 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM$^2$RNN: Non-Linear RNNs with Matrix-Valued States for Scalable Language Modeling
Mar 15, 2026Transformers are highly parallel but are limited to computations in the TC$^0$ complexity class, excluding tasks such as entity tracking and code execution that provably require greater expressive power. Motivated by this limitation, we revisit non-linear Recurrent Neural Networks (RNNs) for language modeling and introduce Matrix-to-Matrix RNN (M$^2$RNN): an architecture with matrix-valued hidden states and expressive non-linear state transitions. We demonstrate that the language modeling performance of non-linear RNNs is limited by their state size. We also demonstrate how the state size expansion mechanism enables efficient use of tensor cores. Empirically, M$^2$RNN achieves perfect state tracking generalization at sequence lengths not seen during training. These benefits also translate to large-scale language modeling. In hybrid settings that interleave recurrent layers with attention, Hybrid M$^2$RNN outperforms equivalent Gated DeltaNet hybrids by $0.4$-$0.5$ perplexity points on a 7B MoE model, while using $3\times$ smaller state sizes for the recurrent layers. Notably, replacing even a single recurrent layer with M$^2$RNN in an existing hybrid architecture yields accuracy gains comparable to Hybrid M$^2$RNN with minimal impact on training throughput. Further, the Hybrid Gated DeltaNet models with a single M$^2$RNN layer also achieve superior long-context generalization, outperforming state-of-the-art hybrid linear attention architectures by up to $8$ points on LongBench. Together, these results establish non-linear RNN layers as a compelling building block for efficient and scalable language models.
Arming Data Agents with Tribal Knowledge
Feb 13, 2026Natural language to SQL (NL2SQL) translation enables non-expert users to query relational databases through natural language. Recently, NL2SQL agents, powered by the reasoning capabilities of Large Language Models (LLMs), have significantly advanced NL2SQL translation. Nonetheless, NL2SQL agents still make mistakes when faced with large-scale real-world databases because they lack knowledge of how to correctly leverage the underlying data (e.g., knowledge about the intent of each column) and form misconceptions about the data when querying it, leading to errors. Prior work has studied generating facts about the database to provide more context to NL2SQL agents, but such approaches simply restate database contents without addressing the agent's misconceptions. In this paper, we propose Tk-Boost, a bolt-on framework for augmenting any NL2SQL agent with tribal knowledge: knowledge that corrects the agent's misconceptions in querying the database accumulated through experience using the database. To accumulate experience, Tk-Boost first asks the NL2SQL agent to answer a few queries on the database, identifies the agent's misconceptions by analyzing its mistakes on the database, and generates tribal knowledge to address them. To enable accurate retrieval, Tk-Boost indexes this knowledge with applicability conditions that specify the query features for which the knowledge is useful. When answering new queries, Tk-Boost uses this knowledge to provide feedback to the NL2SQL agent, resolving the agent's misconceptions during SQL generation, and thus improving the agent's accuracy. Extensive experiments across the BIRD and Spider 2.0 benchmarks with various NL2SQL agents shows Tk-Boost improves NL2SQL agents accuracy by up to 16.9% on Spider 2.0 and 13.7% on BIRD
RedunCut: Measurement-Driven Sampling and Accuracy Performance Modeling for Low-Cost Live Video Analytics
Dec 30, 2025Live video analytics (LVA) runs continuously across massive camera fleets, but inference cost with modern vision models remains high. To address this, dynamic model size selection (DMSS) is an attractive approach: it is content-aware but treats models as black boxes, and could potentially reduce cost by up to 10x without model retraining or modification. Without ground truth labels at runtime, we observe that DMSS methods use two stages per segment: (i) sampling a few models to calculate prediction statistics (e.g., confidences), then (ii) selection of the model size from those statistics. Prior systems fail to generalize to diverse workloads, particularly to mobile videos and lower accuracy targets. We identify that the failure modes stem from inefficient sampling whose cost exceeds its benefit, and inaccurate per-segment accuracy prediction. In this work, we present RedunCut, a new DMSS system that addresses both: It uses a measurement-driven planner that estimates the cost-benefit tradeoff of sampling, and a lightweight, data-driven performance model to improve accuracy prediction. Across road-vehicle, drone, and surveillance videos and multiple model families and tasks, RedunCut reduces compute cost by 14-62% at fixed accuracy and remains robust to limited historical data and to drift.
Locality-aware Fair Scheduling in LLM Serving
Jan 24, 2025



Large language model (LLM) inference workload dominates a wide variety of modern AI applications, ranging from multi-turn conversation to document analysis. Balancing fairness and efficiency is critical for managing diverse client workloads with varying prefix patterns. Unfortunately, existing fair scheduling algorithms for LLM serving, such as Virtual Token Counter (VTC), fail to take prefix locality into consideration and thus suffer from poor performance. On the other hand, locality-aware scheduling algorithms in existing LLM serving frameworks tend to maximize the prefix cache hit rate without considering fair sharing among clients. This paper introduces the first locality-aware fair scheduling algorithm, Deficit Longest Prefix Match (DLPM), which can maintain a high degree of prefix locality with a fairness guarantee. We also introduce a novel algorithm, Double Deficit LPM (D$^2$LPM), extending DLPM for the distributed setup that can find a balance point among fairness, locality, and load-balancing. Our extensive evaluation demonstrates the superior performance of DLPM and D$^2$LPM in ensuring fairness while maintaining high throughput (up to 2.87$\times$ higher than VTC) and low per-client (up to 7.18$\times$ lower than state-of-the-art distributed LLM serving system) latency.
CARFF: Conditional Auto-encoded Radiance Field for 3D Scene Forecasting
Jan 31, 2024



We propose CARFF: Conditional Auto-encoded Radiance Field for 3D Scene Forecasting, a method for predicting future 3D scenes given past observations, such as 2D ego-centric images. Our method maps an image to a distribution over plausible 3D latent scene configurations using a probabilistic encoder, and predicts the evolution of the hypothesized scenes through time. Our latent scene representation conditions a global Neural Radiance Field (NeRF) to represent a 3D scene model, which enables explainable predictions and straightforward downstream applications. This approach extends beyond previous neural rendering work by considering complex scenarios of uncertainty in environmental states and dynamics. We employ a two-stage training of Pose-Conditional-VAE and NeRF to learn 3D representations. Additionally, we auto-regressively predict latent scene representations as a partially observable Markov decision process, utilizing a mixture density network. We demonstrate the utility of our method in realistic scenarios using the CARLA driving simulator, where CARFF can be used to enable efficient trajectory and contingency planning in complex multi-agent autonomous driving scenarios involving visual occlusions.
Prior Knowledge-Guided Attention in Self-Supervised Vision Transformers
Sep 07, 2022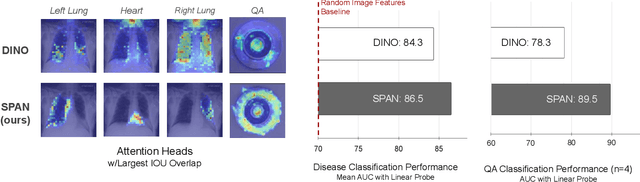
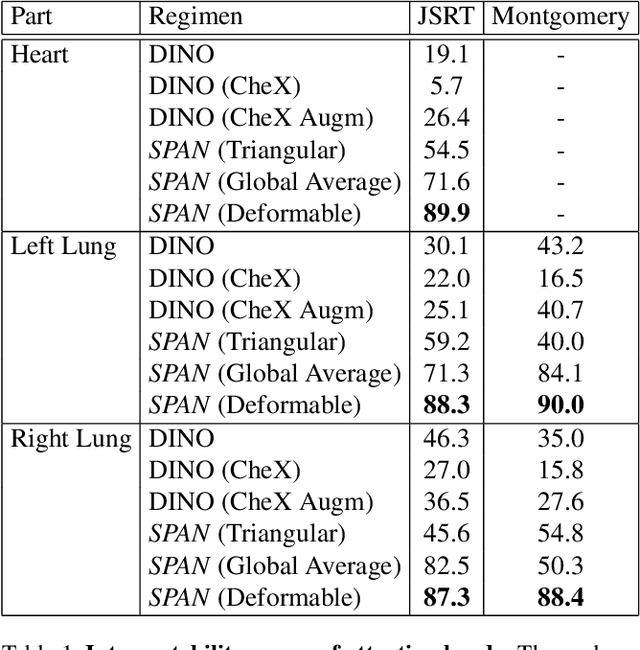
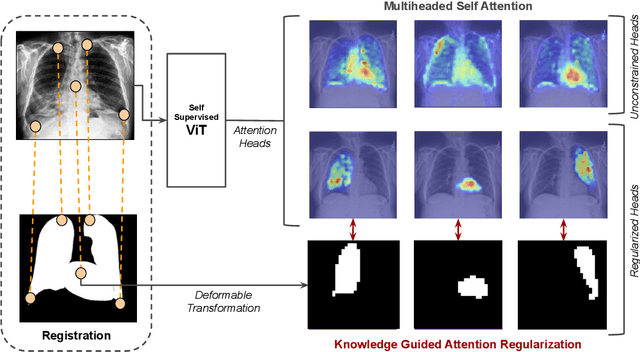

Recent trends in self-supervised representation learning have focused on removing inductive biases from training pipelines. However, inductive biases can be useful in settings when limited data are available or provide additional insight into the underlying data distribution. We present spatial prior attention (SPAN), a framework that takes advantage of consistent spatial and semantic structure in unlabeled image datasets to guide Vision Transformer attention. SPAN operates by regularizing attention masks from separate transformer heads to follow various priors over semantic regions. These priors can be derived from data statistics or a single labeled sample provided by a domain expert. We study SPAN through several detailed real-world scenarios, including medical image analysis and visual quality assurance. We find that the resulting attention masks are more interpretable than those derived from domain-agnostic pretraining. SPAN produces a 58.7 mAP improvement for lung and heart segmentation. We also find that our method yields a 2.2 mAUC improvement compared to domain-agnostic pretraining when transferring the pretrained model to a downstream chest disease classification task. Lastly, we show that SPAN pretraining leads to higher downstream classification performance in low-data regimes compared to domain-agnostic pretraining.
Context-Aware Streaming Perception in Dynamic Environments
Aug 16, 2022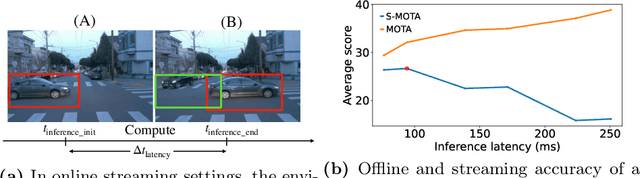
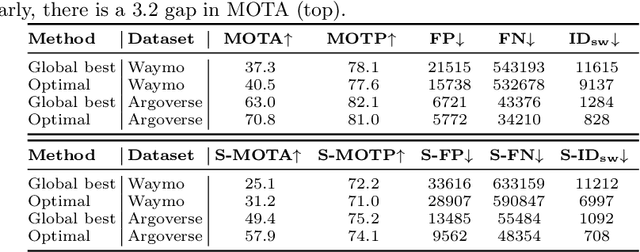
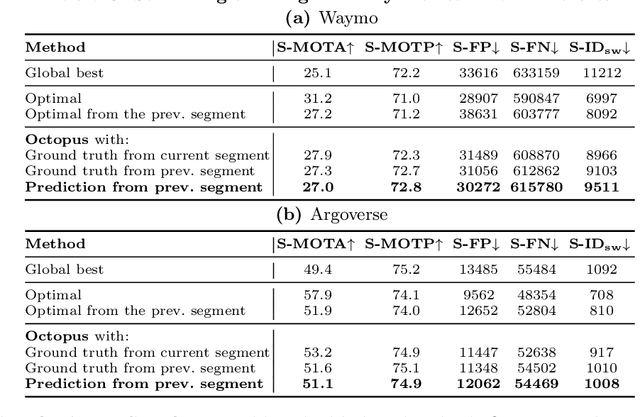
Efficient vision works maximize accuracy under a latency budget. These works evaluate accuracy offline, one image at a time. However, real-time vision applications like autonomous driving operate in streaming settings, where ground truth changes between inference start and finish. This results in a significant accuracy drop. Therefore, a recent work proposed to maximize accuracy in streaming settings on average. In this paper, we propose to maximize streaming accuracy for every environment context. We posit that scenario difficulty influences the initial (offline) accuracy difference, while obstacle displacement in the scene affects the subsequent accuracy degradation. Our method, Octopus, uses these scenario properties to select configurations that maximize streaming accuracy at test time. Our method improves tracking performance (S-MOTA) by 7.4% over the conventional static approach. Further, performance improvement using our method comes in addition to, and not instead of, advances in offline accuracy.
FogROS 2: An Adaptive and Extensible Platform for Cloud and Fog Robotics Using ROS 2
May 19, 2022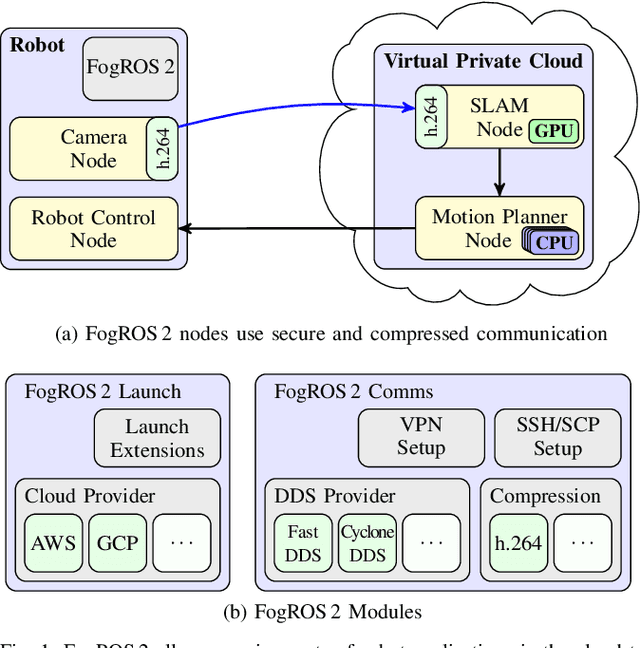
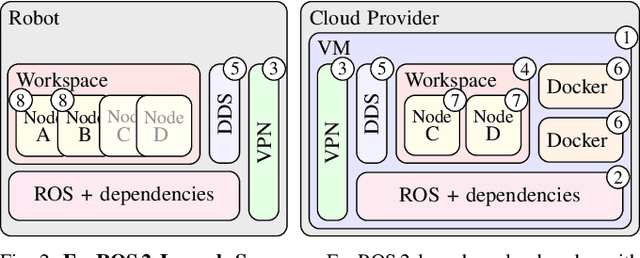
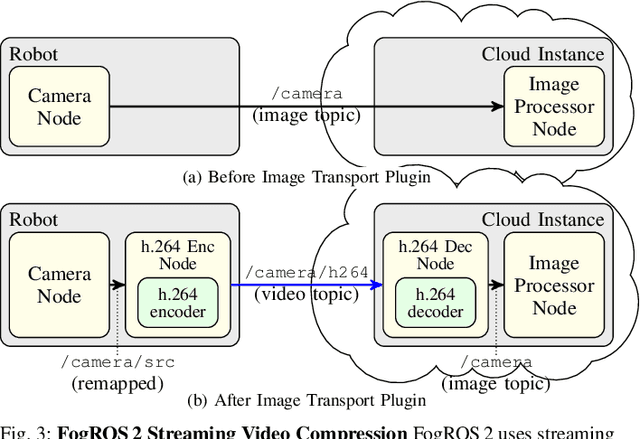
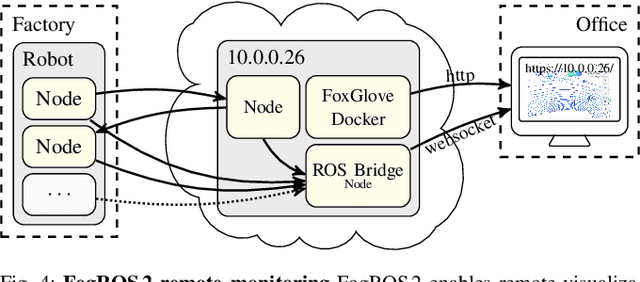
Mobility, power, and price points often dictate that robots do not have sufficient computing power on board to run modern robot algorithms at desired rates. Cloud computing providers such as AWS, GCP, and Azure offer immense computing power on demand, but tapping into that power from a robot is non-trivial. In this paper, we present FogROS 2, an easy-to-use, open-source platform to facilitate cloud and fog robotics compatible with the emerging ROS 2 standard, extending the open-source Robot Operating System (ROS). FogROS 2 provisions a cloud computer, deploys and launches ROS 2 nodes to the cloud computer, sets up secure networking between the robot and cloud, and starts the application running. FogROS 2 is completely redesigned and distinct from its predecessor to support ROS 2 applications, transparent video compression and communication, improved performance and security, support for multiple cloud-computing providers, and remote monitoring and visualization. We demonstrate in example applications that the performance gained by using cloud computers can overcome the network latency to significantly speed up robot performance. In examples, FogROS 2 reduces SLAM latency by 50%, reduces grasp planning time from 14s to 1.2s, and speeds up motion planning 28x. When compared to alternatives, FogROS 2 reduces network utilization by up to 3.8x. FogROS 2, source, examples, and documentation is available at https://github.com/BerkeleyAutomation/FogROS2 .
Reliable Visual Question Answering: Abstain Rather Than Answer Incorrectly
Apr 28, 2022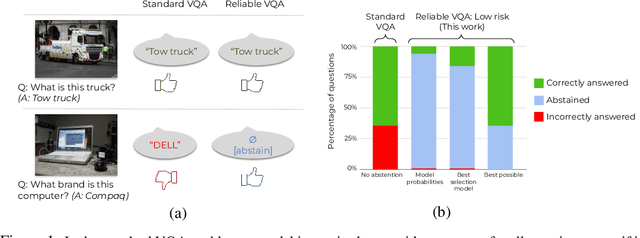
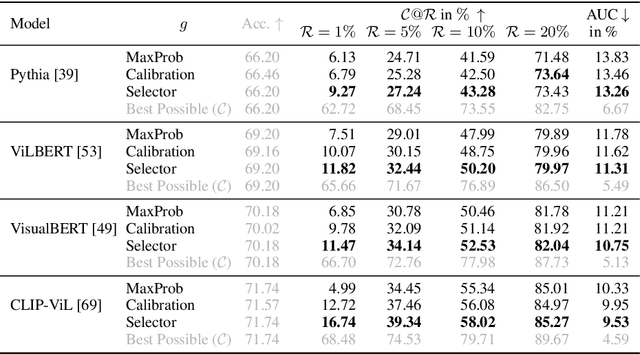


Machine learning has advanced dramatically, narrowing the accuracy gap to humans in multimodal tasks like visual question answering (VQA). However, while humans can say "I don't know" when they are uncertain (i.e., abstain from answering a question), such ability has been largely neglected in multimodal research, despite the importance of this problem to the usage of VQA in real settings. In this work, we promote a problem formulation for reliable VQA, where we prefer abstention over providing an incorrect answer. We first enable abstention capabilities for several VQA models, and analyze both their coverage, the portion of questions answered, and risk, the error on that portion. For that we explore several abstention approaches. We find that although the best performing models achieve over 71% accuracy on the VQA v2 dataset, introducing the option to abstain by directly using a model's softmax scores limits them to answering less than 8% of the questions to achieve a low risk of error (i.e., 1%). This motivates us to utilize a multimodal selection function to directly estimate the correctness of the predicted answers, which we show can triple the coverage from, for example, 5.0% to 16.7% at 1% risk. While it is important to analyze both coverage and risk, these metrics have a trade-off which makes comparing VQA models challenging. To address this, we also propose an Effective Reliability metric for VQA that places a larger cost on incorrect answers compared to abstentions. This new problem formulation, metric, and analysis for VQA provide the groundwork for building effective and reliable VQA models that have the self-awareness to abstain if and only if they don't know the answer.
The Carbon Footprint of Machine Learning Training Will Plateau, Then Shrink
Apr 11, 2022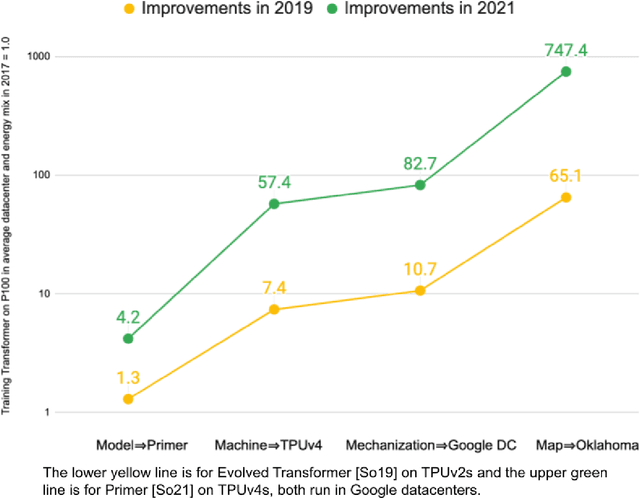
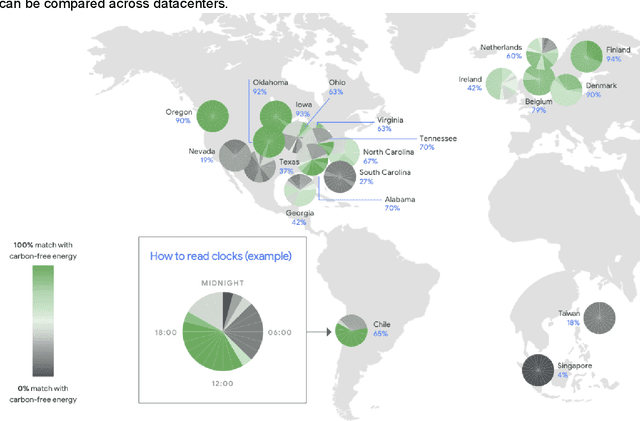
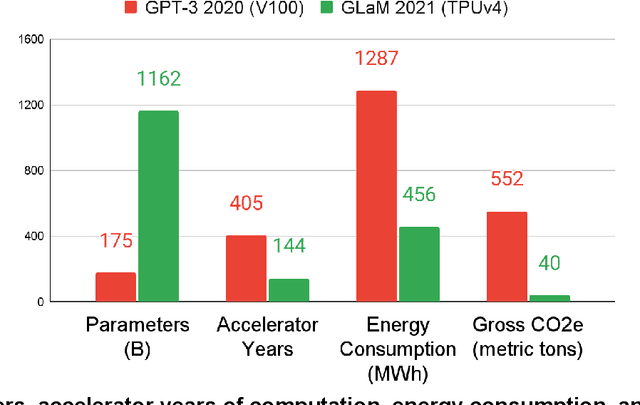
Machine Learning (ML) workloads have rapidly grown in importance, but raised concerns about their carbon footprint. Four best practices can reduce ML training energy by up to 100x and CO2 emissions up to 1000x. By following best practices, overall ML energy use (across research, development, and production) held steady at <15% of Google's total energy use for the past three years. If the whole ML field were to adopt best practices, total carbon emissions from training would reduce. Hence, we recommend that ML papers include emissions explicitly to foster competition on more than just model quality. Estimates of emissions in papers that omitted them have been off 100x-100,000x, so publishing emissions has the added benefit of ensuring accurate accounting. Given the importance of climate change, we must get the numbers right to make certain that we work on its biggest challenges.