 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDerailing Non-Answers via Logit Suppression at Output Subspace Boundaries in RLHF-Aligned Language Models
May 28, 2025



We introduce a method to reduce refusal rates of large language models (LLMs) on sensitive content without modifying model weights or prompts. Motivated by the observation that refusals in certain models were often preceded by the specific token sequence of a token marking the beginning of the chain-of-thought (CoT) block (<think>) followed by a double newline token (\n\n), we investigate the impact of two simple formatting adjustments during generation: suppressing \n\n after <think> and suppressing the end-of-sequence token after the end of the CoT block (</think>). Our method requires no datasets, parameter changes, or training, relying solely on modifying token probabilities during generation. In our experiments with official DeepSeek-R1 distillations, these interventions increased the proportion of substantive answers to sensitive prompts without affecting performance on standard benchmarks. Our findings suggest that refusal behaviors can be circumvented by blocking refusal subspaces at specific points in the generation process.
Understanding the Effect of the Long Tail on Neural Network Compression
Jun 27, 2023Network compression is now a mature sub-field of neural network research: over the last decade, significant progress has been made towards reducing the size of models and speeding up inference, while maintaining the classification accuracy. However, many works have observed that focusing on just the overall accuracy can be misguided. E.g., it has been shown that mismatches between the full and compressed models can be biased towards under-represented classes. This raises the important research question, can we achieve network compression while maintaining "semantic equivalence" with the original network? In this work, we study this question in the context of the "long tail" phenomenon in computer vision datasets observed by Feldman, et al. They argue that memorization of certain inputs (appropriately defined) is essential to achieving good generalization. As compression limits the capacity of a network (and hence also its ability to memorize), we study the question: are mismatches between the full and compressed models correlated with the memorized training data? We present positive evidence in this direction for image classification tasks, by considering different base architectures and compression schemes.
ArctyrEX : Accelerated Encrypted Execution of General-Purpose Applications
Jun 19, 2023



Fully Homomorphic Encryption (FHE) is a cryptographic method that guarantees the privacy and security of user data during computation. FHE algorithms can perform unlimited arithmetic computations directly on encrypted data without decrypting it. Thus, even when processed by untrusted systems, confidential data is never exposed. In this work, we develop new techniques for accelerated encrypted execution and demonstrate the significant performance advantages of our approach. Our current focus is the Fully Homomorphic Encryption over the Torus (CGGI) scheme, which is a current state-of-the-art method for evaluating arbitrary functions in the encrypted domain. CGGI represents a computation as a graph of homomorphic logic gates and each individual bit of the plaintext is transformed into a polynomial in the encrypted domain. Arithmetic on such data becomes very expensive: operations on bits become operations on entire polynomials. Therefore, evaluating even relatively simple nonlinear functions, such as a sigmoid, can take thousands of seconds on a single CPU thread. Using our novel framework for end-to-end accelerated encrypted execution called ArctyrEX, developers with no knowledge of complex FHE libraries can simply describe their computation as a C program that is evaluated over $40\times$ faster on an NVIDIA DGX A100 and $6\times$ faster with a single A100 relative to a 256-threaded CPU baseline.
Reliable Model Compression via Label-Preservation-Aware Loss Functions
Dec 03, 2020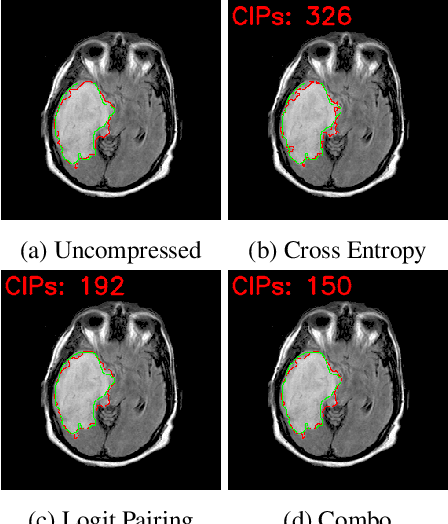
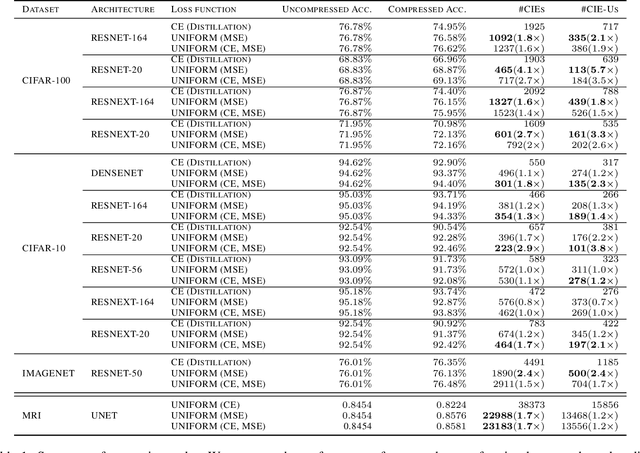
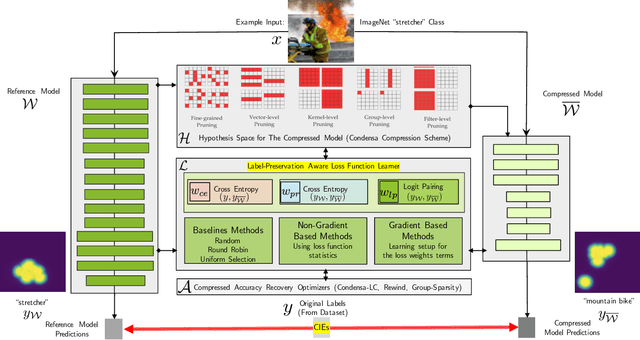
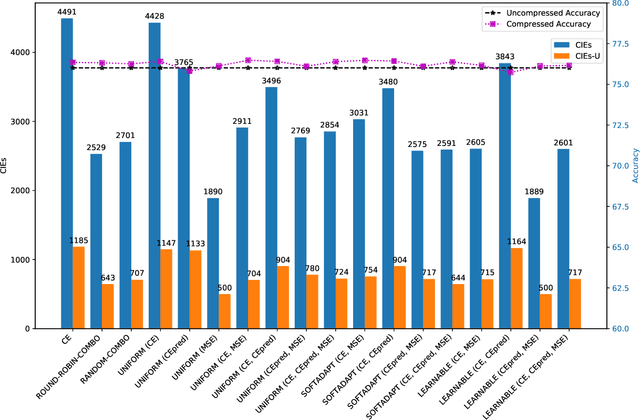
Model compression is a ubiquitous tool that brings the power of modern deep learning to edge devices with power and latency constraints. The goal of model compression is to take a large reference neural network and output a smaller and less expensive compressed network that is functionally equivalent to the reference. Compression typically involves pruning and/or quantization, followed by re-training to maintain the reference accuracy. However, it has been observed that compression can lead to a considerable mismatch in the labels produced by the reference and the compressed models, resulting in bias and unreliability. To combat this, we present a framework that uses a teacher-student learning paradigm to better preserve labels. We investigate the role of additional terms to the loss function and show how to automatically tune the associated parameters. We demonstrate the effectiveness of our approach both quantitatively and qualitatively on multiple compression schemes and accuracy recovery algorithms using a set of 8 different real-world network architectures. We obtain a significant reduction of up to 4.1X in the number of mismatches between the compressed and reference models, and up to 5.7X in cases where the reference model makes the correct prediction.
A Programmable Approach to Model Compression
Nov 06, 2019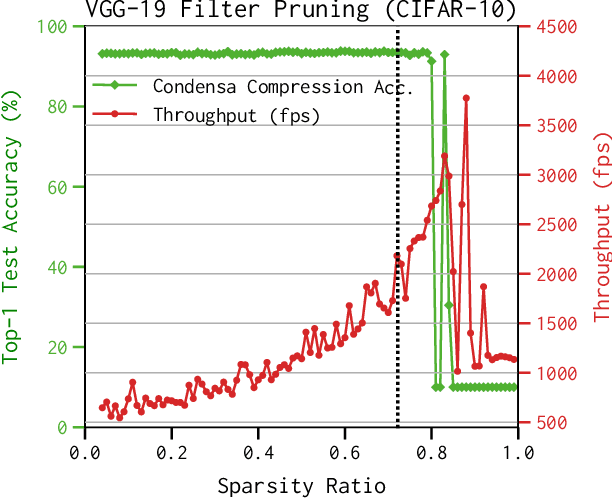
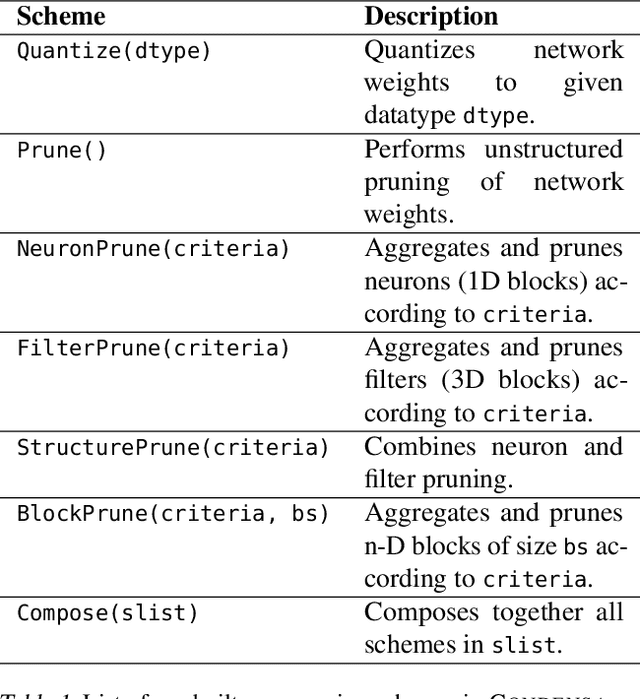
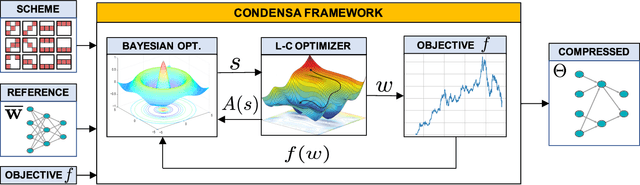
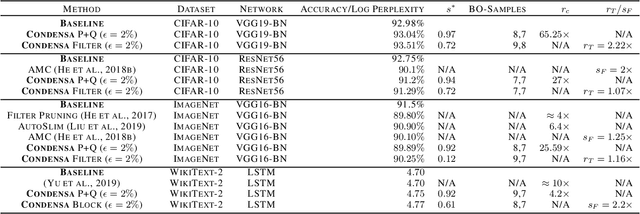
Deep neural networks frequently contain far more weights, represented at a higher precision, than are required for the specific task which they are trained to perform. Consequently, they can often be compressed using techniques such as weight pruning and quantization that reduce both model size and inference time without appreciable loss in accuracy. Compressing models before they are deployed can therefore result in significantly more efficient systems. However, while the results are desirable, finding the best compression strategy for a given neural network, target platform, and optimization objective often requires extensive experimentation. Moreover, finding optimal hyperparameters for a given compression strategy typically results in even more expensive, frequently manual, trial-and-error exploration. In this paper, we introduce a programmable system for model compression called Condensa. Users programmatically compose simple operators, in Python, to build complex compression strategies. Given a strategy and a user-provided objective, such as minimization of running time, Condensa uses a novel sample-efficient constrained Bayesian optimization algorithm to automatically infer desirable sparsity ratios. Our experiments on three real-world image classification and language modeling tasks demonstrate memory footprint reductions of up to 65x and runtime throughput improvements of up to 2.22x using at most 10 samples per search. We have released a reference implementation of Condensa at https://github.com/NVlabs/condensa.
Message Scheduling for Performant, Many-Core Belief Propagation
Sep 24, 2019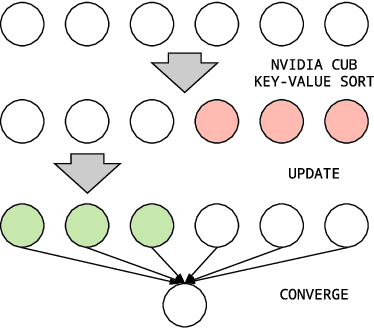
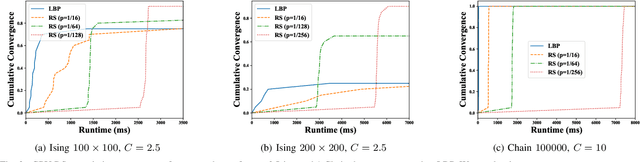
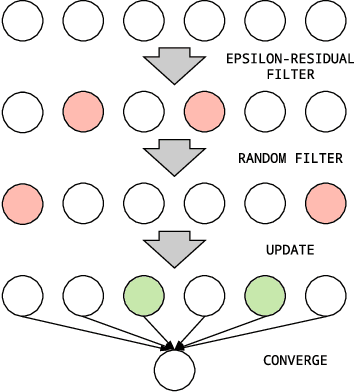
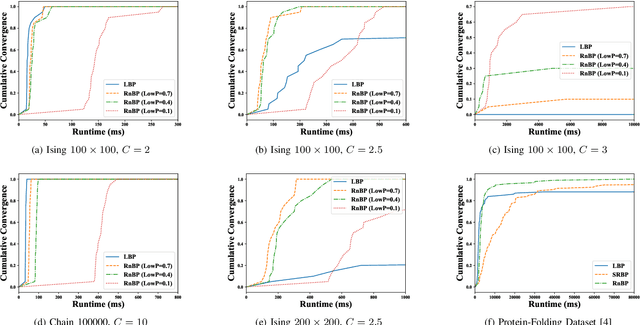
Belief Propagation (BP) is a message-passing algorithm for approximate inference over Probabilistic Graphical Models (PGMs), finding many applications such as computer vision, error-correcting codes, and protein-folding. While general, the convergence and speed of the algorithm has limited its practical use on difficult inference problems. As an algorithm that is highly amenable to parallelization, many-core Graphical Processing Units (GPUs) could significantly improve BP performance. Improving BP through many-core systems is non-trivial: the scheduling of messages in the algorithm strongly affects performance. We present a study of message scheduling for BP on GPUs. We demonstrate that BP exhibits a tradeoff between speed and convergence based on parallelism and show that existing message schedulings are not able to utilize this tradeoff. To this end, we present a novel randomized message scheduling approach, Randomized BP (RnBP), which outperforms existing methods on the GPU.