 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamics Randomization Revisited:A Case Study for Quadrupedal Locomotion
Nov 04, 2020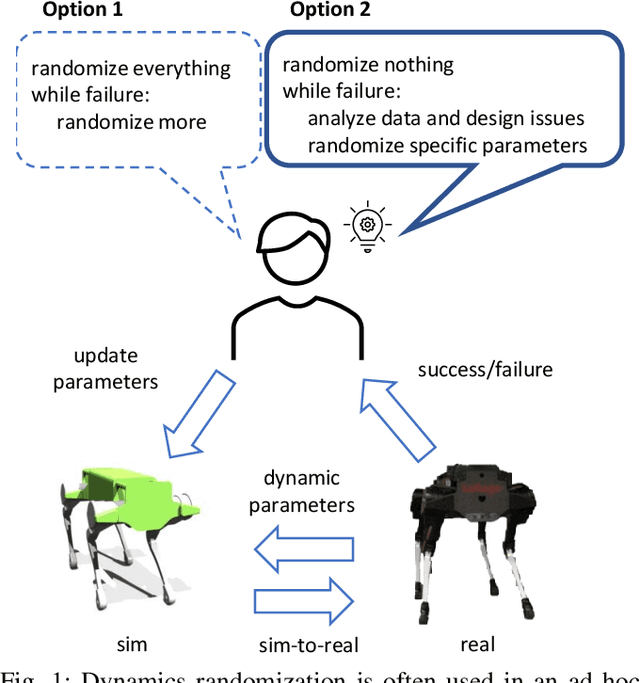
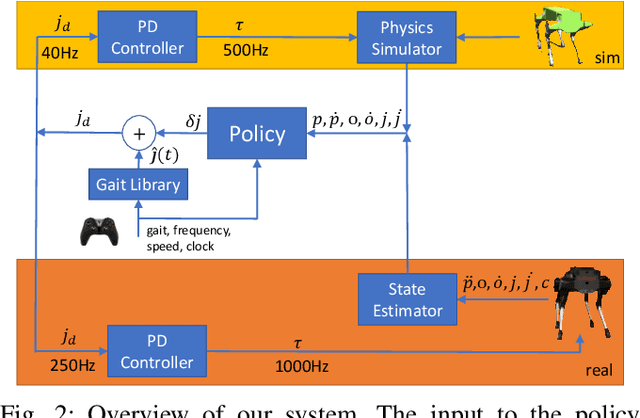

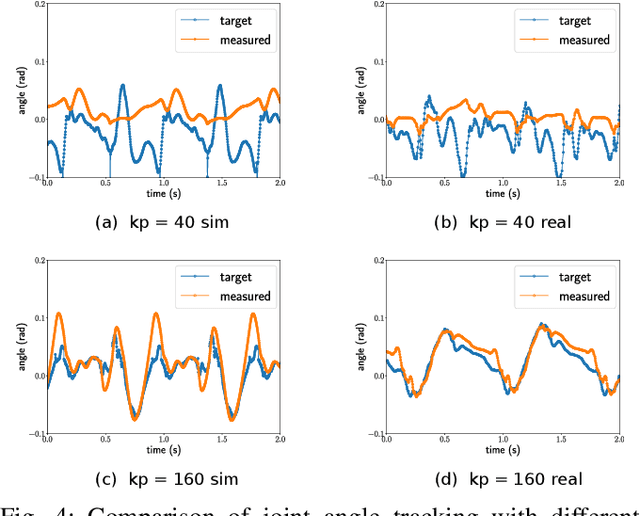
Understanding the gap between simulation andreality is critical for reinforcement learning with legged robots,which are largely trained in simulation. However, recent workhas resulted in sometimes conflicting conclusions with regardto which factors are important for success, including therole of dynamics randomization. In this paper, we aim toprovide clarity and understanding on the role of dynamicsrandomization in learning robust locomotion policies for theLaikago quadruped robot. Surprisingly, in contrast to priorwork with the same robot model, we find that direct sim-to-real transfer is possible without dynamics randomizationor on-robot adaptation schemes. We conduct extensive abla-tion studies in a sim-to-sim setting to understand the keyissues underlying successful policy transfer, including otherdesign decisions that can impact policy robustness. We furtherground our conclusions via sim-to-real experiments with variousgaits, speeds, and stepping frequencies. Additional Details: https://www.pair.toronto.edu/understanding-dr/.
Conservative Safety Critics for Exploration
Oct 27, 2020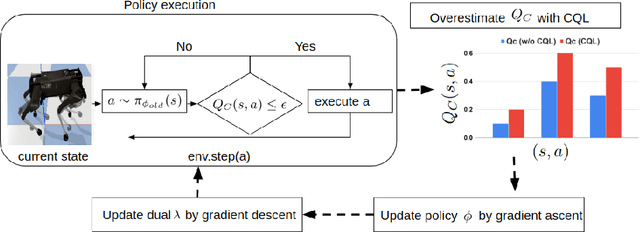

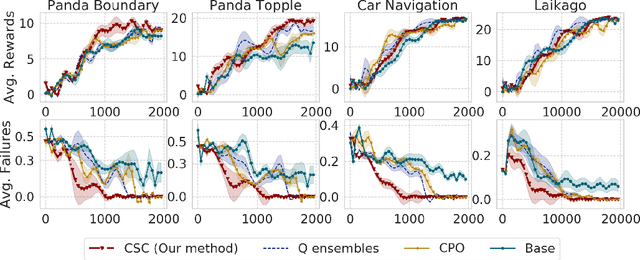
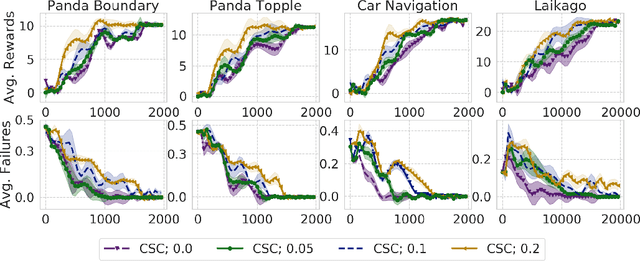
Safe exploration presents a major challenge in reinforcement learning (RL): when active data collection requires deploying partially trained policies, we must ensure that these policies avoid catastrophically unsafe regions, while still enabling trial and error learning. In this paper, we target the problem of safe exploration in RL by learning a conservative safety estimate of environment states through a critic, and provably upper bound the likelihood of catastrophic failures at every training iteration. We theoretically characterize the tradeoff between safety and policy improvement, show that the safety constraints are likely to be satisfied with high probability during training, derive provable convergence guarantees for our approach, which is no worse asymptotically than standard RL, and demonstrate the efficacy of the proposed approach on a suite of challenging navigation, manipulation, and locomotion tasks. Empirically, we show that the proposed approach can achieve competitive task performance while incurring significantly lower catastrophic failure rates during training than prior methods. Videos are at this url https://sites.google.com/view/conservative-safety-critics/home
D2RL: Deep Dense Architectures in Reinforcement Learning
Oct 19, 2020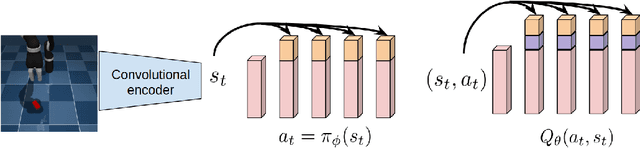
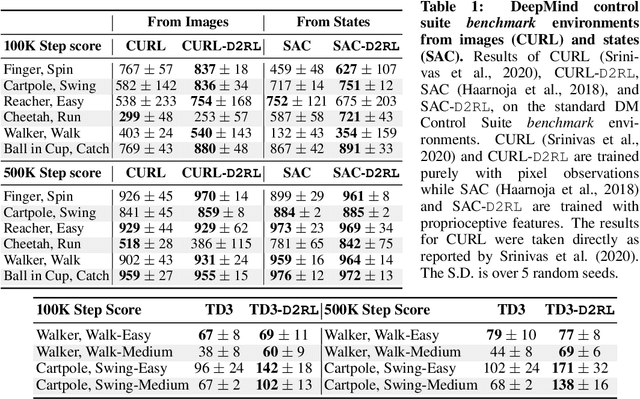
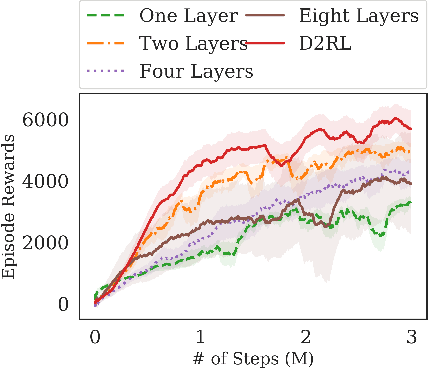
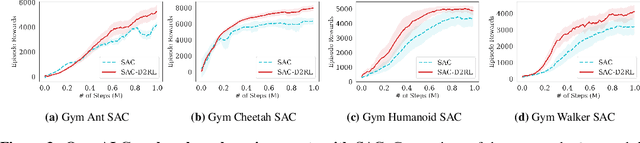
While improvements in deep learning architectures have played a crucial role in improving the state of supervised and unsupervised learning in computer vision and natural language processing, neural network architecture choices for reinforcement learning remain relatively under-explored. We take inspiration from successful architectural choices in computer vision and generative modelling, and investigate the use of deeper networks and dense connections for reinforcement learning on a variety of simulated robotic learning benchmark environments. Our findings reveal that current methods benefit significantly from dense connections and deeper networks, across a suite of manipulation and locomotion tasks, for both proprioceptive and image-based observations. We hope that our results can serve as a strong baseline and further motivate future research into neural network architectures for reinforcement learning. The project website with code is at this link https://sites.google.com/view/d2rl/home.
Learning a Contact-Adaptive Controller for Robust, Efficient Legged Locomotion
Oct 05, 2020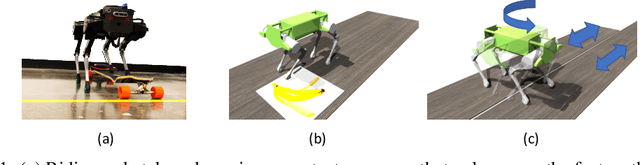
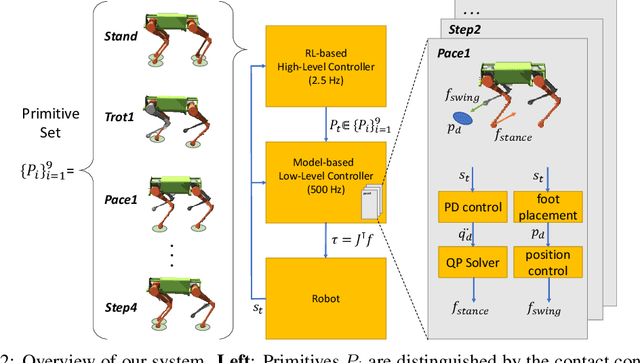

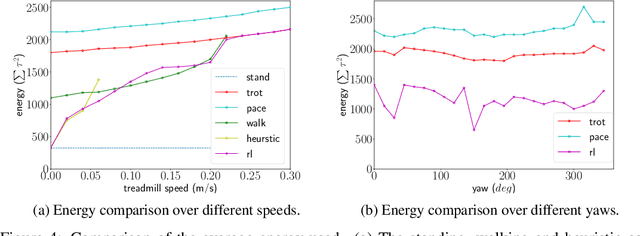
We present a hierarchical framework that combines model-based control and reinforcement learning (RL) to synthesize robust controllers for a quadruped (the Unitree Laikago). The system consists of a high-level controller that learns to choose from a set of primitives in response to changes in the environment and a low-level controller that utilizes an established control method to robustly execute the primitives. Our framework learns a controller that can adapt to challenging environmental changes on the fly, including novel scenarios not seen during training. The learned controller is up to 85~percent more energy efficient and is more robust compared to baseline methods. We also deploy the controller on a physical robot without any randomization or adaptation scheme.
OCEAN: Online Task Inference for Compositional Tasks with Context Adaptation
Aug 17, 2020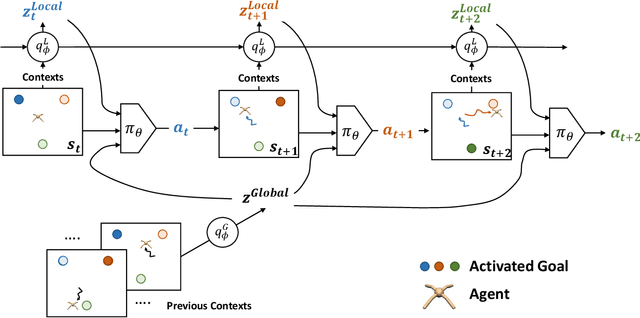
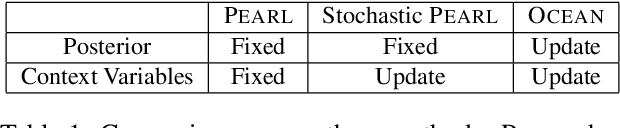


Real-world tasks often exhibit a compositional structure that contains a sequence of simpler sub-tasks. For instance, opening a door requires reaching, grasping, rotating, and pulling the door knob. Such compositional tasks require an agent to reason about the sub-task at hand while orchestrating global behavior accordingly. This can be cast as an online task inference problem, where the current task identity, represented by a context variable, is estimated from the agent's past experiences with probabilistic inference. Previous approaches have employed simple latent distributions, e.g., Gaussian, to model a single context for the entire task. However, this formulation lacks the expressiveness to capture the composition and transition of the sub-tasks. We propose a variational inference framework OCEAN to perform online task inference for compositional tasks. OCEAN models global and local context variables in a joint latent space, where the global variables represent a mixture of sub-tasks required for the task, while the local variables capture the transitions between the sub-tasks. Our framework supports flexible latent distributions based on prior knowledge of the task structure and can be trained in an unsupervised manner. Experimental results show that OCEAN provides more effective task inference with sequential context adaptation and thus leads to a performance boost on complex, multi-stage tasks.
Visuomotor Mechanical Search: Learning to Retrieve Target Objects in Clutter
Aug 13, 2020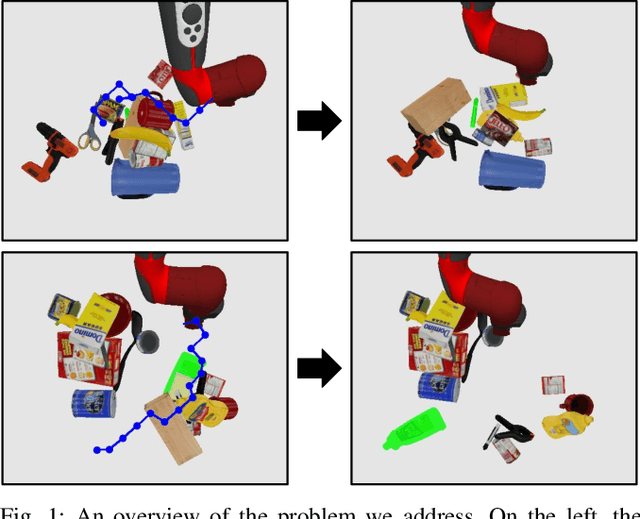
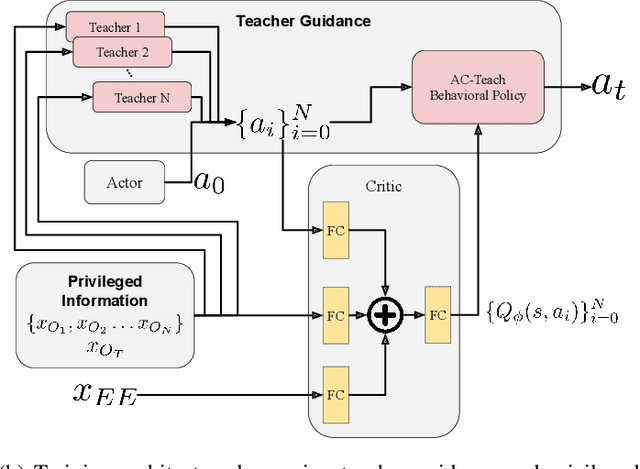
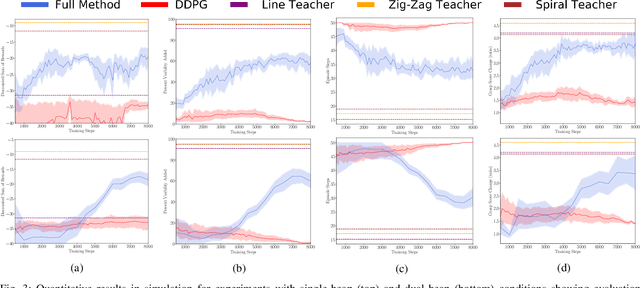
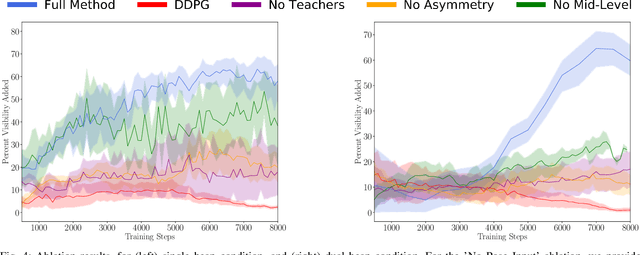
When searching for objects in cluttered environments, it is often necessary to perform complex interactions in order to move occluding objects out of the way and fully reveal the object of interest and make it graspable. Due to the complexity of the physics involved and the lack of accurate models of the clutter, planning and controlling precise predefined interactions with accurate outcome is extremely hard, when not impossible. In problems where accurate (forward) models are lacking, Deep Reinforcement Learning (RL) has shown to be a viable solution to map observations (e.g. images) to good interactions in the form of close-loop visuomotor policies. However, Deep RL is sample inefficient and fails when applied directly to the problem of unoccluding objects based on images. In this work we present a novel Deep RL procedure that combines i) teacher-aided exploration, ii) a critic with privileged information, and iii) mid-level representations, resulting in sample efficient and effective learning for the problem of uncovering a target object occluded by a heap of unknown objects. Our experiments show that our approach trains faster and converges to more efficient uncovering solutions than baselines and ablations, and that our uncovering policies lead to an average improvement in the graspability of the target object, facilitating downstream retrieval applications.
Counterfactual Data Augmentation using Locally Factored Dynamics
Jul 06, 2020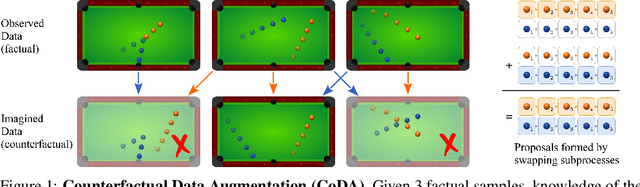

Many dynamic processes, including common scenarios in robotic control and reinforcement learning (RL), involve a set of interacting subprocesses. Though the subprocesses are not independent, their interactions are often sparse, and the dynamics at any given time step can often be decomposed into locally independent causal mechanisms. Such local causal structures can be leveraged to improve the sample efficiency of sequence prediction and off-policy reinforcement learning. We formalize this by introducing local causal models (LCMs), which are induced from a global causal model by conditioning on a subset of the state space. We propose an approach to inferring these structures given an object-oriented state representation, as well as a novel algorithm for model-free Counterfactual Data Augmentation (CoDA). CoDA uses local structures and an experience replay to generate counterfactual experiences that are causally valid in the global model. We find that CoDA significantly improves the performance of RL agents in locally factored tasks, including the batch-constrained and goal-conditioned settings.
Causal Discovery in Physical Systems from Videos
Jul 02, 2020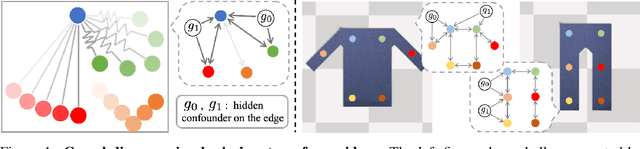
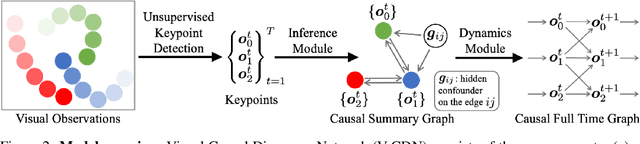
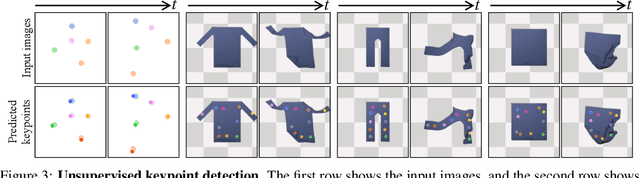
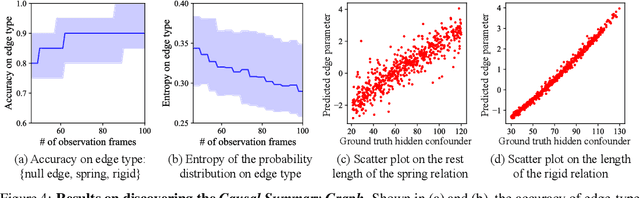
Causal discovery is at the core of human cognition. It enables us to reason about the environment and make counterfactual predictions about unseen scenarios, that can vastly differ from our previous experiences. We consider the task of causal discovery from videos in an end-to-end fashion without supervision on the ground-truth graph structure. In particular, our goal is to discover the structural dependencies among environmental and object variables: inferring the type and strength of interactions that have a causal effect on the behavior of the dynamical system. Our model consists of (a) a perception module that extracts a semantically meaningful and temporally consistent keypoint representation from images, (b) an inference module for determining the graph distribution induced by the detected keypoints, and (c) a dynamics module that can predict the future by conditioning on the inferred graph. We assume access to different configurations and environmental conditions, i.e., data from unknown interventions on the underlying system; thus, we can hope to discover the correct underlying causal graph without explicit interventions. We evaluate our method in a planar multi-body interaction environment and scenarios involving fabrics of different shapes like shirts and pants. Experiments demonstrate that our model can correctly identify the interactions from a short sequence of images and make long-term future predictions. The causal structure assumed by the model also allows it to make counterfactual predictions and extrapolate to systems of unseen interaction graphs or graphs of various sizes.
De-anonymization of authors through arXiv submissions during double-blind review
Jul 01, 2020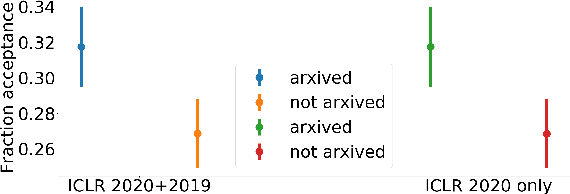
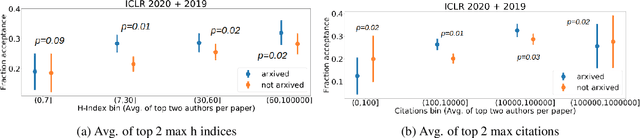
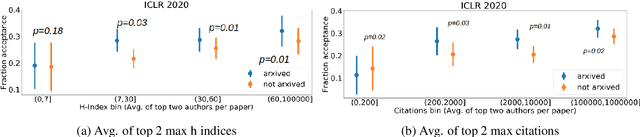

In this paper, we investigate the effects of releasing arXiv preprints of papers that are undergoing a double-blind review process. In particular, we ask the following research question: What is the relation between de-anonymization of authors through arXiv preprints and acceptance of a research paper at a (nominally) double-blind venue? Under two conditions: papers that are released on arXiv before the review phase and papers that are not, we examine the correlation between the reputation of their authors with the review scores and acceptance decisions. By analyzing a dataset of ICLR 2020 and ICLR 2019 submissions (n=5050), we find statistically significant evidence of positive correlation between percentage acceptance and papers with high reputation released on arXiv. In order to understand this observed association better, we perform additional analyses based on self-specified confidence scores of reviewers and observe that less confident reviewers are more likely to assign high review scores to papers with well known authors and low review scores to papers with less known authors, where reputation is quantified in terms of number of Google Scholar citations. We emphasize upfront that our results are purely correlational and we neither can nor intend to make any causal claims. A blog post accompanying the paper and our scraping code will be linked in the project website https://sites.google.com/view/deanon-arxiv/home
Maximum Entropy Models for Fast Adaptation
Jun 30, 2020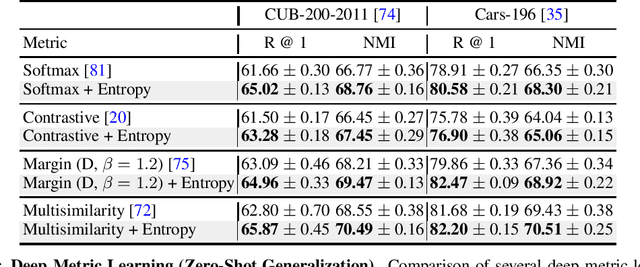
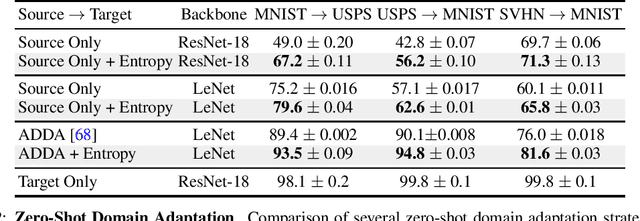

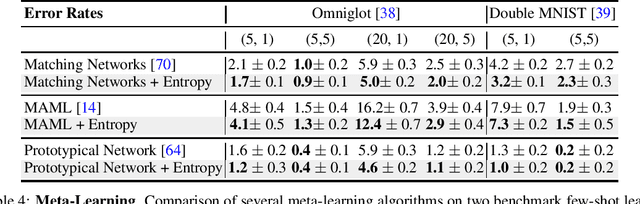
Deep Neural Networks have shown great promise on a variety of downstream tasks; but their ability to adapt to new data and tasks remains a challenging problem. The ability of a model to perform few-shot adaptation to a novel task is important for the scalability and deployment of machine learning models. Recent work has shown that the learned features in a neural network follow a normal distribution [41], which thereby results in a strong prior on the downstream task. This implicit overfitting to data from training tasks limits the ability to generalize and adapt to unseen tasks at test time. This also highlights the importance of learning task-agnostic representations from data. In this paper, we propose a regularization scheme using a max-entropy prior on the learned features of a neural network; such that the extracted features make minimal assumptions about the training data. We evaluate our method on adaptation to unseen tasks by performing experiments in 4 distinct settings. We find that our method compares favourably against multiple strong baselines across all of these experiments.