 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOEM: 1-bit Point-wise Operations based on Expectation-Maximization for Efficient Point Cloud Processing
Nov 26, 2021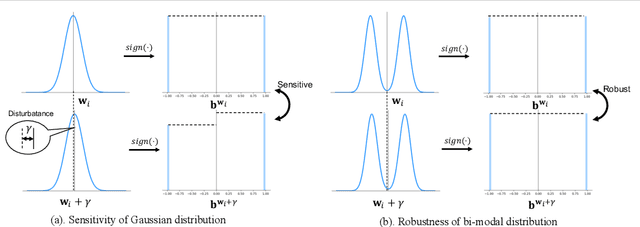
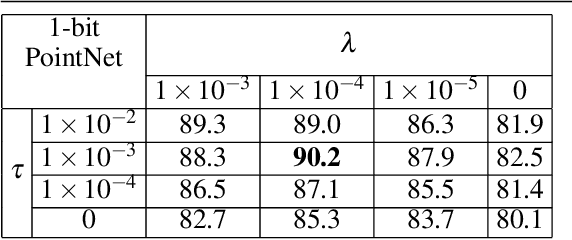
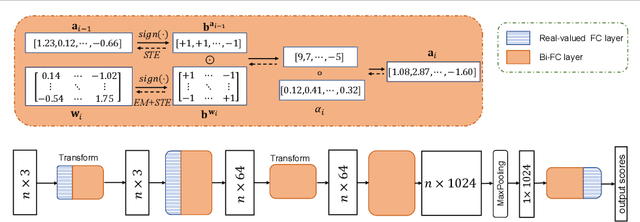

Real-time point cloud processing is fundamental for lots of computer vision tasks, while still challenged by the computational problem on resource-limited edge devices. To address this issue, we implement XNOR-Net-based binary neural networks (BNNs) for an efficient point cloud processing, but its performance is severely suffered due to two main drawbacks, Gaussian-distributed weights and non-learnable scale factor. In this paper, we introduce point-wise operations based on Expectation-Maximization (POEM) into BNNs for efficient point cloud processing. The EM algorithm can efficiently constrain weights for a robust bi-modal distribution. We lead a well-designed reconstruction loss to calculate learnable scale factors to enhance the representation capacity of 1-bit fully-connected (Bi-FC) layers. Extensive experiments demonstrate that our POEM surpasses existing the state-of-the-art binary point cloud networks by a significant margin, up to 6.7 %.
NENet: Monocular Depth Estimation via Neural Ensembles
Nov 16, 2021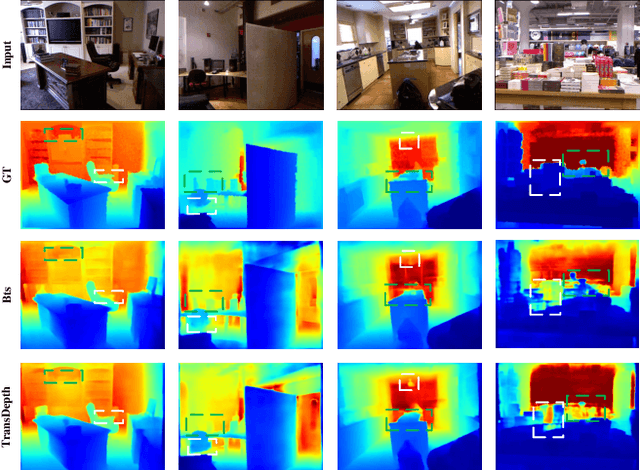
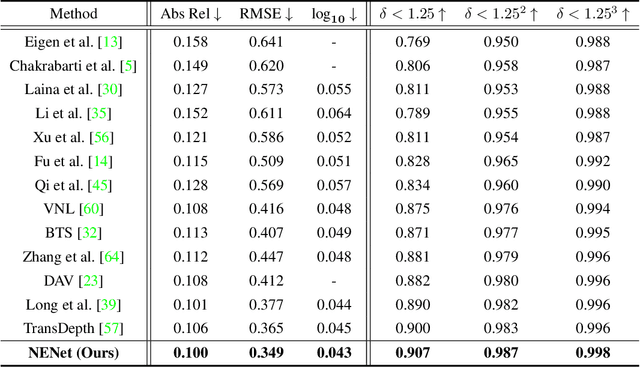
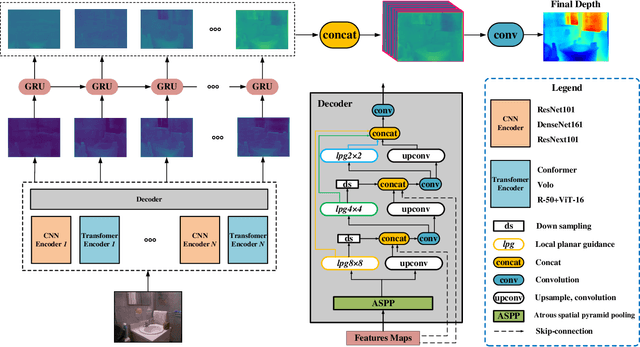
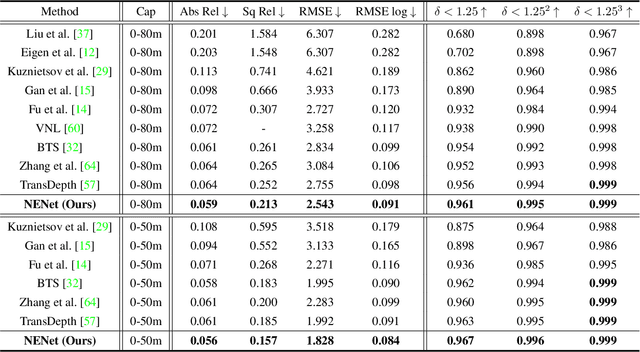
Depth estimation is getting a widespread popularity in the computer vision community, and it is still quite difficult to recover an accurate depth map using only one single RGB image. In this work, we observe a phenomenon that existing methods tend to exhibit asymmetric errors, which might open up a new direction for accurate and robust depth estimation. We carefully investigate into the phenomenon, and construct a two-level ensemble scheme, NENet, to integrate multiple predictions from diverse base predictors. The NENet forms a more reliable depth estimator, which substantially boosts the performance over base predictors. Notably, this is the first attempt to introduce ensemble learning and evaluate its utility for monocular depth estimation to the best of our knowledge. Extensive experiments demonstrate that the proposed NENet achieves better results than previous state-of-the-art approaches on the NYU-Depth-v2 and KITTI datasets. In particular, our method improves previous state-of-the-art methods from 0.365 to 0.349 on the metric RMSE on the NYU dataset. To validate the generalizability across cameras, we directly apply the models trained on the NYU dataset to the SUN RGB-D dataset without any fine-tuning, and achieve the superior results, which indicate its strong generalizability. The source code and trained models will be publicly available upon the acceptance.
Prioritized Subnet Sampling for Resource-Adaptive Supernet Training
Sep 12, 2021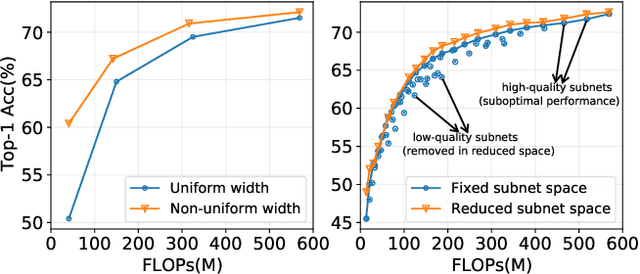
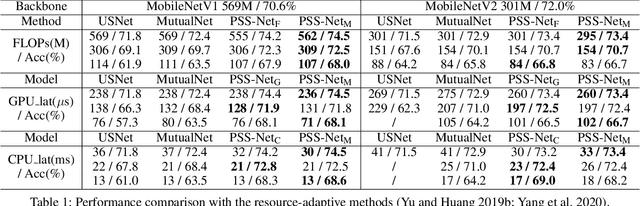
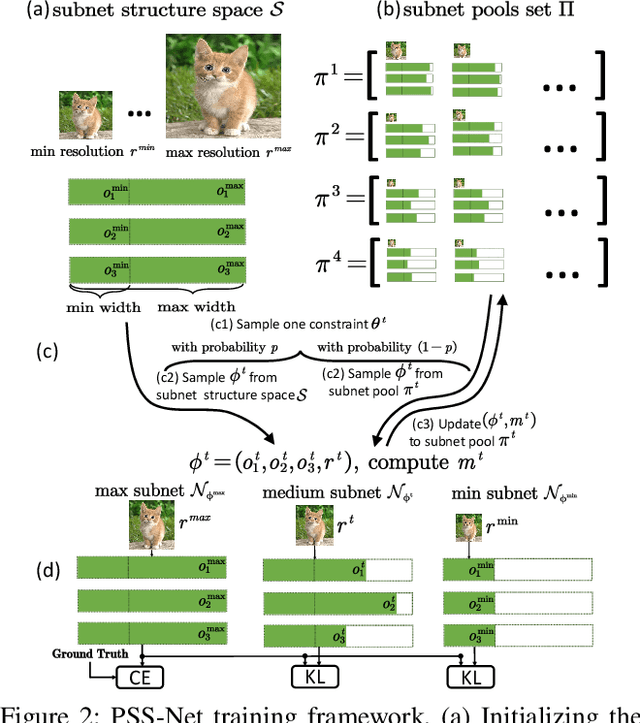
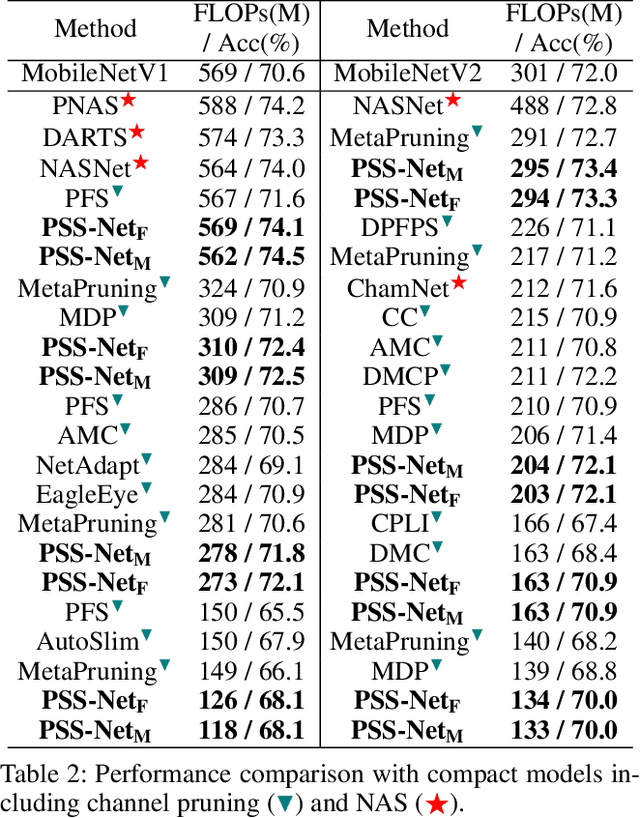
A resource-adaptive supernet adjusts its subnets for inference to fit the dynamically available resources. In this paper, we propose Prioritized Subnet Sampling to train a resource-adaptive supernet, termed PSS-Net. We maintain multiple subnet pools, each of which stores the information of substantial subnets with similar resource consumption. Considering a resource constraint, subnets conditioned on this resource constraint are sampled from a pre-defined subnet structure space and high-quality ones will be inserted into the corresponding subnet pool. Then, the sampling will gradually be prone to sampling subnets from the subnet pools. Moreover, the one with a better performance metric is assigned with higher priority to train our PSS-Net, if sampling is from a subnet pool. At the end of training, our PSS-Net retains the best subnet in each pool to entitle a fast switch of high-quality subnets for inference when the available resources vary. Experiments on ImageNet using MobileNetV1/V2 show that our PSS-Net can well outperform state-of-the-art resource-adaptive supernets. Our project is at https://github.com/chenbong/PSS-Net.
Cogradient Descent for Dependable Learning
Jun 20, 2021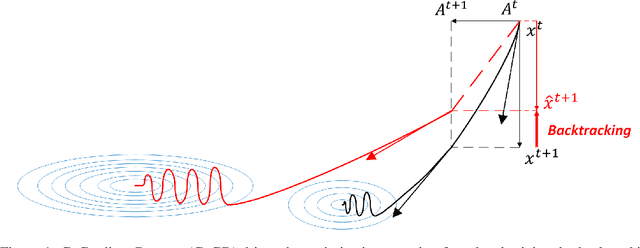
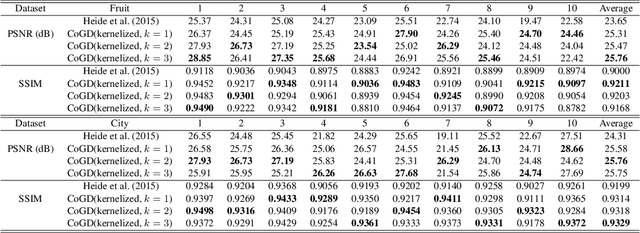
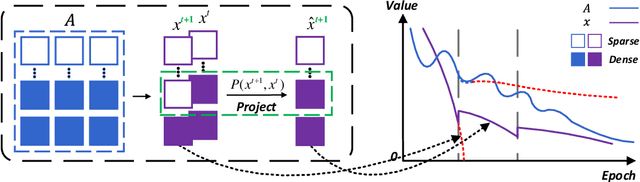
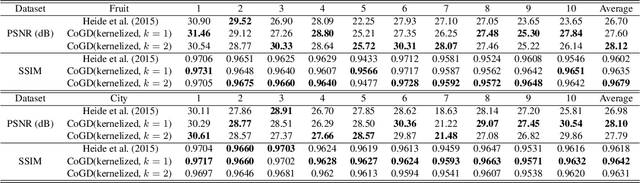
Conventional gradient descent methods compute the gradients for multiple variables through the partial derivative. Treating the coupled variables independently while ignoring the interaction, however, leads to an insufficient optimization for bilinear models. In this paper, we propose a dependable learning based on Cogradient Descent (CoGD) algorithm to address the bilinear optimization problem, providing a systematic way to coordinate the gradients of coupling variables based on a kernelized projection function. CoGD is introduced to solve bilinear problems when one variable is with sparsity constraint, as often occurs in modern learning paradigms. CoGD can also be used to decompose the association of features and weights, which further generalizes our method to better train convolutional neural networks (CNNs) and improve the model capacity. CoGD is applied in representative bilinear problems, including image reconstruction, image inpainting, network pruning and CNN training. Extensive experiments show that CoGD improves the state-of-the-arts by significant margins. Code is available at {https://github.com/bczhangbczhang/CoGD}.
Oriented Object Detection with Transformer
Jun 06, 2021
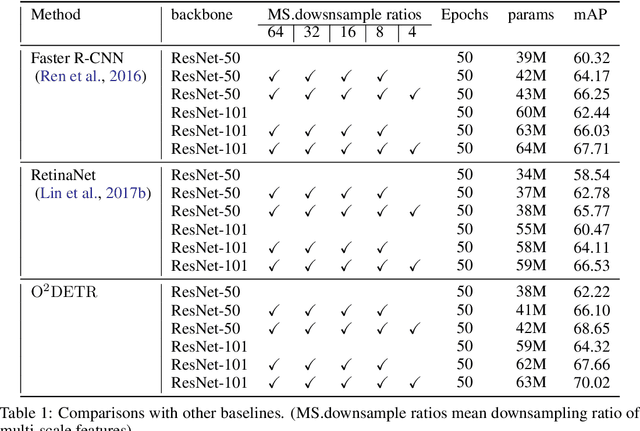
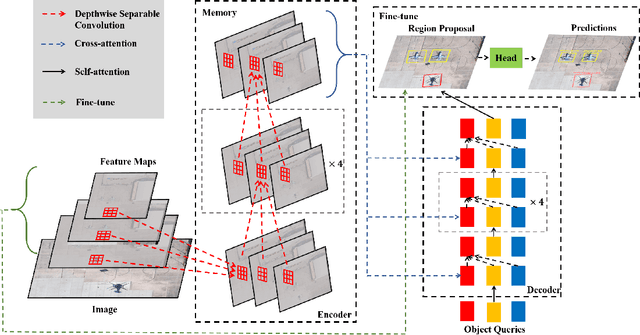
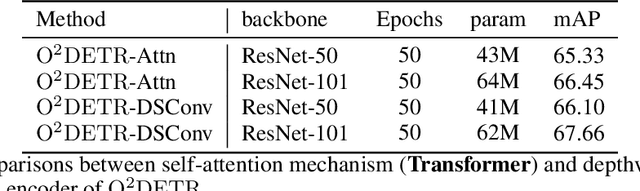
Object detection with Transformers (DETR) has achieved a competitive performance over traditional detectors, such as Faster R-CNN. However, the potential of DETR remains largely unexplored for the more challenging task of arbitrary-oriented object detection problem. We provide the first attempt and implement Oriented Object DEtection with TRansformer ($\bf O^2DETR$) based on an end-to-end network. The contributions of $\rm O^2DETR$ include: 1) we provide a new insight into oriented object detection, by applying Transformer to directly and efficiently localize objects without a tedious process of rotated anchors as in conventional detectors; 2) we design a simple but highly efficient encoder for Transformer by replacing the attention mechanism with depthwise separable convolution, which can significantly reduce the memory and computational cost of using multi-scale features in the original Transformer; 3) our $\rm O^2DETR$ can be another new benchmark in the field of oriented object detection, which achieves up to 3.85 mAP improvement over Faster R-CNN and RetinaNet. We simply fine-tune the head mounted on $\rm O^2DETR$ in a cascaded architecture and achieve a competitive performance over SOTA in the DOTA dataset.
Probabilistic Ranking-Aware Ensembles for Enhanced Object Detections
May 07, 2021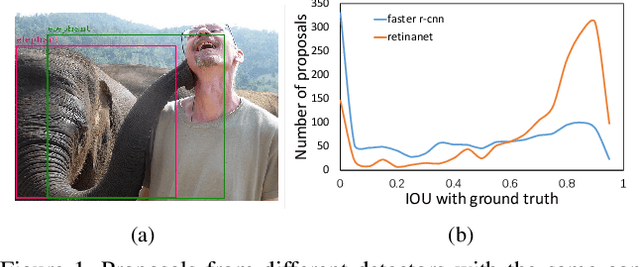

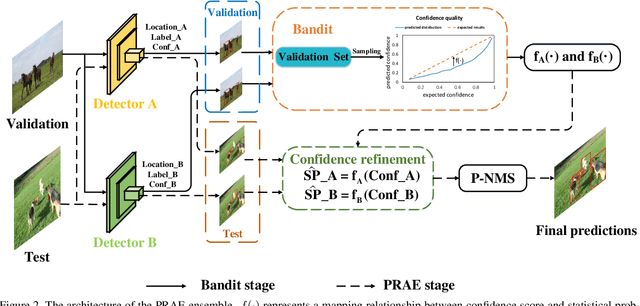

Model ensembles are becoming one of the most effective approaches for improving object detection performance already optimized for a single detector. Conventional methods directly fuse bounding boxes but typically fail to consider proposal qualities when combining detectors. This leads to a new problem of confidence discrepancy for the detector ensembles. The confidence has little effect on single detectors but significantly affects detector ensembles. To address this issue, we propose a novel ensemble called the Probabilistic Ranking Aware Ensemble (PRAE) that refines the confidence of bounding boxes from detectors. By simultaneously considering the category and the location on the same validation set, we obtain a more reliable confidence based on statistical probability. We can then rank the detected bounding boxes for assembly. We also introduce a bandit approach to address the confidence imbalance problem caused by the need to deal with different numbers of boxes at different confidence levels. We use our PRAE-based non-maximum suppression (P-NMS) to replace the conventional NMS method in ensemble learning. Experiments on the PASCAL VOC and COCO2017 datasets demonstrate that our PRAE method consistently outperforms state-of-the-art methods by significant margins.
Interpretable Attention Guided Network for Fine-grained Visual Classification
Mar 09, 2021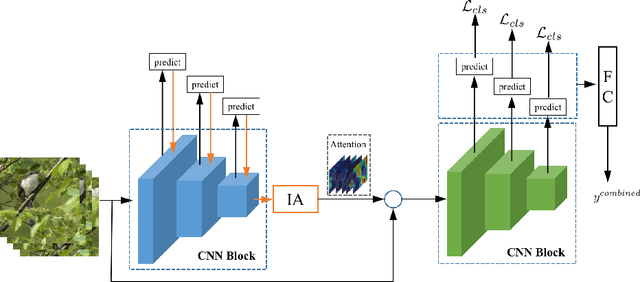
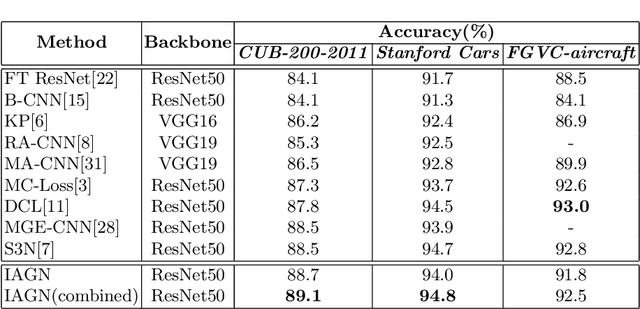

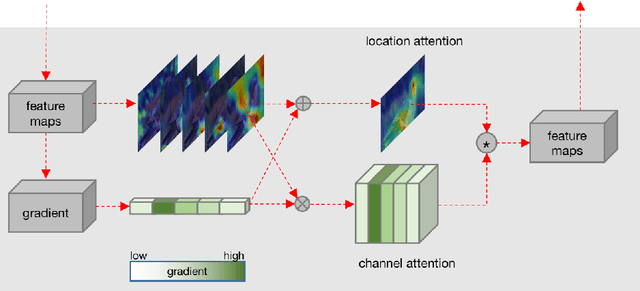
Fine-grained visual classification (FGVC) is challenging but more critical than traditional classification tasks. It requires distinguishing different subcategories with the inherently subtle intra-class object variations. Previous works focus on enhancing the feature representation ability using multiple granularities and discriminative regions based on the attention strategy or bounding boxes. However, these methods highly rely on deep neural networks which lack interpretability. We propose an Interpretable Attention Guided Network (IAGN) for fine-grained visual classification. The contributions of our method include: i) an attention guided framework which can guide the network to extract discriminitive regions in an interpretable way; ii) a progressive training mechanism obtained to distill knowledge stage by stage to fuse features of various granularities; iii) the first interpretable FGVC method with a competitive performance on several standard FGVC benchmark datasets.
SiMaN: Sign-to-Magnitude Network Binarization
Feb 16, 2021

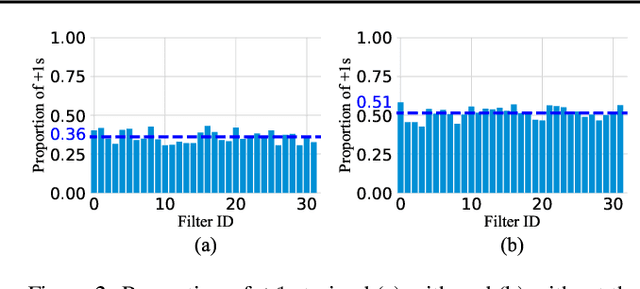
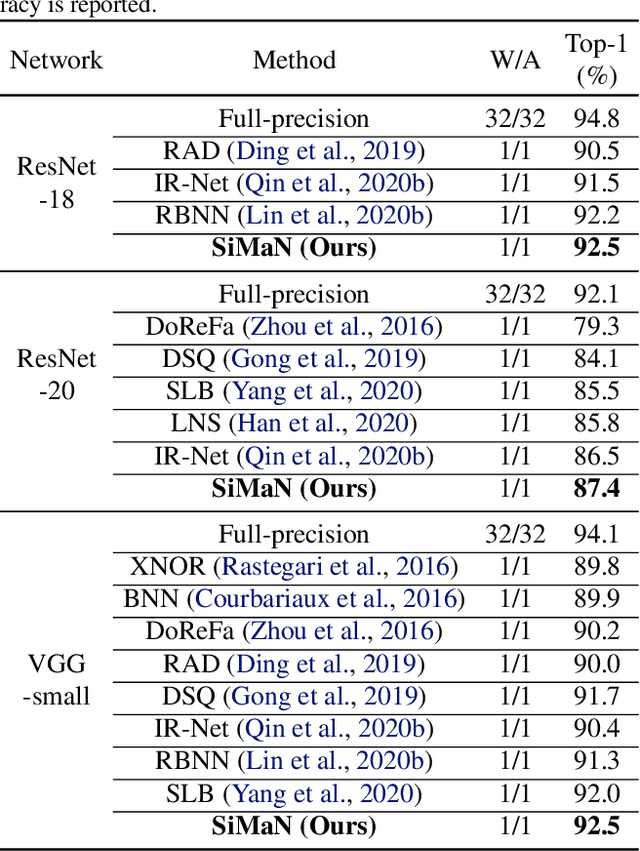
Binary neural networks (BNNs) have attracted broad research interest due to their efficient storage and computational ability. Nevertheless, a significant challenge of BNNs lies in handling discrete constraints while ensuring bit entropy maximization, which typically makes their weight optimization very difficult. Existing methods relax the learning using the sign function, which simply encodes positive weights into +1s, and -1s otherwise. Alternatively, we formulate an angle alignment objective to constrain the weight binarization to {0,+1} to solve the challenge. In this paper, we show that our weight binarization provides an analytical solution by encoding high-magnitude weights into +1s, and 0s otherwise. Therefore, a high-quality discrete solution is established in a computationally efficient manner without the sign function. We prove that the learned weights of binarized networks roughly follow a Laplacian distribution that does not allow entropy maximization, and further demonstrate that it can be effectively solved by simply removing the $\ell_2$ regularization during network training. Our method, dubbed sign-to-magnitude network binarization (SiMaN), is evaluated on CIFAR-10 and ImageNet, demonstrating its superiority over the sign-based state-of-the-arts. Code is at https://github.com/lmbxmu/SiMaN.
Multi-UAV Mobile Edge Computing and Path Planning Platform based on Reinforcement Learning
Feb 14, 2021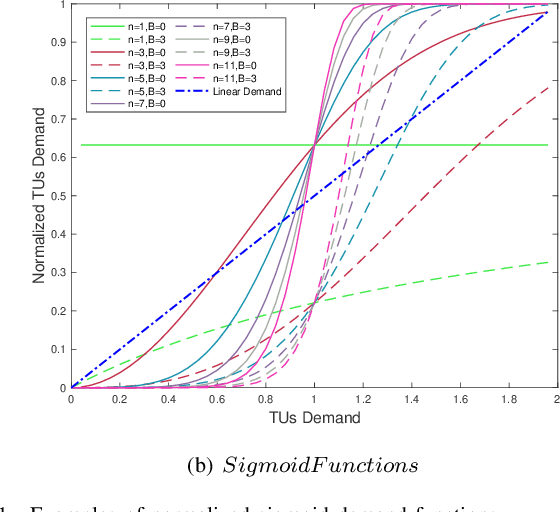
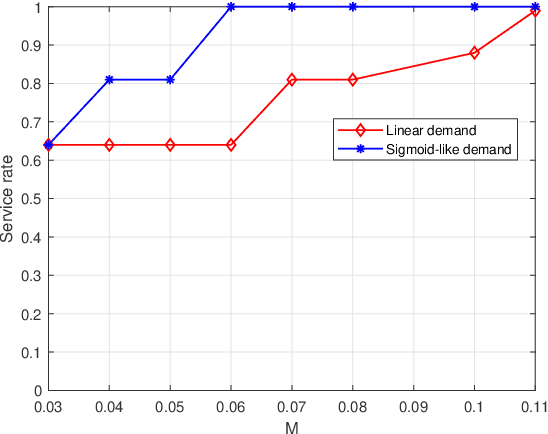
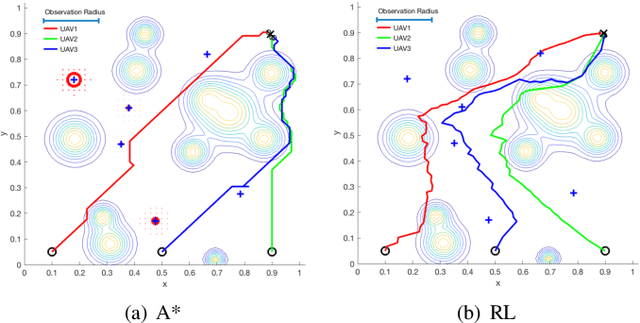
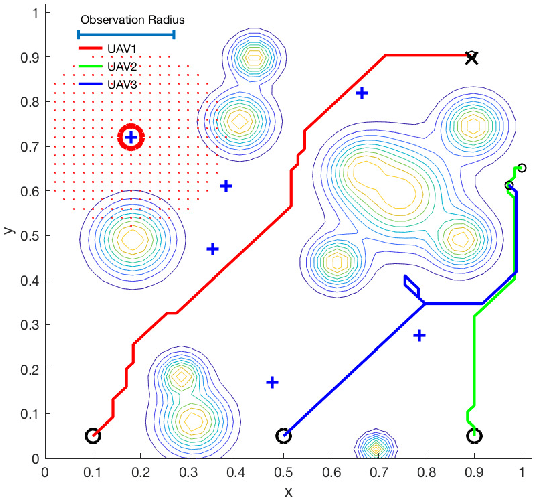
Unmanned Aerial vehicles (UAVs) are widely used as network processors in mobile networks, but more recently, UAVs have been used in Mobile Edge Computing as mobile servers. However, there are significant challenges to use UAVs in complex environments with obstacles and cooperation between UAVs. We introduce a new multi-UAV Mobile Edge Computing platform, which aims to provide better Quality-of-Service and path planning based on reinforcement learning to address these issues. The contributions of our work include: 1) optimizing the quality of service for mobile edge computing and path planning in the same reinforcement learning framework; 2) using a sigmoid-like function to depict the terminal users' demand to ensure a higher quality of service; 3) applying synthetic considerations of the terminal users' demand, risk and geometric distance in reinforcement learning reward matrix to ensure the quality of service, risk avoidance, and the cost-savings. Simulations have shown the effectiveness and feasibility of our platform, which can help advance related researches.
Deformable Gabor Feature Networks for Biomedical Image Classification
Dec 07, 2020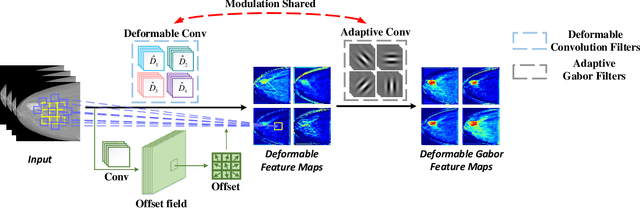
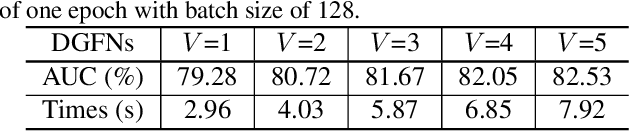
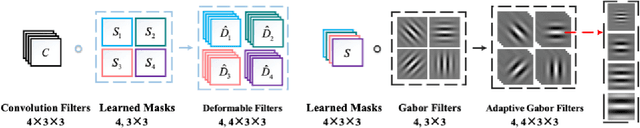
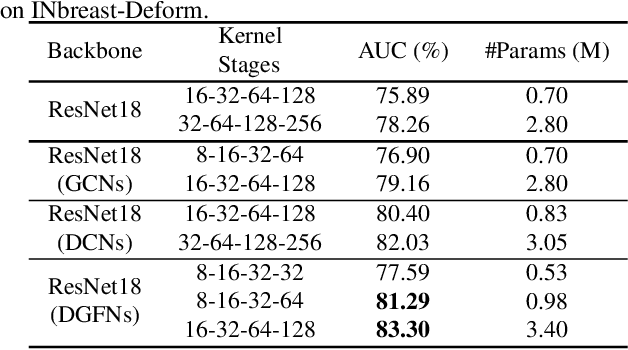
In recent years, deep learning has dominated progress in the field of medical image analysis. We find however, that the ability of current deep learning approaches to represent the complex geometric structures of many medical images is insufficient. One limitation is that deep learning models require a tremendous amount of data, and it is very difficult to obtain a sufficient amount with the necessary detail. A second limitation is that there are underlying features of these medical images that are well established, but the black-box nature of existing convolutional neural networks (CNNs) do not allow us to exploit them. In this paper, we revisit Gabor filters and introduce a deformable Gabor convolution (DGConv) to expand deep networks interpretability and enable complex spatial variations. The features are learned at deformable sampling locations with adaptive Gabor convolutions to improve representativeness and robustness to complex objects. The DGConv replaces standard convolutional layers and is easily trained end-to-end, resulting in deformable Gabor feature network (DGFN) with few additional parameters and minimal additional training cost. We introduce DGFN for addressing deep multi-instance multi-label classification on the INbreast dataset for mammograms and on the ChestX-ray14 dataset for pulmonary x-ray images.