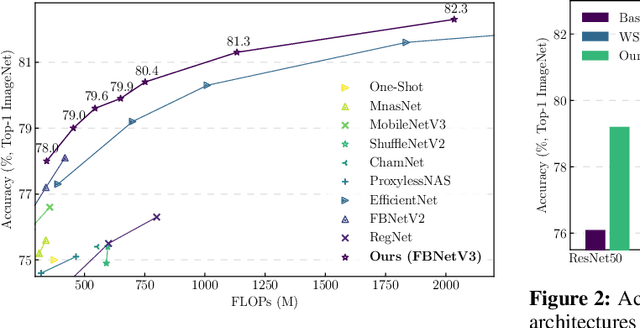
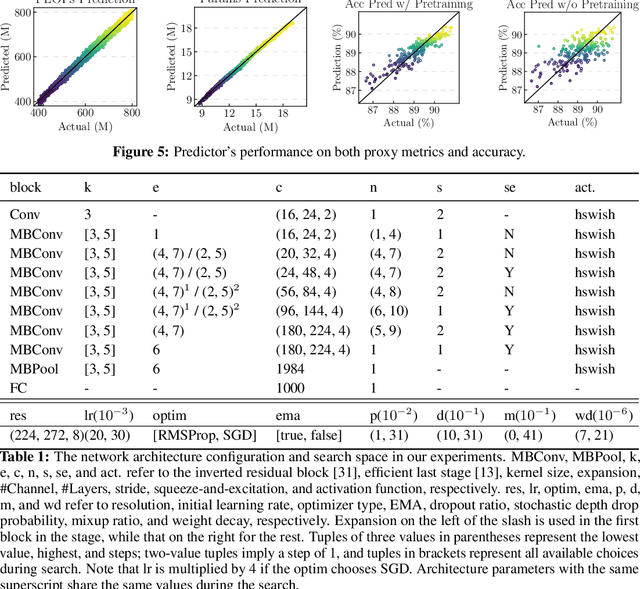

Neural Architecture Search (NAS) yields state-of-the-art neural networks that outperform their best manually-designed counterparts. However, previous NAS methods search for architectures under one training recipe (i.e., training hyperparameters), ignoring the significance of training recipes and overlooking superior architectures under other training recipes. Thus, they fail to find higher-accuracy architecture-recipe combinations. To address this oversight, we present JointNAS to search both (a) architectures and (b) their corresponding training recipes. To accomplish this, we introduce a neural acquisition function that scores architectures and training recipes jointly. Following pre-training on a proxy dataset, this acquisition function guides both coarse-grained and fine-grained searches to produce FBNetV3. FBNetV3 is a family of state-of-the-art compact ImageNet models, outperforming both automatically and manually-designed architectures. For example, FBNetV3 matches both EfficientNet and ResNeSt accuracy with 1.4x and 5.0x fewer FLOPs, respectively. Furthermore, the JointNAS-searched training recipe yields significant performance gains across different networks and tasks.
FBNetV2: Differentiable Neural Architecture Search for Spatial and Channel Dimensions
Apr 12, 2020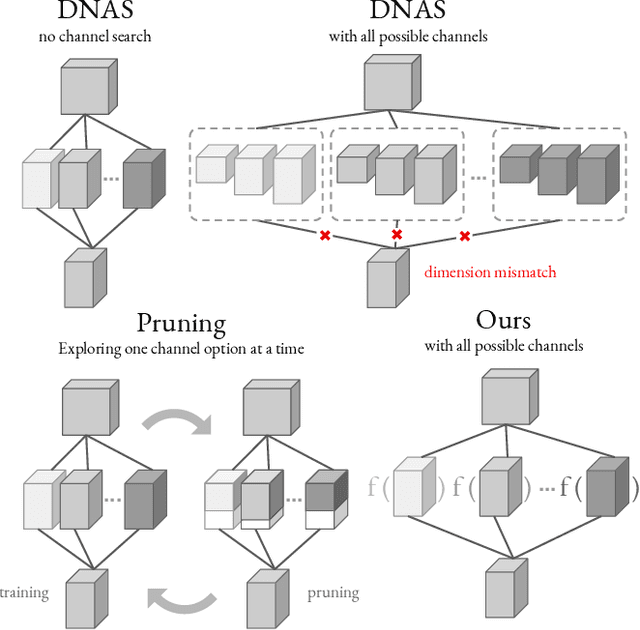
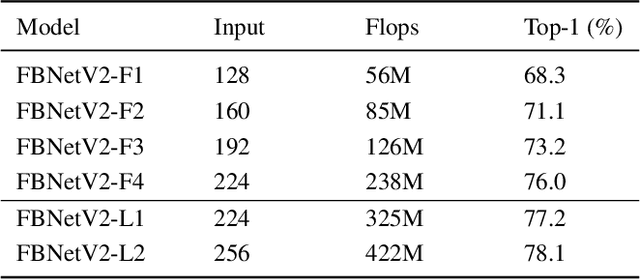
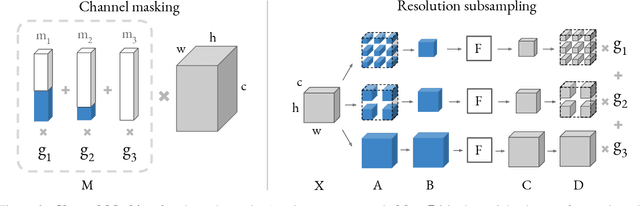
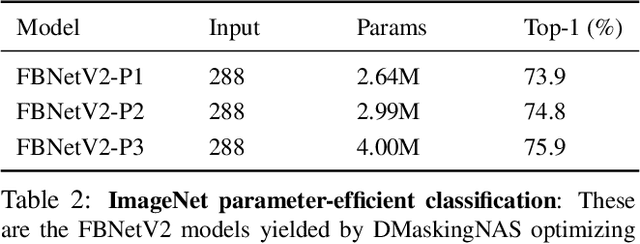
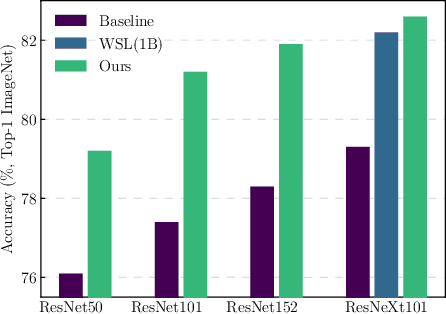
Differentiable Neural Architecture Search (DNAS) has demonstrated great success in designing state-of-the-art, efficient neural networks. However, DARTS-based DNAS's search space is small when compared to other search methods', since all candidate network layers must be explicitly instantiated in memory. To address this bottleneck, we propose a memory and computationally efficient DNAS variant: DMaskingNAS. This algorithm expands the search space by up to $10^{14}\times$ over conventional DNAS, supporting searches over spatial and channel dimensions that are otherwise prohibitively expensive: input resolution and number of filters. We propose a masking mechanism for feature map reuse, so that memory and computational costs stay nearly constant as the search space expands. Furthermore, we employ effective shape propagation to maximize per-FLOP or per-parameter accuracy. The searched FBNetV2s yield state-of-the-art performance when compared with all previous architectures. With up to 421$\times$ less search cost, DMaskingNAS finds models with 0.9% higher accuracy, 15% fewer FLOPs than MobileNetV3-Small; and with similar accuracy but 20% fewer FLOPs than Efficient-B0. Furthermore, our FBNetV2 outperforms MobileNetV3 by 2.6% in accuracy, with equivalent model size. FBNetV2 models are open-sourced at https://github.com/facebookresearch/mobile-vision.
SqueezeSegV3: Spatially-Adaptive Convolution for Efficient Point-Cloud Segmentation
Apr 03, 2020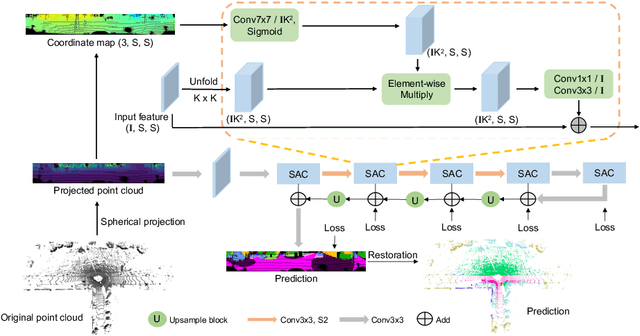
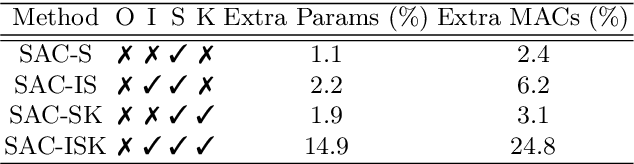
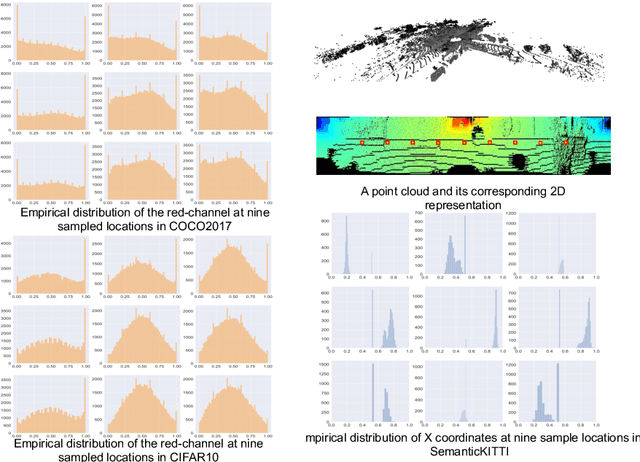
LiDAR point-cloud segmentation is an important problem for many applications. For large-scale point cloud segmentation, the \textit{de facto} method is to project a 3D point cloud to get a 2D LiDAR image and use convolutions to process it. Despite the similarity between regular RGB and LiDAR images, we discover that the feature distribution of LiDAR images changes drastically at different image locations. Using standard convolutions to process such LiDAR images is problematic, as convolution filters pick up local features that are only active in specific regions in the image. As a result, the capacity of the network is under-utilized and the segmentation performance decreases. To fix this, we propose Spatially-Adaptive Convolution (SAC) to adopt different filters for different locations according to the input image. SAC can be computed efficiently since it can be implemented as a series of element-wise multiplications, im2col, and standard convolution. It is a general framework such that several previous methods can be seen as special cases of SAC. Using SAC, we build SqueezeSegV3 for LiDAR point-cloud segmentation and outperform all previous published methods by at least 3.7% mIoU on the SemanticKITTI benchmark with comparable inference speed.
Algorithm-hardware Co-design for Deformable Convolution
Feb 19, 2020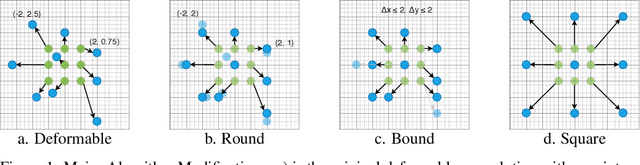
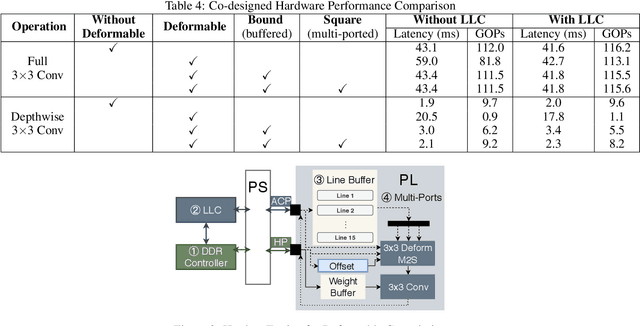
FPGAs provide a flexible and efficient platform to accelerate rapidly-changing algorithms for computer vision. The majority of existing work focuses on accelerating image classification, while other fundamental vision problems, including object detection and instance segmentation, have not been adequately addressed. Compared with image classification, detection problems are more sensitive to the spatial variance of objects, and therefore, require specialized convolutions to aggregate spatial information. To address this, recent work proposes dynamic deformable convolution to augment regular convolutions. Regular convolutions process a fixed grid of pixels across all the spatial locations in an image, while dynamic deformable convolutions may access arbitrary pixels in the image and the access pattern is input-dependent and varies per spatial location. These properties lead to inefficient memory accesses of inputs with existing hardware. In this work, we first investigate the overhead of the deformable convolution on embedded FPGA SoCs, and then show the accuracy-latency tradeoffs for a set of algorithm modifications including full versus depthwise, fixed-shape, and limited-range. These modifications benefit the energy efficiency for embedded devices in general as they reduce the compute complexity. We then build an efficient object detection network with modified deformable convolutions and quantize the network using state-of-the-art quantization methods. We implement a unified hardware engine on FPGA to support all the operations in the network. Preliminary experiments show that little accuracy is compromised and speedup can be achieved with our co-design optimization for the deformable convolution.
Domain-Aware Dynamic Networks
Nov 26, 2019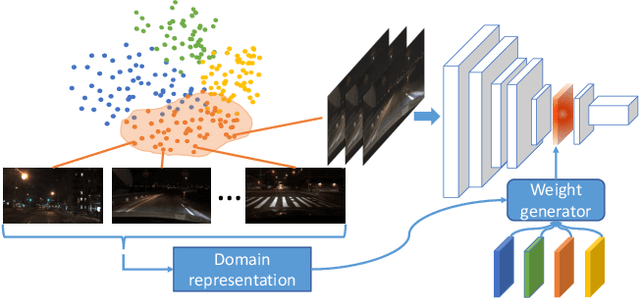
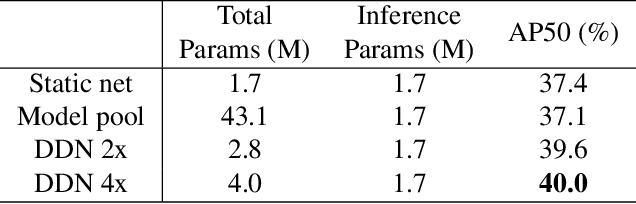
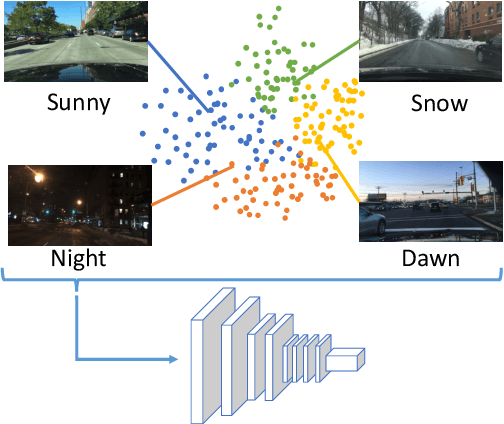
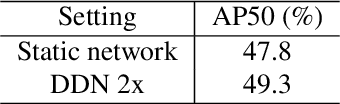
Deep neural networks with more parameters and FLOPs have higher capacity and generalize better to diverse domains. But to be deployed on edge devices, the model's complexity has to be constrained due to limited compute resource. In this work, we propose a method to improve the model capacity without increasing inference-time complexity. Our method is based on an assumption of data locality: for an edge device, within a short period of time, the input data to the device are sampled from a single domain with relatively low diversity. Therefore, it is possible to utilize a specialized, low-complexity model to achieve good performance in that input domain. To leverage this, we propose Domain-aware Dynamic Network (DDN), which is a high-capacity dynamic network in which each layer contains multiple weights. During inference, based on the input domain, DDN dynamically combines those weights into one single weight that specializes in the given domain. This way, DDN can keep the inference-time complexity low but still maintain a high capacity. Experiments show that without increasing the parameters, FLOPs, and actual latency, DDN achieves up to 2.6\% higher AP50 than a static network on the BDD100K object-detection benchmark.
Efficient Deep Neural Networks
Aug 20, 2019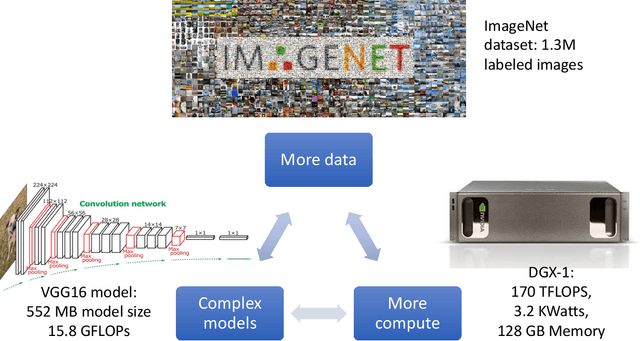
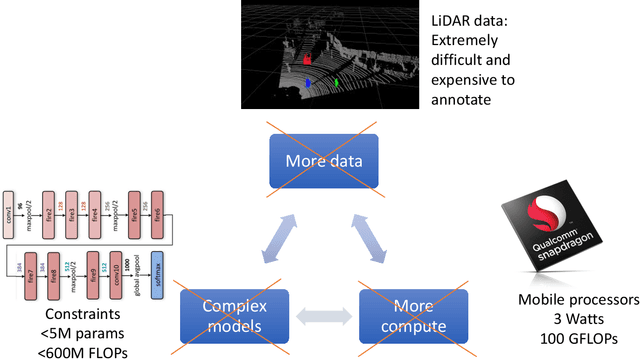
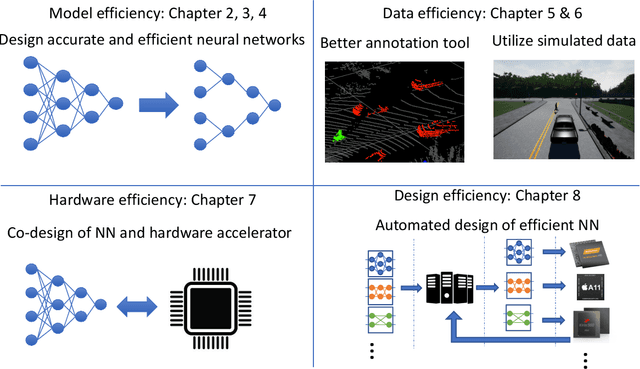
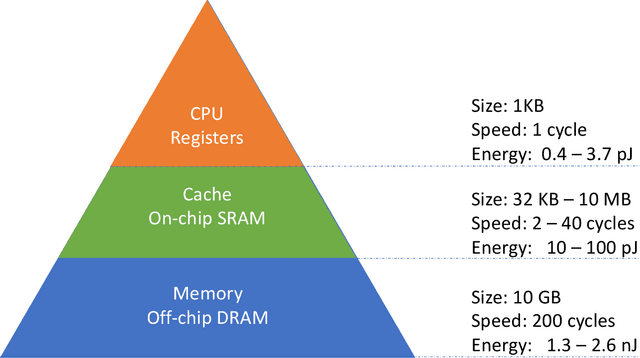
The success of deep neural networks (DNNs) is attributable to three factors: increased compute capacity, more complex models, and more data. These factors, however, are not always present, especially for edge applications such as autonomous driving, augmented reality, and internet-of-things. Training DNNs requires a large amount of data, which is difficult to obtain. Edge devices such as mobile phones have limited compute capacity, and therefore, require specialized and efficient DNNs. However, due to the enormous design space and prohibitive training costs, designing efficient DNNs for different target devices is challenging. So the question is, with limited data, compute capacity, and model complexity, can we still successfully apply deep neural networks? This dissertation focuses on the above problems and improving the efficiency of deep neural networks at four levels. Model efficiency: we designed neural networks for various computer vision tasks and achieved more than 10x faster speed and lower energy. Data efficiency: we developed an advanced tool that enables 6.2x faster annotation of a LiDAR point cloud. We also leveraged domain adaptation to utilize simulated data, bypassing the need for real data. Hardware efficiency: we co-designed neural networks and hardware accelerators and achieved 11.6x faster inference. Design efficiency: the process of finding the optimal neural networks is time-consuming. Our automated neural architecture search algorithms discovered, using 421x lower computational cost than previous search methods, models with state-of-the-art accuracy and efficiency.
LATTE: Accelerating LiDAR Point Cloud Annotation via Sensor Fusion, One-Click Annotation, and Tracking
Apr 19, 2019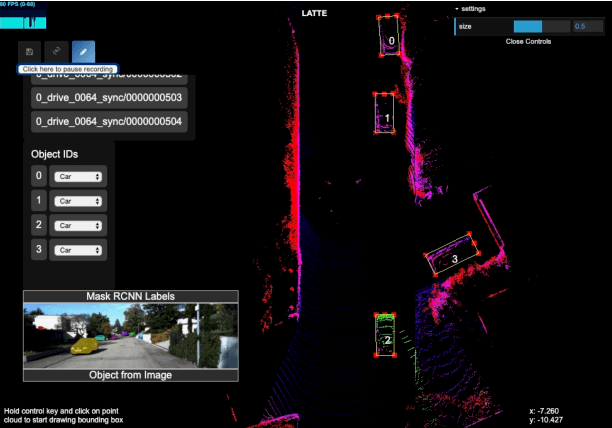
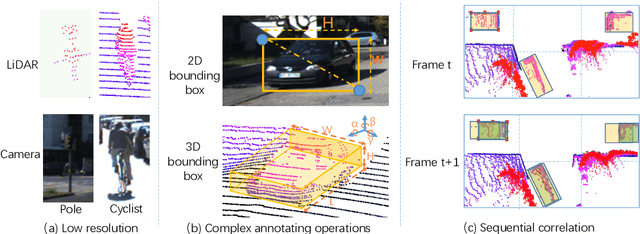
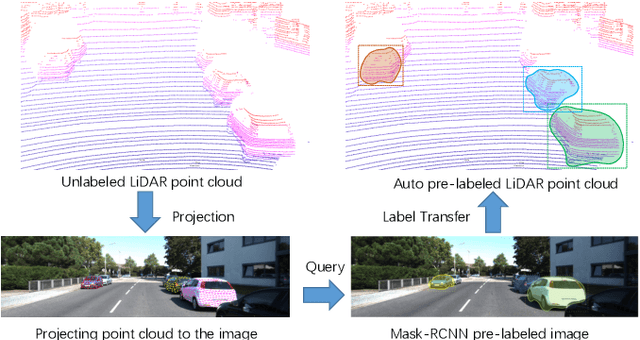
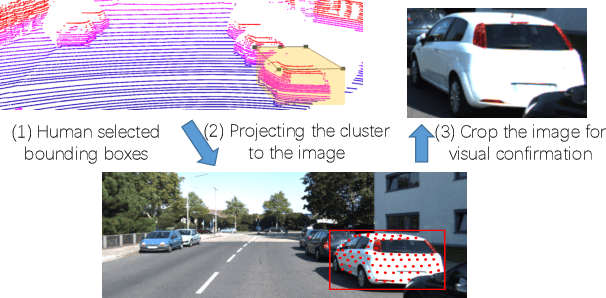
LiDAR (Light Detection And Ranging) is an essential and widely adopted sensor for autonomous vehicles, particularly for those vehicles operating at higher levels (L4-L5) of autonomy. Recent work has demonstrated the promise of deep-learning approaches for LiDAR-based detection. However, deep-learning algorithms are extremely data hungry, requiring large amounts of labeled point-cloud data for training and evaluation. Annotating LiDAR point cloud data is challenging due to the following issues: 1) A LiDAR point cloud is usually sparse and has low resolution, making it difficult for human annotators to recognize objects. 2) Compared to annotation on 2D images, the operation of drawing 3D bounding boxes or even point-wise labels on LiDAR point clouds is more complex and time-consuming. 3) LiDAR data are usually collected in sequences, so consecutive frames are highly correlated, leading to repeated annotations. To tackle these challenges, we propose LATTE, an open-sourced annotation tool for LiDAR point clouds. LATTE features the following innovations: 1) Sensor fusion: We utilize image-based detection algorithms to automatically pre-label a calibrated image, and transfer the labels to the point cloud. 2) One-click annotation: Instead of drawing 3D bounding boxes or point-wise labels, we simplify the annotation to just one click on the target object, and automatically generate the bounding box for the target. 3) Tracking: we integrate tracking into sequence annotation such that we can transfer labels from one frame to subsequent ones and therefore significantly reduce repeated labeling. Experiments show the proposed features accelerate the annotation speed by 6.2x and significantly improve label quality with 23.6% and 2.2% higher instance-level precision and recall, and 2.0% higher bounding box IoU. LATTE is open-sourced at https://github.com/bernwang/latte.
ChamNet: Towards Efficient Network Design through Platform-Aware Model Adaptation
Dec 21, 2018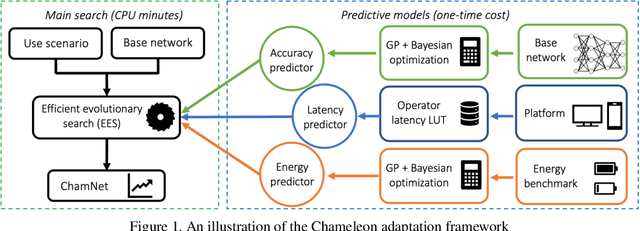
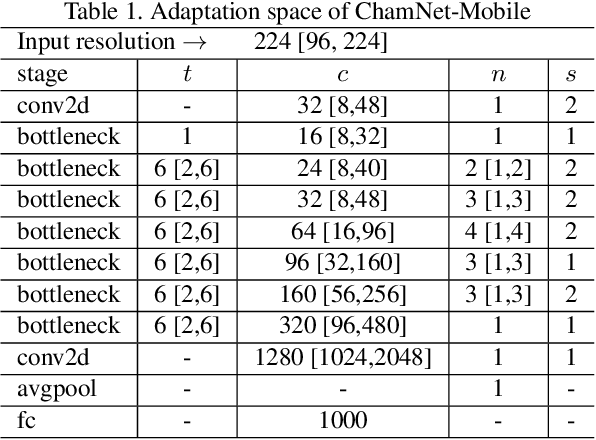
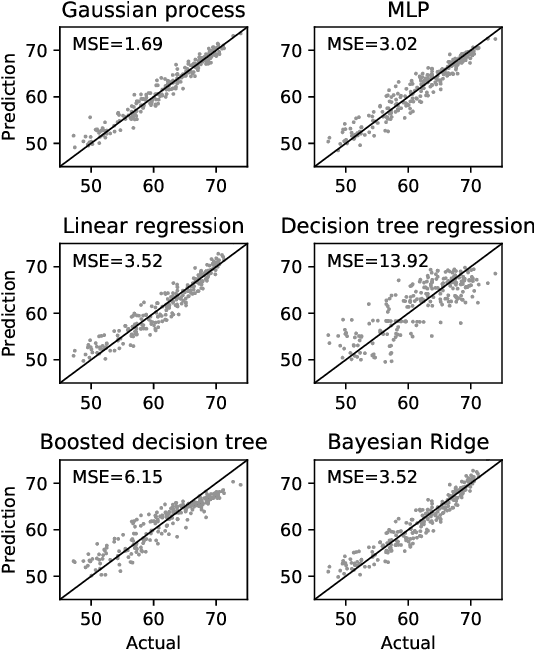
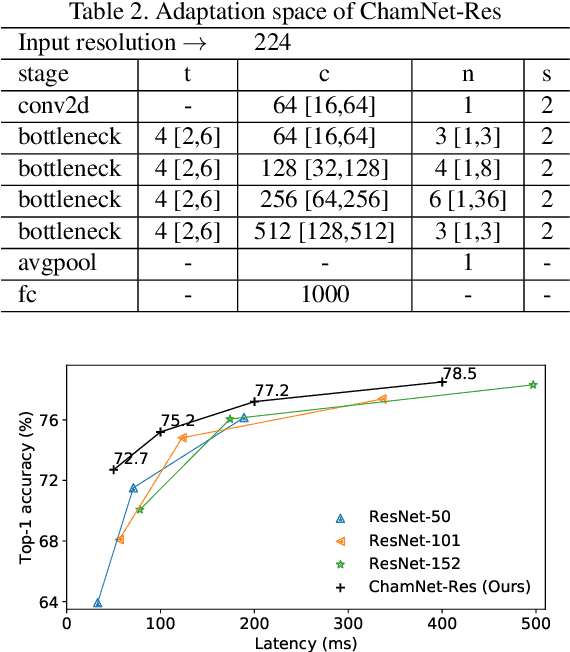
This paper proposes an efficient neural network (NN) architecture design methodology called Chameleon that honors given resource constraints. Instead of developing new building blocks or using computationally-intensive reinforcement learning algorithms, our approach leverages existing efficient network building blocks and focuses on exploiting hardware traits and adapting computation resources to fit target latency and/or energy constraints. We formulate platform-aware NN architecture search in an optimization framework and propose a novel algorithm to search for optimal architectures aided by efficient accuracy and resource (latency and/or energy) predictors. At the core of our algorithm lies an accuracy predictor built atop Gaussian Process with Bayesian optimization for iterative sampling. With a one-time building cost for the predictors, our algorithm produces state-of-the-art model architectures on different platforms under given constraints in just minutes. Our results show that adapting computation resources to building blocks is critical to model performance. Without the addition of any bells and whistles, our models achieve significant accuracy improvements against state-of-the-art hand-crafted and automatically designed architectures. We achieve 73.8% and 75.3% top-1 accuracy on ImageNet at 20ms latency on a mobile CPU and DSP. At reduced latency, our models achieve up to 8.5% (4.8%) and 6.6% (9.3%) absolute top-1 accuracy improvements compared to MobileNetV2 and MnasNet, respectively, on a mobile CPU (DSP), and 2.7% (4.6%) and 5.6% (2.6%) accuracy gains over ResNet-101 and ResNet-152, respectively, on an Nvidia GPU (Intel CPU).
FBNet: Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture Search
Dec 14, 2018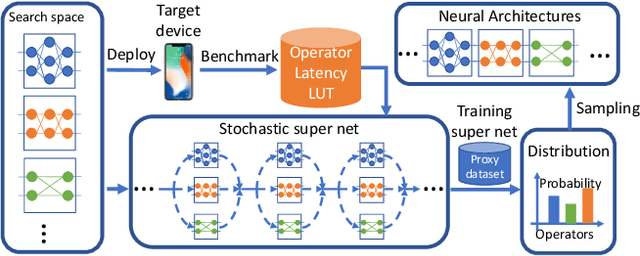
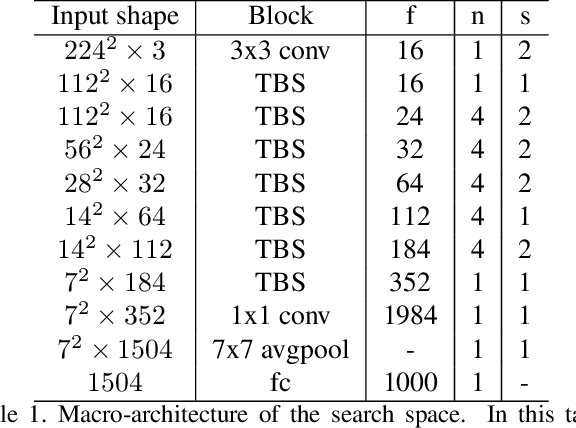
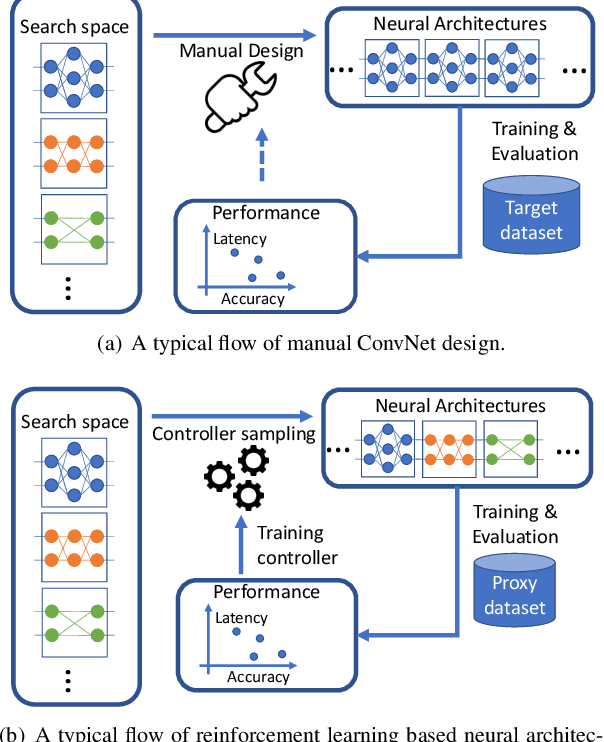
Designing accurate and efficient ConvNets for mobile devices is challenging because the design space is combinatorially large. Due to this, previous neural architecture search (NAS) methods are computationally expensive. ConvNet architecture optimality depends on factors such as input resolution and target devices. However, existing approaches are too expensive for case-by-case redesigns. Also, previous work focuses primarily on reducing FLOPs, but FLOP count does not always reflect actual latency. To address these, we propose a differentiable neural architecture search (DNAS) framework that uses gradient-based methods to optimize ConvNet architectures, avoiding enumerating and training individual architectures separately as in previous methods. FBNets, a family of models discovered by DNAS surpass state-of-the-art models both designed manually and generated automatically. FBNet-B achieves 74.1% top-1 accuracy on ImageNet with 295M FLOPs and 23.1 ms latency on a Samsung S8 phone, 2.4x smaller and 1.5x faster than MobileNetV2-1.3 with similar accuracy. Despite higher accuracy and lower latency than MnasNet, we estimate FBNet-B's search cost is 420x smaller than MnasNet's, at only 216 GPU-hours. Searched for different resolutions and channel sizes, FBNets achieve 1.5% to 6.4% higher accuracy than MobileNetV2. The smallest FBNet achieves 50.2% accuracy and 2.9 ms latency (345 frames per second) on a Samsung S8. Over a Samsung-optimized FBNet, the iPhone-X-optimized model achieves a 1.4x speedup on an iPhone X.
Mixed Precision Quantization of ConvNets via Differentiable Neural Architecture Search
Nov 30, 2018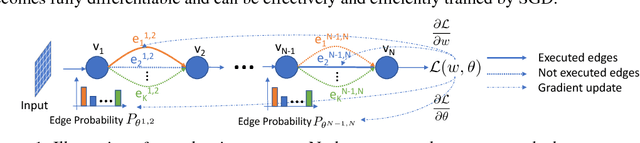
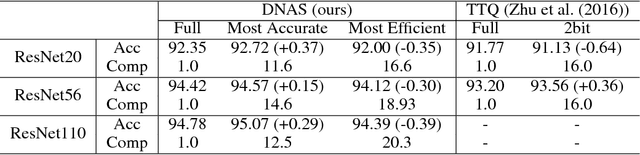
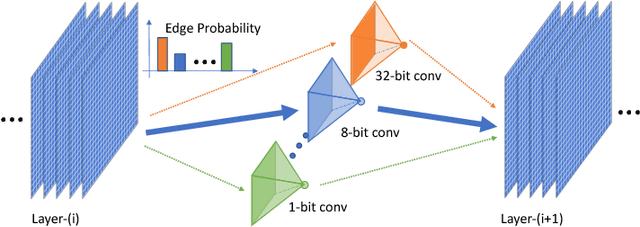

Recent work in network quantization has substantially reduced the time and space complexity of neural network inference, enabling their deployment on embedded and mobile devices with limited computational and memory resources. However, existing quantization methods often represent all weights and activations with the same precision (bit-width). In this paper, we explore a new dimension of the design space: quantizing different layers with different bit-widths. We formulate this problem as a neural architecture search problem and propose a novel differentiable neural architecture search (DNAS) framework to efficiently explore its exponential search space with gradient-based optimization. Experiments show we surpass the state-of-the-art compression of ResNet on CIFAR-10 and ImageNet. Our quantized models with 21.1x smaller model size or 103.9x lower computational cost can still outperform baseline quantized or even full precision models.