 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePREME: Preference-based Meeting Exploration through an Interactive Questionnaire
May 05, 2022

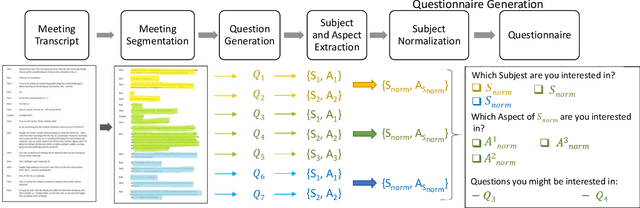

The recent increase in the volume of online meetings necessitates automated tools for managing and organizing the material, especially when an attendee has missed the discussion and needs assistance in quickly exploring it. In this work, we propose a novel end-to-end framework for generating interactive questionnaires for preference-based meeting exploration. As a result, users are supplied with a list of suggested questions reflecting their preferences. Since the task is new, we introduce an automatic evaluation strategy. Namely, it measures how much the generated questions via questionnaire are answerable to ensure factual correctness and covers the source meeting for the depth of possible exploration.
Pathologies of Pre-trained Language Models in Few-shot Fine-tuning
Apr 17, 2022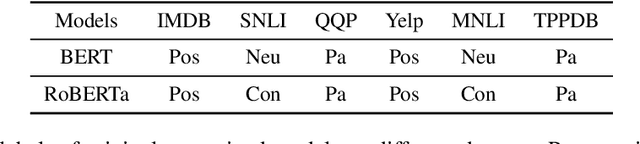
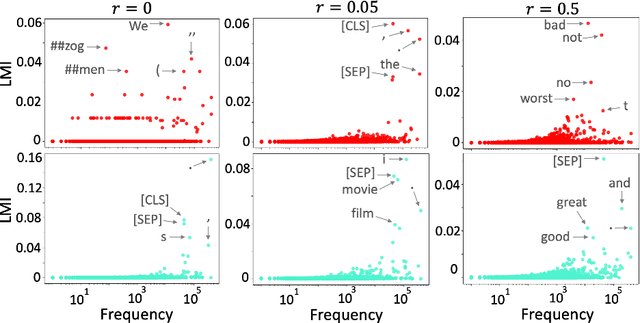
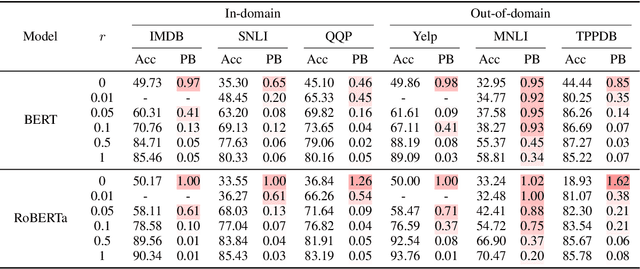
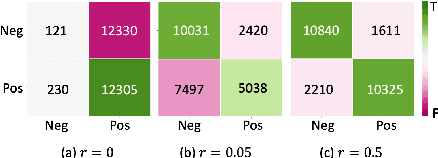
Although adapting pre-trained language models with few examples has shown promising performance on text classification, there is a lack of understanding of where the performance gain comes from. In this work, we propose to answer this question by interpreting the adaptation behavior using post-hoc explanations from model predictions. By modeling feature statistics of explanations, we discover that (1) without fine-tuning, pre-trained models (e.g. BERT and RoBERTa) show strong prediction bias across labels; (2) although few-shot fine-tuning can mitigate the prediction bias and demonstrate promising prediction performance, our analysis shows models gain performance improvement by capturing non-task-related features (e.g. stop words) or shallow data patterns (e.g. lexical overlaps). These observations alert that pursuing model performance with fewer examples may incur pathological prediction behavior, which requires further sanity check on model predictions and careful design in model evaluations in few-shot fine-tuning.
Knowledge Infused Decoding
Apr 06, 2022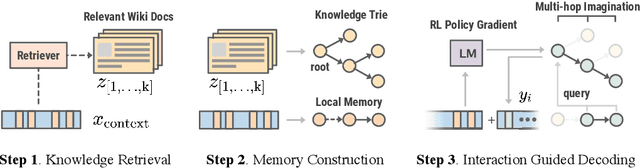
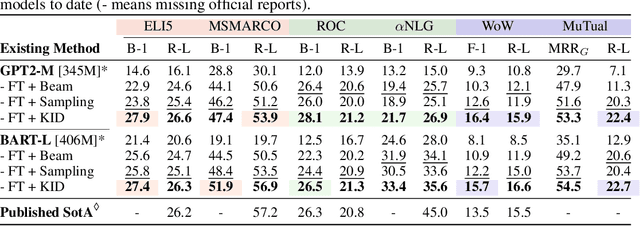
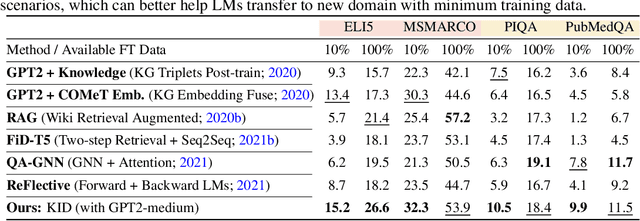
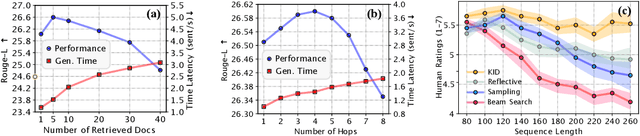
Pre-trained language models (LMs) have been shown to memorize a substantial amount of knowledge from the pre-training corpora; however, they are still limited in recalling factually correct knowledge given a certain context. Hence, they tend to suffer from counterfactual or hallucinatory generation when used in knowledge-intensive natural language generation (NLG) tasks. Recent remedies to this problem focus on modifying either the pre-training or task fine-tuning objectives to incorporate knowledge, which normally require additional costly training or architecture modification of LMs for practical applications. We present Knowledge Infused Decoding (KID) -- a novel decoding algorithm for generative LMs, which dynamically infuses external knowledge into each step of the LM decoding. Specifically, we maintain a local knowledge memory based on the current context, interacting with a dynamically created external knowledge trie, and continuously update the local memory as a knowledge-aware constraint to guide decoding via reinforcement learning. On six diverse knowledge-intensive NLG tasks, task-agnostic LMs (e.g., GPT-2 and BART) armed with KID outperform many task-optimized state-of-the-art models, and show particularly strong performance in few-shot scenarios over seven related knowledge-infusion techniques. Human evaluation confirms KID's ability to generate more relevant and factual language for the input context when compared with multiple baselines. Finally, KID also alleviates exposure bias and provides stable generation quality when generating longer sequences. Code for KID is available at https://github.com/microsoft/KID.
AutoDistil: Few-shot Task-agnostic Neural Architecture Search for Distilling Large Language Models
Jan 29, 2022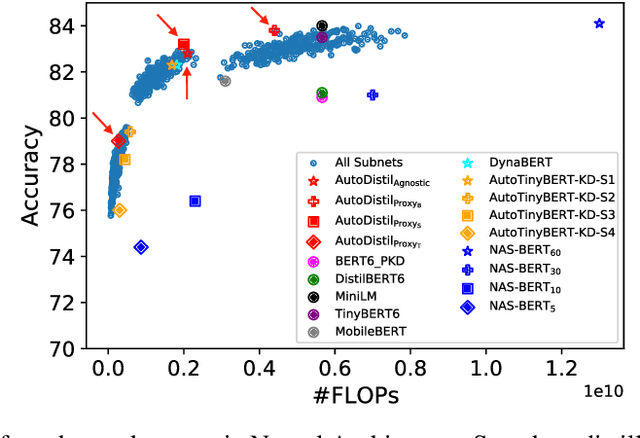
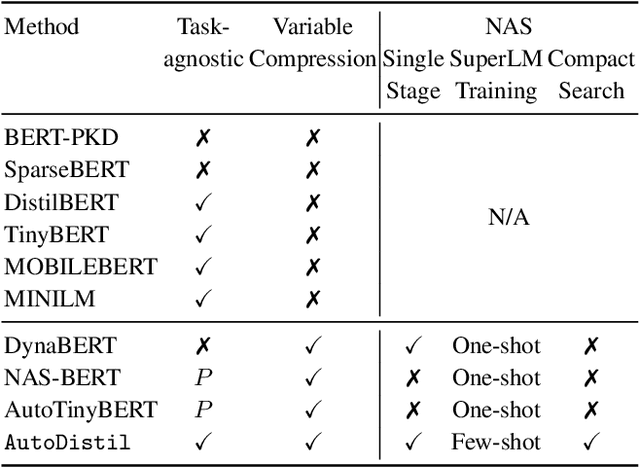
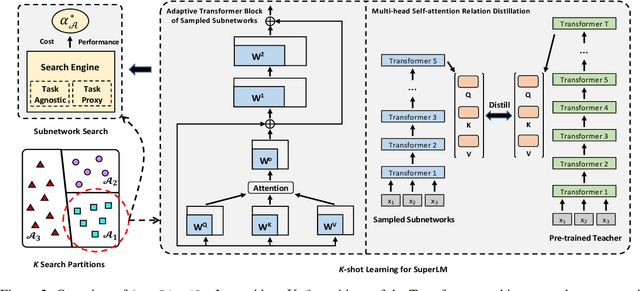
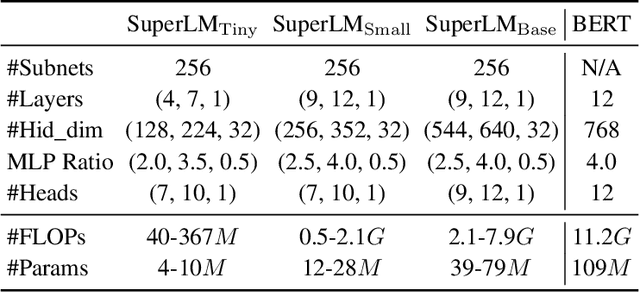
Knowledge distillation (KD) methods compress large models into smaller students with manually-designed student architectures given pre-specified computational cost. This requires several trials to find a viable student, and further repeating the process for each student or computational budget change. We use Neural Architecture Search (NAS) to automatically distill several compressed students with variable cost from a large model. Current works train a single SuperLM consisting of millions of subnetworks with weight-sharing, resulting in interference between subnetworks of different sizes. Our framework AutoDistil addresses above challenges with the following steps: (a) Incorporates inductive bias and heuristics to partition Transformer search space into K compact sub-spaces (K=3 for typical student sizes of base, small and tiny); (b) Trains one SuperLM for each sub-space using task-agnostic objective (e.g., self-attention distillation) with weight-sharing of students; (c) Lightweight search for the optimal student without re-training. Fully task-agnostic training and search allow students to be reused for fine-tuning on any downstream task. Experiments on GLUE benchmark against state-of-the-art KD and NAS methods demonstrate AutoDistil to outperform leading compression techniques with upto 2.7x reduction in computational cost and negligible loss in task performance.
Compositional Generalization for Natural Language Interfaces to Web APIs
Dec 09, 2021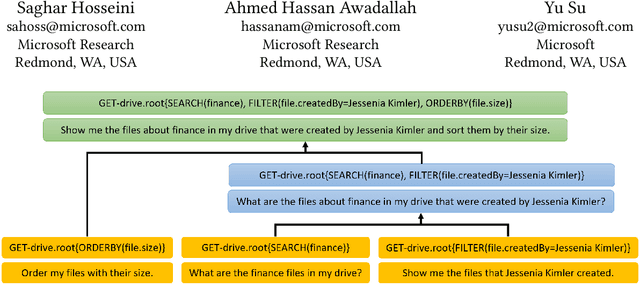


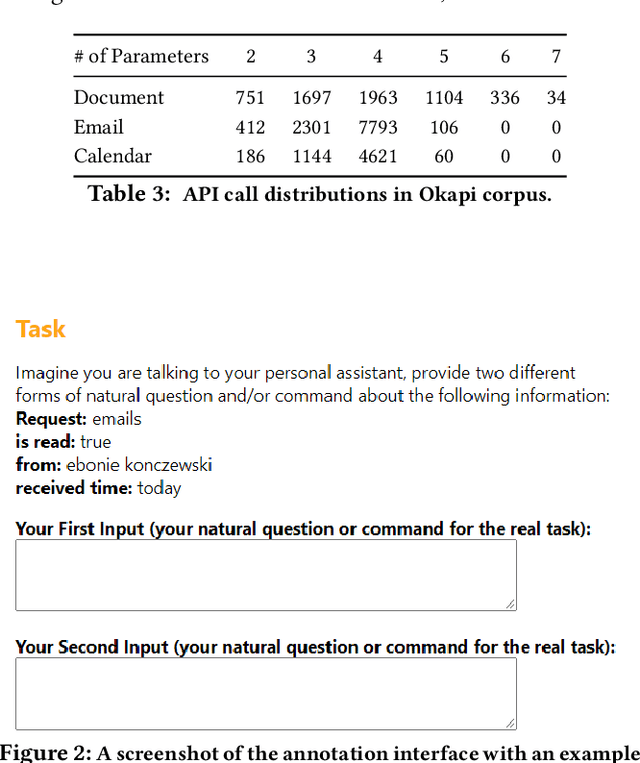
This paper presents Okapi, a new dataset for Natural Language to executable web Application Programming Interfaces (NL2API). This dataset is in English and contains 22,508 questions and 9,019 unique API calls, covering three domains. We define new compositional generalization tasks for NL2API which explore the models' ability to extrapolate from simple API calls in the training set to new and more complex API calls in the inference phase. Also, the models are required to generate API calls that execute correctly as opposed to the existing approaches which evaluate queries with placeholder values. Our dataset is different than most of the existing compositional semantic parsing datasets because it is a non-synthetic dataset studying the compositional generalization in a low-resource setting. Okapi is a step towards creating realistic datasets and benchmarks for studying compositional generalization alongside the existing datasets and tasks. We report the generalization capabilities of sequence-to-sequence baseline models trained on a variety of the SCAN and Okapi datasets tasks. The best model achieves 15\% exact match accuracy when generalizing from simple API calls to more complex API calls. This highlights some challenges for future research. Okapi dataset and tasks are publicly available at https://aka.ms/nl2api/data.
Adversarial GLUE: A Multi-Task Benchmark for Robustness Evaluation of Language Models
Nov 04, 2021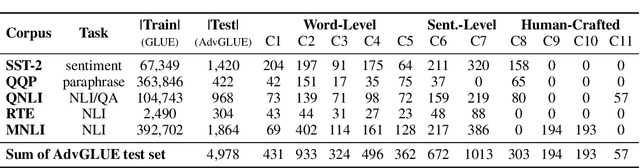
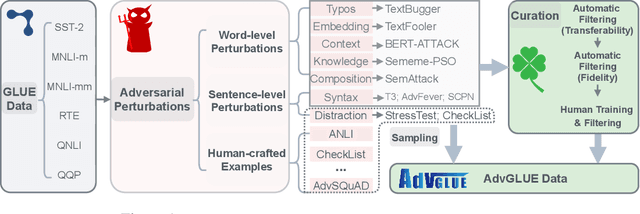


Large-scale pre-trained language models have achieved tremendous success across a wide range of natural language understanding (NLU) tasks, even surpassing human performance. However, recent studies reveal that the robustness of these models can be challenged by carefully crafted textual adversarial examples. While several individual datasets have been proposed to evaluate model robustness, a principled and comprehensive benchmark is still missing. In this paper, we present Adversarial GLUE (AdvGLUE), a new multi-task benchmark to quantitatively and thoroughly explore and evaluate the vulnerabilities of modern large-scale language models under various types of adversarial attacks. In particular, we systematically apply 14 textual adversarial attack methods to GLUE tasks to construct AdvGLUE, which is further validated by humans for reliable annotations. Our findings are summarized as follows. (i) Most existing adversarial attack algorithms are prone to generating invalid or ambiguous adversarial examples, with around 90% of them either changing the original semantic meanings or misleading human annotators as well. Therefore, we perform a careful filtering process to curate a high-quality benchmark. (ii) All the language models and robust training methods we tested perform poorly on AdvGLUE, with scores lagging far behind the benign accuracy. We hope our work will motivate the development of new adversarial attacks that are more stealthy and semantic-preserving, as well as new robust language models against sophisticated adversarial attacks. AdvGLUE is available at https://adversarialglue.github.io.
CLUES: Few-Shot Learning Evaluation in Natural Language Understanding
Nov 04, 2021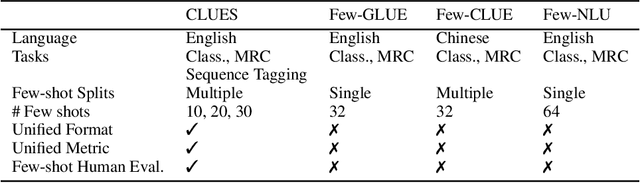
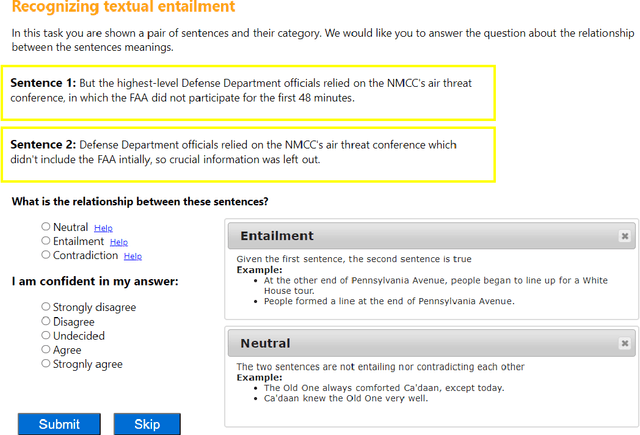

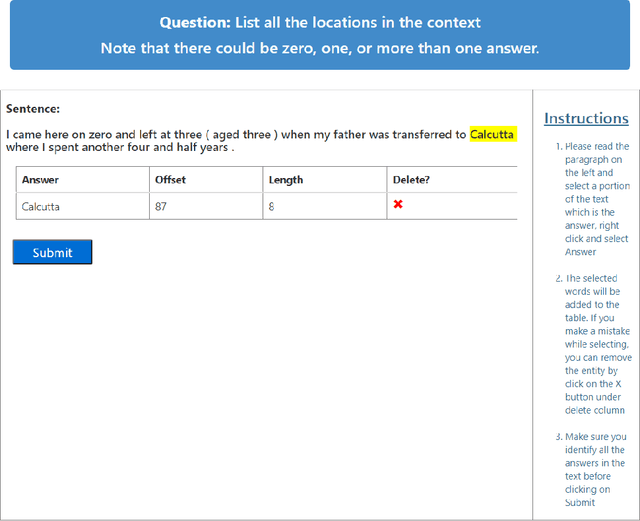
Most recent progress in natural language understanding (NLU) has been driven, in part, by benchmarks such as GLUE, SuperGLUE, SQuAD, etc. In fact, many NLU models have now matched or exceeded "human-level" performance on many tasks in these benchmarks. Most of these benchmarks, however, give models access to relatively large amounts of labeled data for training. As such, the models are provided far more data than required by humans to achieve strong performance. That has motivated a line of work that focuses on improving few-shot learning performance of NLU models. However, there is a lack of standardized evaluation benchmarks for few-shot NLU resulting in different experimental settings in different papers. To help accelerate this line of work, we introduce CLUES (Constrained Language Understanding Evaluation Standard), a benchmark for evaluating the few-shot learning capabilities of NLU models. We demonstrate that while recent models reach human performance when they have access to large amounts of labeled data, there is a huge gap in performance in the few-shot setting for most tasks. We also demonstrate differences between alternative model families and adaptation techniques in the few shot setting. Finally, we discuss several principles and choices in designing the experimental settings for evaluating the true few-shot learning performance and suggest a unified standardized approach to few-shot learning evaluation. We aim to encourage research on NLU models that can generalize to new tasks with a small number of examples. Code and data for CLUES are available at https://github.com/microsoft/CLUES.
DSEE: Dually Sparsity-embedded Efficient Tuning of Pre-trained Language Models
Oct 30, 2021
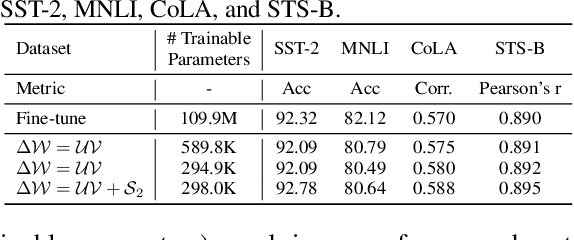
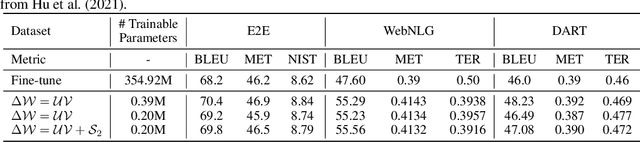
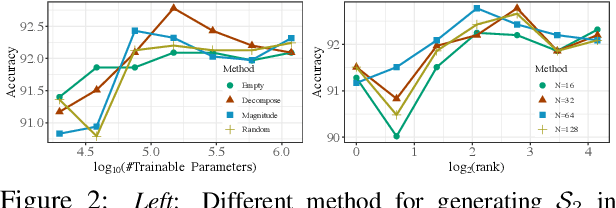
Gigantic pre-trained models have become central to natural language processing (NLP), serving as the starting point for fine-tuning towards a range of downstream tasks. However, two pain points persist for this paradigm: (a) as the pre-trained models grow bigger (e.g., 175B parameters for GPT-3), even the fine-tuning process can be time-consuming and computationally expensive; (b) the fine-tuned model has the same size as its starting point by default, which is neither sensible due to its more specialized functionality, nor practical since many fine-tuned models will be deployed in resource-constrained environments. To address these pain points, we propose a framework for resource- and parameter-efficient fine-tuning by leveraging the sparsity prior in both weight updates and the final model weights. Our proposed framework, dubbed Dually Sparsity-Embedded Efficient Tuning (DSEE), aims to achieve two key objectives: (i) parameter efficient fine-tuning - by enforcing sparsity-aware weight updates on top of the pre-trained weights; and (ii) resource-efficient inference - by encouraging a sparse weight structure towards the final fine-tuned model. We leverage sparsity in these two directions by exploiting both unstructured and structured sparse patterns in pre-trained language models via magnitude-based pruning and $\ell_1$ sparse regularization. Extensive experiments and in-depth investigations, with diverse network backbones (i.e., BERT, GPT-2, and DeBERTa) on dozens of datasets, consistently demonstrate highly impressive parameter-/training-/inference-efficiency, while maintaining competitive downstream transfer performance. For instance, our DSEE-BERT obtains about $35\%$ inference FLOPs savings with <1% trainable parameters and comparable performance to conventional fine-tuning. Codes are available in https://github.com/VITA-Group/DSEE.
What do Compressed Large Language Models Forget? Robustness Challenges in Model Compression
Oct 16, 2021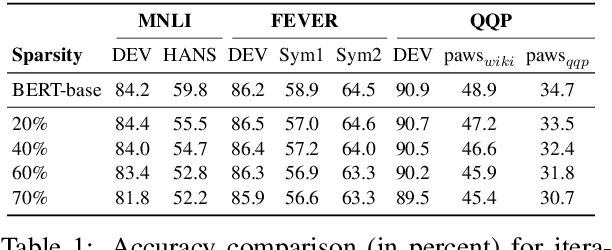
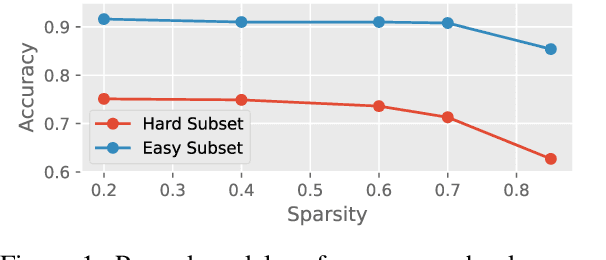
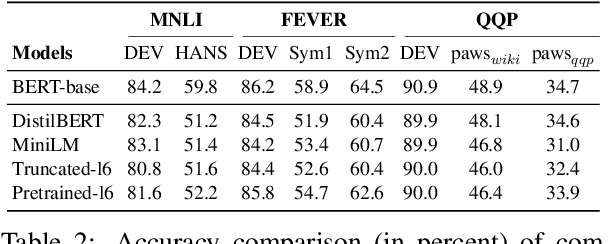
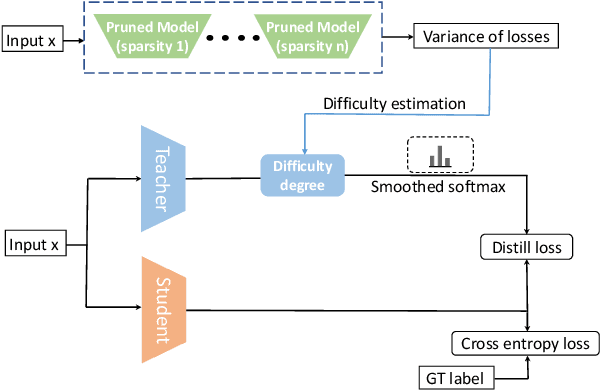
Recent works have focused on compressing pre-trained language models (PLMs) like BERT where the major focus has been to improve the compressed model performance for downstream tasks. However, there has been no study in analyzing the impact of compression on the generalizability and robustness of these models. Towards this end, we study two popular model compression techniques including knowledge distillation and pruning and show that compressed models are significantly less robust than their PLM counterparts on adversarial test sets although they obtain similar performance on in-distribution development sets for a task. Further analysis indicates that the compressed models overfit on the easy samples and generalize poorly on the hard ones. We further leverage this observation to develop a regularization strategy for model compression based on sample uncertainty. Experimental results on several natural language understanding tasks demonstrate our mitigation framework to improve both the adversarial generalization as well as in-distribution task performance of the compressed models.
LiST: Lite Self-training Makes Efficient Few-shot Learners
Oct 12, 2021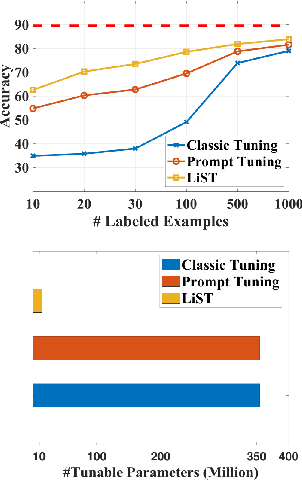
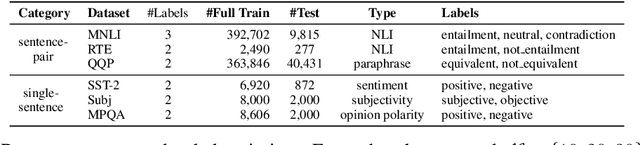
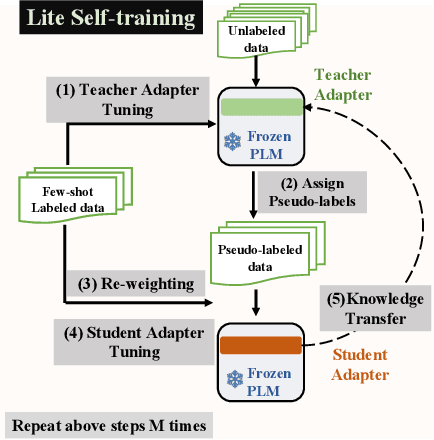
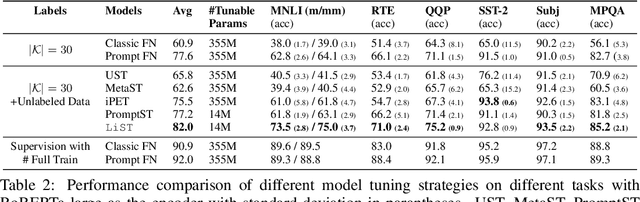
We present a new method LiST for efficient fine-tuning of large pre-trained language models (PLMs) in few-shot learning settings. LiST significantly improves over recent methods that adopt prompt fine-tuning using two key techniques. The first one is the use of self-training to leverage large amounts of unlabeled data for prompt-tuning to significantly boost the model performance in few-shot settings. We use self-training in conjunction with meta-learning for re-weighting noisy pseudo-prompt labels. However, traditional self-training is expensive as it requires updating all the model parameters repetitively. Therefore, we use a second technique for light-weight fine-tuning where we introduce a small number of task-specific adapter parameters that are fine-tuned during self-training while keeping the PLM encoder frozen. This also significantly reduces the overall model footprint across several tasks that can now share a common PLM encoder as backbone for inference. Combining the above techniques, LiST not only improves the model performance for few-shot learning on target domains but also reduces the model memory footprint. We present a comprehensive study on six NLU tasks to validate the effectiveness of LiST. The results show that LiST improves by 35% over classic fine-tuning methods and 6% over prompt-tuning with 96% reduction in number of trainable parameters when fine-tuned with no more than 30 labeled examples from each target domain.