 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReSkill: Reconciling Skill Creation with Policy Optimization in Agentic RL
Jun 01, 2026Agentic reinforcement learning (RL) enables LLM agents to improve continuously from environment rewards, yet the resulting policies do not systematically accumulate reusable strategies that generalize across tasks. Modular skills can provide such reusable strategies, yet existing skill-augmented RL methods decouple skill creation from policy optimization, risking adopting skills that conflict with the evolving policy. Inspired by Anthropic's Skill Creator, we introduce ReSkill, an RL-in-the-loop skill creation framework that reconciles skill evolution with policy learning. ReSkill exploits the group-wise structure of GRPO to naturally embed three mechanisms with only marginal additional overhead: (1) an assertion-driven skill creator that diagnoses failures from past experience and proposes conditional, trigger-based skill revisions; (2) within-group rollout sampling that enables controlled comparison of skill versions, capturing which version best supports the policy's ongoing learning; and (3) Thompson Sampling with adaptive discounting to balance exploration and exploitation in skill version selection as the policy evolves. Across several domains, ReSkill consistently outperforms existing memory and skill-based RL methods, with the largest gains on unseen tasks. Analysis of the skill lifecycle shows skills being automatically created, tested, refined, and pruned as the policy improves, demonstrating reconciled skill-policy co-evolution.
OPERA: Online Data Pruning for Efficient Retrieval Model Adaptation
Mar 17, 2026Domain-specific finetuning is essential for dense retrievers, yet not all training pairs contribute equally to the learning process. We introduce OPERA, a data pruning framework that exploits this heterogeneity to improve both the effectiveness and efficiency of retrieval model adaptation. We first investigate static pruning (SP), which retains only high-similarity query-document pairs, revealing an intrinsic quality-coverage tradeoff: ranking (NDCG) improves while retrieval (Recall) can degrade due to reduced query diversity. To resolve this tradeoff, we propose a two-stage dynamic pruning (DP) strategy that adaptively modulates sampling probabilities at both query and document levels throughout training, prioritizing high-quality examples while maintaining access to the full training set. Evaluations across eight datasets spanning six domains demonstrate the effectiveness of both approaches: SP improves ranking over standard finetuning (NDCG@10 +0.5\%), while DP achieves the strongest performance on both ranking (NDCG@10 +1.9\%) and retrieval (Recall@20 +0.7\%), with an average rank of 1.38 across all methods. These findings scale to Qwen3-Embedding, an LLM-based dense retriever, confirming architecture-agnostic benefits. Notably, DP reaches comparable performance in less than 50\% of the training time required by standard finetuning.
SenTSR-Bench: Thinking with Injected Knowledge for Time-Series Reasoning
Feb 23, 2026Time-series diagnostic reasoning is essential for many applications, yet existing solutions face a persistent gap: general reasoning large language models (GRLMs) possess strong reasoning skills but lack the domain-specific knowledge to understand complex time-series patterns. Conversely, fine-tuned time-series LLMs (TSLMs) understand these patterns but lack the capacity to generalize reasoning for more complicated questions. To bridge this gap, we propose a hybrid knowledge-injection framework that injects TSLM-generated insights directly into GRLM's reasoning trace, thereby achieving strong time-series reasoning with in-domain knowledge. As collecting data for knowledge injection fine-tuning is costly, we further leverage a reinforcement learning-based approach with verifiable rewards (RLVR) to elicit knowledge-rich traces without human supervision, then transfer such an in-domain thinking trace into GRLM for efficient knowledge injection. We further release SenTSR-Bench, a multivariate time-series-based diagnostic reasoning benchmark collected from real-world industrial operations. Across SenTSR-Bench and other public datasets, our method consistently surpasses TSLMs by 9.1%-26.1% and GRLMs by 7.9%-22.4%, delivering robust, context-aware time-series diagnostic insights.
Efficient Table Retrieval and Understanding with Multimodal Large Language Models
Feb 07, 2026Tabular data is frequently captured in image form across a wide range of real-world scenarios such as financial reports, handwritten records, and document scans. These visual representations pose unique challenges for machine understanding, as they combine both structural and visual complexities. While recent advances in Multimodal Large Language Models (MLLMs) show promising results in table understanding, they typically assume the relevant table is readily available. However, a more practical scenario involves identifying and reasoning over relevant tables from large-scale collections to answer user queries. To address this gap, we propose TabRAG, a framework that enables MLLMs to answer queries over large collections of table images. Our approach first retrieves candidate tables using jointly trained visual-text foundation models, then leverages MLLMs to perform fine-grained reranking of these candidates, and finally employs MLLMs to reason over the selected tables for answer generation. Through extensive experiments on a newly constructed dataset comprising 88,161 training and 9,819 testing samples across 8 benchmarks with 48,504 unique tables, we demonstrate that our framework significantly outperforms existing methods by 7.0% in retrieval recall and 6.1% in answer accuracy, offering a practical solution for real-world table understanding tasks.
MLZero: A Multi-Agent System for End-to-end Machine Learning Automation
May 20, 2025Existing AutoML systems have advanced the automation of machine learning (ML); however, they still require substantial manual configuration and expert input, particularly when handling multimodal data. We introduce MLZero, a novel multi-agent framework powered by Large Language Models (LLMs) that enables end-to-end ML automation across diverse data modalities with minimal human intervention. A cognitive perception module is first employed, transforming raw multimodal inputs into perceptual context that effectively guides the subsequent workflow. To address key limitations of LLMs, such as hallucinated code generation and outdated API knowledge, we enhance the iterative code generation process with semantic and episodic memory. MLZero demonstrates superior performance on MLE-Bench Lite, outperforming all competitors in both success rate and solution quality, securing six gold medals. Additionally, when evaluated on our Multimodal AutoML Agent Benchmark, which includes 25 more challenging tasks spanning diverse data modalities, MLZero outperforms the competing methods by a large margin with a success rate of 0.92 (+263.6\%) and an average rank of 2.28. Our approach maintains its robust effectiveness even with a compact 8B LLM, outperforming full-size systems from existing solutions.
Visual Instruction Tuning with Chain of Region-of-Interest
May 11, 2025High-resolution (HR) images are pivotal for enhancing the recognition and understanding capabilities of multimodal large language models (MLLMs). However, directly increasing image resolution can significantly escalate computational demands. In this study, we propose a method called Chain of Region-of-Interest (CoRoI) for Visual Instruction Tuning, aimed at alleviating the computational burden associated with high-resolution images for MLLMs. Drawing inspiration from the selective nature of the human visual system, we recognize that not all regions within high-resolution images carry equal importance. CoRoI seeks to identify and prioritize the most informative regions, thereby enhancing multimodal visual comprehension and recognition while circumventing the need for processing lengthy HR image tokens. Through extensive experiments on 11 benchmarks, we validate the efficacy of CoRoI across varying sizes, ranging from 7B to 34B in parameters. Our models consistently demonstrate superior performance across diverse multimodal benchmarks and tasks. Notably, our method outperforms LLaVA-NeXT on almost all benchmarks and our finetuned 34B model surpasses proprietary methods like Gemini Pro 1.0 on six benchmarks, as well as outperforming GPT-4V on MMB, SEED-I, and MME.
PipeRAG: Fast Retrieval-Augmented Generation via Algorithm-System Co-design
Mar 08, 2024



Retrieval-augmented generation (RAG) can enhance the generation quality of large language models (LLMs) by incorporating external token databases. However, retrievals from large databases can constitute a substantial portion of the overall generation time, particularly when retrievals are periodically performed to align the retrieved content with the latest states of generation. In this paper, we introduce PipeRAG, a novel algorithm-system co-design approach to reduce generation latency and enhance generation quality. PipeRAG integrates (1) pipeline parallelism to enable concurrent retrieval and generation processes, (2) flexible retrieval intervals to maximize the efficiency of pipeline parallelism, and (3) a performance model to automatically balance retrieval quality and latency based on the generation states and underlying hardware. Our evaluation shows that, by combining the three aforementioned methods, PipeRAG achieves up to 2.6$\times$ speedup in end-to-end generation latency while improving generation quality. These promising results showcase the effectiveness of co-designing algorithms with underlying systems, paving the way for the adoption of PipeRAG in future RAG systems.
Improving Context-Based Meta-Reinforcement Learning with Self-Supervised Trajectory Contrastive Learning
Mar 10, 2021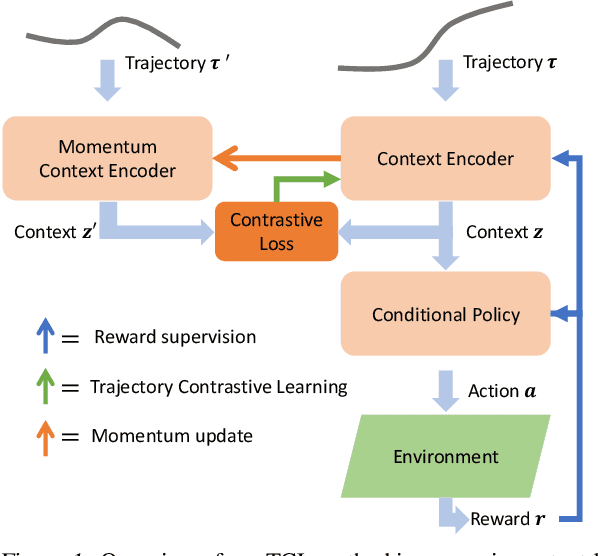
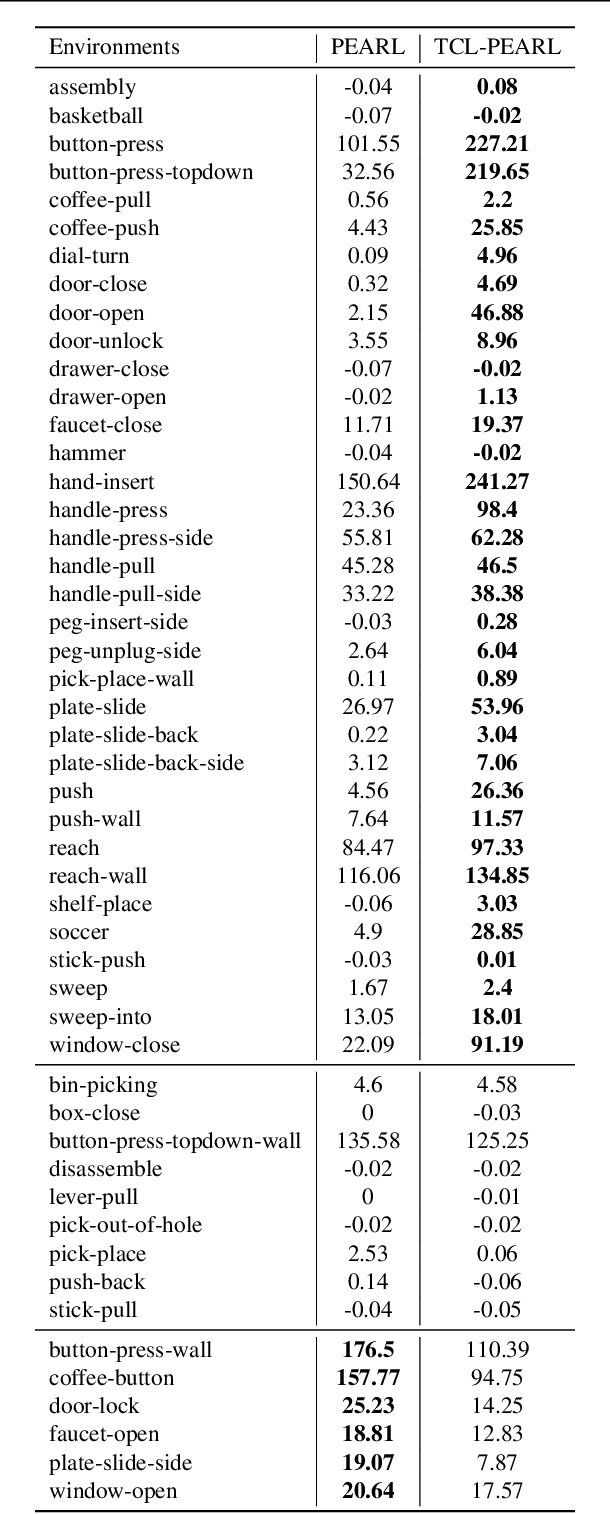
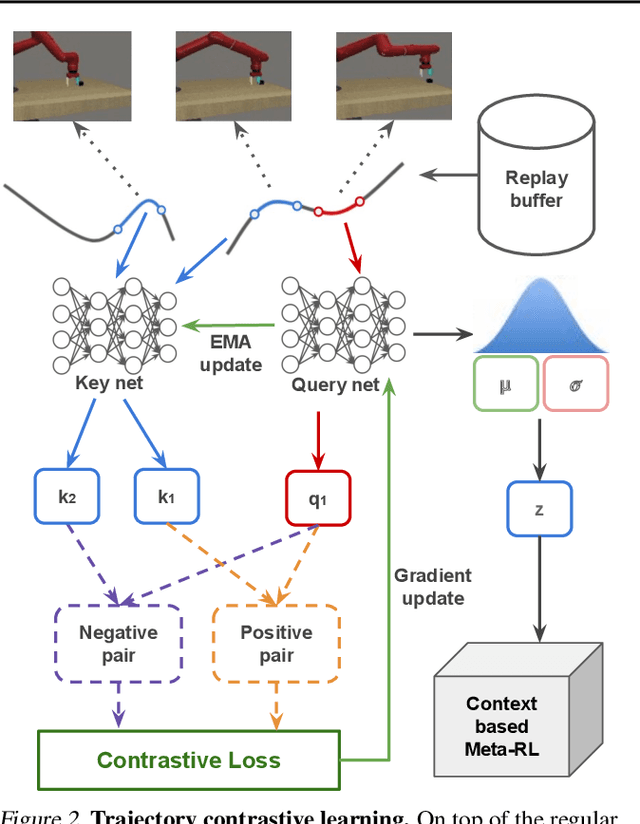

Meta-reinforcement learning typically requires orders of magnitude more samples than single task reinforcement learning methods. This is because meta-training needs to deal with more diverse distributions and train extra components such as context encoders. To address this, we propose a novel self-supervised learning task, which we named Trajectory Contrastive Learning (TCL), to improve meta-training. TCL adopts contrastive learning and trains a context encoder to predict whether two transition windows are sampled from the same trajectory. TCL leverages the natural hierarchical structure of context-based meta-RL and makes minimal assumptions, allowing it to be generally applicable to context-based meta-RL algorithms. It accelerates the training of context encoders and improves meta-training overall. Experiments show that TCL performs better or comparably than a strong meta-RL baseline in most of the environments on both meta-RL MuJoCo (5 of 6) and Meta-World benchmarks (44 out of 50).
Neural forecasting: Introduction and literature overview
Apr 21, 2020


Neural network based forecasting methods have become ubiquitous in large-scale industrial forecasting applications over the last years. As the prevalence of neural network based solutions among the best entries in the recent M4 competition shows, the recent popularity of neural forecasting methods is not limited to industry and has also reached academia. This article aims at providing an introduction and an overview of some of the advances that have permitted the resurgence of neural networks in machine learning. Building on these foundations, the article then gives an overview of the recent literature on neural networks for forecasting and applications.
LATTE: Accelerating LiDAR Point Cloud Annotation via Sensor Fusion, One-Click Annotation, and Tracking
Apr 19, 2019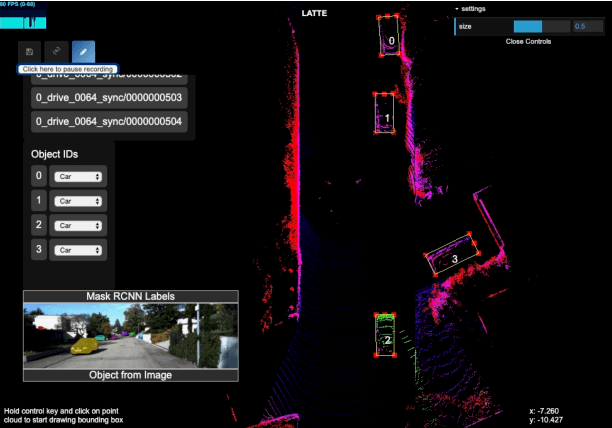
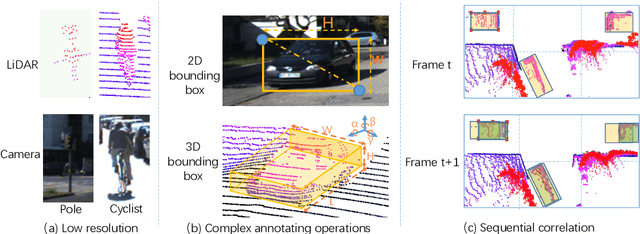
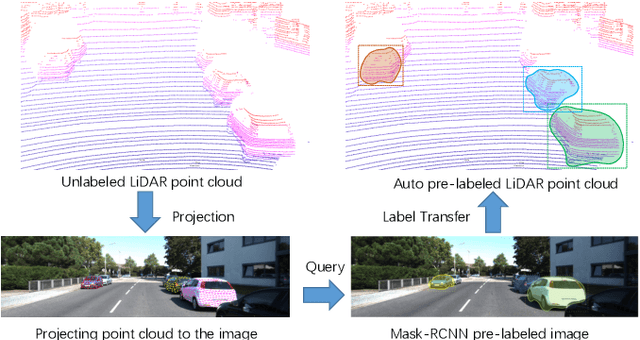
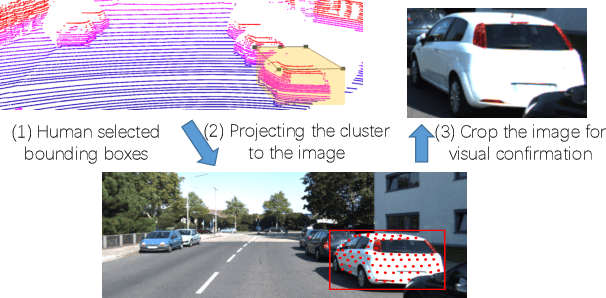
LiDAR (Light Detection And Ranging) is an essential and widely adopted sensor for autonomous vehicles, particularly for those vehicles operating at higher levels (L4-L5) of autonomy. Recent work has demonstrated the promise of deep-learning approaches for LiDAR-based detection. However, deep-learning algorithms are extremely data hungry, requiring large amounts of labeled point-cloud data for training and evaluation. Annotating LiDAR point cloud data is challenging due to the following issues: 1) A LiDAR point cloud is usually sparse and has low resolution, making it difficult for human annotators to recognize objects. 2) Compared to annotation on 2D images, the operation of drawing 3D bounding boxes or even point-wise labels on LiDAR point clouds is more complex and time-consuming. 3) LiDAR data are usually collected in sequences, so consecutive frames are highly correlated, leading to repeated annotations. To tackle these challenges, we propose LATTE, an open-sourced annotation tool for LiDAR point clouds. LATTE features the following innovations: 1) Sensor fusion: We utilize image-based detection algorithms to automatically pre-label a calibrated image, and transfer the labels to the point cloud. 2) One-click annotation: Instead of drawing 3D bounding boxes or point-wise labels, we simplify the annotation to just one click on the target object, and automatically generate the bounding box for the target. 3) Tracking: we integrate tracking into sequence annotation such that we can transfer labels from one frame to subsequent ones and therefore significantly reduce repeated labeling. Experiments show the proposed features accelerate the annotation speed by 6.2x and significantly improve label quality with 23.6% and 2.2% higher instance-level precision and recall, and 2.0% higher bounding box IoU. LATTE is open-sourced at https://github.com/bernwang/latte.