 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"One-size-fits-all"? Observations and Expectations of NLG Systems Across Identity-Related Language Features
Oct 23, 2023



Fairness-related assumptions about what constitutes appropriate NLG system behaviors range from invariance, where systems are expected to respond identically to social groups, to adaptation, where responses should instead vary across them. We design and conduct five case studies, in which we perturb different types of identity-related language features (names, roles, locations, dialect, and style) in NLG system inputs to illuminate tensions around invariance and adaptation. We outline people's expectations of system behaviors, and surface potential caveats of these two contrasting yet commonly-held assumptions. We find that motivations for adaptation include social norms, cultural differences, feature-specific information, and accommodation; motivations for invariance include perspectives that favor prescriptivism, view adaptation as unnecessary or too difficult for NLG systems to do appropriately, and are wary of false assumptions. Our findings highlight open challenges around defining what constitutes fair NLG system behavior.
PREME: Preference-based Meeting Exploration through an Interactive Questionnaire
May 05, 2022

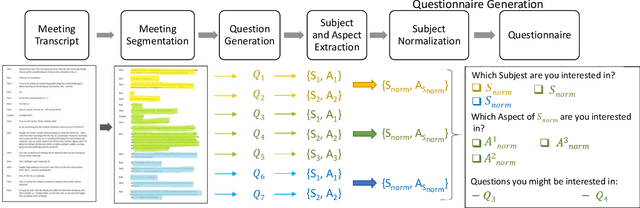

The recent increase in the volume of online meetings necessitates automated tools for managing and organizing the material, especially when an attendee has missed the discussion and needs assistance in quickly exploring it. In this work, we propose a novel end-to-end framework for generating interactive questionnaires for preference-based meeting exploration. As a result, users are supplied with a list of suggested questions reflecting their preferences. Since the task is new, we introduce an automatic evaluation strategy. Namely, it measures how much the generated questions via questionnaire are answerable to ensure factual correctness and covers the source meeting for the depth of possible exploration.
Knowledge Infused Decoding
Apr 06, 2022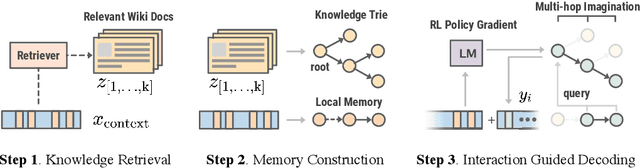
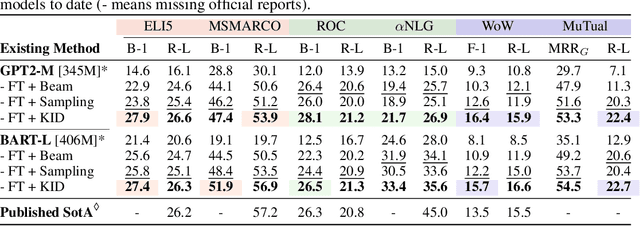
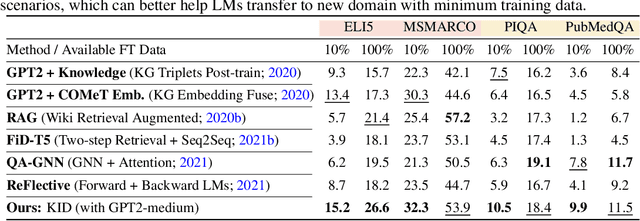
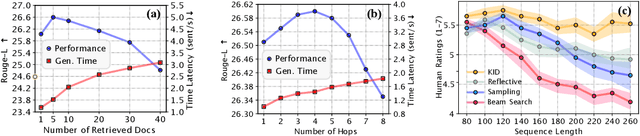
Pre-trained language models (LMs) have been shown to memorize a substantial amount of knowledge from the pre-training corpora; however, they are still limited in recalling factually correct knowledge given a certain context. Hence, they tend to suffer from counterfactual or hallucinatory generation when used in knowledge-intensive natural language generation (NLG) tasks. Recent remedies to this problem focus on modifying either the pre-training or task fine-tuning objectives to incorporate knowledge, which normally require additional costly training or architecture modification of LMs for practical applications. We present Knowledge Infused Decoding (KID) -- a novel decoding algorithm for generative LMs, which dynamically infuses external knowledge into each step of the LM decoding. Specifically, we maintain a local knowledge memory based on the current context, interacting with a dynamically created external knowledge trie, and continuously update the local memory as a knowledge-aware constraint to guide decoding via reinforcement learning. On six diverse knowledge-intensive NLG tasks, task-agnostic LMs (e.g., GPT-2 and BART) armed with KID outperform many task-optimized state-of-the-art models, and show particularly strong performance in few-shot scenarios over seven related knowledge-infusion techniques. Human evaluation confirms KID's ability to generate more relevant and factual language for the input context when compared with multiple baselines. Finally, KID also alleviates exposure bias and provides stable generation quality when generating longer sequences. Code for KID is available at https://github.com/microsoft/KID.
What do Compressed Large Language Models Forget? Robustness Challenges in Model Compression
Oct 16, 2021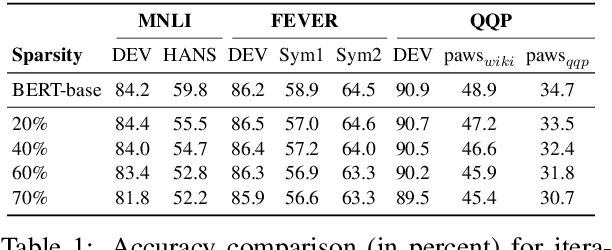
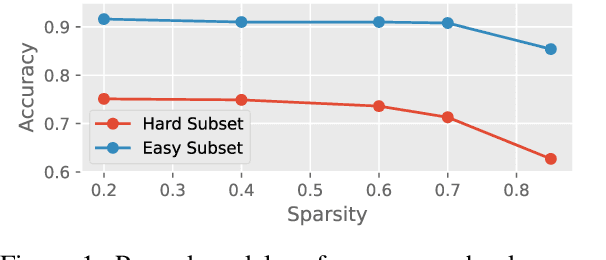
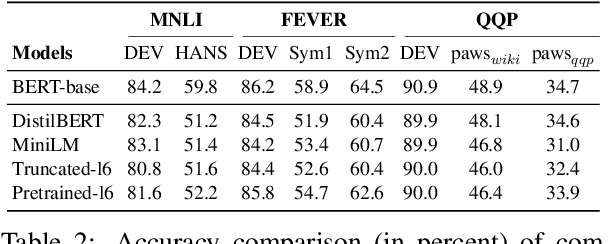
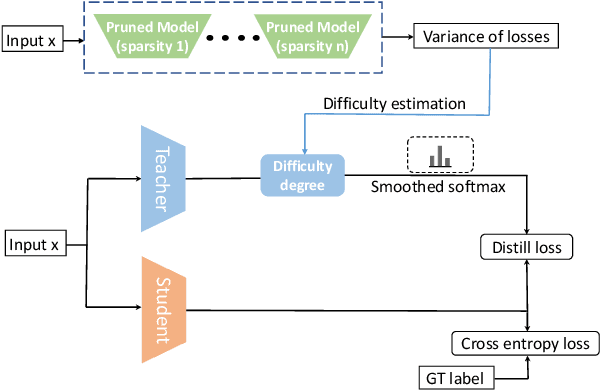
Recent works have focused on compressing pre-trained language models (PLMs) like BERT where the major focus has been to improve the compressed model performance for downstream tasks. However, there has been no study in analyzing the impact of compression on the generalizability and robustness of these models. Towards this end, we study two popular model compression techniques including knowledge distillation and pruning and show that compressed models are significantly less robust than their PLM counterparts on adversarial test sets although they obtain similar performance on in-distribution development sets for a task. Further analysis indicates that the compressed models overfit on the easy samples and generalize poorly on the hard ones. We further leverage this observation to develop a regularization strategy for model compression based on sample uncertainty. Experimental results on several natural language understanding tasks demonstrate our mitigation framework to improve both the adversarial generalization as well as in-distribution task performance of the compressed models.
UserIdentifier: Implicit User Representations for Simple and Effective Personalized Sentiment Analysis
Oct 01, 2021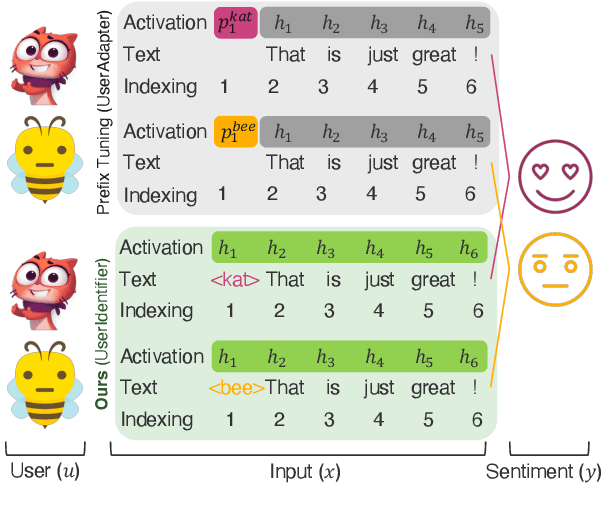
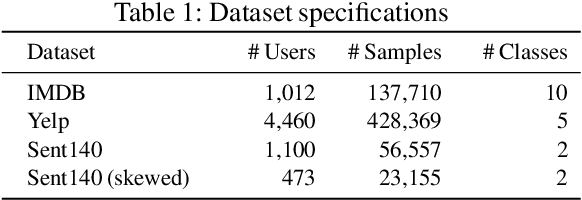
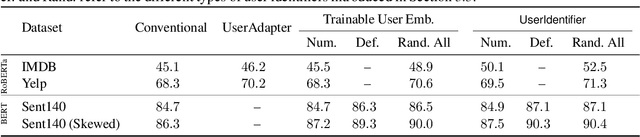
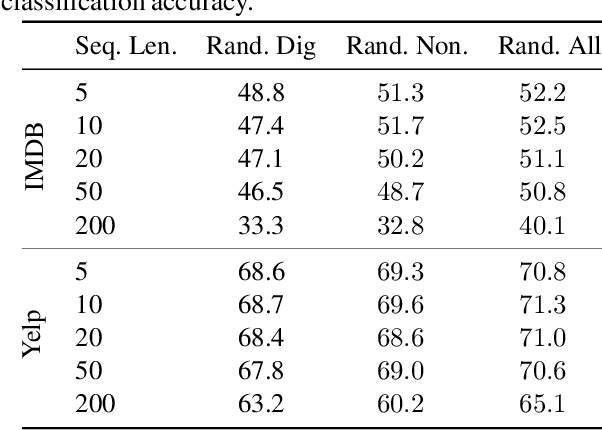
Global models are trained to be as generalizable as possible, with user invariance considered desirable since the models are shared across multitudes of users. As such, these models are often unable to produce personalized responses for individual users, based on their data. Contrary to widely-used personalization techniques based on few-shot learning, we propose UserIdentifier, a novel scheme for training a single shared model for all users. Our approach produces personalized responses by adding fixed, non-trainable user identifiers to the input data. We empirically demonstrate that this proposed method outperforms the prefix-tuning based state-of-the-art approach by up to 13%, on a suite of sentiment analysis datasets. We also show that, unlike prior work, this method needs neither any additional model parameters nor any extra rounds of few-shot fine-tuning.
A Conditional Generative Matching Model for Multi-lingual Reply Suggestion
Sep 15, 2021

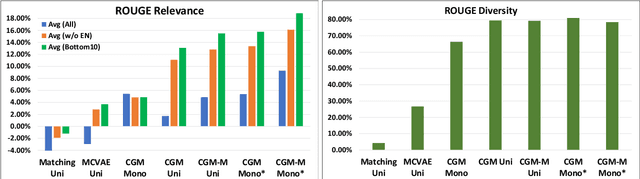
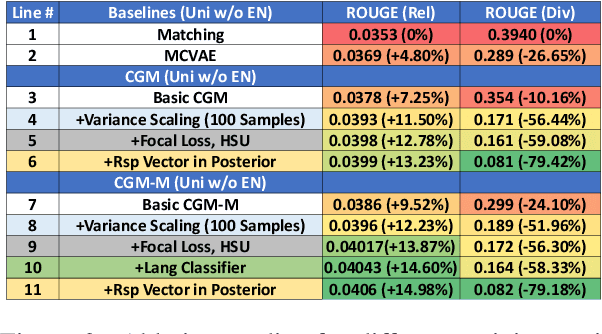
We study the problem of multilingual automated reply suggestions (RS) model serving many languages simultaneously. Multilingual models are often challenged by model capacity and severe data distribution skew across languages. While prior works largely focus on monolingual models, we propose Conditional Generative Matching models (CGM), optimized within a Variational Autoencoder framework to address challenges arising from multi-lingual RS. CGM does so with expressive message conditional priors, mixture densities to enhance multi-lingual data representation, latent alignment for language discrimination, and effective variational optimization techniques for training multi-lingual RS. The enhancements result in performance that exceed competitive baselines in relevance (ROUGE score) by more than 10\% on average, and 16\% for low resource languages. CGM also shows remarkable improvements in diversity (80\%) illustrating its expressiveness in representation of multi-lingual data.
Language Scaling for Universal Suggested Replies Model
Jun 04, 2021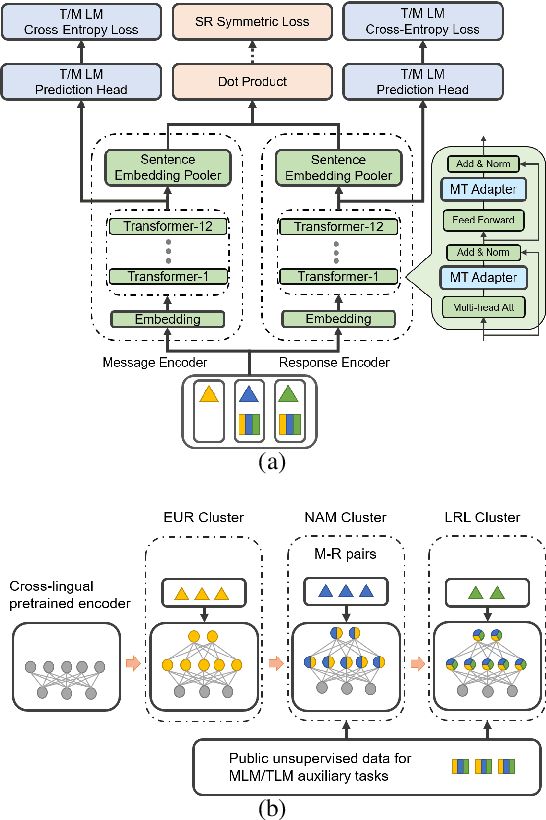

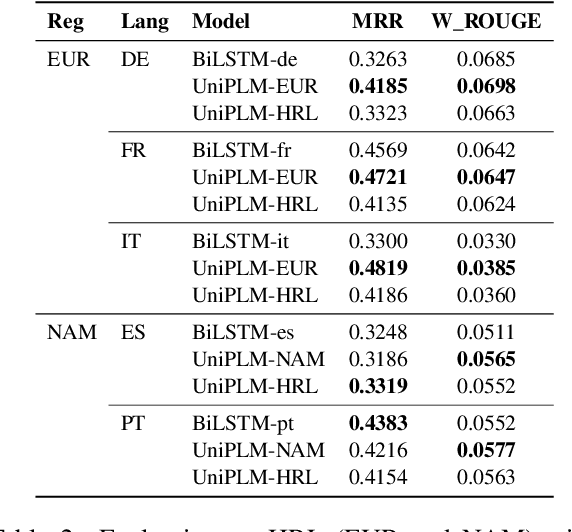
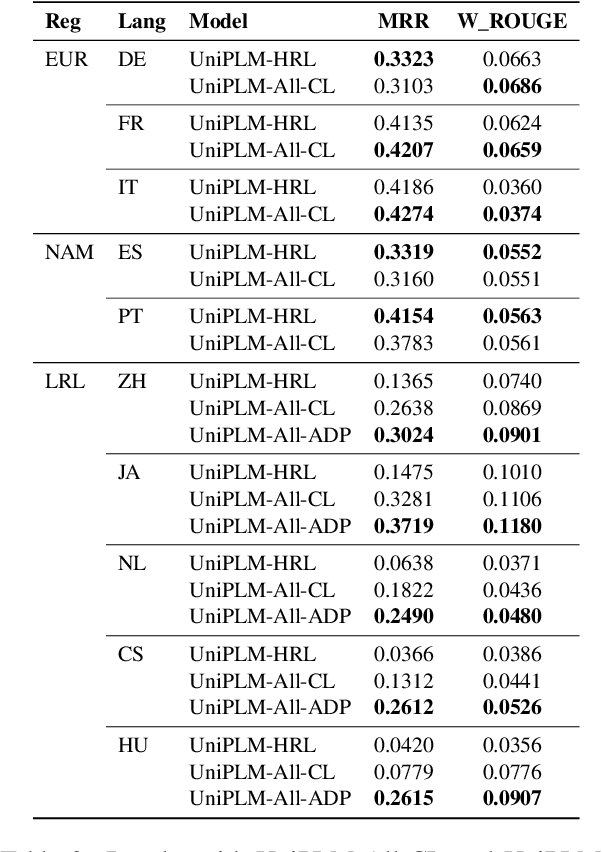
We consider the problem of scaling automated suggested replies for Outlook email system to multiple languages. Faced with increased compute requirements and low resources for language expansion, we build a single universal model for improving the quality and reducing run-time costs of our production system. However, restricted data movement across regional centers prevents joint training across languages. To this end, we propose a multi-task continual learning framework, with auxiliary tasks and language adapters to learn universal language representation across regions. The experimental results show positive cross-lingual transfer across languages while reducing catastrophic forgetting across regions. Our online results on real user traffic show significant gains in CTR and characters saved, as well as 65% training cost reduction compared with per-language models. As a consequence, we have scaled the feature in multiple languages including low-resource markets.
A Dataset and Baselines for Multilingual Reply Suggestion
Jun 03, 2021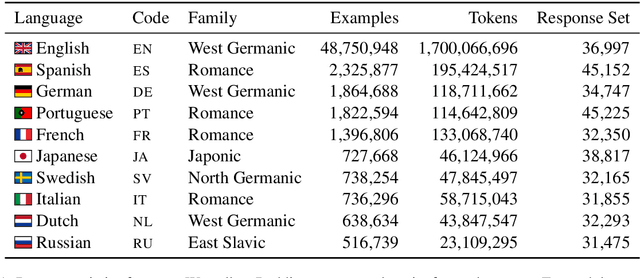
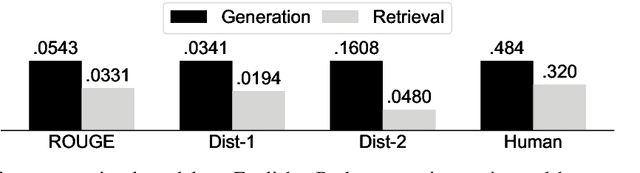

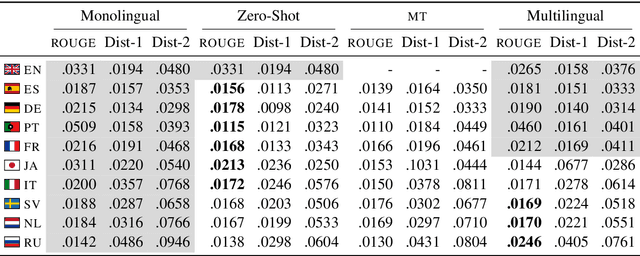
Reply suggestion models help users process emails and chats faster. Previous work only studies English reply suggestion. Instead, we present MRS, a multilingual reply suggestion dataset with ten languages. MRS can be used to compare two families of models: 1) retrieval models that select the reply from a fixed set and 2) generation models that produce the reply from scratch. Therefore, MRS complements existing cross-lingual generalization benchmarks that focus on classification and sequence labeling tasks. We build a generation model and a retrieval model as baselines for MRS. The two models have different strengths in the monolingual setting, and they require different strategies to generalize across languages. MRS is publicly available at https://github.com/zhangmozhi/mrs.
MetaXL: Meta Representation Transformation for Low-resource Cross-lingual Learning
Apr 16, 2021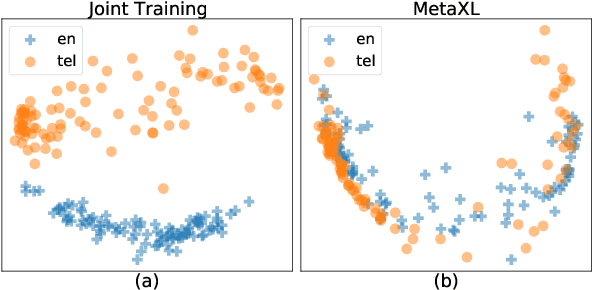
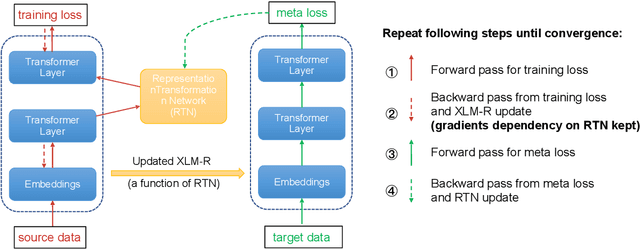
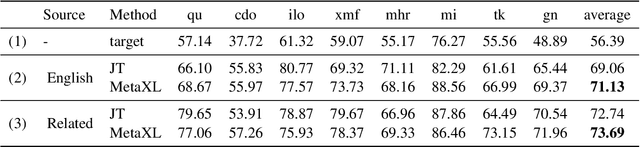
The combination of multilingual pre-trained representations and cross-lingual transfer learning is one of the most effective methods for building functional NLP systems for low-resource languages. However, for extremely low-resource languages without large-scale monolingual corpora for pre-training or sufficient annotated data for fine-tuning, transfer learning remains an under-studied and challenging task. Moreover, recent work shows that multilingual representations are surprisingly disjoint across languages, bringing additional challenges for transfer onto extremely low-resource languages. In this paper, we propose MetaXL, a meta-learning based framework that learns to transform representations judiciously from auxiliary languages to a target one and brings their representation spaces closer for effective transfer. Extensive experiments on real-world low-resource languages - without access to large-scale monolingual corpora or large amounts of labeled data - for tasks like cross-lingual sentiment analysis and named entity recognition show the effectiveness of our approach. Code for MetaXL is publicly available at github.com/microsoft/MetaXL.
Learning with Weak Supervision for Email Intent Detection
May 26, 2020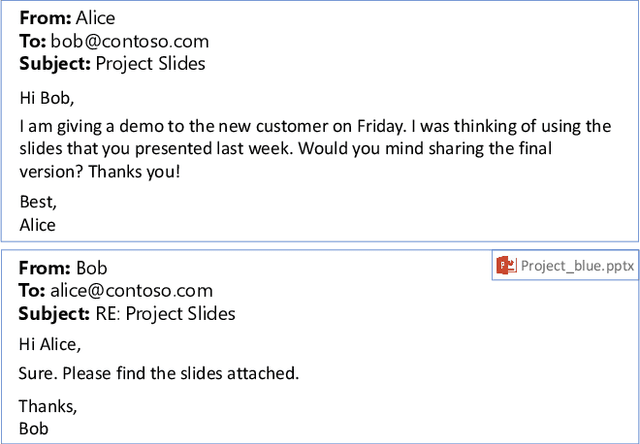

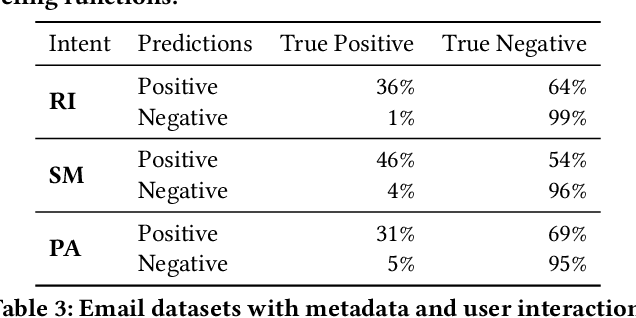
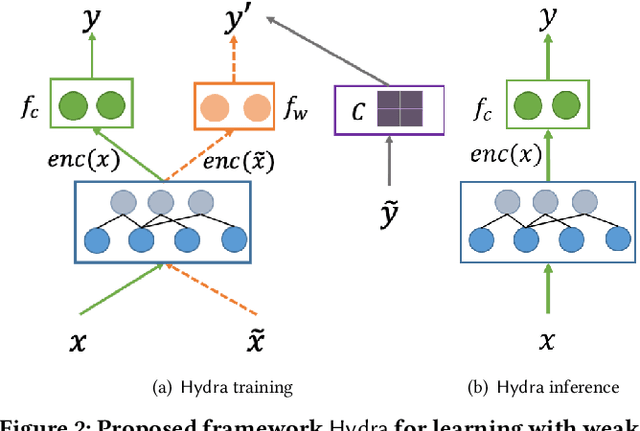
Email remains one of the most frequently used means of online communication. People spend a significant amount of time every day on emails to exchange information, manage tasks and schedule events. Previous work has studied different ways for improving email productivity by prioritizing emails, suggesting automatic replies or identifying intents to recommend appropriate actions. The problem has been mostly posed as a supervised learning problem where models of different complexities were proposed to classify an email message into a predefined taxonomy of intents or classes. The need for labeled data has always been one of the largest bottlenecks in training supervised models. This is especially the case for many real-world tasks, such as email intent classification, where large scale annotated examples are either hard to acquire or unavailable due to privacy or data access constraints. Email users often take actions in response to intents expressed in an email (e.g., setting up a meeting in response to an email with a scheduling request). Such actions can be inferred from user interaction logs. In this paper, we propose to leverage user actions as a source of weak supervision, in addition to a limited set of annotated examples, to detect intents in emails. We develop an end-to-end robust deep neural network model for email intent identification that leverages both clean annotated data and noisy weak supervision along with a self-paced learning mechanism. Extensive experiments on three different intent detection tasks show that our approach can effectively leverage the weakly supervised data to improve intent detection in emails.
* 10 pages, 3 figures